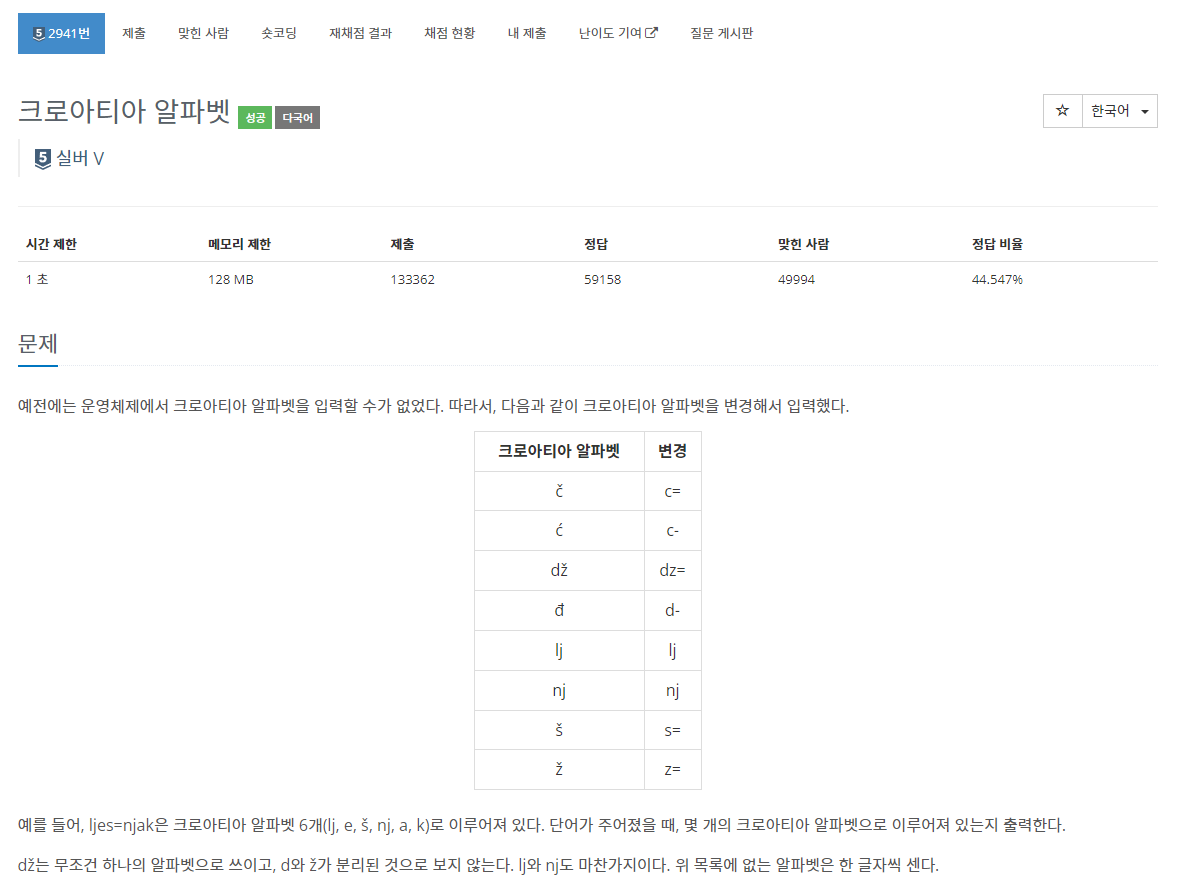
백준#2941
1. 내 코드
words = input()
c_al = ["c=", "c-", "dz=", "d-", "lj", "nj", "s=", "z="]
cnt = 0
for al in c_al:
# words = words.strip()
if al in words:
cnt += 1
words = words.replace("%s"%al, "")
# print(al, words)""
# print("words: ", words)
for arg in words:
# print(arg)
cnt += 1
print(cnt)2. 풀이
words = input()
c_al = ["c=", "c-", "dz=", "d-", "lj", "nj", "s=", "z="]
for al in c_al:
if al in words:
words = words.replace("%s"%al, "*")
print(len(words))3. 반성점
💡 새로 카운트할 생각만 해서 실제로 단어의 길이를 줄일 생각을 하지 못 했다
4. 배운점
💡 내 코드 상에서는 제거된 단어, 즉 재조합된 단어에 크로아티아어가 존재할 경우 이를 크로아티아어로 보았다. 이를 방지하기 위해 크로아티아어를 아예 삭제하지 않고 새로운 단어로 대체하는 방식을 사용해야했다
