
개요
- 물리적 구조
- I/O 순서 스케줄링
- 장치 포맷팅과 부트 블록, 손상된 블록 및 스왑 공간의 관리
- RAID 시스템의 구조
11.1 대용량 저장장치의 구조 개관
HDD
암을 원하는 실린더로 이동하는 탐색시간과,
원하는 섹터가 헤드까지 회전하는 데 걸리는 회전 지연시간이 필요하다.
드라이브 컨트롤러에 DRAM 버퍼를 사용하여 성능을 향상한다.
DRAM이란?
DRAM(Dynamic Random Access Memory)은 컴퓨터에서 사용하는 주요 형태의 RAM입니다.
DRAM은 메모리 셀이 데이터를 저장할 때,
각 셀이 하나의 비트를 저장하는 방식으로 작동합니다.
이 데이터는 소량의 전기가 충전되어 있는 콘덴서로 저장되며,
이 충전 상태는 '0' 또는 '1'의 이진 코드로 해석됩니다.
하지만 DRAM의 주요 단점 중 하나는 콘덴서가 지속적으로 방전되는 성질 때문에
데이터가 지속되도록 주기적으로 '새로 고침'이 필요하다는 것입니다.
이것이 DRAM이 '동적'이라는 이름을 가진 이유입니다.
SRAM과 DRAM
SRAM과 DRAM은 컴퓨터 시스템에서 사용되는 두 가지 유형의 RAM입니다.
둘 다 데이터를 일시적으로 저장하는데 사용되지만,
구조와 성능 측면에서 몇 가지 중요한 차이점이 있습니다.
-
DRAM(Dynamic Random Access Memory):
DRAM은 데이터를 저장하는 데 커패시터를 사용합니다.
커패시터는 일정 시간 동안 충전 상태를 유지할 수 있지만,
시간이 지나면 충전이 방전되기 시작합니다.
이로 인해 DRAM은 데이터를 유지하기 위해 주기적인 리프레시가 필요합니다.
DRAM은 SRAM보다 느리지만,
더 적은 공간을 차지하고 비용이 더 적게 듭니다.
DRAM은 컴퓨터의 주 메모리에 주로 사용됩니다. -
SRAM(Static Random Access Memory):
SRAM은 데이터를 저장하는 데 플립플롭 회로를 사용합니다.
이로 인해 SRAM은 데이터를 저장하기 위해 지속적인 전력 공급이 필요하지만,
리프레시가 필요하지 않습니다.
SRAM은 DRAM에 비해 빠르지만,
더 많은 공간을 차지하고 비용이 더 많이 듭니다.
SRAM은 주로 CPU의 캐시 메모리에 사용됩니다.
결론적으로,
SRAM과 DRAM은 각각의 특성 때문에 다른 용도로 사용됩니다.
SRAM은 빠른 속도가 필요한 곳에서,
DRAM은 대량의 데이터를 저렴하게 저장해야 하는 곳에서 주로 사용됩니다.
NVM(nonvolatile memory device
플래시 메모리 기반 NVM은 SSD(solid-state disk)라고 한다.
NVM장치는 움직이는 부품이 없어 안정성이 높고
탐색시간이나 지연시간이 없어 더 빠르다.
페이지 단위로 읽고 쓸 수 있고
삭제는 블록(페이지가 여러개 모인)단위로 가능하다.
garbage collect
NVM(Non-Volatile Memory)은 전원을 끄더라도 데이터를 유지할 수 있는 메모리 유형을 말합니다.
NAND 플래시와 같은 NVM은 SSD(Solid State Drive)와 같은 저장장치에 주로 사용됩니다.
NVM은 전통적인 하드디스크와 달리,
데이터를 덮어쓰는 것이 아닌 새로운 위치에 데이터를 쓰고 이전 데이터를 무효화합니다.
이런 동작 방식 때문에 사용되지 않는 블록이 생기게 되며,
이러한 블록들을 재활용하기 위한 과정이 필요한데,
이 과정을 가비지 컬렉션(Garbage Collection)이라고 합니다.
NVM의 가비지 수집 과정은 다음과 같습니다:
- NVM 컨트롤러는 사용되지 않는 블록(즉, 무효화된 데이터가 있는 블록)을 식별합니다.
- 사용되지 않는 블록에 있는 유효한 데이터를 다른 곳으로 이동합니다. 이 과정을 '데이터 이주'라고 부릅니다.
- 데이터 이주가 완료되면, 이제 더 이상 유효한 데이터를 가지고 있지 않은 블록을 삭제(erase)합니다. 이제 이 블록은 새로운 데이터를 저장하기 위해 사용될 수 있습니다.
이러한 가비지 수집 과정은 NVM의 수명과 성능에 중요한 역할을 합니다.
가비지 수집이 잘 이루어지지 않으면 NVM의 사용 가능한 공간이 줄어들고,
쓰기 성능이 저하될 수 있습니다.
그러나 가비지 수집 과정 자체도 리소스를 사용하고 추가적인 쓰기 연산을 발생시키므로,
이를 효율적으로 관리하는 것이 중요합니다.
NAND 반도체는 왜 쓰기 횟수가 정해져있어?
NAND 플래시 메모리는
데이터를 저장하고 삭제하는 과정에서 물리적인 변화가 일어나기 때문에 쓰기 횟수가 제한적입니다.
데이터를 저장하거나 삭제할 때마다,
NAND 플래시 메모리 셀의 반도체 소재에 전기를 통하게 됩니다.
이때 발생하는 전기적인 에너지는 소재를 매우 높은 온도로 가열시키며,
이러한 반복적인 가열과 냉각 과정은 소재에 물리적인 손상을 일으킵니다.
따라서 메모리 셀이 지속적으로 쓰고 지워질수록,
이런 손상이 누적되어 결국은 셀이 더 이상 정확하게 데이터를 저장하거나 검색할 수 없게 됩니다.
특히, 쓰기 연산은 각 셀에 저장된 전자를 제거하는 프로세스로,
셀에 가장 큰 손상을 입히는 원인입니다.
이로 인해 NAND 플래시 메모리의 수명은 주로 "쓰기 사이클" 또는 "프로그램/삭제(P/E) 사이클"의 수로 측정됩니다.
이는 셀이 안전하게 쓰고 지울 수 있는 횟수를 의미합니다.
그러나 이러한 한계는 NAND 플래시의 기술 개선과 함께 점차 개선되고 있으며,
또한 플래시 메모리 관리 알고리즘(예: 웨어 레벨링)은 셀의 고르지 않은 사용을 최소화하고
전체 플래시의 수명을 연장하는데 도움을 줍니다.
과잉 공급(over-provisioning)
NVM장치는 언제나 쓸 수 있도록 다수의 페이지(종종 전체 용량의 20%)를 따로 준비해 놓는다.
RAM 드라이브가 뭐야?
RAM 드라이브(또는 RAM 디스크)는 컴퓨터의 주 기억 장치인 RAM을 마치 디스크 드라이브처럼 사용하는 기술을 말합니다.
이는 컴퓨터 시스템의 RAM에서 일정한 공간을 분할하여,
그 공간에 데이터를 저장하고 디스크 드라이브처럼 접근하는 것을 가능하게 합니다.
RAM 드라이브의 장점 중 하나는 속도입니다.
RAM은 하드 드라이브나 SSD와 비교했을 때 훨씬 빠른 속도를 보입니다.
따라서 RAM 드라이브에 데이터를 저장하면 데이터의 읽기/쓰기 속도가 크게 향상되므로,
특히 빠른 응답 시간이 필요한 애플리케이션에 유용합니다.
그러나 RAM 드라이브에는 두 가지 주요한 한계가 있습니다.
첫째, RAM은 비휘발성 메모리가 아닙니다.
즉, 전원을 끄면 RAM에 저장된 모든 데이터가 사라집니다.
둘째, RAM은 비교적 고가의 리소스입니다.
따라서 대용량의 데이터를 저장하기에는 비효율적일 수 있습니다.
이런 이유로,
RAM 드라이브는 일반적으로 특정 유형의 데이터나 애플리케이션에 대한 임시 저장 공간으로 사용됩니다.
예를 들어, 시스템 캐시, 임시 파일, 특정 애플리케이션의 데이터베이스 등에 활용됩니다.
보조저장장치 연결 방법
보조저장장치는 일반적으로 SATA(serial advanced technology attachment)라는 버스를 통해 컴퓨터에 연결된다.
NVMe(NVM express)는 시스템 PCI버스에 직접 연결하여 처리량을 높이고 지연시간을 줄였다.
PCI버스가 뭐야?
PCI(Peripheral Component Interconnect) 버스는 개인용 컴퓨터에서 가장 일반적으로 사용되는 하드웨어 인터페이스입니다.
이것은 1990년대에 인텔에 의해 도입되었으며,
다양한 장치들이 컴퓨터의 주요 부품들과 소통하도록 하는 표준 연결 방식을 제공합니다.
PCI 버스는 주로 컴퓨터의 마더보드에 직접 장착되는 추가 하드웨어 컴포넌트들,
예를 들어 그래픽 카드, 사운드 카드, 네트워크 카드 등을
컴퓨터의 메인 프로세서(CPU)와 메모리에 연결하는 데 사용됩니다.
PCI 버스의 주요 장점 중 하나는 "플러그 앤 플레이" 기능입니다.
이는 사용자가 하드웨어를 컴퓨터에 추가하거나 제거할 때 소프트웨어 구성을 수동으로 변경할 필요 없이
운영 체제가 자동으로 장치를 인식하고 설정할 수 있음을 의미합니다.
이것은 하드웨어의 설치 및 관리를 대폭 단순화합니다.
PCI 버스는 시간이 지남에 따라 PCI Express(또는 PCIe)와 같은 더 빠르고 더 유연한 기술로 대체되었습니다. PCI Express는 각 장치가 전용 통신 경로를 갖도록 설계되었으며,
이로 인해 더 높은 데이터 전송 속도를 제공합니다.
LBA가 뭐야?
LBA(Logical Block Addressing)는 컴퓨터 하드 디스크 드라이브, 플래시 메모리 등의 데이터 스토리지 장치에서 데이터의 위치를 참조하는 방법 중 하나입니다.
전통적으로, 하드 드라이브에 저장된 데이터의 위치는 실린더, 헤드, 섹터 (CHS) 라는 세 가지 물리적 좌표를 사용하여 지정되었습니다.
이 방법은 하드 드라이브의 구조와 밀접하게 연관되어 있었으며,
특히 초기의 작은 용량의 드라이브에서는 잘 작동하였습니다.
그러나 데이터 스토리지 기술이 발전하면서,
CHS 주소 지정 방식의 한계가 뚜렷하게 드러났습니다.
이 방법은 드라이브의 물리적 구조에 너무 많이 의존하였으며,
특히 용량이 큰 현대의 하드 드라이브에서는 비효율적이었습니다.
LBA는 이러한 문제를 해결하기 위해 도입된 개념으로,
데이터의 위치를 단순한 선형 목록으로 나타냅니다.
각 블록(또는 섹터)에는 고유한 숫자가 할당되며,
이 숫자는 0에서 시작하여 드라이브의 끝까지 증가합니다.
이렇게 하면 용량이 큰 드라이브에서도 효율적인 데이터 접근이 가능하게 됩니다.
오늘날 대부분의 하드 드라이브 및 플래시 스토리지 장치는 LBA를 사용하여 데이터를 주소 지정합니다.
11.2 디스크 스케줄링
디스크에 온 요청을 큐에 담아 스케줄링한다.
디스크 스케줄링은 디스크 I/O 요청을 어떤 순서로 처리할지 결정하는 작업으로
디스크 헤드의 움직임을 최소화하여 전체 성능을 향상시키는 데에 목적이 있다.
SCAN 스케줄링
디스크 암이 와이퍼처럼 한쪽 끝에서 다른쪽 끝으로 지잉지잉 반복하여 움직이며 가는 길에 있는 요청을 처리한다.
이는 엘리베이터 알고리즘이라고도 불린다.
C-SCAN 알고리즘(circular-SCAN)
각 요청의 처리시간을 좀 더 균등하게 하기 위한 SCAN의 변형이다.
원처럼 한쪽 끝에 다다르면 처음 시작했던 자리로 돌아가서 서비스를 시작한다.
deadline 스케줄러
"Deadline Scheduler"는 디스크 스케줄링 알고리즘 중 하나로,
각 디스크 요청에 대해 정해진 "마감 시간"을 부여하고,
이 마감 시간이 가장 급한 요청부터 처리하는 방식을 사용합니다.
예를 들어, 디스크 요청 A, B, C가 있고, 각각의 마감 시간이 각각 5초, 10초, 3초라고 가정합시다. 그럼 이 경우 Deadline Scheduler는 C, A, B 순서로 요청을 처리합니다.
이 알고리즘의 주요 목표는 디스크 요청들이 지정된 마감 시간 내에 완료될 수 있도록 하는 것입니다.
따라서 실시간 시스템에서 많이 사용되는데,
이런 시스템들에서는 각 작업이 특정 시간 내에 완료되어야 하므로 Deadline Scheduler가 유용할 수 있습니다.
하지만 이 알고리즘은 마감 시간을 충족시키는 것을 최우선으로 하므로,
디스크 헤드의 움직임을 최소화하는 등의 다른 최적화를 무시할 수 있다는 단점도 있습니다.
따라서 애플리케이션의 요구 사항과 디스크의 특성에 따라 적절한 스케줄링 알고리즘을 선택해야 합니다.
CFQ 스케줄러
SATA 드라이브의 디폴트 스케줄러이다.
CFQ(Completely Fair Queuing) 스케줄러는 Linux에서 널리 사용되는 I/O 스케줄링 알고리즘 중 하나입니다. CFQ는 "완전히 공정한 큐잉"이라는 의미로,
이름에서 알 수 있듯이 각 프로세스에 공평하게 I/O 처리 시간을 할당하려는 목표를 가지고 있습니다.
CFQ 스케줄러는 디스크 I/O 요청을 각 프로세스 별로 분리된 큐에 넣습니다.
이후에 이들 큐를 순회하며 각 큐에서 하나의 I/O 요청을 가져와 디스크에 전달합니다.
이 방식은 모든 프로세스가 공평하게 디스크 I/O를 사용할 수 있도록 보장합니다.
또한, CFQ는 시크(seek) 연산을 최소화하도록 설계되어 있습니다.
디스크 헤드의 물리적인 움직임을 최소화함으로써 성능을 향상시키려는 목표를 가지고 있습니다.
이를 위해 CFQ는 프로세스의 I/O 요청을 가능한 한 가까운 디스크 위치에 있는 요청부터 처리합니다.
하지만, CFQ는 랜덤 I/O 액세스 패턴을 가진 워크로드에 대해선 성능이 떨어질 수 있습니다.
이런 경우에는 deadline 스케줄러나 다른 I/O 스케줄링 알고리즘이 더 적합할 수 있습니다.
11.3 NVM 스케줄링
NVM은 임의 접근이 가능해 일반적으로 간단히 FCFS 정책을 사용한다.
쓰기 증폭
데이터 쓰기를 한번 할 때, 가비지 수집에 의해 페이지 쓰기 2번, 읽기 1번을 해야함에 따른 I/O 요청 증폭을 말한다.
이는 장치의 쓰기 성능에 큰 영향을 끼친다.
11.4 오류 감지 및 수정
메모리시스템은 바이트 단위로 패리티 비트를 통해 오류를 감지했다. (짝수인지 홀수인지)
이는 체크섬의 한 형태이다.
또다른 방법으로 해시 함수를 사용하여 다중 비트 오류를 감지하는 순환 중복 검사(CRC)가 있다.
이 둘은 오류 감지만 된다.
ECC
ECC(Error Correction Code)는 오류를 검출하고, 가능하다면 자동으로 수정하는 데 사용되는 검증 방법입니다.
예를 들어, 햄밍 코드(Hamming Code)는 단일 비트 오류를 검출하고 수정할 수 있습니다.
Reed-Solomon 코드는 여러 비트 오류를 검출하고 수정할 수 있습니다.
수정은 알고리즘과 저장장치를 추가로 사용하여 수행된다.
디스크 드라이브는 섹터별 ECC를,
플래시 드라이브는 페이지당 ECC를 사용한다.
데이터를 write할 때 데이터의 모든 바이트에서 계산된 값으로 ECC가 기록된다.
이 후 데이터를 read할 때, ECC를 다시 계산해 저장된 ECC값과 비교한다.
ECC는 충분한 정보를 포함하고 있어 수정까지 할 수 있다.
복구 가능한 정도의 오류면 소프트 오류를 보고하고,
복구 불가능할 정도면 하드 오류를 보고한다.
11.5 저장장치 관리
드라이브의 초기화, 드라이브로부터의 부팅, 손상된 블록의 복구
드라이브를 사용하여 파일을 보유하려면
- 파티셔닝: 저장 장치를 논리적인 부분, 즉 파티션으로 나눕니다.
이를 통해 하나의 물리적인 저장 장치를 여러 개의 독립적인 부분으로 분할하여 관리할 수 있습니다.
-
볼륨 생성 및 관리: 볼륨을 생성하고 관리합니다.
볼륨을 생성함으로써 운영 체제는 파티션을 사용할 수 있게 됩니다. -
논리적 포매팅 또는 파일 시스템의 생성: 각 볼륨에 파일 시스템을 생성합니다.
파일 시스템은 데이터를 저장하고 검색하는 방식을 정의하는데,
운영 체제가 데이터를 효과적으로 관리하고 검색할 수 있도록 하는 역할을 합니다.
이 과정을 통해 볼륨은 사용자 데이터(파일 및 디렉토리)를 저장할 준비가 됩니다.
raw disk란?
파일 시스템 자료구조 없이 파티션을 논리 블록의 배열처럼 사용하게 하는 것
부트 프로세스
BIOS 또는 UEFI라는 펌웨어가 cpu레지스터, 장치 컨트롤러, 메인 메모리 등 하드웨어를 초기화 하고,
보조저장장치의 부트 블록에 있는 부트스트랩을 실행시킴.
부트스트랩 본체는 커널을 찾아내 시작시킨다.
부트스트랩 로더를 써서 부트 프로세스를 여러 단계로 진행하는 이유가 뭐야?
부트스트랩 로더는 컴퓨터가 부팅할 때 필요한 프로그램을 메모리로 불러오는 역할을 합니다.
이 과정은 일반적으로 여러 단계로 진행되는데, 그 이유는 아래와 같습니다:
-
초기화: 컴퓨터의 하드웨어를 초기화하는 것은 복잡한 과정이며,
이는 운영 체제를 불러오기 전에 완료되어야 합니다.
이 초기화 단계는 BIOS 또는 UEFI를 통해 진행되며,
이들은 부트스트랩 로더를 불러오는 역할을 합니다. -
단순성: 부트스트랩 로더는 운영 체제의 커널을 불러오는 역할을 합니다.
초기 로더가 단순하게 유지될수록 오류 발생 가능성이 줄어듭니다.
따라서, 복잡한 작업들은 부트스트랩 로더가 아닌, 이후 단계에서 처리하게 됩니다. -
운영 체제 선택: 컴퓨터에 여러 운영 체제가 설치된 경우,
부트스트랩 로더를 통해 사용자는 부팅하려는 운영 체제를 선택할 수 있습니다.
따라서, 부트스트랩 로더를 통해 부트 프로세스가 여러 단계로 진행되는 것은 초기화, 오류 최소화, 운영 체제 선택 등의 이점을 제공합니다.
펌웨어란?
펌웨어는 키보드, 하드 드라이브, BIOS 또는 비디오 카드와 같은 하드웨어 장치에
영구적으로 새겨지는 소프트웨어 프로그램입니다.
다른 장치와 통신하고 기본 입력/출력 작업과 같은 기능을 수행하기 위한 영구적 지침을 제공하도록 프로그래밍되어 있습니다.
손상된 블록
구형 IDE 컨트롤러를 가진 디스크는
디스크 포맷중에 디스크를 스캔하여 수동으로 검사한다.
손상된게 있으면 사용 불가로 표시해 파일시스템이 그 블록을 못쓰도록 한다.
정교한 디스크는 손상된 블록의 리스트를 관리해
예비 섹터와 교체 시킨다. (섹터 포워딩)
이는 헤드를 먼 곳으로 이동시켜 디스크 스케줄링 알고리즘을 말짱 도루묵으로 만들 수 있으므로
가능한 동일한 실린더 내에서 예비 섹터를 찾아 대체한다.
또는 섹터 밀어내기로 처리할 수도 있다. 이는 단순히 한칸씩 밀어서 쓰는것이다. (1이 고장났으면 : 1 -> 2, 2-> 3, ... 17 -> 18)
NVM은 헤더위치를 고려안해도 되므로 단순히 그냥 예비 영역을 두어 관리하면 된다.
11.6 스왑 공간 관리
드라이브는 메모리보다 훨씬 느리므로 스왑 공간의 설계와 구현은 가상 메모리 성능에 커다란 영향을 미친다.
스왑 공간이 어떻게 사용되고, 어디에 위치하며, 어떻게 관리하는지 알아보자.
스왑 공간 사용
프로세스 이미지 전체를 스왑공간에 유지하게 할 수도 있고,
일반적으로 페이지들만 저장할 수도 있다.
스왑공간은 넉넉하게 잡는게 좋다.
스왑 공간 위치
일반 파일 시스템이 차지하고 있는 공간 안에 만들 수도 있고,
별도의 파티션을 만들어 사용할 수도 있다.
스왑 공간은 별도의 raw 파티션에 만들어질 수 있는데,
이 파티션은 별도의 스왑 관리 루틴에 의해 스와핑 하는 데에만 사용된다.
스왑 공간 관리의 예
코드가 있는 텍스트 세그먼트 페이지들은 read-only이므로
데이터에 변경이 없을것이므로 번거롭게 swap-out하지 않고 바로 새로운 데이터로 덮어 써버리고,
나중에 그 내용이 필요하면 파일 시스템으로부터 읽어온다.
스왑공간은 프로세스의 스택, 힙 및 초기화되지 않은 데이터에 할당된 메모리를 포함하여
익명 메모리(파일이 백업하지 않은 메모리) 페이지의 백업 저장소로만 사용된다.
익명 메모리란?
익명 메모리는 이름이 없는 메모리를 나타내는 용어입니다.
이는 보통 프로세스가 실행되는 동안 임시적으로 할당되는 메모리를 나타내며,
특정 파일이나 디스크에 대한 대응 관계가 없습니다.
익명 메모리는 주로 힙(heap) 또는 스택(stack)과 같은 프로그램 실행 공간에서 사용되며,
프로세스의 동적 메모리 할당 요청에 의해 생성됩니다.
예를 들어, C 언어에서 malloc 함수를 호출하거나,
자바에서 new 연산자를 사용하여 객체를 생성할 때 할당되는 메모리는 익명 메모리에 해당합니다.
익명 메모리는 프로세스의 생명 주기와 연관되어 있어,
프로세스가 종료되면 해당 프로세스가 사용하던 익명 메모리도 해제됩니다.
이와는 대조적으로, 이름이 있는 메모리(즉, 파일에 매핑된 메모리)는 특정 파일에 연결되어 있으므로,
파일 시스템에 지속적으로 존재할 수 있습니다.
11.7 저장장치 연결
컴퓨터는 호스트에 연결하는 방식,
네트워크로 연결된 저장장치,
클라우드 저장장치 등의 3가지 방법으로 보조저장장치에 접근한다.
호스트 연결 저장장치
SATA와 같은 기술을 사용한 로컬 I/O 포트를 통해 연결한다.
고성능 서버에서는 광섬유 채널과 같은 더 정교한 I/O 아키텍처를 사용한다.
네트워크 연결 저장장치
NAS(network-attached storage).
RPC(원격 프로시저 호출) 인터페이스를 통해 액세스 한다.
RPC는 TCP/UDP를 통해 전달된다.
NAS는 CIFS 또는 NFS 프로토콜을 사용하면 다른 파일 시스템인 것처럼 접근되고,
iSCSI 프로토콜을 사용하면 raw 블록 장치로 접근된다.
클라우드 저장장치
네트워크 연결 저장장치와 유사하게 네트워크를 통해 액세스한다.
NAS와는 달리 인터넷 또는 다른 WAN을 통해 접속한다.
NAS와 또 다른 점은 프로토콜 대신 API로 저장장치에 접근한다는 점이다.
프로토콜 대신 API를 쓰는 이유는 WAN의 지연시간 및 장애 시나리오이다.
NAS 프로토콜은 LAN에서 사용하도록 설계되어 WAN보다 지연시간이 짧고 연결이 끊어질 가능성이 훨씬 작다.
만약 문제가 발생하면 복구될때까지 기다린다.
클라우드는 WAN이라 이런식으론 안된다.
SAN(storage-area network)와 저장장치 배열
네트워크에 있는 저장 시스템의 단점 중 하나는
입출력 연산시 네트워크의 대역폭을 소비하는 점이고,
이로 인해 네트워크 통신이 지연된다.
이는 규모가 커질수록 심각한 문제가 된다.
SAN은 서버들과 저장장치들을 연결하는 네트워크다.
네트워크 프로토콜 대신 저장장치 프로토콜을 사용한다.
SAN의 장점은 유연성이다.
여러 호스트와 저장장치가 같이 묶일 수 있고,
저장장치는 동적으로 호스트에 할당될 수 있다.
결론적으로 SAN은 높은 속도의 특수 네트워크를 통해 서버와 공유 스토리지 장치를 연결하는 고성능 스토리지 네트워크 시스템입니다.
11.8 RAID 구조
RAID란 "Redundant Array of Inexpensive Disks"로,
"저렴한 디스크들의 중복 배열"이라는 의미입니다.
RAID는 여러 개의 (저렴한) 디스크를 하나의 그룹으로 묶어,
하나의 안정적인 고성능 디스크처럼 동작하게 하는 기술을 가리킵니다.
하지만 현재에는 이러한 경제적인 이유보다는 높은 신뢰성과 높은 데이터 전송률 때문에 사용되므로
약자 I를 Independent로 보는게 더 합당하다.
중복 정보가 여러 드라이브에 저장되기 때문에 신뢰성이 높고
다수의 드라이브이므로 병렬적으로 운영된다면 높은 데이터 전송률도 가질 수 있다.
중복으로 신뢰성 향상
MTBF(mean time between failure) : 고장 사이의 평균 시간
중복을 도입하는 가장 간단하지만 가장 비용이 많이 드는 방법은 모든 드라이브의 복사본을 만드는 것이다.
이 기술은 mirroring이라고 불린다.
이 경우 쓰기작업은 두 드라이브에 모두 실행되고 이러한 결과를 mirrored volume이라고 한다.
미러드 볼륨의 MTBF는 각각의 드라이브의 MTBF와 평균 수리 시간에 의해 좌우된다.
두 드라이브의 고장이 독립적이라고 가정하면 미러드 디스크 시스템의 평균 데이터 분실 시간은
(단일 드라이브의 MTBF^드라이브 수) / (드라이브 수 * 평균 수리시간)이다.
하지만 전력 문제나 자연재해, 제조상의 결점 등과 같이
두 드라이브의 고장이 독립적이지 않을 가능성도 많다.
그래도 싱글시스템보다 더 높은 신뢰성을 제공해 준다.
다만 전원 문제는 자주 발생할 수 있으므로
대비책으로 두 드라이브에 동시에 병렬로 쓰기 작업을 하는게 아닌
하나에 먼저하고 다음에 하는식을로 직렬로 하는 것이다.
또 다른 대안으론 비휘발성 캐시를 두는 것이다.
병렬성을 이용한 성능 향상
여러 드라이브를 사용할 경우 여러 드라이브에 걸쳐 데이터 스트라이핑을 사용하여
전송 비율을 높일 수 있다.
가장 간단한 형식으로 데이터 스트라이핑은 여러 드라이브에 각 바이트의 비트를 나누어 저장함으로써 구성된다.
이걸 비트 레벨 스트라이핑이라고 한다.
다른 여러 레벨 단위 스트라이핑도 가능하다.
따라서 여러 액세스의 처리량을 높이고, 응답시간을 줄인다.
RAID 레벨
미러링은 신뢰성이 높지만 비용이 비싸고,
스트라이핑은 속도는 빠르지만 신뢰성은 그대로다.
이에 패리티 비트와 스트라이핑을 결합한 많은 기법이 제안되었다.
이러한 기법은 각기 다른 가성비를 가지며, RAID 레벨로 분류된다.
가장 많이 사용하는 것만 소개한다.
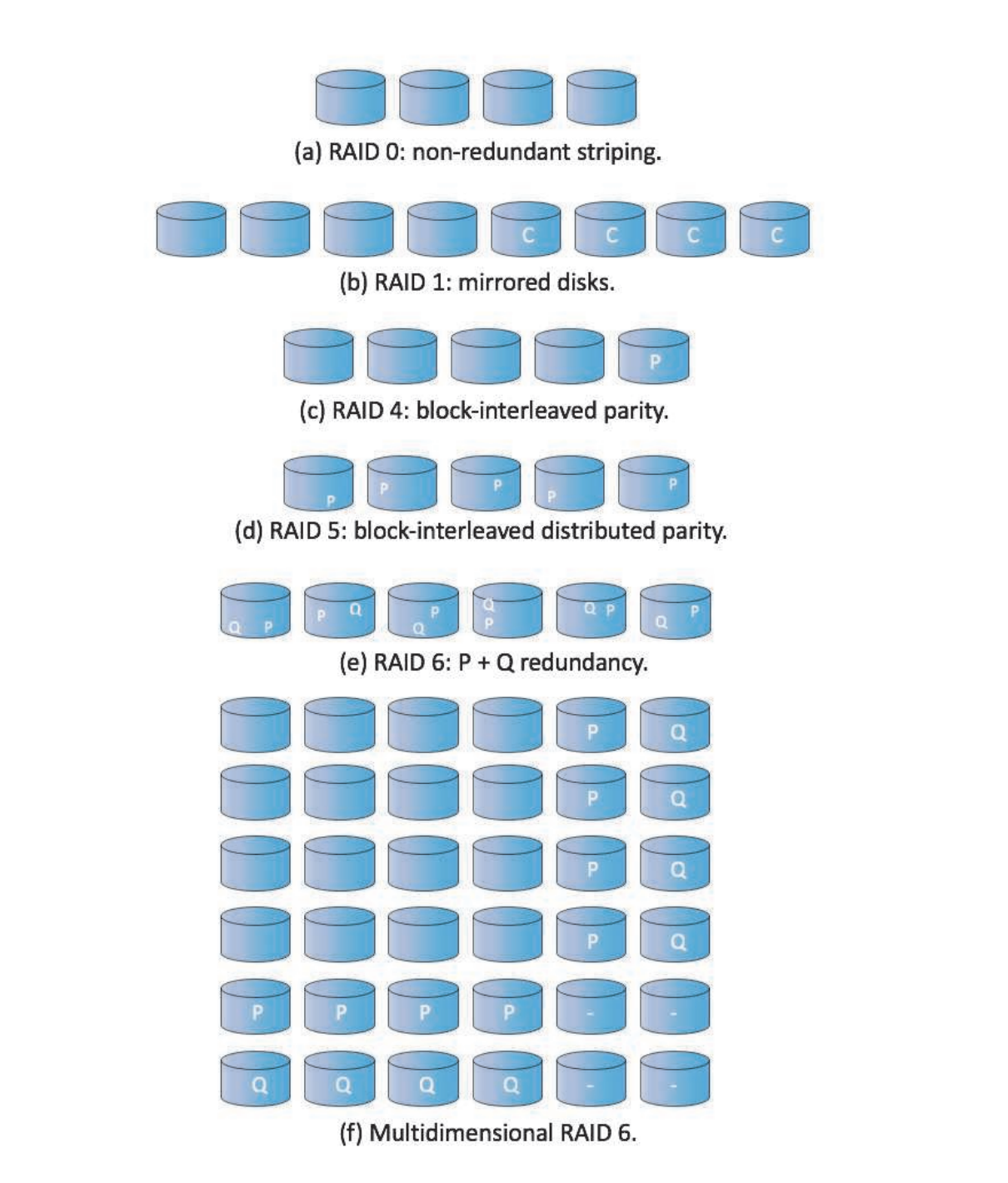
- RAID 0 : 블록 레벨 스트라이핑만 함
- RAID 1 : 미러링만 사용
RAID 4 (블록 인터리브 패리티)
하나의 드라이브를 오류 수정 블록 저장용으로 둔다
드라이브 컨트롤러는 메모리 시스템과 달리 어떤 섹터가 고장났는지 알 수 있어
패리티 비트로 오류를 수정할 수 있다.
모든 디스크를 병렬로 읽을 수 있으므로 대용량 읽기가 빠르다.
데이터와 패리티를 병렬로 쓸 수 있기 때문에 대용량 쓰기도 빠르다.
하지만 (블록보다)작은 독립적인 쓰기는 병렬로 수행할 수 없어 느리다. (블록 단위기 때문에)
데이터를 쓰려면 다음과 같은 읽기-수정-쓰기 주기가 필요하다.
-
읽기: 먼저, 운영체제는 변경할 데이터가 있는 블록과 패리티 블록을 읽어야 합니다. 이는 두 개의 드라이브 접근이 필요합니다.
-
수정: 그 다음, 운영체제는 새로운 데이터로 블록을 수정하고, 다른 블록과 함께 수정된 블록의 패리티를 다시 계산합니다.
-
쓰기: 마지막으로, 수정된 블록과 새로 계산된 패리티 블록을 디스크에 다시 써야 합니다. 이 작업도 두 개의 드라이브 접근이 필요합니다.
이런 절차가 필요한 이유는, 패리티가 모든 데이터 블록에 대해 계산되므로, 하나의 데이터 블록만 변경되더라도 패리티 블록도 업데이트되어야 하기 때문입니다.
RAID 4는 서비스 중단 없이 드라이브를 추가할 수 있는데,
추가된 드라이브의 모든 블록이 0이면 패리티 값에 변경이 없기 때문이다.
레벨4는 동일한 데이터 보호 기능을 제공하면서 레벨 1에 비해 두 가지 장점이 있다.
첫째, 여러 일반 드라이브에 하나의 패리티 드라이브만 필요해 저장장치 오버헤드가 적다.
둘째, N-way 데이터 스트라이핑으로 인해 읽거나 쓰는 전송 속도가 N배 빠르다.
RAID4를 포함한 모든 패리티 기반 RAID 레벨의 문제는 XOR 패리티 계산 및 기록 비용이다.
하지만 최신 CPU는 드라이브 I/O에 비해 훨씬 빨라 성능저하가 적어지고,
또한 패리티 전용 하드웨어를 통해 cpu의 부담도 줄인다.
또한 버퍼링을 통해 쓰기 작업할 때마다 읽수쓰 주기를 하는게 아니라 모아뒀다가 한번에 해서 효율을 높인다.
이러한 것들을 통해 종종 비-패리티보다 더 빠를 때도 있다.
RAID 5 (블록 인터리브 분산 패리티)
RAID4와 달리 모든 드라이브에 데이터와 패리티를 분산 시킨다.
예를 들어 1번째 블록에 대한 패리티는 2번째 드라이브에 저장되고
2를 제외한 나머지 1,3,4 드라이브의 1번째 블록에 데이터가 분산 저장된다.
이렇게 패리티 비트를 분산시켜 저장해 RAID4에서의 패리티 드라이브에 대한 과도한 부하를 방지한다.
RAID 6 (P + Q 중복)
RAID 5와 유사하지만, 여러 디스크 오류에 대비해 중복 정보를 저장한다.
패리티 비트 대신 Galois field 수학과 같은 에러 교정 코드가 사용된다.
데이터 4블록마다 2블록의 중복 데이터를 저장한다.
다차원 RAID 6
드라이브들을 논리적 2차원 배열로 생각해 각 행과 열 방향에 따라 RAID 6를 구현한다.
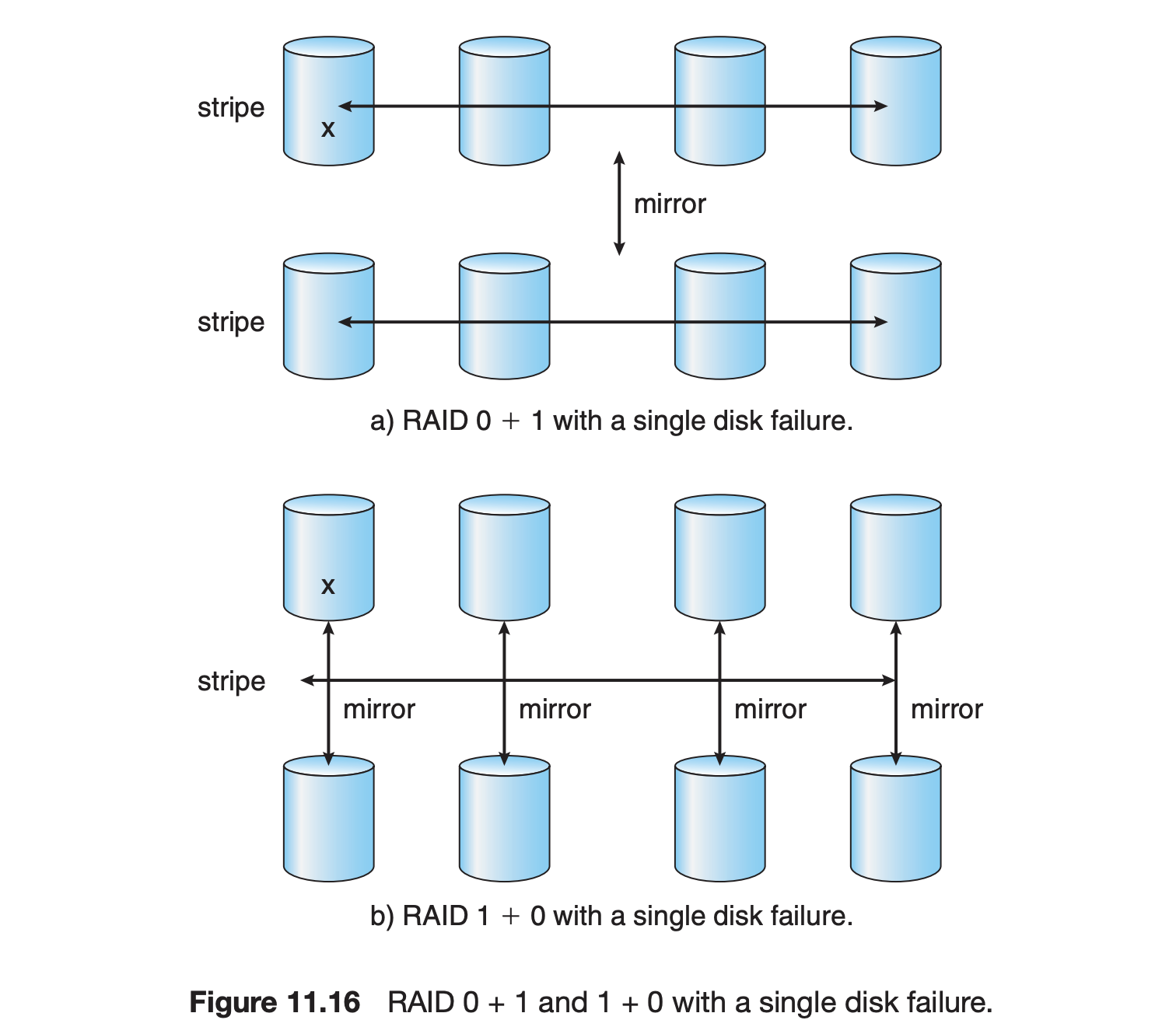
RAID 0 + 1
둘을 섞은거다.
즉, 데이터를 병렬로 나누고 복제하여 저장한다.
성능과 신뢰성 둘 다 중요한 환경에서 사용되는데
드라이브의 세트가 스트라이프되고, 그게 미러링돼서 2세트가 있다.
RAID 1 + 0
또다른 변형으로 여기선 미러링부터 하고 스트라이핑한다.
즉, 데이터를 복제하고 복제된 데이터를 병렬로 저장한다.
이는 0 + 1에 비해 장점이 있는데
이것은 주로 하드 드라이브의 실패 시나리오를 생각해보면 이해가 됩니다.
RAID 0 + 1에서 하나의 드라이브가 실패하면,
그 드라이브가 포함된 전체 스트라이프 세트가 손상되어 사용할 수 없게 됩니다.
이는 미러링된 다른 세트에는 영향을 미치지 않지만,
손상된 세트에 있는 모든 데이터에는 접근할 수 없게 됩니다.
반면에 RAID 1 + 0에서 하나의 드라이브가 실패하더라도,
해당 드라이브를 미러링한 다른 드라이브가 계속 작동하므로 데이터에 여전히 접근할 수 있습니다.
또한, 다른 모든 드라이브들도 여전히 작동하므로,
시스템 전체의 성능에 미치는 영향은 최소화됩니다.
RAID의 구현은 또 다른 변형된 형태들이 있다.
아래의 계층들에서 RAID가 구현되는 것을 고려해보자.
-
커널 내에 저장소 관리 소프트웨어가 RAID를 구현할 수 있다.
-
HBA(host bus adapter) 하드웨어에 구현될 수 있다.
HBA에 직접 연결된 드라이브들만 RAID의 일부가 된다. -
저장장치 배열 하드웨어에 구현될 수 있다.
-
SAN의 내부연결 계층에 구현될 수 있다.
RAID 시스템에서 추가로 활용될 수 있는 기능에는 스냅샷과 복제가 있습니다.
- 스냅샷은 마지막 업데이트가 이루어진 이전의 파일 시스템 상태를 보여주는 것을 말합니다.
- 복제는 분산된 여러 위치에 데이터를 자동으로 복사함으로써 데이터의 중복성을 확보하고 재난 복구를 지원하는 방식입니다. 복제는 동기식 또는 비동기식이 될 수 있습니다.
- 동기식 복제에서는 작성이 완료되려면 각 블록이 로컬 및 원격 모두에 쓰여져야 합니다.
- 비동기식 복제에서는 작성 작업이 그룹화되어 주기적으로 쓰여집니다. 이는 주 데이터 센터가 실패한 경우 데이터 손실을 초래할 수 있지만, 더 빠르고 거리 제한이 없습니다.
또한 이러한 기능들의 구현은 RAID가 어느 계층에서 구현되느냐에 따라 다르게 진행됩니다. 예를 들어, RAID가 소프트웨어에서 구현되면 각 호스트가 자체 복제를 수행하고 관리해야 할 수 있습니다. 그러나 스토리지 배열이나 SAN 인터커넥트에서 복제가 구현되면 호스트 운영 체제나 그 기능에 관계없이 호스트 데이터를 복제할 수 있습니다.
대부분의 RAID 구현에는 '핫 스페어'라는 개념이 포함됩니다. 핫 스페어는 데이터를 저장하기 위해 사용되지 않지만, 드라이브의 고장 시 대체 용도로 사용됩니다. 예를 들어, 한 쌍의 드라이브 중 하나가 고장 난 경우 핫 스페어는 미러링된 쌍을 재구성하는 데 사용될 수 있습니다. 이를 통해 실패한 드라이브가 교체되기를 기다리지 않고도 자동으로 RAID 레벨을 복원할 수 있습니다. 하나 이상의 핫 스페어를 할당하면 사람의 개입 없이 여러 고장을 복구할 수 있습니다.
레이드 레벨 선택
어떤 레벨을 선택해야 할까?
고려사항 중 하나는 복구 능력이다.
대화형 데이터베이스 시스템 처럼 데이터의 지속적인 공급이 필요하다면 이는 매우 중요한 요소이다.
복구 능력은 RAID 레벨에 따라 천차만별이다.
복구는 레이드 레벨 1이 제일 빠르다(미러링)
레이드 0은 데이터 손실이 중요하지 않은 고성능 응용 프로그램에 사용된다.
레이드 1의 높은 공간 오버헤드로 인해 레이드 5는 보통의 양의 데이터를 저장하는 데 선호된다.
레이드 6 계열은 저장장치 배열에서 가장 일반적인 형식이다.
큰 공간 오버헤드 없이 우수한 성능과 보호 기능을 제공한다.
확장
레이드의 개념은 여러 저장장치에 적용된다.
레이드의 문제점들
RAID 시스템의 한계와 Solaris ZFS 파일 시스템이 이러한 문제를 어떻게 해결하는지에 대해 알아보자
-
RAID 시스템의 한계: RAID는 물리적인 미디어 오류를 방지하지만, 다른 하드웨어와 소프트웨어 오류는 방지하지 못합니다. 예를 들어, 하드웨어 RAID 컨트롤러의 실패나 소프트웨어 RAID 코드의 버그로 인한 데이터 손실이 발생할 수 있습니다.
-
ZFS의 체크섬 기능: ZFS는 모든 블록(데이터와 메타데이터 포함)의 내부 체크섬을 유지합니다. 이 체크섬은 체크섬이 계산된 블록과 함께 저장되지 않고, 그 블록을 가리키는 포인터와 함께 저장됩니다. 이를 통해 ZFS는 데이터 문제를 감지하고, 문제가 있을 경우 자동으로 수정할 수 있습니다.
-
ZFS의 유연성: 대부분의 RAID 구현체는 유연성이 부족합니다. ZFS는 파일 시스템 관리와 볼륨 관리를 하나의 단위로 결합하여, 드라이브를 스토리지 풀로 모으고, 이 풀 내에 하나 이상의 ZFS 파일 시스템을 저장합니다. 이 풀의 전체 여유 공간은 그 풀 내의 모든 파일 시스템에서 사용할 수 있습니다.
요약하면, RAID는 물리적인 미디어 오류에 대한 보호만을 제공하며, 다른 하드웨어 및 소프트웨어 오류에 대해서는 보호하지 못한다는 한계가 있습니다. 반면 ZFS는 체크섬 기능을 통해 이러한 문제를 해결하고, 파일 시스템 관리와 볼륨 관리를 통합함으로써 더 큰 유연성을 제공합니다.
또 다른 이슈는 융통성의 부족이다.
드라이브 사용과 요구 조건은 매우 빈번하게 바뀐다.
객체 저장소
일반적으로 파일 시스템을 사용하여 사용자의 콘텐츠를 저장한다.
데이터 저장장치에 대한 또 다른 접근법은 저장장치 풀로 시작하여
해당 풀에 객체를 배치하는 것이다.
이 방법은 풀을 탐색하고 해당 객체를 찾을 방법이 없다.
따라서 이는 사용자가 아닌 컴퓨터 지향적이며 프로그램에서 사용하도록 설계되었다.
일반적인 순서는 다음과 같다.
- 저장장치 풀 내에 객체를 생성하고 객체 ID를 받는다.
- 필요할 때 객체 ID를 통해 객체에 접근한다.
- 객체 ID를 통해 객체를 삭제한다.
HDFS(Hadoop file system) 및 Ceph와 같은 객체 저장소 관리 소프트웨어는
객체를 관리한다.
객체 저장소는 수평 확장성의 이점이 있다.
컴퓨터를 더 추가하고 저장장치를 풀에 추가하기만 하면 된다.
범용 컴퓨터에서는 객체 저장소가 일반적이지 않지만
Google의 인터넷 검색 콘텐츠, Facebook의 사진 등 많은 양의 데이터가 객체 저장소에 저장된다.
AWS도 객체 저장소를 사용하여 데이터 객체와 파일 시스템을 보유한다.
이 텍스트는 오브젝트 스토리지에 대해 설명하고 있습니다.
-
오브젝트 스토리지란? : 오브젝트 스토리지는 데이터를 스토리지 풀에 '오브젝트' 형태로 저장하는 방식입니다. 파일 시스템과 달리, 오브젝트 스토리지에서는 풀을 탐색하여 오브젝트를 찾는 방법이 없습니다. 대신 오브젝트 ID를 통해 오브젝트를 생성, 접근, 삭제합니다. 이 방식은 사용자 중심이 아닌 컴퓨터 중심으로, 프로그램에 의해 사용되도록 설계되었습니다.
-
오브젝트 스토리지의 특징: 오브젝트 스토리지는 보통 Hadoop 파일 시스템(HDFS)이나 Ceph 같은 오브젝트 스토리지 관리 소프트웨어에 의해 관리됩니다. 이 방식은 스토리지 배열보다 비용이 저렴하고 접근 속도가 빠르며, 가로 확장성이 뛰어나다는 장점이 있습니다. 오브젝트 스토리지는 각 오브젝트가 자체적으로 내용을 설명하므로, 무구조적 데이터를 저장하는데 적합합니다.
-
오브젝트 스토리지의 활용: 일반적인 개인용 컴퓨터에서는 오브젝트 스토리지를 흔히 사용하지 않지만, Google 검색 내용, Dropbox 내용, Spotify 음악, Facebook 사진 등 많은 데이터가 오브젝트 스토리지에 저장됩니다. 클라우드 컴퓨팅(예: Amazon AWS)은 일반적으로 오브젝트 스토어를 사용하여 파일 시스템과 고객 애플리케이션의 데이터 오브젝트를 저장합니다.

뛰어난 글이네요, 감사합니다.