학습내용
ORM
- ORM : 쿼리를 작성할 때 원하는 객체 지향 언어로 작성하게 해주는 것이 Object-Relational Mapping 이라는 개념
대표적인 파이썬 ORM 라이브러리 : SQLalchemy
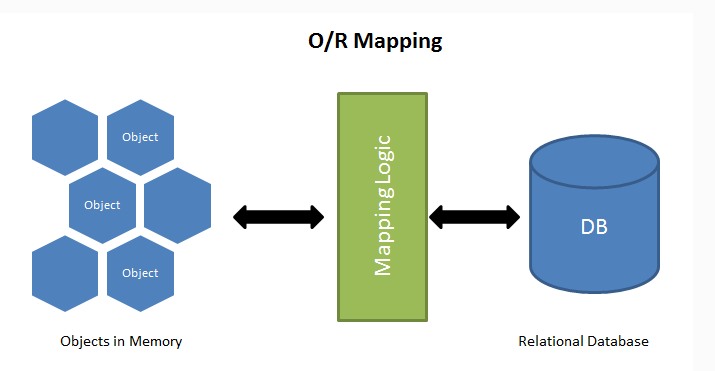
- DBAPI : 데이터베이스에 접근할 수 있도록 해주는 파이썬모듈
데이터베이스 엔진에 따라 호환되는 라이브러리가 따로있음
postgre -> psycopg2
sqlite -> sqlite3
SQLalchemy와 DBAPI의 차이는 SQLalchemy는 파이썬코드를 sql 쿼리로 맵핑해주고 데이터베이스를 작동시키는 방식이고, DBAPI는 파이썬을 통해 sql문을 작성하여 이를 바로 데이터베이스로 넘겨준다.
SQLalchemy
SQLalchemy : 다른 라이브러리들과 대비되는 특징으로 사용자가 정의한 DDL을 제외하고 자체적으로 스키마를 생성하지않는다는 특징이 있음
크게
- Core : 데이터베이스 시스템과 상호작용, SQL 문법을 파이썬 언어로 표현 가능하게 해줌.
- ORM : Core를 기반으로 한 기능으로, SQLAlchemy에서의 기능들을 어플리케이션 코드와 ORM 사용에 더 초점을 맞춰서 변경한 것.
으로 나누어져있다.
#최신버전 설치
pip install --pre sqlalchemy
#데이터베이스 연결
from sqlalchemy import create_engine
engine = create_engine("sqlite:///:memory:")'://' 다음에 '/' 가 하나가 오면 현재 디렉토리 기준에서 상대적 경로이며 '//' 처럼 두 개가 있다면 절대적 경로
#mapping
#데이터베이스의 구조와 코드 상에 구조를 연결
from sqlalchemy.orm import declarative_base
Base = declarative_base() #상속받는 클래스들을 자동으로 인지하고 매핑
#테이블 생성
from sqlalchemy import Column, Integer, String
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String)
age = Column(Integer)
item_id = Column(Integer, ForeignKey('item.id'))
items = relationship('item', back_populates = 'users') #관계형성
def __repr__(self): #테이블을 print했을때 표기되는 형태
return f"User {self.id}: {self.name}"
- back_populates 는 연결된 테이블의 입장에서 어떻게 연결되어야 하는지 알려줌. 양쪽 테이블에 다 표기해주어야함.
- backref : 한쪽테이블에서만 정의해주면 됨.
- cascade : 외래키 자기참조
# 기본 문법
Base.metadata.drop_all(engine) #모든 테이블 삭제
Base.metadata.create_all(engine) #모든 테이블 생성
from sqlalchemy.orm import sessionmaker #중간에서 데이터베이스 상태 관리해주는 session 생성
from sqlalchemy.orm import Session
Session = sessionmaker(bind=engine)
session = Session() #세션생성
#Insert data
def insert_address(customer_id, address_id, city, street,
session=session):
address_data = Address(customer_id=customer_id, address_id=address_id, city=city, street=street)
session.add(address_data)
session.commit()
#Read data
def read_item_invoices_date(item_id, session=session):
read_data = session.query(Invoice_Item.invoice_date).filter(Invoice_Item.item_id==item_id).all()
return read_data
#Delete data
def delete_customer(customer_id, session=session):
del_data = session.query(Customer).filter(Customer.customer_id==customer_id).one()
session.delete(del_data)
session.commit()
#Update data
def update_customer_name(customer_id, new_name, session=session):
update_data = session.query(Customer).filter(Customer.customer_id==customer_id).one()
update_data.customer_name = new_name
session.commit()
#all, one, first 등을 이용하여 query결과를 불러올 수 있음.
#first는 없으면 None, all은 [], one은 에러가 발생한다.#csv파일 옮기기
from csv import DictReader
from sqlalchemy import create_engine, Column, Integer, String, Float
from sqlalchemy.orm import declarative_base, Session
import pandas as pd
### 아래 코드는 변경하지 말아주세요! ###
DATABASE_URI = "sqlite:///titanic_orm.db"
CSV_FILEPATH = 'titanic.txt'
engine = create_engine(DATABASE_URI)
Base = declarative_base(bind=engine)
session = Session(bind=engine)
### 위 코드는 변경하지 말아주세요! ###
class Passenger(Base):
__tablename__ = 'Passenger'
id = Column(Integer, primary_key=True)
Survived = Column(Integer)
Pclass = Column(Integer)
Name = Column(String)
Sex = Column(String)
Age = Column(Float)
Siblings_Spouses_Aboard = Column(Integer)
Parents_Children_Aboard = Column(Integer)
Fare = Column(Float)
Base.metadata.drop_all(engine)
Base.metadata.create_all(engine)
with open('titanic.txt') as file:
filereader = DictReader(file) #dict형태로 불러온다면 키 값으로 데이터를 쉽게 찾을 수 있어 편리함.
id = 1
for row in filereader:
Survived = int(row['Survived'])
Pclass = int(row['Pclass'])
Name = str(row['Name'])
Sex = str(row['Sex'])
Age = float(row['Age'])
Siblings_Spouses_Aboard = int(row['Siblings/Spouses Aboard'])
Parents_Children_Aboard = int(row['Parents/Children Aboard'])
Fare = float(row['Fare'])
row_data = Passenger(id = id, Survived=Survived, Pclass=Pclass, Name=Name, Sex=Sex, Age=Age,
Siblings_Spouses_Aboard=Siblings_Spouses_Aboard, Parents_Children_Aboard=Parents_Children_Aboard, Fare=Fare) #추가 데이터 생성
session.add(row_data)
id += 1 #id값 변화
session.commit()