📌 Using Pretrained Models From Keras
1. Pretrained networks: keras.applications package
🔅 keras.applications 패키지에서 다양한 pretrained CNN network 제공
model = keras.applications.resnet50.ResNet50(weights="imagenet")1) Create a ResNet-50 model and download weights pretrained on the ImageNet dataset
🔅 imagenet으로 학습된 데이터는 대부분의 데이터의 low level feature에 적용 가능
2) Pretrained parameters: expects 224x224 images => use Tensorflow's tf.image.resize(); tf.image.crop_and_resize() to keep aspect ratio
🔅 pretrained의 이미지가 224x224이므로 새로운 데이터의 크기도 224x224로 만들어줘야함
images_resized = tf.image.resize(images, [224,224])3) Using a preprocess_input() function for each model, preprocess your images. Pixel values range from 0 to 255
🔅 keras applications에 있는 모든 pretrained model들은 preprocess_input()이라는 함수 존재해 pixel이 0~255까지의 값을 갖도록 함
inputs = keras.applications.resnet50.preprocess_input(images_resized * 255)4) make predictions
Y_proba = model.predict(inputs)5) Y_proba : matrix with # of images (row)x # of class (column) (in this case, 1,000 classes)
🔅 이미지 숫자만큼의 row, class 개수만큼의 column을 갖는 matrix 형태
🔅 Ex. 이미지가 100개가 있을 경우, imagenet의 class는 1000이므로 100x1000 matrix 출력
6) decode_predictions() function: display the top K predictions, including the class name and the estimated probability
🔅 확률이 높은 class K개를 보여줌
top_K = keras.applications.resnet50.decode_predictions(Y_proba. top=3)
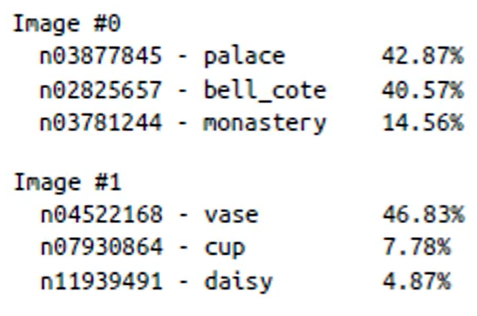
for image_index in range(len(images)): #보기좋게 출력
print("Image #{}".format(image_index))
for class_id, name, y_proba in top_K[image_index]:
print("{} - {:12s} {:.2f}%".format(class_id, name, y_proba * 100))
print()🔅 결과
top=3이므로 3개씩 출력됨
📌 Pretrained Models for Transfer Learning
1. Building an image classifier without enough training data
1) Reuse the lower layers of a pretrained model
2) Ex. reusing a pretrained MobileNet model
🔅 get information about the dataset
import tensorflow_datasets as tfds
dataset, info = tfds.load("tf_flowers", as_supervised=True, with_info=True) #as_supervised=True => supervised learning 방식, information도 함께 load
dataset_size = info.split["train"].num_examples #3670
class_names = info.features["labels"].names #["dandelion", "daisy", ...]
n_classes = info.features["labels"].num_classes #5🔅 split the training set to train/validation/test dataset
test_split, valid_split, train_split = tfds.Split.TRAIN.subsplit([10,15,75]) #10%, 15%, 75%로 나눔
test_set = tfds.load("tf_flowers", split=test_split, as_supervised=True)
valid_set = tfds.load("tf_flowers", split=valid_split, as_supervised=True)
train_set = tfds.load("tf_flowers", split=train_split, as_supervised=True)🔅 preprocess image: 224x224 images
train, valid, test 3개의 datasets에 모두 preprocessing 진행
def preprocess(image, label):
resized_image = tf.image.resize(image, [224,224])
final_image = keras.applications.mobilenet.preprocess_input(resized_image) #resized_image 값이 0~255까지의 값이므로 255를 곱할 필요 없음
return final_image, label🔅 shuffle & repeat training set + add batching & prefetching to all datasets
batch_size = 32 #mini batch 하나에 32개의 instance 존재
# shuffle 함수의 parameter는 shuffle buffer size. 한번에 몇개를 넣어 shuffle할 것인가
train_set = train_set.shuffle(1000).repeat()
# prefetch next batch for performance. 다음에 진행될 batch를 미리 메모리에서 버퍼로 가져오고 이 것이 preprocess를 진행한 후 해당 변수로 들어옴
train_set = train_set.map(preprocess).batch(batch_size).prefetch(1)
valid_set = valid_set.map(preprocess).batch(batch_size).prefetch(1)
test_set = test_set.map(preprocess).batch(batch_size).prefetch(1)🔸 data augmentation: change the preprocessing function and adding random transformations to training images
🔸 Ex. tf.image.random_crop(): random crop, tf.image.random_flip_left_right(): random horizontal flip
🔅 Load an MobileNet model, pretrained on ImageNet
# include_top=False => excludes global average pooling layer and dense output layer
base_model = keras.applications.mobilenet.MobileNet(weights="imagenet", include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output) #our own global average pooling layer
output = keras.layers.Dense(n_classes, activation="softmax")(avg) #output: classification
model = keras.models.Model(inputs=base_model.input, outputs=output) #model creation💡 생성한 모델은 mobilenet과 같은 구조이지만, global average pooling과 output 앞의 weight는 고정되어있고 global average pooling과 output은 새로운 데이터를 이용한 학습을 통해 최적의 weight를 구하도록 함
🔅 Freezing trained layers
전체 layer의 parameter 값이 변하면 안되기 때문에 global average pooling 이전의 layer는 고정시킴
for layer in base_model.layers:
layer.trainable = False🔸 base_model.trainable = False가 아니라 위의 코드처럼 작성해야함. base_model.trainable은 base model에 직접적으로 적용하는 것이고, 하고자하는 것은 mobilenet의 object를 빌리는 것이므로 위의 코드 사용
🔅 Model compile and training
optimizer = keras.optimizers.SGD(lr=0.2, momentum=0.9, decay=0.01)
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"])
history = model.fit(train_set, steps_per_epoch = int(0.75*dataset_size/batch_size), validation_data=valid_set, validation_steps=int(0.15*dataset_size/batch_size), epochs=5)🔸 Heavy computing: better to run in GPU environment or using colab
🔅 epoch 수를 늘리고 early stopping 하는 것이 좋음
🔅 After a few epochs, validation accuracy about 75-80%, and stop making much progress
🔅 Top layers are now pretty well trained => ready to unfreeze all layers or just the top ones. => freeze시켰던 layer 중 top layer를 한 두개씩 풀어 parameter 값을 조정. 값이 조금 변할 경우 모두 풀어도 되지만, 값이 많이 변할 때 모든 layer를 풀면 parameter가 엉망이 될 수도 있음
🔅 Continue training (after compile the model) with a much lower learning rate to avoid damaging the pretrained weights => 위에서 지정한 optimizer보다 learning rate를 작게 하는 것이 regularization 역할을 하므로 작게 만들어야함
for layer in base_model.layers:
layer.trainable = True
optimizer = keras.optimizers.SGD(lr=0.01, momentum=0.9, decay=0.001)
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"])
history = model.fit(train_set, steps_per_epoch = int(0.75*dataset_size/batch_size), validation_data=valid_set, validation_steps=int(0.15*dataset_size/batch_size), epochs=5)