Detection of Malicious PDF based on Document Structure Features and Stream Objects 요약 및 정리
논문 스터디
1. Introduction
이전에는 이메일에 실행 파일 포맷인 PE(portable executable) 파일을 첨부하였으나, 최근에는 문서 파일의 취약점을 이용하여 문서형 악성코드를 유포하고 있다. 문서형 악성코드는 실행 파일 자체가 아니기 때문에 기존 보안 프로그램을 우회하기 쉬운 특징을 이용한 것이다. 논문에서는 문서의 구조뿐만 아니라 삽입된 악성 스크립트로부터 텍스트 키워드를 추출하여 보다 정교한 탐지 모델을 제시하였다. 모델에는 SVM, Random Forest, Naive Bayesian algorithm 등을 적용시켰다.
2. Related Works
문서형 악성코드의
(1) 악성 행위 정보를 파일 및 레지스트리, 네트워크, 프로세스의 관점에서 분석하여 해당 행위 정보를 기반으로 탐지하는 연구
(2) 문서의 취약점을 분석하고 내부 구조 및 알려진 취약점을 보여주는 연구
(3) 악성코드 바이너리 실행파일에 포함된 API에 대한 호출 빈도수 및 문자열의 유사도를 비교하여 악성 여부를 판별하는 연구
등이 있다.
3. Proposed Model
1.1 PDF structure analysis
- PDF의 구성요소
- Object : PDF는 데이터 오브젝트들로 구성됨. 폰트, 텍스트, 페이지, 이미지 등이 여기에 해당
- File Structure : Object 저장, 접근, 업데이트 정보를 포함하고 있음
- Document Structure : Object들이 어떻게 각 문서를 구성하고 배치되는지 설명
- Content Streams : 대량 데이터(이미지, 오디오, 폰트, 동영상, 페이지 설명, 자바스크리트 등)을 포함. 길이 제한이 없어 대량 데이터를 이진 형태로 저장.
-
PDF 파일 구조
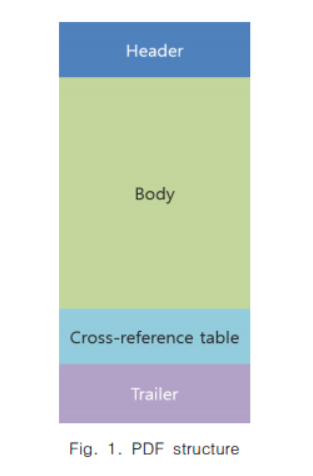
- Header
- PDF 명세 버전을 알림
- Body
- PDF 문서를 구성하는 Object를 포함
- 실질적인 내용을 담고 있는 간접 Object(레이블된 오브젝트)들로 구성됨
- 문서의 내용, 폰트, 페이지, 이미지 요소들을 나타냄
- Cross-reference table(xref)
- Object들을 참조할 때 사용
- 간접 Object에 관한 정보를 가지고 있음
- Object들의 사용여부
- Trailer
- Root 오브젝트의 위치 정보 표시
- Cross-reference table 위치 정보 표시
- Header
-
PDF 문서 임베디드된 엔티티
-
PDF 파일 구조 example
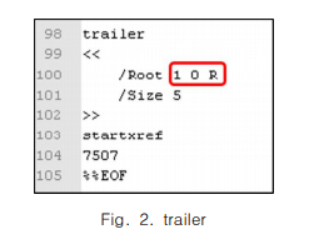
그림 2는 trailer의 예로, Root 오브젝트는 1번째 오브젝트의 오프셋(상대적 위치) 0을 참조하는 것을 나타내고 있다. Cross-reference table 항목 수는 5개, 오프셋 값은 7057임을 나타낸다.
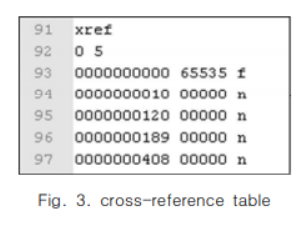
오브젝트는 0번부터 5개 존재한다. f는 해당 오브젝트를 사용하지 않음으로, n은 사용함을 나타낸다. 94번째 line은 1번째 오브젝트, 오프셋 10, 사용함을 의미한다.

붉은색 박스의 오브젝트 1번 타입은 catalog, 페이지 레이아웃은 싱글 페이지, 페이지 내용은 2번 오브젝트를 참고, 문서 열람시 액션은 4번 오브젝트를 참고한다.
PDF 파일에서 레이블된 오브젝트는 고유의 식별자를 갖게 되며 다른 오브젝트는 이를 이용하여 해당 오브젝트를 간접 참조할 수 있다. 악성 PDF는 보통 스트림 오브젝트에 악성코드를 삽입하게 되는데, 다른 타입은 길이의 제약을 가지므로 stream 오브젝트를 이용한다.
악성 문서를 분석해보면 자바스크립트가 포함되어 있는 경우가 대부분이다.
1.2 PDF feature extraction
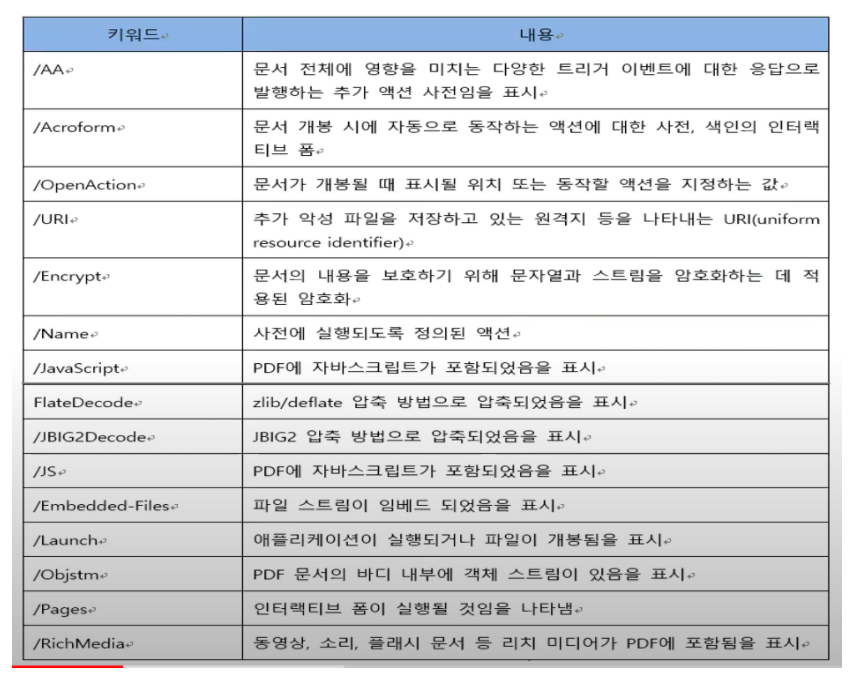
- 악성코드 탐지를 위한 126개의 feature를 추출
- PDF 파일 기본 정보(2개)
- 사이즈, 버전
- PDF 파일 인코딩 및 자바스크립트 삽입 정보(4개)
- ASCIIHex, Flate, ASCII85, JAVASCRIPT
- PDF 파일 내의 주요 키워드 정보(43개)
- obj, endobj, stream, endstream 등
- PDF 파일에 인코딩되어 삽입된 스크립트 내 텍스트 정보(77개)
- 메소드명 : charCodeAt, fromCharCode, replace, join 등
- 개체명, 속성명 : Array, String, Date, length 등
- 연산자, 상수, 타입, 예약어 : var, if, this, function 등
- 가독 스트링 : app, fnc, sum, arr, num 등
- PDF 파일 기본 정보(2개)
- PDF 파일 내에 존재하는 정상 문서와 악성 문서의 특징 구별되는 주요한 키워드
- obj, endobj : 오브젝트의 시작과 끝 태그
- stream, endstream : 스트림 태그
- /Page : 페이지 수 정보
- /JS, /JavaScript : 자바스크립트 태그
- /AA, /OpenAction : 자동 실행
- /Type : 오브젝트 타입 정보
4. Experiment Results
악성 문서 11093개, 정상 문서 9000개를 연구에 사용. 기존의 연구들에 비해 샘플 수가 많다.
1.1 Feature statistics
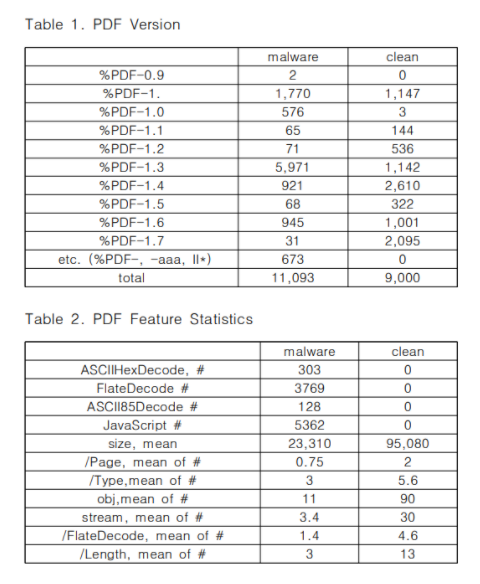
Table 2에서의 통계치들에서 malware와 clean의 특질들이 극명하게 차이가 나는 것을 볼 수 있다.
1.2 Training algorithm
Naive Bayes, Random forest, Support vector machine을 이용하였다.
Random forest를 사용하여 악성문서를 판단하게 된다면 문제점이 있다. 악성 문서를 의도적으로 수정하여 일부 기능을 "정상화"하고 포함된 악성 콘텐츠를 그대로 유지하면서 양성 문서와 유사하게 만드는 것이 가능하다.
이런 이유로 트리 형태의 모델보다는 black box형태의 알고리즘에서 좋은 성능을 내는 것이 중요하다.
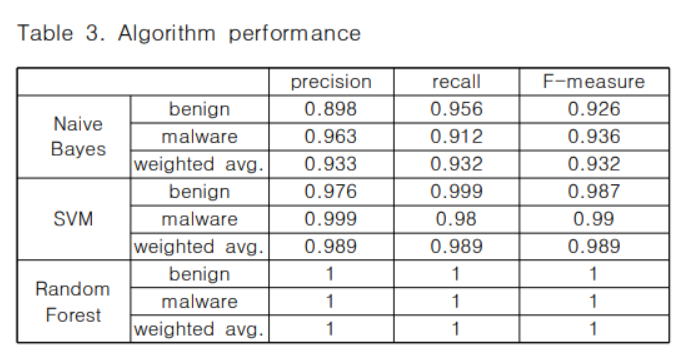
결과는 black box형태의 알고리즘인 SVM에서도 98.9%의 성능을 나타내어, 과거의 연구에서보다 훨씬 높은 성능을 보였다.
1.3 Feature importance
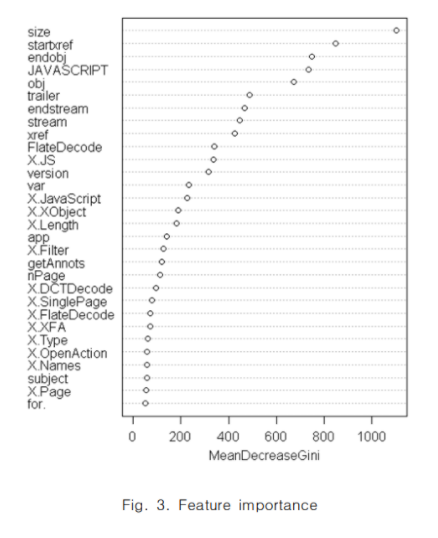
변수의 중요도를 시각화 해본 결과, 가장 importance가 높은 변수는 size로 나타났다. 악성 문서는 정상 문서에 비해 크기가 작은 특징을 가진다.
5. Conclusion
분석 결과 악성 PDF는 이들 stream 오브젝트에 악성코드를 삽입한다. 긴 바이트를 분석해보면 자바스크립트가 포함되어 있는 경우가 대부분이다. 또한 탐지를 감추기위해 인코딩되어 있음을 알 수 있었다.
PDF파일 기본 정보 2개, PDF 파일 인코딩 및 자바스크립트 삽입 정보 4개, PDF 파일 내의 주요 키워드 정보 43개의 발생 건수를 특질로 추출하였다. 이를 black blox 알고리즘인 SVM에서 98.9%의 탑지율을 보였다.
향후 연구로는 딥러닝을 이용한 PDF 문서형 악성코드 탐지를 계획하고 있다.
Reference
-
Detection of Malicious PDF based on Document Structure Features and Stream Objects
저자 : Ah Reum Kang, Young-Seob Jeong, Se Lyeong Kim, Jonghyun Kim
