싱글톤 패턴(Singleton pattern)
public class Singleton {
private static Singleton instance = null;
//외부에서 직접 사용하지 못하게 private 지정
private Singleton() {
// 생성자는 외부에서 호출못하게 private 으로 지정
}
public static Singleton getInstance() {
if(instance == null) instance = new Singleton();
return instance;
}
public void method() {
//method implement..
}
}싱글톤 패턴은 하나의 클래스에 오직 하나의 인스턴스만 가지는 패턴이다. 보통은 하나의 클래스로, 객체가 생성되면 서로 다른 인스턴스가 각각 메모리에 할당된다. 하지만 싱글톤은 하나의 클래스를 기반으로 단 하나의 인스턴스를 만든다. 보통 데이터베이스 연결모듈에 사용된다.
장점
하나의 인스턴스를 기반으로 해당 인스턴스를 다른 모듈들이 공유하기 때문에, 인스턴스를 생성할 때, 비용이 줄어든다. 그렇기 때문에 인스턴스 생성에 많은 비용이 드는 I/O 바운드 작업에 많이 사용된다.
🔍 I/O 바운드 작업이란?
실제 객체를 생성하는 비용은 그렇게 크지 않다. 하지만 객체 생성 시, I/O 바운드를 요청할 경우 그 비용은 크다.
Network,DB,FileSystem을 요청하는 것을 I/O바운드라고 하는데, DB의 인스턴스를 생성할 경우, DB 서버에 연결을 요청 후 그 인스턴스를 반환하는 것인데, 이는 비용이 비쌀 수 밖에 없다.
단점
TDD(Test Driven Development)를 할 때, 단위테스트를 주로 사용하는데 이때 문제가 될 수 있다. 각 단위 테스트는 독립적이어야 하는데, 싱글톤 패턴은 단위 테스트를 독립적으로 수행할 수 없다.
더 자세히 말하자면, A라는 단위 테스트에서 싱글톤 인스턴스를 Write 하고, B라는 단위 테스트에서는 싱글톤 인스턴스를 Only-Read 한다고 할 때, A ➡ B의 테스트 결과와, B ➡ A의 테스트 결과는 다르게 나온다. 이는 독립적인 단위 테스트라고 볼 수 없다.
다음은 싱글톤 패턴은 멀티쓰레드(Multi Thread)환경에 매우 취약하다는 것이다.
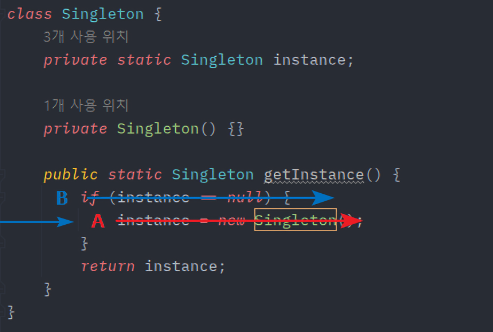
다음 코드를 보면, 멀티 쓰레드 환경에서 싱글톤 인스턴스는 2번 생성될 수 있다는 치명적인 문제점이 있다.
Dependency ?
우선 DI, DIP의 개념을 익히기 전 의존성(Dependency)가 무엇인지 알아야 한다.
다음 코드를 보자.
class B {
public void go() {
System.out.println("B의 go 함수");
}
}
class A {
public void go() {
B classB = new B();
classB.go(); //의존성
}
}
public class Test {
public static void main(String[] args) {
A classA = new A();
classA.go();
}
}
//B의 go 함수만약 클래스B의 go()의 이름이 gorani()로 바뀐다면, 클래스A의 classB.go()도 classB.gorani()로 변경되어야 한다. 이를 의존성이라고 한다.
즉, 요약하자면 B의 코드가 변경될 때, A도 변경되어야 한다면, A가 B에 의존한다는 것이다.
A ➡ B
DI(Dependeny Injection)
🧷 Spring의 의존성 주입 3가지
- 필드 주입 (@Autowired)
- Setter 주입
- 생성자 주입
의존성 주입은 class A가 class B를 참조할 때, 직접 class B를 생성하는 것이 아니라, 외부에서 'class B'인스턴스를 생성하고 주입 받는 것을 의미한다!!
우선 현재 코드 예시는 생성자 주입 방식의 의존성 주입이다.
class FrontendDeveloper {
public void writeJavaScript() {
System.out.println("자바스크립트로 코딩");
}
}
class BackendDeveloper {
public void writeJava() {
System.out.println("자바로 코딩");
}
}
public class Project {
private final FrontendDeveloper frontendDeveloper;
private final BackendDeveloper backendDeveloper;
public Project(FrontendDeveloper frontendDeveloper,
BackendDeveloper backendDeveloper) {
this.frontendDeveloper = frontendDeveloper;
this.backendDeveloper = backendDeveloper;
}
public void implement() {
frontendDeveloper.writeJavaScript(); //Dependency
backendDeveloper.writeJava(); //Dependency
}
public static void main(String[] args) {
Project project = new Project(new FrontendDeveloper(),
new BackendDeveloper());
project.implement();
}
}
//자바스크립트로 코딩
//자바로 코딩위 코드에서, FrontendDeveloper 클래스의 writeJavaScipt()함수의 이름이 변경되거나, BackendDeveloper 클래스의 writeJava()함수의 이름이 변경되면, Project 클래스의 implement()도 변경해야 한다.
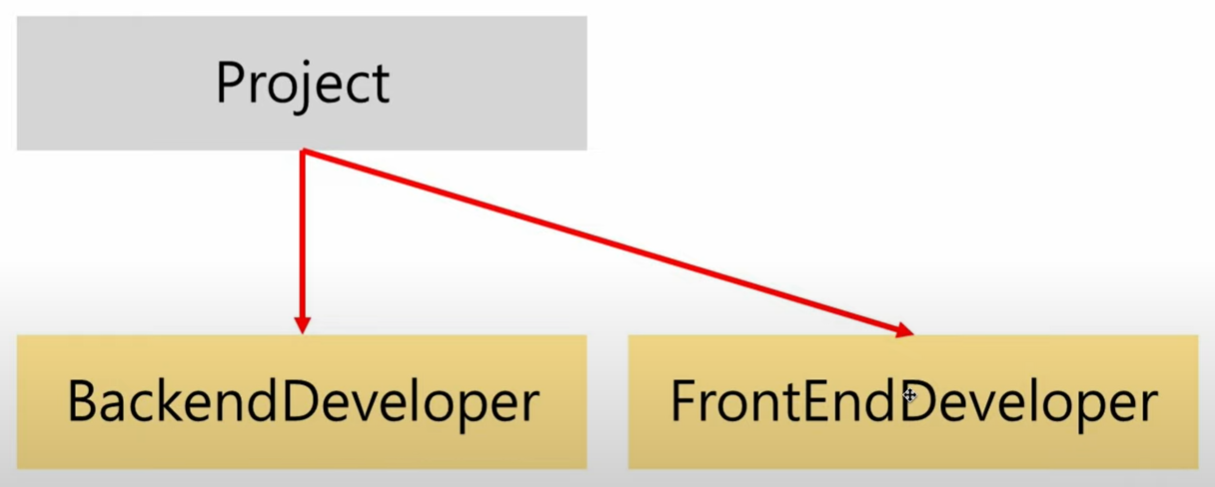
따라서, 다음과 같은 의존 관계이다. 이는 Project라는 상위 모듈이 BackendDeveloper와 FrontendDeveloper라는 하위 모듈에 의존하고 있다.
또한, Project클래스는 생성자를 통해 의존성을 주입하였다.
하지만 위 코드는 Project가 BackendDeveloper나 FrontendDeveloper에 강하게 결속된다는 단점이 있다. 이 문제는 DIP(의존 역전 원칙)을 통해 해결할 수 있다.
DIP(Dependecy Inversion Principle)
interface Developer {
void develop();
}
class FrontendDeveloper implements Developer {
@Override
public void develop() {
writeJavaScript();
}
public void writeJavaScript() {
System.out.println("자바스크립트로 코딩");
}
}
class BackendDeveloper implements Developer {
@Override
public void develop() {
writeJava();
}
public void writeJava() {
System.out.println("자바로 코딩");
}
}
public class Project {
private final List<Developer> developers;
public Project(List<Developer> developers) {
this.developers = developers;
}
public void implement() {
developers.forEach(Developer::develop);
}
public static void main(String[] args) {
List<Developer> developers = new ArrayList<>();
developers.add(new FrontendDeveloper());
developers.add(new BackendDeveloper());
Project project = new Project(developers);
project.implement();
}
}
//자바스크립트로 코딩
//자바로 코딩위 코드에서, FrontendDeveloper 클래스의 writeJavaScipt()함수의 이름이 변경되거나, BackendDeveloper 클래스의 writeJava()함수의 이름이 변경되어도 Project 클래스의 implement()는 변경할 필요가 없다.
이는 다음과 같은 의존도를 나타나기 때문이다.
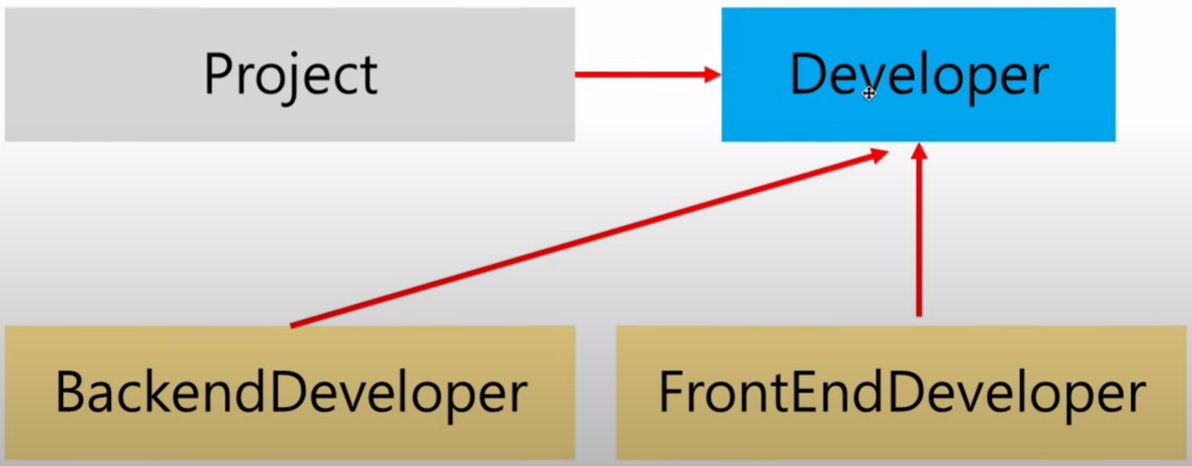
Project라는 상위 모듈이 Devloper라는 추상화 된 인터페이스에 의존하고 있고, 하위 모듈인 BackendDeveloper와 FrontendDeveloper 역시 Devloper에 의존하고 있다.
기존의 상위 모듈 ➡ 하위 모듈의 관계가 상위 모듈 ➡ 추상화 ⬅ 하위 모듈로 역전되었기 때문에, DIP(의존 역전 원칙)이라고 부른다.
📘의존관계역전원칙
- 상위 모듈은 하위 모듈에 의존해서는 안 된다. 둘 다 추상화에 의존해야 한다.
- 추상화는 세부사항에 의존해서는 안 된다. 세부 사항은 추상화에 따라 달라져야 한다.
DI, DIP의 차이
처음에 DI, DIP를 이해하기로는 DI, DIP는 전혀 다른 개념으로, DI를 적용하면 상위모듈 → 하위모듈을 의존하는 문제점이 발생하는데, 이를 해결하기 위한 방법이 DIP로만 받아들였다. 하지만 이것도 틀린 것은 아니라고 생각한다.
하지만 더 정확한 개념을 이해하자면, DI 는 DIP 를 구현하는 기법 중 하나일 뿐 서로 같은 개념이 아니다. 굳이 포함관계를 말하자면, DI ⊂ DIP이다.
큰 틀로 비유하자면, DI는 컴포넌트들 간의 의존성을 줄이면서 유연,확장 가능한 코드를 작성하기 위한 설계 패턴 중 하나다. 다시 말하면, DI는 생성자 주입, Setter 주입, 필드 주입과 같은 방식이 존재하며, 이러한 방식들은 구현의 방법에 가까운 내용이다.
그에 반해, DIP는 SOLID의 원칙 중 하나로, 소프트웨어 디자인 원칙 중 하나 입니다. 위에서 언급했던 DIP의 2가지 원칙이 있듯이, DIP는 원칙 혹은 패턴 등과 더 관련되어 있는 내용이라고 생각하면 된다.

이렇게 유용한 정보를 공유해주셔서 감사합니다.