
이전 포스트들에서는 전체적인 그림에 해당하는 CycleGAN 모델과, 모델들을 학습하기 위해 손실을 계산하고 역전파 알고리즘을 수행하는 코드를 구현하였습니다. 그 다음에 필요한 것은 학습에 필요한 데이터셋일 것입니다. 이 포스트에서는 학습을 하기 위한 재료인 데이터셋을 구성하고, 논문에 적혀 있는 세부적인 사항들을 구현해보겠습니다.
학습 데이터셋으로 DataLoader 구성하기
논문에 사용되는 데이터셋은 여기서 받을 수 있습니다. 그 중 apple2orange.zip 파일의 압축을 풀면 다음과 같은 디렉토리 구조를 볼 수 있습니다.
apple2orange
├── trainA
| └── images...
├── trainB
├── testA
└── testBtrainA, trainB 두 폴더의 이미지를 토대로 미니 배치를 구성하게 됩니다. 여기서 unpaired한 데이터셋을 구성하기 위해 두 스타일의 데이터를 랜덤으로 구성하는 작업이 필요합니다. 이는 다음과 같은 구현을 사용합니다.
class UnpairedDataset(DataLoader):
def __init__(self, dataset_dir, styles, transforms):
self.dataset_dir = dataset_dir
self.styles = styles
self.image_path_A = glob.glob(os.path.join(dataset_dir, styles[0]) + "/*")
self.image_path_B = glob.glob(os.path.join(dataset_dir, styles[1]) + "/*")
self.transform = transforms
def __getitem__(self, index_A):
index_B = random.randint(0, len(self.image_path_B) - 1)
item_A = self.transform(Image.open(self.image_path_A[index_A]))
item_B = self.transform(Image.open(self.image_path_B[index_B]))
return [item_A, item_B]
def __len__(self):
return len(self.image_path_A)- 생성자에서는 root 폴더 내의 두 스타일에 해당하는 학습 폴더들의 리스트를 저장하게 됩니다. 또한, 이미지를 바로 입력에 넣지 않고 텐서로 만들고 정규화하는 작업들을
transform으로 정의하게 되는데, 여기서 사용하는 변형들은 다음과 같습니다.
transform = transforms.Compose(
[
transforms.Resize((args.size, args.size)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
]
)Generator의 제일 뒷단 활성함수가 -1에서 1로 값을 조정하는 tanh이기 때문에, 입력도 -1에서 1로 맞추어주기 위해 Normalize 함수를 구성하게 됩니다. PIL로 불러온 이미지를 ToTensor에 통과하면 0에서 1 사이이므로, 해당하는 범위로 바꾸어 주는 값을 인수로 지정합니다.
그 외에 데이터 증강 기법으로 무작위하게 가로로 뒤집기도 사용합니다. 가로와 달리 세로 뒤집기를 했을 때는 누가 보아도 티가 나기 때문에 사용하지 않습니다.
-
__getitem__메서드에서 unpaired 이미지들을 반환하게 됩니다. trainA은 인덱스로 반환하고, trainB를 랜덤으로 선택해서 반환하도록 합니다. -
__len__는 trainA를 인덱스로 반환하므로, trainA의 크기를 반환하도록 합니다.
이를 사용하기 위해 Dataset과 DataLoader를 train.py에 정의하게 되는데, 이는 다음과 같습니다.
dataloader = DataLoader(
UnpairedDataset(args.dataset_path, ["trainA", "trainB"], transform)
)스케쥴링 적용하기
그 다음은 스케쥴링입니다. 논문에서 언급하는 부분은 다음과 같습니다.

예를 들어서 처음의 LR이 0.5이고, 500 epoch를 학습한다고 했을 때, 101 epoch에서 0.4, 201 epoch에 0.3이 되는 방식으로 볼 수 있습니다. PyTorch에서는 linear하게 감소하는 스케쥴러를 따로 정의해둔 것은 아니라 별도로 lambda 함수로 LambdaLR로 다음과 같이 정의합니다.
lr_lambda = lambda epoch: 1 - ((epoch - 1) // 100) / (args.epoch / 100)
scheduler_G = optim.lr_scheduler.LambdaLR(optimizer=optim_G, lr_lambda=lr_lambda)
scheduler_D_A = optim.lr_scheduler.LambdaLR(
optimizer=optim_D_A, lr_lambda=lr_lambda
)
scheduler_D_B = optim.lr_scheduler.LambdaLR(
optimizer=optim_D_B, lr_lambda=lr_lambda
)epoch가 주어졌을 때 원래 LR에 곱해주는 값을 반환하는 lambda 함수를 만들고, 이를 스케쥴러에 넣는 방식입니다. 세 개의 optimizer를 사용하므로, 스케쥴러도 각각 생성하게 됩니다.
이미지 버퍼 사용하기
논문 내에서 안정적인 학습을 돕기 위해 history 기반 학습을 사용합니다.

즉, 생성한 이미지를 한 번만 사용하는 것이 아니라 버퍼에 저장해서 가져오는 방식으로 보면 되겠습니다. 이는 공식 코드에 사용된 ImagePool로 사용합니다.
pool_fake_A = ImagePool(args.pool_size)
pred_fake_A = netD_B(pool_fake_A.query(fake_A))2번째 줄에 fake_A를 버퍼에 넣으면 query 함수에서 버퍼에 저장되어 있는 무작위의 이미지를 반환해줍니다.
가중치 초기화하기
논문 내에서는 다음과 같이 언급되어 있습니다.

자세한 방법은 여기에 언급되어 있습니다. 네 모델에 다음과 같이 적용합니다.
netG_A2B.apply(init_weight)
netG_B2A.apply(init_weight)
netD_A.apply(init_weight)
netD_B.apply(init_weight)그 외 도움이 되는 구현들
전체적으로 결과 재현에 필요한 학습 파이프라인에 필요한 대부분을 구현하였습니다. 여기서는 부가적으로 구현한 부분들을 간단하게 언급하겠습니다.
- argparse 사용하기: identity loss 사용, dataset path 지정 등 사용하는 유저나 설정 등에 따라 달라질 수 있는데 이를 코드 내에서 다루기보다는 터미널에서 처리하고 싶을 때 사용합니다.
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=500)
parser.add_argument("--batch_size", type=int, default=1)
parser.add_argument("--dataset_path", type=str, default="datasets/apple2orange")
parser.add_argument("--checkpoint_path", type=str, default=None)
parser.add_argument("--size", type=int, default=256)
parser.add_argument("--lambda_ide", type=float, default=10)
parser.add_argument("--lr", type=float, default=2e-4)
parser.add_argument("--pool_size", type=int, default=50)
parser.add_argument("--identity", action="store_true")
args = parser.parse_args()- checkpoint 불러오기: 한 번에 모든 학습을 진행하면 좋겠지만, 갑자기 꺼질 경우 등에 대비하기 위해 구현합니다. 가중치를 불러오는 경우는 argparse로 지정하도록 합니다. 불러올 때는
load_state_dict, 새로 학습할 때에는 가중치 초기화를 하는 코드를 구현합니다.
if args.checkpoint_path is not None:
checkpoint = torch.load(args.checkpoint_path, map_location=device)
netG_A2B.load_state_dict(checkpoint["netG_A2B_state_dict"])
netG_B2A.load_state_dict(checkpoint["netG_B2A_state_dict"])
netD_A.load_state_dict(checkpoint["netD_A_state_dict"])
netD_B.load_state_dict(checkpoint["netD_B_state_dict"])
epoch = checkpoint["epoch"]
else:
netG_A2B.apply(init_weight)
netG_B2A.apply(init_weight)
netD_A.apply(init_weight)
netD_B.apply(init_weight)
epoch = 0- Loss 기록하기: 손실이 줄어드는 것을 확인하면서 학습이 되고 있는지 확인하고 싶을 때 기록하는 코드를 구현해야 합니다. 평균 손실을 기록하고 저장할 때 PyTorch 내의
AverageMeter를 사용하는 것이 편한데, 여기서는 3개의 손실을 보여줄 것이기 때문에 적은 코드를 사용하기 위해LossDisplayer를 따로 구현합니다. 또한 파일로 내보내고, 웹 상에서도 확인하기 위해 TensorBoard 기반 함수들을 활용합니다.
class LossDisplayer:
def __init__(self, name_list):
self.count = 0
self.name_list = name_list
self.loss_list = [0] * len(self.name_list)
def record(self, losses):
self.count += 1
for i, loss in enumerate(losses):
self.loss_list[i] += loss.item()
def get_avg_losses(self):
return [loss / self.count for loss in self.loss_list]
def display(self):
for i, total_loss in enumerate(self.loss_list):
avg_loss = total_loss / self.count
print(f"{self.name_list[i]}: {avg_loss:.4f} ", end="")
def reset(self):
self.count = 0
self.loss_list = [0] * len(self.name_list)disp = LossDisplayer(["G_GAN", "G_recon", "D"])
summary = SummaryWriter()
# Record and display loss
avg_losses = disp.get_avg_losses()
summary.add_scalar("loss_G_GAN", avg_losses[0], epoch)
summary.add_scalar("loss_G_recon", avg_losses[1], epoch)
summary.add_scalar("loss_D", avg_losses[2], epoch)
disp.display()
disp.reset()학습 전체 코드는 여기서 확인할 수 있습니다.
학습하기
코드를 모두 작성했으면 이제 학습할 시간입니다. 학습을 수행하기 위해 다음과 같이 명령어를 입력하면 됩니다.
CUDA_VISIBLE_DEVICES=0 python3 train.py --identity --dataset_path apple2orange이는 0번 CUDA를 지원하는 GPU로 identity loss를 사용하고, dataset 경로로 현재 폴더에 있는 apple2orange 폴더를 사용하는 것으로 볼 수 있습니다. 이를 실행하면 다음과 같이 출력됩니다.
cuda
Epoch 1
G_GAN: 0.7555 G_recon: 8.2069 D: 0.6294
Epoch 2
G_GAN: 0.7297 G_recon: 6.4134 D: 0.4776
Epoch 3
G_GAN: 0.7417 G_recon: 5.9897 D: 0.4722
Epoch 4
G_GAN: 0.7261 G_recon: 5.5554 D: 0.4716
Epoch 5
G_GAN: 0.7799 G_recon: 5.3572 D: 0.4590
Epoch 6
G_GAN: 0.7470 G_recon: 5.1694 D: 0.4494
...이렇게 터미널로 확인할 수도 있지만, 좀 더 쉽게 그래프로 확인하기 위해 기록한 손실들을 불러와서 matplotlib으로 보이도록 해보겠습니다.
from tensorboard.backend.event_processing.event_accumulator import EventAccumulator
import numpy as np
import matplotlib.pyplot as plt
event_acc = EventAccumulator("runs/[만들어진 로그 파일]")
event_acc.Reload()
loss_G_GAN = np.array([[s.step, s.value] for s in event_acc.Scalars('loss_G_GAN')])
loss_G_recon = np.array([[s.step, s.value] for s in event_acc.Scalars('loss_G_recon')])
loss_D =np.array([[s.step, s.value] for s in event_acc.Scalars('loss_D')])
plt.subplot(131)
plt.title("loss_G_GAN")
plt.plot(loss_G_GAN[:, 0], loss_G_GAN[:, 1])
plt.subplot(132)
plt.title("loss_G_recon")
plt.plot(loss_G_recon[:, 0], loss_G_recon[:, 1])
plt.subplot(133)
plt.title("loss_D")
plt.plot(loss_D[:, 0], loss_D[:, 1])
plt.show()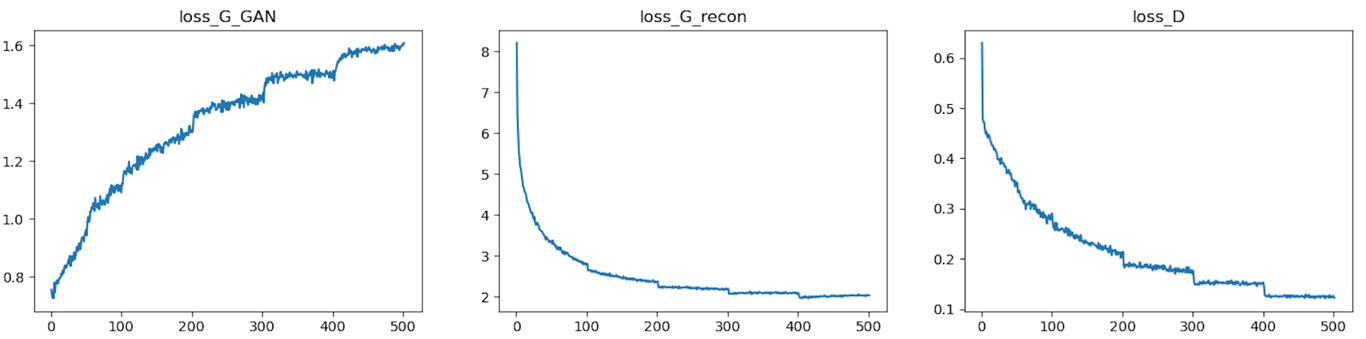
일단 재구성하는 손실(cycle, identity)가 낮아지는 것으로 보았을 때 학습이 되는 것으로 볼 수 있습니다. 그런데, generator의 GAN 손실은 증가하는 것을 확인할 수 있습니다. 반면 Discriminator는 잘 학습되는 것으로 볼 수 있습니다.
