
관련 포스트에서 관련 개념에 대해 설명했으니 참고하시면 됩니다. 미세 조정으로 보면 되나, 여기서는 파인튜닝으로 표현하겠습니다.
여기서는 일반적인 사진으로 구성된 ImageNet으로 학습된 모델을 사용해서 개와 고양이로 이루어진 적은 사진 데이터에 대해 파인튜닝을 수행해 보겠습니다. 여기서 사용할 데이터셋은 여기서 받을 수 있습니다.
사전 학습된 모델을 불러오고 설정하기
그저 가중치를 불러올 뿐만 아니라, 분류 모델에서 일부 레이어들을 고정하고 분류할 클래스 수에 맞추어 말단 레이어를 수정하는 과정이 필요합니다.
학습할 수 있도록 하는 모델을 불러오는 방법은 그저 학습된 모델 자체를 불러오거나, 모델을 선언한 뒤 state_dict를 불러오는 방법이 있습니다. 여기에서는 torchvision을 이용해서 간단하게 EfficientNet을 불러오도록 하겠습니다.
model = models.efficientnet_b0(pretrained=True)이를 활용하면 pretrained=True를 명시하는 것만으로 가중치가 불러와집니다. torchvision에서는 더 많은 모델들은 제공하고 있는데 여기를 참고해주세요.
이제 여기에서 얼마만큼 모델의 가중치를 고정시키고, 학습할 것인지 결정합니다. 여기서는 fully-connected 레이어만 학습 가능하도록 했는데, 해당하는 코드는 다음과 같습니다.
for param in model.parameters():
param.requires_grad = False
model.classifier[0].requires_grad = True
model.classifier[1] = nn.Linear(1280, 2)모델 내의 각 레이어의 가중치에 접근하기 위해 parameters 메서드를 사용합니다. requires_grad를 False로 설정해서 가중치를 고정합니다.
또한, 개와 고양이 단 두개의 클래스를 사용하므로, 마지막 단 출력 노드 수를 2개로 새로 정의합니다. 아니면 결과 노드 수를 하나로 두개, 개일 때 1 고양이일 때 0으로 학습하는 binary cross entropy로도 사용할 수 있습니다.
학습 과정 구현하기
모델을 사용 가능하게 만들었으면, 학습 파이프라인을 구성하면 됩니다. 이는 일반적으로 모델 학습하는 방법과 동일합니다.
먼저 데이터셋부터 만들겠습니다. 이전에 만든 구조와 동일합니다.
dataset.py
import os
import torchvision.transforms as transforms
from torch.utils.data import Dataset
from PIL import Image
class DogCatDataset(Dataset):
def __init__(self, data_dir="train"):
self.data_dir = data_dir
self.image_path_list = os.listdir(data_dir)
self.transform = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
def __getitem__(self, index):
image_path = os.path.join(self.data_dir, self.image_path_list[index])
x_data = Image.open(image_path)
x_data = self.transform(x_data)
y_data = 1 if "dog" in self.image_path_list[index] else 0
return x_data, y_data
def __len__(self):
return len(self.image_path_list)학습을 위한 설정들입니다. 학습과 검증에 사용할 DataLoader를 만들고 손실, optimizer 등을 정의합니다.
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(self.device)
dataset = DogCatDataset()
train_dataset, self.val_dataset, _ = random_split(
dataset, [100, 900, 24000]
)
train_loader = DataLoader(self.train_dataset, batch_size=8, shuffle=True)
val_loader = DataLoader(self.val_dataset, batch_size=64, shuffle=False)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)참고로 작은 데이터셋에 robust함을 보이기 위해 학습 이미지의 수를 100개로 두고, 조금 더 정확한 검증을 위해 900개의 검증 이미지를 둡니다. 나머지 24000개는 사용하지 않도록 구성했습니다.
그 다음 모델을 학습하는 과정을 구현합니다.
for epoch in range(10):
model.train()
train_total_loss = 0.0
train_correct = 0
for images, labels in self.train_loader:
images = images.to(self.device)
labels = labels.to(self.device)
outputs = model(images)
predicted = torch.max(outputs, 1)[1]
loss = self.criterion(outputs, labels)
train_total_loss += loss.item()
train_correct += (labels == predicted).sum().cpu()
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
val_total_loss = 0.0
val_correct = 0
with torch.no_grad():
for images, labels in self.val_loader:
images = images.to(self.device)
labels = labels.to(self.device)
outputs = model(images)
predicted = torch.max(outputs, 1)[1]
loss = self.criterion(outputs, labels)
val_total_loss += loss.item()
val_correct += (labels == predicted).sum().cpu()
train_loss = train_total_loss / len(self.train_loader)
train_accuracy = train_correct / len(self.train_dataset)
val_loss = val_total_loss / len(self.val_loader)
val_accuracy = val_correct / len(self.val_dataset)
print(
f"epoch {epoch+1}:\t",
f"train_loss: {train_loss:.4f},",
f"train_accuracy: {train_accuracy:.4f},",
f"val_loss: {val_loss:.4f},",
f"val_accuracy: {val_accuracy:.4f}",
)추가적으로 터미널에서 학습과 검증 데이터셋에 대해 손실과 정확도를 나타내기 위해 추가적인 변수들을 사용하였음을 참고하면 됩니다. 한 에포크 학습이 끝날 때마다 검증 데이터셋에 대해 확인하도록 했습니다.
이렇게 파이프라인을 구성하고 실행하면 다음과 같이 출력됩니다.
cuda
epoch 1: train_loss: 0.6008, train_accuracy: 0.7100, val_loss: 0.4670, val_accuracy: 0.8922
epoch 2: train_loss: 0.4392, train_accuracy: 0.8800, val_loss: 0.3800, val_accuracy: 0.9156
epoch 3: train_loss: 0.2999, train_accuracy: 0.9500, val_loss: 0.3224, val_accuracy: 0.9244
epoch 4: train_loss: 0.2688, train_accuracy: 0.9500, val_loss: 0.2900, val_accuracy: 0.9211
epoch 5: train_loss: 0.2527, train_accuracy: 0.9500, val_loss: 0.2767, val_accuracy: 0.9333
epoch 6: train_loss: 0.2149, train_accuracy: 0.9700, val_loss: 0.2561, val_accuracy: 0.9278
epoch 7: train_loss: 0.1936, train_accuracy: 0.9800, val_loss: 0.2463, val_accuracy: 0.9367
epoch 8: train_loss: 0.2182, train_accuracy: 0.9700, val_loss: 0.2268, val_accuracy: 0.9344
epoch 9: train_loss: 0.1594, train_accuracy: 0.9500, val_loss: 0.2354, val_accuracy: 0.9356
epoch 10: train_loss: 0.2130, train_accuracy: 0.9200, val_loss: 0.2324, val_accuracy: 0.9356검증 데이터셋에 대해 94% 정도의 정확도가 나오면서 학습이 잘 수행되었음을 알 수 있습니다.
여러 정책들 비교하기
그런데 파인튜닝이 잘 되었는지 비교할 대조군을 만들지는 않았습니다. 처음부터 scratch로 학습하는 게 좋을 수도 있고, pretrained 모델을 불러와 모든 레이어를 학습하도록 할 때 더 좋을 수도 있을 것입니다.
그래서 간단하게 세 가지 상황(scratch 학습, 모든 레이어 파인튜닝, FC 레이어 파인튜닝)에 대해 비교해 보도록 간단하게 구현하겠습니다.
이를 구현하기 위해 사용할 모델들을 정의하도록 하겠습니다.
models.py
import torch.nn as nn
import torchvision.models as models
def efficientnet_b0_scratch():
model = models.efficientnet_b0(pretrained=False)
model.classifier[1] = nn.Linear(1280, 2)
return model
def efficientnet_b0_fine_tune_all():
model = models.efficientnet_b0(pretrained=True)
model.classifier[1] = nn.Linear(1280, 2)
return model
def efficientnet_b0_fine_tune_classifier():
model = models.efficientnet_b0(pretrained=True)
for param in model.parameters():
param.requires_grad = False
model.classifier[0].requires_grad = True
model.classifier[1] = nn.Linear(1280, 2)
return model세 가지 상황에 대해 구현하였고, 말단 레이어 출력 노드 수는 2인 것은 동일합니다.
각 모델에 대해서 optimizer만 따로 필요하고, 나머지 데이터셋이나 학습 과정 등은 모두 동일합니다. 불필요한 코드를 줄이기 위해 모델과 optimizer가 주어졌을 때 학습하고 결과를 출력해 주도록 코드를 구성하면 다음과 같습니다.
def train():
exp_names = ["scratch", "tune_all", "tune_classifier"]
model0 = efficientnet_b0_scratch()
model1 = efficientnet_b0_fine_tune_all()
model2 = efficientnet_b0_fine_tune_classifier()
optimizer0 = torch.optim.Adam(model0.parameters(), lr=1e-3)
optimizer1 = torch.optim.Adam(model1.parameters(), lr=1e-3)
optimizer2 = torch.optim.Adam(model2.parameters(), lr=1e-3)
trainer = Trainer()
r0 = trainer.train_model(exp_names[0], model0, optimizer0)
r1 = trainer.train_model(exp_names[1], model1, optimizer1)
r2 = trainer.train_model(exp_names[2], model2, optimizer2)
visualize(exp_names, [r0, r1, r2])세 상황에 대해 모델과 optimizer를 구성하고, 모델을 학습하는 데 Trainer 클래스를 사용했습니다. Trainer의 생성자에는 데이터셋, DataLoader, 손실 등이 들어가고, train_model 메서드로 모델을 학습합니다. 이 코드들은 위의 학습 파이프라인을 토대로 구성하면 됩니다.
이를 완성한 뒤 터미널에서 실행하면 다음과 같이 출력됩니다.
cuda
scratch
epoch 1: train_loss: 0.9321, train_accuracy: 0.5100, val_loss: 0.6934, val_accuracy: 0.4989
epoch 2: train_loss: 0.7457, train_accuracy: 0.5200, val_loss: 0.6943, val_accuracy: 0.4989
epoch 3: train_loss: 0.7604, train_accuracy: 0.4700, val_loss: 0.7049, val_accuracy: 0.5011
epoch 4: train_loss: 0.7056, train_accuracy: 0.5300, val_loss: 0.6926, val_accuracy: 0.5011
epoch 5: train_loss: 0.7342, train_accuracy: 0.5600, val_loss: 0.7106, val_accuracy: 0.4978
epoch 6: train_loss: 0.6573, train_accuracy: 0.6200, val_loss: 0.7573, val_accuracy: 0.5056
epoch 7: train_loss: 0.6714, train_accuracy: 0.6000, val_loss: 0.9880, val_accuracy: 0.5744
epoch 8: train_loss: 0.6740, train_accuracy: 0.5900, val_loss: 1.5609, val_accuracy: 0.5411
epoch 9: train_loss: 0.6525, train_accuracy: 0.7200, val_loss: 1.5163, val_accuracy: 0.5700
epoch 10: train_loss: 0.5836, train_accuracy: 0.7500, val_loss: 0.8283, val_accuracy: 0.5267
tune_all
epoch 1: train_loss: 0.4827, train_accuracy: 0.7400, val_loss: 0.1176, val_accuracy: 0.9522
epoch 2: train_loss: 0.1911, train_accuracy: 0.9200, val_loss: 0.3973, val_accuracy: 0.8611
epoch 3: train_loss: 0.2415, train_accuracy: 0.8800, val_loss: 0.4145, val_accuracy: 0.8567
epoch 4: train_loss: 0.2460, train_accuracy: 0.9400, val_loss: 0.2989, val_accuracy: 0.8811
epoch 5: train_loss: 0.3336, train_accuracy: 0.9100, val_loss: 0.2961, val_accuracy: 0.8467
epoch 6: train_loss: 0.1922, train_accuracy: 0.9300, val_loss: 0.3620, val_accuracy: 0.8422
epoch 7: train_loss: 0.0724, train_accuracy: 0.9900, val_loss: 0.3439, val_accuracy: 0.8589
epoch 8: train_loss: 0.1294, train_accuracy: 0.9300, val_loss: 0.3729, val_accuracy: 0.8600
epoch 9: train_loss: 0.1878, train_accuracy: 0.9500, val_loss: 0.6183, val_accuracy: 0.7722
epoch 10: train_loss: 0.1224, train_accuracy: 0.9400, val_loss: 0.3176, val_accuracy: 0.8722
tune_classifier
epoch 1: train_loss: 0.6437, train_accuracy: 0.6600, val_loss: 0.4999, val_accuracy: 0.8822
epoch 2: train_loss: 0.5181, train_accuracy: 0.7600, val_loss: 0.4053, val_accuracy: 0.9144
epoch 3: train_loss: 0.4232, train_accuracy: 0.8800, val_loss: 0.3748, val_accuracy: 0.9011
epoch 4: train_loss: 0.3855, train_accuracy: 0.9000, val_loss: 0.3436, val_accuracy: 0.9211
epoch 5: train_loss: 0.3051, train_accuracy: 0.9200, val_loss: 0.3301, val_accuracy: 0.9267
epoch 6: train_loss: 0.2976, train_accuracy: 0.9000, val_loss: 0.3122, val_accuracy: 0.9244
epoch 7: train_loss: 0.2431, train_accuracy: 0.9600, val_loss: 0.3028, val_accuracy: 0.9244
epoch 8: train_loss: 0.2620, train_accuracy: 0.8900, val_loss: 0.3008, val_accuracy: 0.9211
epoch 9: train_loss: 0.2173, train_accuracy: 0.9700, val_loss: 0.2892, val_accuracy: 0.9211
epoch 10: train_loss: 0.2366, train_accuracy: 0.9400, val_loss: 0.2729, val_accuracy: 0.9211세 상황에 대해 학습이 이루어진 것을 알 수 있습니다. 참고로 가중치, 데이터셋 분할 등이 다르기 때문에 위의 상황과 정확하게 일치하지 않을 수 있는 점을 참고해 주세요.
위 출력들을 시각화하면 다음과 같이 나옵니다.
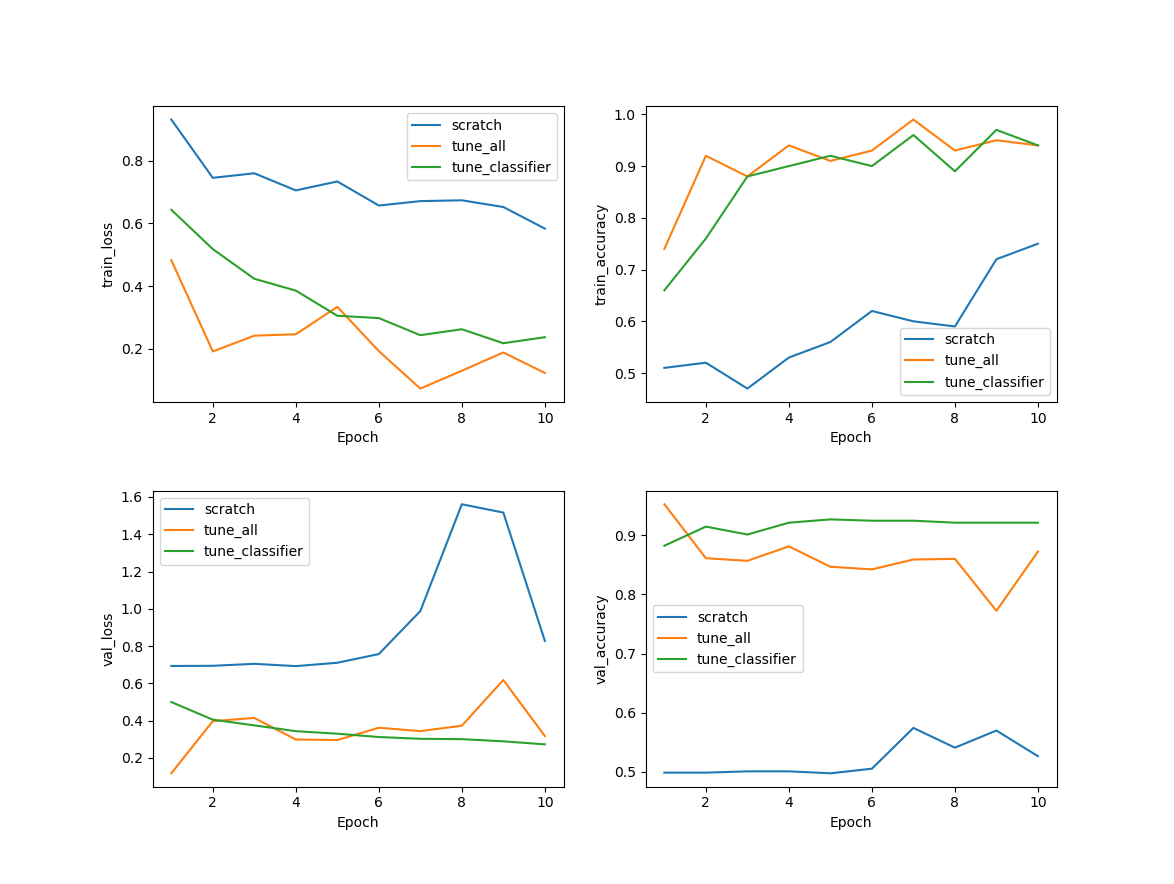
이를 간단하게 분석해보겠습니다.
-
scatch부터 학습된 경우 loss도 꽤 위에서부터 내려오고, 전체적인 정확도가 다른 상황들보다 낮은 것을 알 수 있습니다. 그리고 학습 정확도는 올라가는 데 반해 검증 정확도는 크게 오르지 않는 점을 알 수 있습니다.
-
모든 레이어를 학습 가능하게 했을 때 학습 손실은 잘 내려가고 정확도는 올라가는 것을 볼 수 있습니다. 그런데 검증 데이터를 보면 손실은 1 epoch에서 제일 낮고, 정확도도 높은데 epoch가 증가할수록 성능이 나빠집니다. 전형적인 과적합이라고 볼 수 있습니다.
-
일부 레이어만 튜닝한 방식이 안정적이고 검증 데이터셋에 대해서도 좋은 성능을 보이는 것을 알 수 있습니다.
여기서는 Fully-connected 레이어들만 학습하는 것이 제일 좋은 결과가 나왔습니다. 여기서 데이터셋의 종류, 양 또는 학습양에 따라 결과가 달라질 수 있습니다. 그래서 각 상황에 대해 실험을 해보는 것이 좋습니다.
전체 코드는 여기서 확인할 수 있습니다.
