불량 사용자 [2019 카카오 겨울 인턴쉽] C++ DFS Set 을 이용한 풀이
처음엔 단순히 for문으로 완전탐색을 하면 풀릴 줄 알았다. 하지만 생각해보니 user_id와 banned_id의 개수는 총 8개 이하이므로
다중 for문으로는 전체 개수를 구할 수 없었다.
따라서 브루트 포스방식으로 풀려면 DFS를 적용해야했다.
2번 테스트케이스의 예로 들면
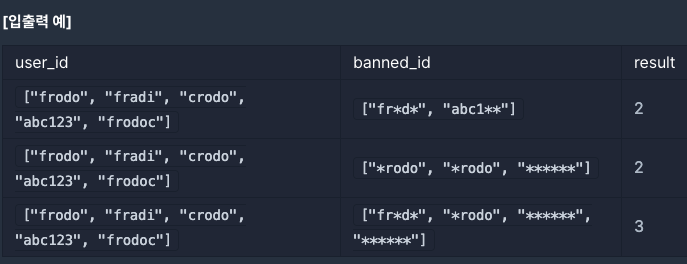
user_id의 인덱스는 0부터 4까지이고 banned_id의 인덱스는 0부터 2까지이다.
따라서
user_id의 인덱스 banned_id의 인덱스
012 0 1 2
013 0 1 2
014 0 1 2
023 0 1 2
024 0 1 2
034 0 1 2
021 0 1 2
023 0 1 2
...
102 0 1 2
103 0 1 2 이런식으로
서로 같은 문자열인지 체크한다.
*를 빼고 같은 문자열인지 포문을 돌며 한글자씩 체크한다.
user_id의 014 frodo fradi frodoc 이 rodo rodo **와 같은지 체크하는 것이다.
이경우에는 같지 않다.
만약 저 세개가 모두 같다면 vector temp; 에 넣는다.
그다음 이 벡터를 중복체크를 하기 위해 set <vector> s;에 넣는다.
만약 set에 이 벡터가 없으면 경우의 수는 1개 늘어나는 것이고
만약 set에 이 벡터가 있으면 중복되는 경우이므로 경우의 수는 늘어나지 않는다.
이렇게 set <vector> s에서 중복체크를 해주면 정답을 쉽게 구할 수 있다.
#include <string>
#include <vector>
#include <iostream>
#include <set>
#include <algorithm>
using namespace std;
vector <string> uid;
vector <string> bid;
int usize; int bsize;
int visited[8]={0,};
set <vector <string> > s;
vector <int> v;
int answer=0;
bool isSame(string a, string b)
{
if(a.size()!=b.size())
return false;
bool isFalse=0;
for(int i=0;i<a.size();i++)
{
if(b[i]=='*') continue;
if(a[i]!=b[i])
{
isFalse=1;
break;
}
}
if(isFalse==1) return false;
return true;
}
void dfs() {
if(v.size()==bsize)
{
bool isAnswer=1;
for(int i=0;i<v.size();i++)
if(!isSame(uid[v[i]],bid[i]))
{
isAnswer=0;
break;
}
if(isAnswer==1)
{
vector <string> temp;
for(int i=0;i<v.size();i++)
temp.push_back(uid[v[i]]);
sort(temp.begin(),temp.end());
if(s.find(temp)==s.end())
{
answer++;
s.insert(temp);
}
}
return;
}
for(int i=0;i<usize;i++)
{
if(visited[i]!=0) continue;
visited[i]=1;
v.push_back(i);
dfs();
v.pop_back();
visited[i]=0;
}
}
int solution(vector<string> user_id, vector<string> banned_id) {
uid=user_id; bid=banned_id;
usize=uid.size(); bsize=bid.size();
dfs();
return answer;
}