상속 관계 매핑
논리적인 수퍼타입, 서브타입을 물리적인 테이블로 구현할때는 아래의 세가지 전략중 하나를 선택할 수 있다.
-
각각의 테이블로 변환(Identity)
각각을 모두 테이블로 만들고조회할 때 조인을 사용한다. JPA에서는 조인 전략이라 한다. -
단일 테이블로 변환(Roll Up)
테이블을 하나만 사용해서 통합한다. JPA 에서는 단일 테이블 전략이라 한다. -
구현 클래스마다 테이블 전략 (Roll Down)
서브 타입마다 하나의 테이블을 만든다. JPA에서는 구현 클래스마다 테이블 전략이라 한다.
Join 전략
Item을 Album, Movie, Book 이 상속하는 관계일때 이를 JPA Join 전략을 써서 DB와 매핑하는 방법을 알아보자.
이때 각각의 피상속 엔티티의 PK는 Item의 ID가 되도록 한다.
Join 전략 구현하기
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "DTYPE")
@Getter @Setter
public abstract class Item {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ITEM_ID")
private Long id;
private String name;
private int price;
}
@Entity
@DiscriminatorValue("A")
@Getter @Setter
public class Album extends Item {
private String artist;
}
@Entity
@DiscriminatorValue("M")
@Getter @Setter
public class Movie extends Item {
private String director;
private String actor;
}
@Entity
@DiscriminatorValue("B")
@PrimaryKeyJoinColumn(name = "BOOK_ID")
@Getter @Setter
public class Book extends Item {
private String author; //작가
}-
@Inheritance(strategy = InheritanceType.JOINED)
상속관계를 매핑하는 전략중 어떤 것을 사용할지 정한다. -
@DiscriminatorColumn(name = "DTYPE")
피상속 객체들을 구분할 칼럼의 이름을 지정한다. -
@DiscriminatorValue("A")
Item 테이블에서 DTYPE 칼럼에 Album이 생기면 A가 입력되도록 한다. -
@PrimaryKeyJoinColumn(name = "BOOK_ID")
이 설정이 없으면 Book 테이블에 PK이자 FK인 칼럼의 이름은 ITEM_ID가 됐을 것이다. 이 설정을 할면 BOOK_ID 가 된다.
Join 전략 시행하기
DB를 잘 모르는 내 입장에서는 책에 있는 설명으로는 이해가 되지 않았기 때문이다. Auto DDL을 켜놓고 엔티티를 등록하면서 만들어지는 테이블을 살펴봤다.
public class Main {
static EntityManagerFactory emf =
Persistence.createEntityManagerFactory("jpabook");
public static void main(String[] args) {
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
Album A = new Album();
Movie M = new Movie();
Book B = new Book();
A.setArtist("John");
A.setName("John Album");
M.setActor("James");
M.setName("James Movie");
B.setAuthor("Michael");
B.setName("Michael Book");
em.persist(A);
em.persist(M);
em.persist(B);
tx.commit();
emf.close();
}
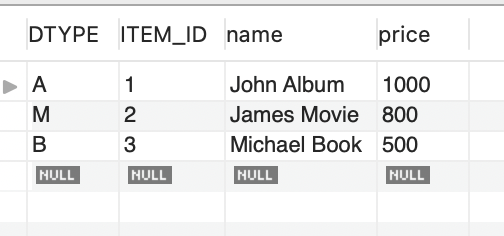
}그 결과 Item 테이블은 다음과 같이 만들어졌다. 이제야
@DiscriminatorColumn(name = "DTYPE") 과 @DiscriminatorValue("A")이 하는 역할이 뭔지 이해가 되었다.

Album 테이블은 ITEM_ID 칼럼이 있는데,
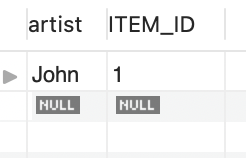
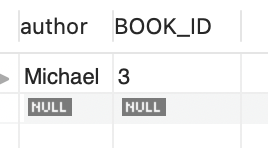
Book 테이블은 ITEM_ID 칼럼이 아닌 BOOK_ID 칼럼이 있었다. 둘은 이름만 다르지 하는 기능은 동일하다.
Join 전략 장단점
■ 장점
- 테이블이 정규화된다.
- 외래 키 참조 무결성 제약조건을 활용할 수 있다.
- 저장공간을 효율적으로 사용한다.
■ 단점
- 조회할 때 조인이 많이 사용되므로 성능이 저하될 수 있다. - 조회 쿼리가 복잡하다.
- 데이터를 등록할 INSERT SQL을 두 번 실행한다.
단일 테이블 전략
단일 테이블 전략(Single-Table Strategy)은 테이블을 하나만 사용한다. 그리고 구분 컬럼(DTYPE)으로 어떤 자식 데이터가 저장되었는지 구분 한다. 조회할 때 조인을 사용하지 않으므로 일반적으로 가장 빠르다.
이 전략을 사용할 때 주의점은 자식 엔티티가 매핑한 컬럼은 모두 null을 허용 해야 한다는 점이다
단일 테이블 전략 구현
Item 엔티티의 상속 전략 SINGLE_TABLE로 변경하고, Book의 @PrimaryKeyJoinColumn(name = "BOOK_ID") 를 주석처리하자
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "DTYPE")
@Getter @Setter
public abstract class Item {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ITEM_ID")
private Long id;
private String name;
private int price;
}단일 테이블 전략 시행
이전에 만들어뒀던 테이블들을 모두 없애고
DROP TABLE Book;
DROP TABLE Album;
DROP TABLE Movie;
SET foreign_key_checks = 0;
DROP TABLE Item;
SET foreign_key_checks = 1;위와 동일한 main문을 시행하면 단일 Item 테이블이 생성된다. 관련된 서브 테이블들이 모두 하나로 뭉쳐져 있다.
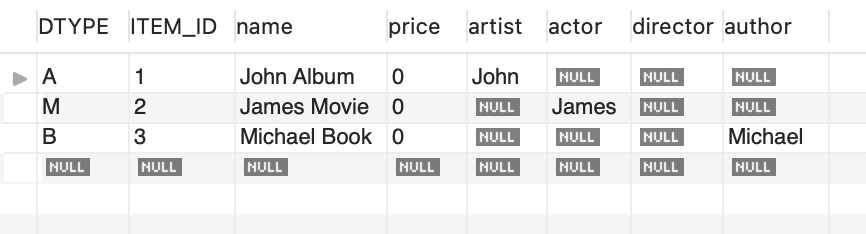
단일 테이블 전략 장단점
■ 장점
- 조인이 필요 없으므로 일반적으로 조회 성능이 빠르다. - 조회 쿼리가 단순하다.
■ 단점
- 자식 엔티티가 매핑한 컬럼은 모두 null을 허용해야 한다.
- 단일 테이블에 모든 것을 저장 하므로 테이블이 커질 수 있다. 그러므로 상황에 따라서는 조회 성능이 오히려 느려질 수 있다.
■ 특징
- 구분 컬럼을 꼭 사용해야 한다. 따라서 @DiscriminatorColumn을 꼭 설정해야 한다.
- @DiscriminatorValue를 지정하지 않으면 기본으로 엔티티 이름을 사용한다. (예 Moive, Album, Book)
구현 클래스마다 테이블(Roll Down) 전략
Roll Down 구현
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
@DiscriminatorColumn(name = "DTYPE")
@Getter @Setter
public abstract class Item {Roll Down 장단점
■ 장점
- 서브 타입을 구분해서 처리할 때 효과적이다. - not null 제약조건을 사용할 수 있다.
■ 단점
- 여러자식테이블을함께조회할때성능이느리다(SQL에UNION을사용해야한다). - 자식 테이블을 통합해서 쿼리하기 어렵다.
■ 특징
- 구분 컬럼을 사용하지 않는다.
이 전략은 데이터베이스 설계자와 ORM 전문가 둘 다 추천하지 않는 전략이다. 조인이나 단일 테이블 전략을 고려하자.
정확히 모르는 개념
(DB)슈퍼타입, 서브타입 관계
수퍼 타입이 서브 타입들의 공통된 속성들을 가지고 있고 서브 타입은 고유한 속성들만 가지고 있는 형태이다.
객체의 상속관계와 엄청 비슷하다.
이걸 테이블로 관리하는 방법에는 3가지가 있다.
-
RollUp
하나의 테이블로 묶여서 관리하기
[장점]
조인할 일이 없으므로 SQL문장 구성이 단순, 수행속도가 빨라지는 경우가 많다.
서브타입을 구분하지 않고 데이터를 조회할 경우 처리가 용이하다.
[단점]
특정 서브타입의 NOT NULL 제한 불가(NULL값이 많아질 수 있다) -
RollDown
각 서브 타입 별로 테이블을 만들고 수퍼 타입의 속성을 포함하게 만든다.
[장점]
정보를 각 서브타입 별로 조작할 경우, 조인하지 않아도 되며 Full Scan 발생시 유리.
관계에 의해 발생하는 복잡한 참조 무결성 규칙을 적용할 수 있다.
[단점]
처리속도 감소할 수 있다.
UID 유지 관리가 어렵다.
- Identity
슈퍼타입과 서브타입 각각을 테이블로 생성.
[장점]
각각의 테이블로 처리할 경우, 수행 속도가 빠르다.
슈퍼 타입에 속한 정보만 조회하는 경우, 문장 작성이 용이하다.
컬럼의 중복이 적으므로, 상대적으로 작은 공간을 차지한다.
관계에 의해 발생하는 복잡한 참조 무결성 규칙을 적용할 수 있다.
외래 키 참조 무결성 제약조건
무결성 제약조건중 참조 무결성을 이야기하는 것이다.
참조 무결성이란 외래키는 참조할 수 없는 값을 가질 수 없다는 규칙입니다. 외래키는 다른 릴레이션의 기본키를 참조하는 속성이고 릴레이션 간의 관계를 표현하는 역할을 합니다. 그런데 외래키가 자신이 참조하는 릴레이션의 기본키와 상관없는 값을 가지게 되면 두 릴레이션을 연관시킬 수 없으므로 외래키 본래의 의미가 없어집니다.
