05번째 게시물
안녕하세요. 이번 게시물에서는 03,04번째 게시물에서 다뤘던 뇌종양이미지 데이터를 가지고 오토엔코더를 통해 새로운 뇌종양 이미지를 생성해보려고 합니다.
참고 블로그 : https://jamm-notnull.tistory.com/7, https://medium.com/dataseries/variational-autoencoder-with-pytorch-2d359cbf027b
1. VAE 개념
Auto encoder는 unspervised learning의 일종으로 라벨링 없이 학습을 진행할 수 있습니다.
조금 더 세세한 모델의 아키텍처는 04번째 게시물에 작성하였습니다.
04번째에서는 단순히 입력 - 복원된 출력을 비교하여 이상치를 탐지하였지만 이번 게시물에서는 기존과 똑같이 복원된 출력이 아니라 기존과 특징이 비슷하되 새로운 이미지를 생성하는 것이 목적입니다.
VAE는 이러한 목적을 LOSS함수 재정의 하면서 만족 시킬 수 있습니다.
일반적인 AE 에서는 Input 값이라는 한가지 점을 추종하면서 Input과 유사한 이미지를 만드는 것이 목적입니다.
한 점을 추종하는 : AE_loss = (입력-출력)^2 (meansquared loss)
하지만 VAE는 한가지 점을 추종하는 것이 아니라 한가지 점과 동일하지 않으면서 유사한 여러가지 점들을 추종하는 것이 목표입니다. 따라서 VAE는 일반적인 AE_Loss에 Input과 비교했을 때 그럴듯한 이미지가 존재하는 구간을 추종하게 됩니다. 이러한 점에서 VAE_Loss는 기존 AE_Loss함수에 KLdivergence_Loss 라는 새로운 항이 추가됩니다. KLdivergence_Loss는 한 가지 확률분포가 다른 확률분포와 얼마나 다른지를 측정하는 방법입니다. 따라서 우리는 이미지의 확률분포가 정규분포를 따른다는 가정을 하고 KLdivergence_Loss 항을 통해 VAE가 생성해낸 확률분포를 정규 분포와 비교하면서 생성 확률분포가 정규분포와 유사하게 되도록 학습할 수 있습니다. 최종적으로 생성되는 이미지의 확률분포와 정규분포가 유사해지면 이미지 데이터가 확률적으로 존재하는 구간을 알게 되는 것이기 때문에 그 구간에서 여러가지 원본과 다른 이미지들을 샘플링 할 수 있습니다.
한 점과 유사한 데이터가 분포하는 구간을 추종하는 : VAE_loss = AE_loss + KL_divergence_loss
KLdivergence 항을 생성하기에는 여러가지 수학적 증명과 가정들이 필요하기 때문에 이것에 대한 설명은 제외하고 전체 total_loss 함수를 구하는 방법만 말씀드리겠습니다.
1) 가정 : 이미지는 Feature값을 확률 분포로 하는 정규분포를 따른다.
아래 그림에서 x,y축 들은 latent vector 원소 값들을 z축은 이미지가 만들어질 확률을 의미합니다.
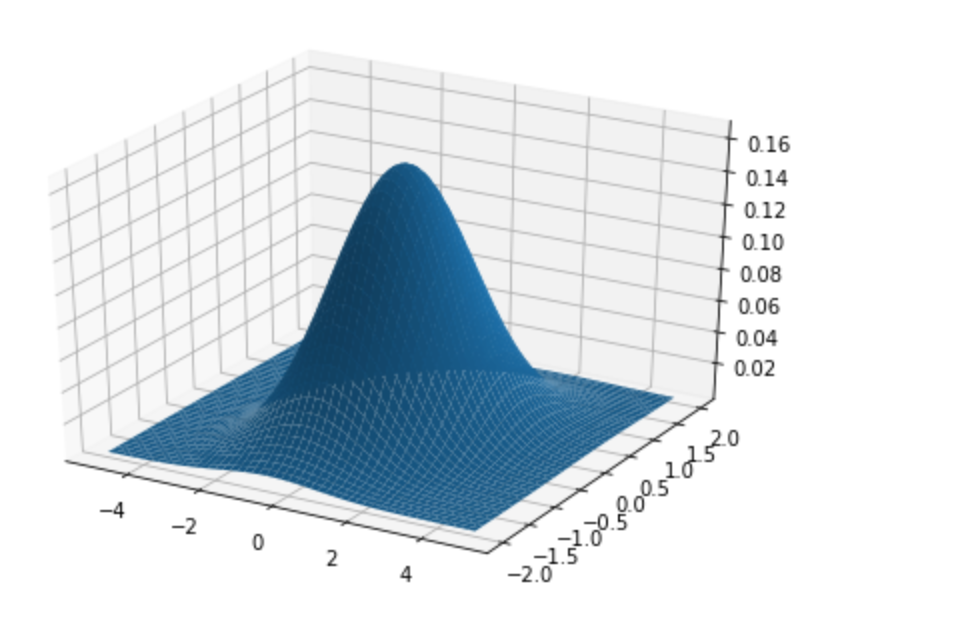
2) 각 이미지의 전체 픽셀 값들의 평균, 분산을 구한 뒤 실제 이미지의 확률분포를 생성
3) kl_loss = -0.5 * ( 1 + log_var - mu^2 - exp(log_var))로 계산
(정규분포와 얼마나 차이가 존재하는지 알아보는 척도)
4) 생성된 확률 분포에서 값을 샘플링(적당히 input과 비슷한 이미지) 해서 이 값과 input이미지를 비교해서 meansquared_error 계산
(예측 중인 확률분포에서 값을 샘플링해서 input과 비교하여 얼마나 차이 나는지 알아보는 척도)
5) total_loss = meansquared_error + kl_loss 로 계산후 가중치 역전파 실시
결론적으로 VAE는 위의 두 가지 Loss 항을 가지고 데이터가 존재하는 구간을 찾고 우리는 데이터가 존재하는 구간에서 여러가지 데이터를 샘플링 함으로써 원본과 같진 않지만 유사한 이미지들을 얻을 수 있습니다.
VAE의 장점으로는 확률적으로 계산을 하다보니 코드를 유연하고 간단하게 짤 수 잇습니다.
하지만 VAE의 단점으로는 확률적으로 이미지를 추출하다보니 추출되는 이미지의 그럴듯함이 GAN이나 다른 모델에 비해 떨어지게 됩니다.
2. VAE 생성 및 학습 실습
(이미지 생성이다 보니 Convolution layer를 쓰는 VAE모델을 가져왔습니다.)
1) VAE 모델 정의
class VariationalEncoder(nn.Module):
def __init__(self, latent_dims):
super(VariationalEncoder, self).__init__()
self.conv1 = nn.Conv2d(1, 8, 3, stride=2, padding=1)
self.conv2 = nn.Conv2d(8, 16, 3, stride=2, padding=1)
self.batch2 = nn.BatchNorm2d(16)
self.conv3 = nn.Conv2d(16, 32, 3, stride=2, padding=0)
self.linear1 = nn.Linear(18432, 128)
self.linear2 = nn.Linear(128, latent_dims)
self.linear3 = nn.Linear(128, latent_dims)
self.N = torch.distributions.Normal(0, 1)
self.N.loc = self.N.loc.cpu()
self.N.scale = self.N.scale.cpu()
self.kl = 0
def forward(self, x):
x = x.to(device)
x = F.relu(self.conv1(x))
x = F.relu(self.batch2(self.conv2(x)))
x = F.relu(self.conv3(x))
x = torch.flatten(x, start_dim=1)
x = F.relu(self.linear1(x))
mu = self.linear2(x)
logvar = self.linear3(x)
sigma = torch.exp(logvar)**0.5
z = mu + sigma*self.N.sample(mu.shape)
self.kl = -0.5*torch.sum(1+logvar-mu.pow(2)-logvar.exp())
return z
class Decoder(nn.Module):
def __init__(self, latent_dims):
super().__init__()
self.decoder_lin = nn.Sequential(
nn.Linear(latent_dims, 128),
nn.ReLU(True),
nn.Linear(128, 18432),
nn.ReLU(True)
)
self.unflatten = nn.Unflatten(dim=1, unflattened_size=(32, 24, 24))
self.decoder_conv = nn.Sequential(
nn.ConvTranspose2d(32,out_channels=16, kernel_size=3, stride=2, output_padding=1),
nn.BatchNorm2d(16),
nn.ReLU(True),
nn.ConvTranspose2d(16, out_channels=8, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.BatchNorm2d(8),
nn.ReLU(True),
nn.ConvTranspose2d(8, out_channels=1, kernel_size=3, stride=2, padding=1, output_padding=1)
)
def forward(self, x):
x = self.decoder_lin(x)
x = self.unflatten(x)
x = self.decoder_conv(x)
x = torch.sigmoid(x)
return x
class VariationalAutoencoder(nn.Module):
def __init__(self, latent_dims):
super().__init__()
self.encoder = VariationalEncoder(latent_dims)
self.decoder = Decoder(latent_dims)
def forward(self, x):
x = x.to(device)
z = self.encoder(x)
return self.decoder(z)2) one-epoch 시 활용하는 학습 함수
--------------------------------------------------------
###Training function
def train_epoch(vae, device, dataloader, optimizer):
vae.train()
train_loss = 0.0
for x, _ in dataloader:
x = x.to(device)
x_hat = vae(x)
loss = ((x - x_hat)**2).sum() + vae.encoder.kl
# Backward pass
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Print batch loss
print('\t partial train loss (single batch): %f' % (loss.item()))
train_loss+=loss.item()
return train_loss / len(dataloader.dataset)
----------------------------------------------------------------3) 실제 train 실시
---------------------------------------------------
## 실제 train 실시
for epoch in range(num_epochs):
train_loss = train_epoch(vae,device,train_dataloader,optim)
val_loss = test_epoch(vae,device,val_dataloader)
print('\n EPOCH {}/{} \t train loss {:.3f} \t val loss {:.3f}'.format(epoch + 1, num_epochs,train_loss,val_loss))
torch.save(vae.state_dict(),save_path)
--------------------------------------------------VAE엔코더,디코더 클래스를 순서대로 만들고 전체 VAE클래스에서 엔코더, 디코더를 연결해줍니다.
1) 엔코더 클래스
엔코더 부분을 보면 Convolution layer들을 거치면서 정보를 압축하고 linear layer들을 거친 뒤 이미지의 분포 생성을 위해 필요한 평균(mu), 분산(logvar)를 계산하게 됩니다. 여기서는 latent vector를 4로 설정했기 때문에 5차원의 정규 분포가 그려질 것 입니다. 또한 평균과 분산을 각각의 linear layer에서 추출된 값을 이용해 계산합니다. 이미지에 대한 정보가 함축되어 있는 값들이며 각각 추출하는 것은 random한 요소를 넣기 위함입니다. 그리고 계산한 평균과 분산을 가지고 kl_loss 항을 계산합니다. 또한 분산과 평균을 가지고 생성한 정규 분포에 정보가 latent vector만큼 함축된 feature map을 랜덤으로 샘플링해서 가져옵니다.(일반 AE_loss 계산 시 활용)
2) 디코더 클래스
엔코더에서 표준정규분포를 통해 샘플링한 feature map 값을 엔코더와 동일한 아키텍쳐로 함축된 정보를 디코딩합니다.
3) VAE 클래스
데이터가 엔코더를 거치고 디코를 거친 뒤 결과를 도출할 수 있도록 연결시켜 줍니다.
4) train_epoch 함수
1epoch당 학습하는 함수입니다. loss항을 계산하기 위해 엔코더에서 샘플링 해온 피처맵을 디코딩하여 x_hat 이미지로 도출한 뒤 input 이미지와 비교하여 일반적인 mean_squared_loss항(AE_loss항)을 계산한 뒤 엔코더에서 계산했던 KL_Divergence_loss 항을 더하여 loss함수를 완성합니다. 그리고 완성한 loss함수를 역전파 하면서 모델을 학습시킵니다.
3. VAE 결과
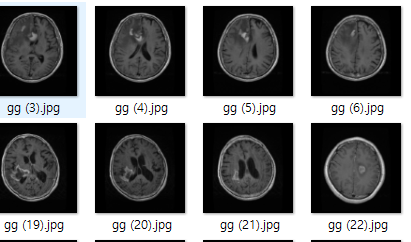
1. 실제에 존재하는 input 이미지
2. 이미지 생성 확률 분포를 학습하고 임의적으로 샘플링한 결과
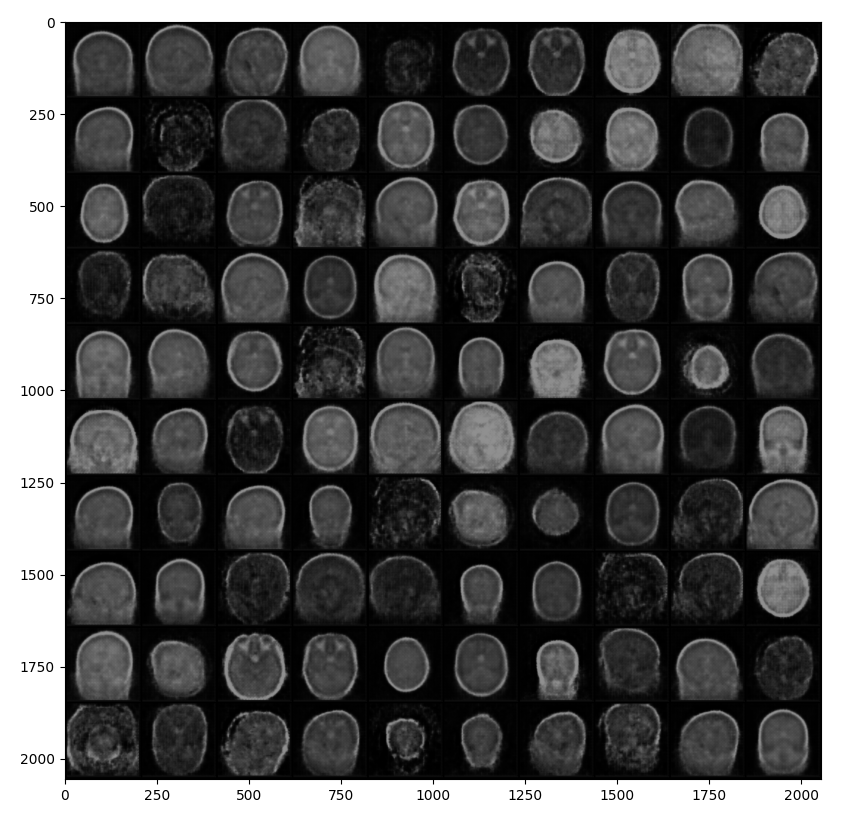
생성된 모델을 보면 언듯 보면 그럴듯 하긴 하지만 자세하게 보면 뭔가 많이 부족한 그림인걸 알 수 있습니다. 확률적으로 이미지를 추출하다보니 추출되는 이미지의 디테일이 상당히 떨어지는 것을 확인할 수 있습니다. 뭔가 계란 같네요 그냥...
4. 전체코드
import os
import torch
import torchvision
import numpy as np
import pandas as pd
import torch.nn as nn
import albumentations as A
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import nn
from PIL import Image
from torch.utils.data import DataLoader
from torch.utils.data import Dataset, DataLoader
from albumentations.pytorch.transforms import ToTensorV2
# dataset class
class dataset(Dataset):
def __init__(self, data):
self.x = data["numpy"]
self.y = data["label"]
def __len__(self):
return len(self.y)
def __getitem__(self, index):
single_x = self.x[index]
single_y = self.y.iloc[index]
single_y = torch.tensor(single_y)
self.augmentor = self.augmentation()
augmented = self.augmentor(image=single_x)["image"]
normalizated = self.normalization(augmented)
return normalizated, single_y
def augmentation(self):
pipeline = []
pipeline.append(A.HorizontalFlip(p=0.5))
pipeline.append(A.RandomBrightnessContrast(p=0.5))
pipeline.append(A.Resize(height=200,width=200))
pipeline.append(ToTensorV2(transpose_mask=True, p=1))
return A.Compose(pipeline, p=1)
def normalization(self, array):
normalizated_array = (array - array.min()) / (array.max() - array.min())
return normalizated_array
def split_feature_label(file_path):
label = file_path.split("\\")[1]
img = Image.open(file_path).convert("L")
img_array = np.array(img, dtype=np.uint8)
return img_array, label
def fileopen_splitdata_labeling(dir):
train_data = {"numpy": [], "label": []}
val_data = {"numpy": [], "label": []}
test_data = {"numpy": [], "label": []}
train_shape = np.zeros(2)
val_shape = np.zeros(2)
test_shape = np.zeros(2)
test_path = []
for (directory, _, filenames) in os.walk(dir):
if "Training" in directory:
for filename in filenames:
if ".jpg" in filename:
file_path = os.path.join(directory, filename)
img_array, label = split_feature_label(file_path=file_path)
train_shape = train_shape + img_array.shape
train_data["numpy"].append(img_array)
train_data["label"].append(label)
elif "Validation" in directory:
for filename in filenames:
if ".jpg" in filename:
file_path = os.path.join(directory, filename)
img_array, label = split_feature_label(file_path=file_path)
val_shape = val_shape + img_array.shape
val_data["numpy"].append(img_array)
val_data["label"].append(label)
elif "Testing" in directory:
for filename in filenames:
if ".jpg" in filename:
file_path = os.path.join(directory, filename)
test_path.append(file_path)
img_array, label = split_feature_label(file_path=file_path)
test_shape = test_shape + img_array.shape
test_data["numpy"].append(img_array)
test_data["label"].append(label)
train_data["label"] = pd.get_dummies(train_data["label"])
val_data["label"] = pd.get_dummies(val_data["label"])
test_data["label"] = pd.get_dummies(test_data["label"])
train_avg_shape = train_shape / len(train_data["numpy"])
val_avg_shape = val_shape / len(val_data["numpy"])
test_avg_shape = test_shape / len(test_data["numpy"])
print(f"\n\n###데이터 셋 별 평균 이미지 크기 확인###\n!!!!WARNING!!!!")
print(f"1. train데이터 평균 이미지 크기 : {train_avg_shape}")
print(f"2. val데이터 평균 이미지 크기 : {val_avg_shape}")
print(f"3. test데이터 평균 이미지 크기 : {test_avg_shape}")
return train_data, val_data, test_data,test_path
class VariationalEncoder(nn.Module):
def __init__(self, latent_dims):
super(VariationalEncoder, self).__init__()
self.conv1 = nn.Conv2d(1, 8, 3, stride=2, padding=1)
self.conv2 = nn.Conv2d(8, 16, 3, stride=2, padding=1)
self.batch2 = nn.BatchNorm2d(16)
self.conv3 = nn.Conv2d(16, 32, 3, stride=2, padding=0)
self.linear1 = nn.Linear(18432, 128)
self.linear2 = nn.Linear(128, latent_dims)
self.linear3 = nn.Linear(128, latent_dims)
self.N = torch.distributions.Normal(0, 1)
self.N.loc = self.N.loc.cpu()
self.N.scale = self.N.scale.cpu()
self.kl = 0
def forward(self, x):
x = x.to(device)
x = F.relu(self.conv1(x))
x = F.relu(self.batch2(self.conv2(x)))
x = F.relu(self.conv3(x))
x = torch.flatten(x, start_dim=1)
x = F.relu(self.linear1(x))
mu = self.linear2(x)
logvar = self.linear3(x)
sigma = torch.exp(logvar)**0.5
z = mu + sigma*self.N.sample(mu.shape)
self.kl = -0.5*torch.sum(1+logvar-mu.pow(2)-logvar.exp())
return z
class Decoder(nn.Module):
def __init__(self, latent_dims):
super().__init__()
self.decoder_lin = nn.Sequential(
nn.Linear(latent_dims, 128),
nn.ReLU(True),
nn.Linear(128, 18432),
nn.ReLU(True)
)
self.unflatten = nn.Unflatten(dim=1, unflattened_size=(32, 24, 24))
self.decoder_conv = nn.Sequential(
nn.ConvTranspose2d(32,out_channels=16, kernel_size=3, stride=2, output_padding=1),
nn.BatchNorm2d(16),
nn.ReLU(True),
nn.ConvTranspose2d(16, out_channels=8, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.BatchNorm2d(8),
nn.ReLU(True),
nn.ConvTranspose2d(8, out_channels=1, kernel_size=3, stride=2, padding=1, output_padding=1)
)
def forward(self, x):
x = self.decoder_lin(x)
x = self.unflatten(x)
x = self.decoder_conv(x)
x = torch.sigmoid(x)
return x
class VariationalAutoencoder(nn.Module):
def __init__(self, latent_dims):
super().__init__()
self.encoder = VariationalEncoder(latent_dims)
self.decoder = Decoder(latent_dims)
def forward(self, x):
x = x.to(device)
z = self.encoder(x)
return self.decoder(z)
### Training function
def train_epoch(vae, device, dataloader, optimizer):
vae.train()
train_loss = 0.0
for x, _ in dataloader:
x = x.to(device)
x_hat = vae(x)
loss = ((x - x_hat)**2).sum() + vae.encoder.kl
# Backward pass
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Print batch loss
print('\t partial train loss (single batch): %f' % (loss.item()))
train_loss+=loss.item()
return train_loss / len(dataloader.dataset)
def test_epoch(vae, device, dataloader):
vae.eval()
val_loss = 0.0
with torch.no_grad():
for x, _ in dataloader:
x = x.to(device)
encoded_data = vae.encoder(x)
x_hat = vae(x)
loss = ((x - x_hat)**2).sum() + vae.encoder.kl
val_loss += loss.item()
return val_loss / len(dataloader.dataset)
def show_image(img):
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
if __name__ == "__main__":
dir = "./Brain Tumor MRI Classfication/"
save_path = "./model/brain_tumor_epoch30.pt"
train_data, val_data, test_data,test_path = fileopen_splitdata_labeling(dir=dir)
class_num = len(set(train_data["label"]))
train_dataset = dataset(train_data)
val_dataset = dataset(val_data)
test_dataset = dataset(test_data)
print("\n###데이터셋 정의완료###")
train_batch = 32
val_batch = 1
test_batch = 1
lr = 0.00001
step_size = 30
gamma = 0.01
total_epoch = 1
train_dataloader = DataLoader(train_dataset, batch_size=train_batch,shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=val_batch)
test_dataloader = DataLoader(test_dataset, batch_size=test_batch)
torch.manual_seed(0)
d = 4
vae = VariationalAutoencoder(latent_dims=d)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
print(f'Selected device: {device}')
vae.to(device)
signal = input(str("if you want to train press y or n : "))
if signal == "y":
lr = 1e-3
num_epochs = 50
optim = torch.optim.Adam(vae.parameters(), lr=lr, weight_decay=1e-5)
for epoch in range(num_epochs):
train_loss = train_epoch(vae,device,train_dataloader,optim)
val_loss = test_epoch(vae,device,val_dataloader)
print('\n EPOCH {}/{} \t train loss {:.3f} \t val loss {:.3f}'.format(epoch + 1, num_epochs,train_loss,val_loss))
torch.save(vae.state_dict(),save_path)
if signal == "n":
with torch.no_grad():
vae.load_state_dict(torch.load(save_path))
latent = torch.randn(128, d, device=device)
img_recon = vae.decoder(latent)
img_recon = img_recon.cpu()
fig, ax = plt.subplots(figsize=(20, 8.5))
show_image(torchvision.utils.make_grid(img_recon.data[:100],10,5))
plt.show()5. 결론
처음으로 판별 모델이 아니라 생성모델을 통해 임의의 이미지를 생성해보았는데, 가장 기초적인 VAE모델이다 보니 디테일이 많이 떨어지는 것을 확인할 수 있었습니다. 추후에 GAN이나 디퓨전 모델을 통해 생성모델 성능을 비교해볼 것입니다.
