
DataLoader는 PyTorch에서 배치 학습에 요긴하게 사용되는 클래스입니다. 일반적으로는 딥러닝을 학습할 때 데이터를 모델에 입력해 나오는 출력과 목표값을 비교하는 방식으로 순방향 전달이 일어납니다. 이 순방향 전달을 컨베이어 벨트로 비유해 그림으로 나타내보겠습니다.
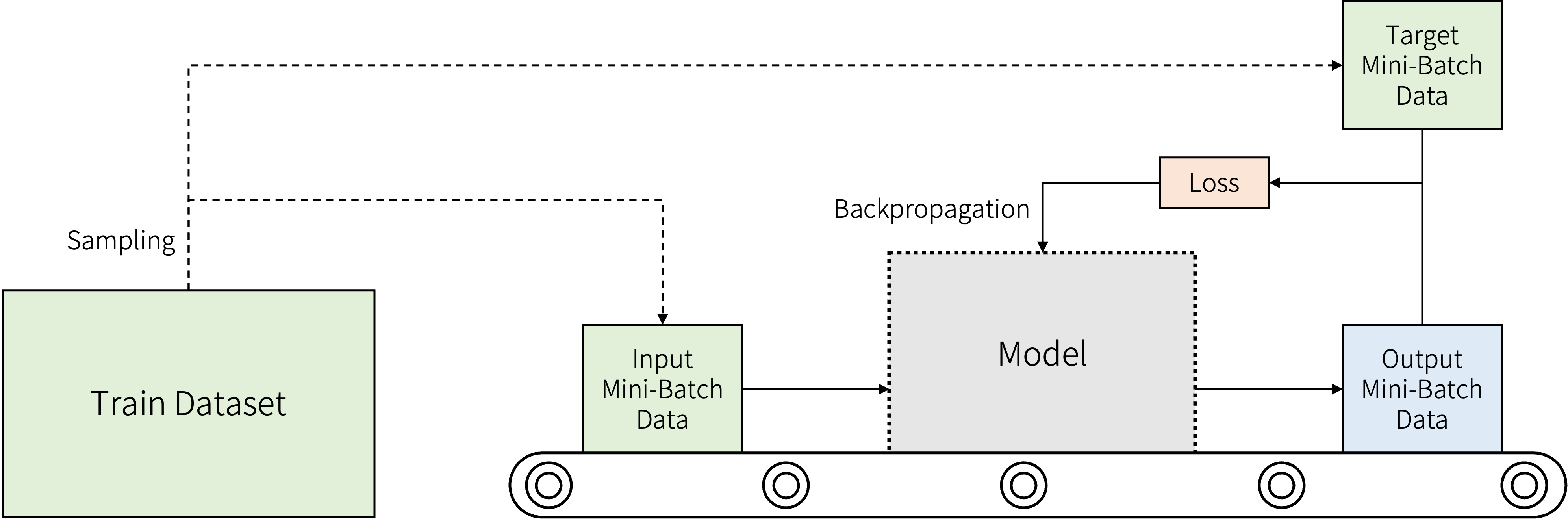
이번에는 모델에 넣을 데이터 관점에서 생각해봅시다. 작은 데이터셋이 아닌 이상 모든 데이터(배치)를 한번에 모델에 입력하기는 힘들 것입니다. 이는 연산 시간이나 메모리 측면 모두 이유가 될 수 있습니다. 그래서 학습할 데이터셋을 쪼개서, 미니 배치 단위로 모델에 입력하게 됩니다. DataLoader가 이 과정을 도와줍니다. 그러면 이제 이것을 어떻게 사용하는지 알아보겠습니다.
DataLoader 간단하게 사용하기
먼저 사용할 모듈들을 불러옵니다.
from torch.utils.data import Dataset, DataLoader그러면 한 DataLoader 인스턴스를 생성하기 위해 생성자에 어떤 파라메터들이 필요한지 살펴보겠습니다.
DataLoader(dataset, batch_size=1, shuffle=False, ...)클래스 생성자에 필요한 인수들을 살펴보면 나머지 옵션들을 모두 기본으로 설정하고 싶다면 데이터셋만 넘겨주어도 DataLoader 인스턴스가 생성될 수 있습니다. 물론 배치 크기가 1인 경우가 많지는 않겠죠. 보통 학습을 할 때에는 다음과 같이 생성합니다.
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)배치 크기는 클수록 학습의 안정성에 도움을 주지만 학습(역전파) 횟수 역시 일반적으로 클수록 수렴이 일어나기 때문에 적절한 크기로 지정해줍니다. 그리고 각 에포크마다 셔플을 하는 과정으로 과적합(overfitting)을 줄일 수 있도록 지정해줍니다. 다만 테스트 과정에서는 보통 사용하지 않습니다.
DataLoader 인스턴스를 만들었으면 미니 배치 단위로 데이터를 불러올 준비가 된 것입니다. 이 객체는 iterable하기 때문에 모델 학습을 할 때 다음과 같이 for문으로 바로 데이터를 불러옵니다.
for index, (images, labels) in enumerate(dataloader):
print(f"{index}/{len(dataloader)}", end=' ')
print("x shape:", images.shape, end=' ')
print("y shape:", labels.shape)index는 for문에서 얼마만큼 데이터가 불러와졌는지 확인하는 용도로 사용합니다. 실질적으로 데이터는 데이터셋의 __getitem__에서 반환한 튜플 형태로 값이 넘어오는데, 특이한 점은 미니 배치 단위로 데이터가 0번째 차원으로 묶여 반환하게 됩니다. 여기서는 이전 Dataset 포스트의 DogCatDataset를 사용했을 때, 출력 결과는 다음과 같습니다.
0/1563 x shape: torch.Size([16, 3, 256, 256]) y shape: torch.Size([16])
1/1563 x shape: torch.Size([16, 3, 256, 256]) y shape: torch.Size([16])
2/1563 x shape: torch.Size([16, 3, 256, 256]) y shape: torch.Size([16])
...결과로 나온 [16, 3, 256, 256]를 보면 알 수 있듯이, 2D 이미지에 대해서 입력할 텐서의 차원 순서는 [batch size, channels, height, width]입니다. 그래서 딥러닝에서 순방향 전달에 사용하는 컨볼루션 연산같은 모듈도 2D 이미지에 대해서 4D 텐서가 들어가게 됩니다. 참고로 테스트 과정에서 하나의 이미지만 통과할 때에도 [1, 3, H, W] 형식으로 unsqeeze해서 넣어주어야 합니다.
num_workers와 pin_memory
DataLoader 인스턴스를 생성할 때 가끔씩 고려할 인수인 num_workers, pin_memory에 대해 간단하게 짚고 넘어가겠습니다.
DataLoader(..., num_workers=0, collate_fn=None, pin_memory=False, ...)-
num_workers: 데이터를 로드할 때 복수 개의 프로세스로 멀티프로세싱을 수행합니다. 이는 CPU가 데이터를 빠르게 로딩해서 GPU 연산 시간의 비율을 높이기 위한 작업이라고 할 수 있습니다. 물론 이도 너무 높으면 오버헤드가 걸릴 수 있으므로 적당한 숫자를 고르는 것이 중요합니다. 물론 이를 지정하지 않았을 때 더 안정적이라던가, 작은 데이터셋에서는 더 선호되기도 하기 때문에 상황에 맞게 사용하는 것이 좋겠습니다.
-
pin_memory: 이 옵션은 메모리의 데이터를 GPU로 옮길 때의 과정을 단축해 주는 역할을 합니다. 이는
DataLoader가 데이터 샘플들을 host memory가 아닌 page-locked memory로 할당해서 전송 시간을 단축하는 방식입니다. 작은 데이터셋이 아닐 경우에는 일반적으로 효과가 있다고 합니다.
