Synchronous
- clock을 이용해 타이밍을 맞춘다.
- 하드웨어 시스템은 전부 동기 방식으로 작동한다.
func distance(_ p1: Int, _ p2: Int) -> Int {
return abs(p1 - p2)
}
func area(x1: Int, y1: Int, x2: Int, y2: Int) -> Int {
let dX = distance(x1, x2)
let dY = distance(y1, y2)
return dX * dY
}위 코드에서 area()는 내부에서 distance()를 호출하고 리턴 값을 기다린다. 이 처럼 어떤 함수가 다른 함수의 리턴 값을 기다리고 있고 그 값을 처리하게 해주는 함수를 동기함수 혹은 blocking함수라고 한다.
Indirection (간접 참조)
예전엔 함수가 없이 코드가 위에서 부터 한 줄씩 실행되는 구조였다.
따라서 반복되는 코드가 많았고, 이를 해결하기 위해 간접참조 개념이 시작 되었다.
Routine - subroutine

area()에서 distance()를 호출하면 서브루틴에서 실행되고 routine으로 돌아온다. 이를 통해 하위 함수라는 개념을 만들었다.
Sync Remote Resource
네트워크에서 여러대의 장비가 있을 경우를 생각해보자.
remote에 있는 resource를 가져올 때,
Data
Swift 자료형으로 Image, Pointer, String, File, URL, 바이너리 데이터 등 많은 데이터를 Data 자료형에 담아 접근할 수 있다.
Data의 contentsof 파라미터로 URL을 넘겨주면 remote에 있는 것도 로컬에 담아올 수 있다.
하지만 이는 전형적인 동기 API로, 동기 방식으로 동작하기 때문에 remote의 resource를 다 받기 전까진 앱의 실행이 멈춘다.
따라서 이는 권장 방법은 아니고 쓴다고 해도 금방 불러올 수 있는 데이터에 한해서만 사용해야 한다.
let data = try? Data(contentsOf: URL(string: "https://~~"))Asynchronous
앞선 예제와 같은 상황을 해결하기 위해 비동기 방식으로 작업을 분리해야 한다.
그렇게 하기 위해선 area()가 distance()를 호출했을 때, distance()가 바로 리턴을 해주어 area()가 다시 실행될 수 있게끔 해주고 distance()는 자신의 작업이 끝나면 callback을 해준다.
이 후 원래 distance()를 호출했을 때 실행하려했던 area()의 코드를 실행한다.

코드상으로는 context#1 에 closure나 callback함수가 선언되어 있고,
이를 context#2가 호출하는 식으로 되어있다.
func callback(_ a: Int, _ b: Int) -> {
return a + b
}
func context1(a: Int, b: Int, cb: (Int, Int) -> Int {
print(a)
print(callback(a, b))
print(b)
}
context1(a: 1, b: 2, cb: callback)worker 개념으로 봤을 때, 보통은 context#1과 context#2가 스레드가 분리돼서 각각의 스레드로 된다.
Parallel vs Concurrent
Parallel은 물리적으로 일꾼이 여러명이라 일을 병렬적으로 처리할 수 있는 것을 말하고,
Concurrent는 시간을 나누거나 공간을 나누는 식으로, 실제 일꾼은 한 명이지만 여러명인 것처럼 보이게 하는 논리적 방식의 병렬처리를 뜻한다.

- 이미지 출처 : https://developpaper.com
일꾼(worker)과 큐
 중간 목적인 queue를 두어 A -> A1 으로 작업을 진행하고, 다시 A1 -> B로 짧은 텀으로 작업을 진행시킨다.
여기서 일꾼이 한명이면 큐를 어떻게 나누든 결과적으론 동일하지만
Parallel과 병합하여 구간을 여러개로 나누고 일꾼을 여러명 두게 되면
일꾼이 5명만 있더라도 10개의 작업이 동시에 돌아가고 있는 것처럼 보이게 할 수 있다.
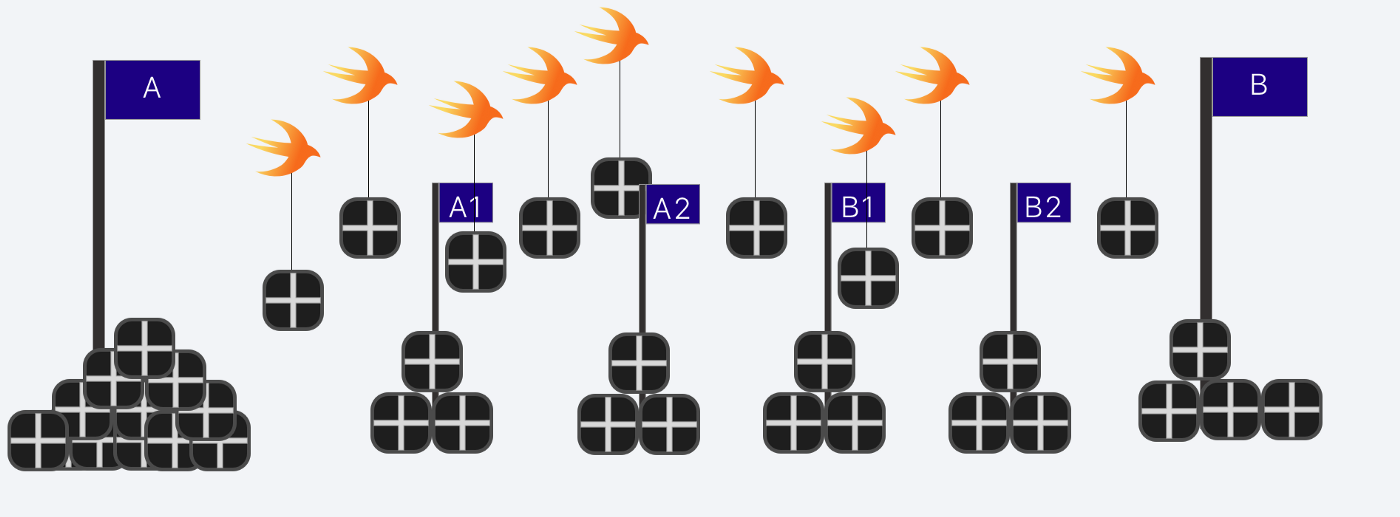
중간 목적인 queue를 두어 A -> A1 으로 작업을 진행하고, 다시 A1 -> B로 짧은 텀으로 작업을 진행시킨다.
여기서 일꾼이 한명이면 큐를 어떻게 나누든 결과적으론 동일하지만
Parallel과 병합하여 구간을 여러개로 나누고 일꾼을 여러명 두게 되면
일꾼이 5명만 있더라도 10개의 작업이 동시에 돌아가고 있는 것처럼 보이게 할 수 있다.

Process vs Thread
기술이 발전함에 따라 운영체제도 프로세스 하나당 여러개의 스레드를 두는 멀티 스레딩을 지원해주게 되었다.
운영체제는 cpu가 여러개일 시 프로세스 마다 Parallel하게 동작하게 하고 cpu가 하나더라도 시간을 나누어 써서 각 스레드를 Concurrent하게 동작시킨다. (물론 cpu가 여러개이면 두 방식이 동시에 돌아간다.)
Concurrent Programming
장점
- UI 화면의 반응성
- 병렬처리로 인한 속도 향상
비용
- 제대로 멀티-스레드 코드를 작성하는 것은 꽤 어렵다.
- 디버깅도 어렵다.
- 확장 가능하게 여러 작업을 동시에 처리하는 일반적인 문제들
현재 스레드를 포함한 MicroProcessor의 퍼포먼스는 발열등의 물리적인 문제로 한계치에 다다랐는데, 이에 코어를 늘려 동시성을 제공하는 식으로 변화하였다.
따라서 이에 맞게 프로그래밍의 패러다임도 변화하였다.
개념
기존에는 동시성을 제공하기 위해서 개발자가 직접 여러개의 스레드를 만들어 관리하는 것을 권장했다면,
이제는 효율적인 스레드의 관리를 운영체제에게 맡기고, 스레드보다 더 작은 코드 단위인 Closure로 작업을 분리하여, 그 스레드에 해당하는 queue에다 closure를 넣어주기만 하면된다.

GCD (Grand Central Dispatch)
개발자가 dispatch큐에 블럭코드를 넣으면 그 큐에 연결된 스레드에서 실행하고 결과를 넘겨주는 구조를 제공해주는 라이브러리이다.
Event Sourcing
파일이 바뀌는 등 어떤 이벤트가 발생했을 때도 일반 블럭코드를 큐에 바인딩해서 처리한 것처럼 Dispatch source를 사용하여 처리 가능.
주기적으로 발생해야 하는 작업도 클로저에 바인딩해서 특정한 클로저가 주기적으로 이벤트에 맞춰서 실행되게끔 할 수 있다. (Timer 예제)
Queue
- main queue
DispatchQueue.main - global queue : 내부적으로 큐가 여러개이다.
DispatchQueue.global() - serial queue : 큐가 하나이다.
DispatchQueue.init(label: String)
아무 옵션을 주지 않으면 기본적으로 직렬큐가 만들어지고 global 큐를 만들면 동시성이 있는 큐로 만들어진다.
GCD Design patterns
GCD를 만들 때 쉬운 방식은 dispatch_async()를 쓰는 것이다.
큐는 프로듀서/컨슈머(큐에 뭘 넣는 애와 빼가는 애) 구조로.
큐를 스레드가 꺼내가지 않고 다른 큐에 넣는 작업을 할 수 있다. 큐가 여러 개 있을 때 큐끼리 스케줄링하는 큐를 만들어서 대기큐에서 빼서 다른 큐로 옮기는 작업을 할 수 있는데, 이 때 클로저가 작업들 사이에 데이터를 전달해주는 역할을 할 수 있다.
큐에는 가벼운 작업만 넣어야 한다.
출처 : https://www.youtube.com
출처 : https://www.youtube.com
callback
다른 함수에 전달 되는 함수. 나중에 실행된다.
