
배경
인공지능 온라인 경진대회는 과학기술정보통신부가 주관했고, 2019년부터 개최된 대회입니다. 그저 좋은 성적을 거두었다고 해서 상금이 주어지거나 그런 건 아니고 사업화 과정과 연계되어서 지원금을 제공하는 구조입니다.
사실 그런 건 크게 신경쓰지 않았고, 좋은 경험을 해보자라는 느낌으로 참가했습니다. 물론 한 번 참여하면 최대한 할 수 있는 건 해보는 성격이라 약간의 긴장을 하기는 했습니다.
제가 비전을 주로 다루므로, 이미지 영역으로 하기로 했고 그 중에서도 4문제가 있었습니다.
저는 일부러 제일 어려워(?) 보이는 문제를 골랐습니다. 이는 도전 정신을 일깨워보려는 시도였습니다. classification과 detection은 누구나 많이 들어본 문제이고, 그나마 segmentation은 좀 덜 활성화되어 있지만 그래도 가끔씩 대회에 나오는 문제입니다. 그에 반해 inpainting은 매우 많은 사람들이 처음 들어볼 수 있다고 생각했습니다. 저는 inpainting을 포함한 포괄적인 생성 모델링(colorization, style transfer) 등에 관심이 있었고, 석사 과정에서 이미지 간 변환 문제 중 하나인 super-resolution을 주로 다뤘기 때문에(그마저 ML 기반 접근법이긴 했지만) 유리할 것이라고도 생각했습니다.
문제 소개
문제 이름은 토지 피복지도 항공위성 손상 이미지 복원 문제입니다. 말 그대로 일부 영역이 사라진 이미지를 복구하는 문제라고 풀어 쓸 수 있겠습니다. 문제의 배경으로는 항공위성의 경우 활용이 잘 되는데 기상상황, 비행체 등으로 음영, 스림, 가림 등의 이슈가 생기면 재수집이 어렵고, 국가 안보 관련 비식별화가 필요해 이를 채워 줄 방법이 필요하다고 합니다.

위 그림과 같이 영상에 검은 선으로 일부 영역을 지워버린 것(왼쪽)을 모델을 통해 복구한 영상(오른쪽)으로 만드는 작업이 되겠습니다.
Inpainting 문제는 생각보다 인기(?)있는 문제입니다. 해당되는 연구도 많이 이루어졌습니다. 이 inpainting 문제의 해결 관점은 두 가지가 있습니다.
-
얼마나 원본과 비교해서
정확하게복원되었는지 -
얼마나
실제 사진처럼복원되었는지
보통 inpainting에서는 두 번째 관점을 목표로 삼으면서 연구가 이루어졌습니다. 예를 들어 아래 그림처럼 최근 inpainting 모델은 일부분을 지워도 감쪽같이 실제 사진처럼 복원해줍니다.

그런데, 여기서는 경진대회로 다루다 보니 첫 번째 관점을 사용해 출제되었습니다. 평가 지표는 다음과 같습니다.
참고로 이미지 복원 관련 지표로는 얼마나 정확하게 복원되었는지를 평가하는 PSNR, SSIM 등이 있고, 실제 사진처럼 복원되었는지는 FID 등이 있습니다. 여기서 평가 지표로 제시된 PSNR은 픽셀 차이를 직접 비교하는 지표입니다.
그 외에 규칙으로는 외부 데이터 사용이 불가하고, 재현 서버 환경(NVIDIA T4)에서 학습 36시간, 추론 3시간 이내의 조건이 있습니다.
문제 접근 방법
저는 이미지 간 변환인 super-resolution 관점에서 복원 문제로 바라보았습니다. 아래 SRGAN처럼 super-resolution도 두 가지 관점을 바라보고 있는 것을 확인 할 수 있습니다.

관련 연구에서 발견한 복원 문제의 특징과 생각한 점은 다음과 같습니다.
-
모델이 성능에 큰 영향을 끼치므로 이 문제의 주요 키는
모델 선정이라고 생각했습니다. -
모델의 학습 시간이 길어질수록 성능이 올라가는 구조라서
최대한의 학습 시간을 사용하는 것이 좋다고 판단했습니다. -
학습 시간을 절약하기 위해 scratch부터 학습하기보다는
파인 튜닝을 하는 것이 유리하다고 판단했습니다.
모델 선정하기
일단 정확하게 복구하는 inpainting 모델을 알고 있지는 않기 때문에 모델의 탐구가 필요했습니다. 이 과정에는 구글링과 google scholar의 도움을 받았습니다. 제가 추려낸 후보군 모델들은 다음과 같습니다.
-
DeepFillv2 (CVPR 2019): Image inpainting에서 매우 유명한 모델입니다.
-
GIN (ECCV 2020): AIM 2020 Challenge on Image Extreme Inpainting에서 좋은 성능을 보인 모델입니다.
-
AOT-GAN (TVCG 2021): MMEditing에서 제공하는 최신 모델입니다.
-
LaMa (WACV 2022): Fourier convolution block을 사용한 최신 모델입니다.
-
Palette (CVPR 2021): FID 끝판왕인 diffusion 기반 모델입니다.
이렇게 몇 개의 모델을 추려냈고 이 중에서 하나를 골라야 했습니다. 제가 모델을 선정하는 기준은 다음과 같습니다.
-
언제 연구가 수행되었는지 (출판/업로드일)
-
논문에서 어떤 데이터셋으로 실험했고, 성능은 어떤지
-
모델이 어떤 구조로 되어 있는지
이 관점으로 바라보았을 때 DeepFillv2는 상대적으로 연구가 수행된 지 오래 되어서 제외했고, Palette는 diffusion 기반 모델이라 PSNR 관점에서 보면 적합하지 않을 것이라고 생각해서 제외했습니다.
그래서 두 개를 제외하고 3개 중 하나를 선택해야 했습니다. 막 느낌상 고를 수는 없고 모두 학습을 하기에는 시간이 부족해서 Pretrained 모델 성능을 보고 사용할 모델을 결정하기로 했습니다. 이는 unseen 데이터에 대해서도 잘 복구하면 파인 튜닝을 통해 성능을 더 끌어올릴 수 있다고 생각했기 때문입니다.
세 모델에 대해서 성능을 측정하기로 했습니다. 물론 해당되는 코드를 적당히 수정해서 작성했습니다. 보통 이미지 하나에 대해 통과한 뒤 성능을 비교하는 방법을 사용합니다. 저는 더욱 정확한 성능 측정을 위해서 Test-time augmentation을 사용하기로 했습니다.

Test-time augmentation(TTA)은 추론 단계에서 이루어지며, 하나의 이미지를 증강 기법을 통해 여러 이미지로 모델을 통과시킵니다. 그리고 통과한 이미지들의 결과들을 기반으로 최종 결과를 판단하는 기법입니다. 보통 막판에 성능을 올리는 기법인데, inpainting에서 보통 사용하는 적대적 생성 모델(GAN)의 경우 원본 이미지만으로는 편차가 클 것으로 예상했습니다.
저는 하나의 이미지에 대해 (0도, 90도, 180도, 270도 회전) x (그대로, 뒤집어서)로 총 8가지 경우로 증강하고, 각 결과에 대해 평균을 취한 값을 결과로 계산했습니다. 그렇게 각 모델에 대해 TTA를 적용해 제출한 결과 다음과 같은 결과를 얻었습니다.
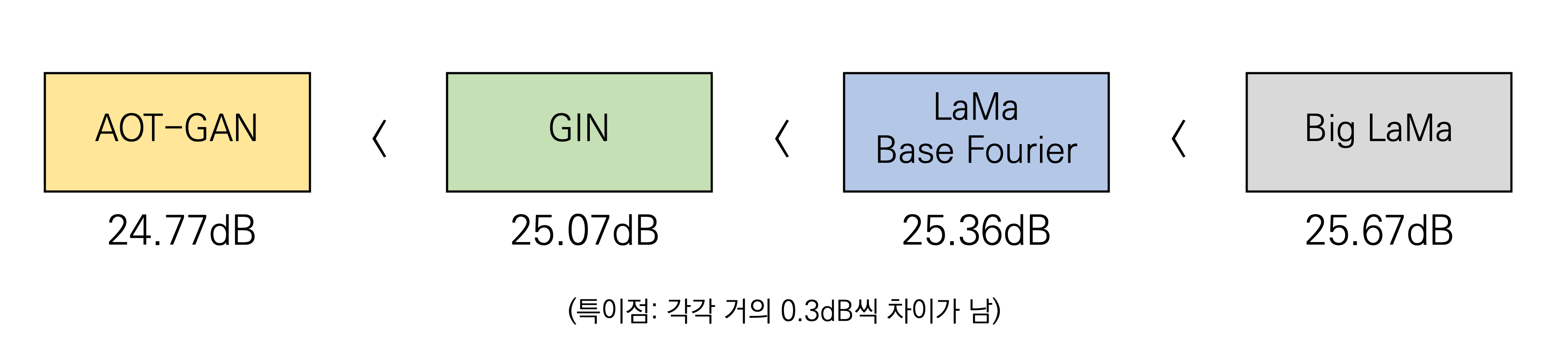
LaMa 모델이 가장 좋은 성능을 보이는 것으로 확인되었습니다. 참고로 LaMa의 경우 여러 버전의 모델이 있는데, 제안하는 Fourier 모델을 적용한 Base Fourier와 Big LaMa 2개를 사용했습니다. 이것만 보면 당연히 Big LaMa를 사용하는 것이 적당하다고 생각할 수 있는데, Big LaMa의 경우 매우 큰 모델이라(논문에서 8개의 V100 GPU로 학습한다고 함) 사용하기 어렵다는 판단을 했습니다. 결론적으로 LaMa Base Fourier 모델을 사용하기로 결정했습니다.
참고로 LaMa는 one-stage 모델에 Fourier transform을 사용해 high receptive field를 가져서 좋은 성능을 낸다고 주장하고 있습니다. 논문 자체에 대한 리뷰는 여기를 참조해주세요.
파인 튜닝
LaMa가 가장 성능이 좋다고 확인한 다음 파인 튜닝을 진행했습니다. Pretrained 모델은 공식 Github 레포에서 받아 사용하였고, 추가적으로 작성한 코드들도 해당 구조를 기반으로 수정하는 작업을 진행했습니다. 먼저 파인 튜닝을 최종적으로 학습한 방식을 다음 그림에 간단하게 나타내면 다음과 같습니다.
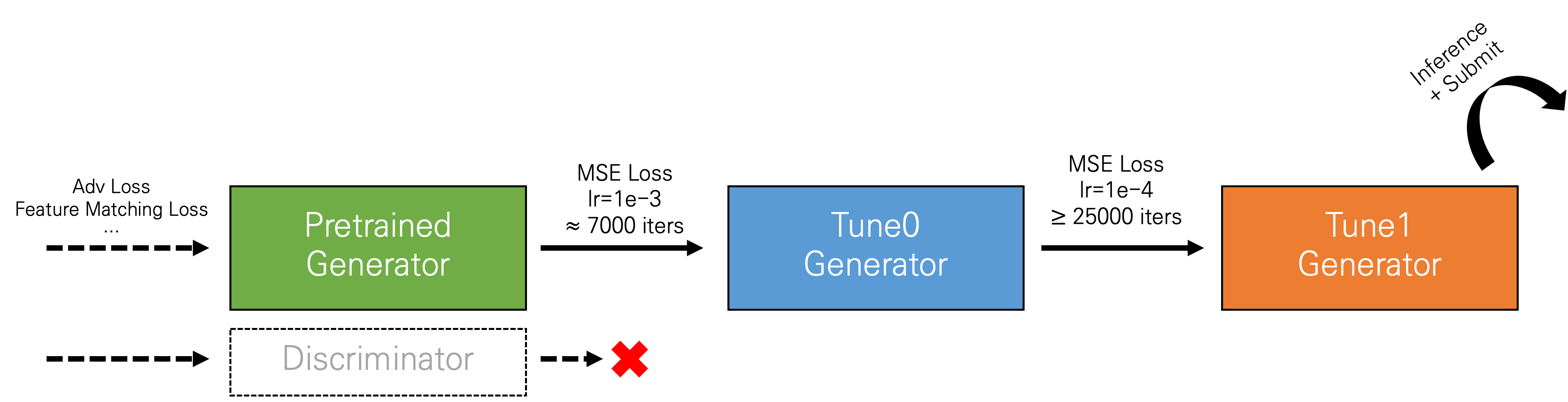
Pretrained 모델은 얼마나 실제 사진처럼 복원되도록 학습해야 하기 때문에 정확하게 복구하는 손실 등을 사용하지 않았습니다. 따라서 파인 튜닝을 진행할 때에는 마스킹된 부분에 대해 모델이 예측한 결과와 ground truth를 직접적으로 비교하는 Mean square loss를 사용하였습니다. 당연히 generator만 사용하고, discriminator는 따로 사용하지 않았습니다.
그리고 super-resolution같이 정교하게 복원해야 하는 문제들은 아주 천천히 성능이 오르기 때문에 큰 학습률을 사용하기 쉽지 않습니다. 대신 어느 정도 근사하게 예측하도록 그 다음에 정교하게 학습하도록 학습률을 조정하는 과정을 거쳤습니다. Super-resolution이 보통 0.0001의 학습률을 사용해서 근사하게 학습할 때에는 0.001로 5000 step 정도 학습시키고, 그 다음에 0.0001로 학습률을 줄여서 25000 step 이상으로 오래 학습했습니다.
학습 전략 및 실험
파인 튜닝을 수행하도록 코드까지 적당히 바꾸었다면 그 다음에 해야 할 것은 시간이 꽤 많이 들어갈 수 있는 실험 부분입니다. 모델 자체의 학습이 오래 걸리기 때문에 주요한 것들 위주로 몇몇 실험을 진행했습니다.
-
하이퍼파라메터로는 학습률을 중점적으로 조절해보았습니다. 0.01, 0.005, 0.001, 0.0001을 사용해서 학습해보았으며, 결과적으로는 위 방법대로 하는 것이 성능이 제일 높일 수 있는 방법이었습니다.
-
학습 단계에서 데이터 증강을 방식에 따른 성능 차이를 비교해보았습니다. 근사하게 학습했을 때까지 기준으로 random crop, resize, rotation 없이 horizontal/vertial flip만 했을 때 성능이 가장 좋았습니다.
-
학습 시간을 나눠서 k-fold learning을 진행해 보았습니다. 그렇지만 각 fold별로 학습해서 합쳐도 오래 학습한 모델 하나보다 성능이 낮아서 결과적으로는 사용하지 않았습니다.
결과
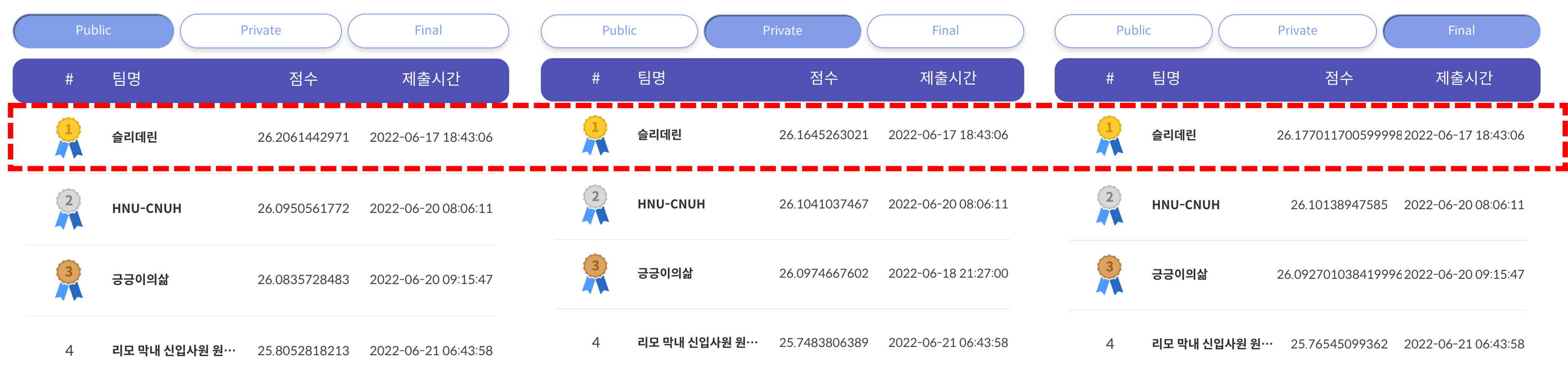
다른 모델들에 대해서도 실험을 진행하느라 시간이 조금 걸렸습니다. 파인 튜닝을 1000 step 정도 처음 수행하고 제출했을 때의 (public) 성능은 25.84dB였습니다. 그리고 학습을 더 오래 시키고, 학습률을 조절하는 방식으로 튜닝한 결과 최종적으로 26.20dB까지 성능을 향상시켰습니다.
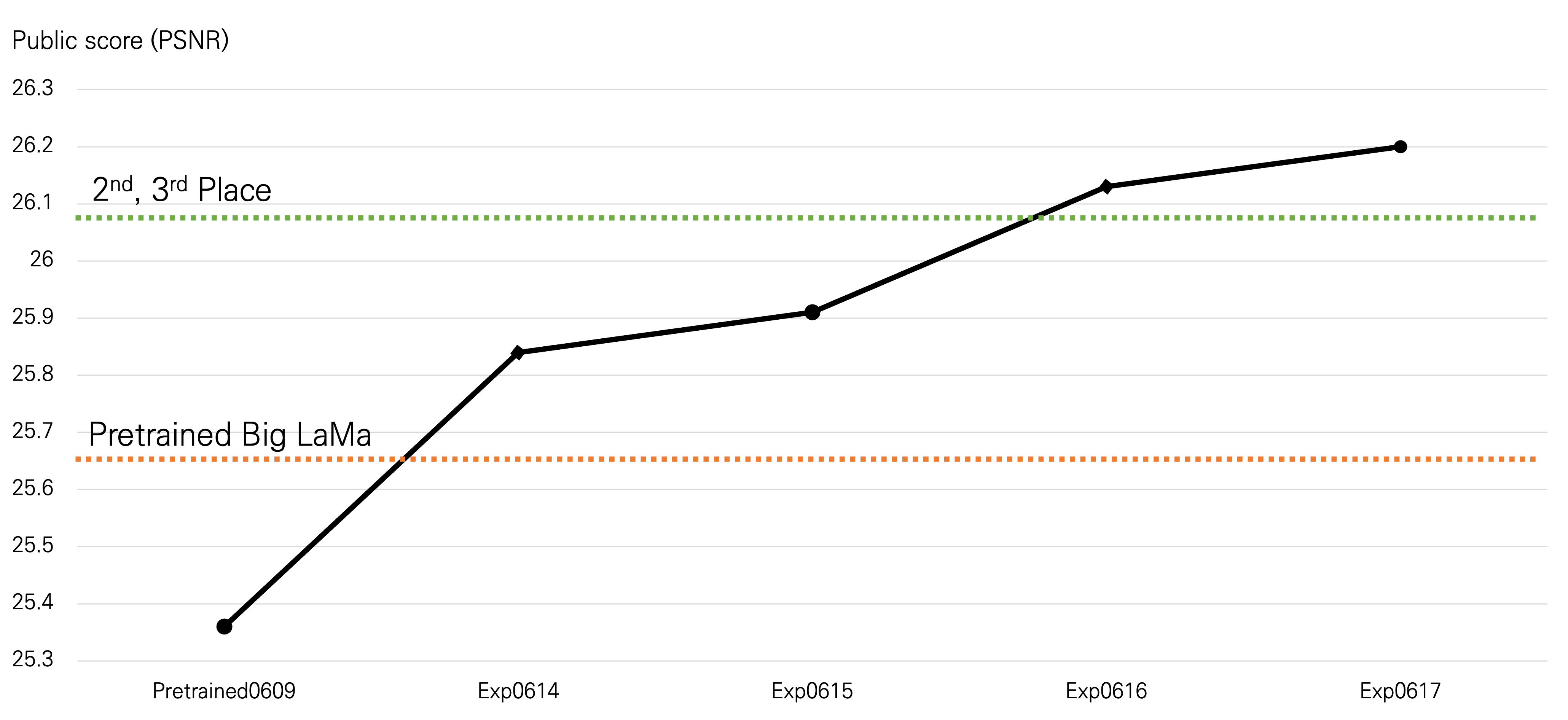
결과적으로 public, private, final 모두에서 1위를 차지했습니다. 2,3위와 성능 차이가 조금 나는 편이었으며, 또 4위와는 크게 차이가 나는 것을 확인할 수 있었습니다. 그리고 별도의 학습 없이 Big LaMa를 사용했어도 상위권에 들 수 있는 것으로 해석되었습니다.
후기
2주동안 상대적으로 짧은 기간동안 퇴근 후나 주말에 조금 빠듯하게 진행한 대회였습니다. 이 대회에서 Inpainting 파인 튜닝은 처음 해보았고, 해당 문제에 대한 follow-up을 이 기회에 해보았습니다. 모델 선정이 사실상 제일 키 포인트라고 생각하고 모델을 잘 발견해서 좋은 결과를 얻을 수 있었다고 생각합니다. 조금 큰 대회에서 수상하는 기회가 잘 없는데, 그런 김에 약간의 자신감도 생긴 것 같습니다.

자세한 설명 감사합니다.. 어려운 문제인데 정말 알기쉽게 쏙쏙 설명해주시네요