공부의 기록 시리즈는 공유하고자 적는 글이 아닙니다. 공부할때 필기 하는 습관이 있고, 모르는 내용을 메모할 공간이 필요하기 때문에 적는 글입니다. 나중에 이 글을 잘 정제하고 편집해서 공유를 위한 글을 따로 포스팅합니다.
JPA에서 가장 중요한 일은 엔티티와 테이블을 정확히 매핑하는 것이다.
JPA는 다양한 매핑 어노테이 션을 지원하는데 크게 4가지로 분류할 수 있다.
■ 객체와 테이블 매핑: @Entity, @Table
■ 기본키매핑:@Id
■ 필드와 컬럼 매핑: @Column
■ 연관관계 매핑: @ManyToOne, @JoinColumn
연관관계 매핑은 다른 포스팅에서 다룬다.
XML을 이용해서 매핑하는 방법이 있다고 한다. 알아보자.
@Entity
JPA를 사용해서 테이블과 매핑할 클래스는 @Entity 어노테이션을 필수로 붙여야 한다.
@Entity 에는 name 속성이 있는데, 엔티티의 이름을 지정하는 것이다. 보통 기본값으로 클래스 이름을 이용한다. 그런데 만약에 다른 패키지에 동일한 이름의 엔티티 이름이 있다면 다르게 설정해야 할 것이다.
@Entity 를 사용할때는 다음의 주의사항이 있다.
■ 기본 생성자는 필수다(파라미터가 없는 public 또는 protected 생성자).
■ final 클래스, enum, interface, inner 클래스에는 사용할 수 없다.
■ 저장할 필드에 final을 사용하면 안 된다.
@Table
엔티티와 매핑할 테이블을 지정한다. 생략하면 매핑한 엔티티 이름을 테이블 이름으로 사용한다.
@Table에는 다음과 같은 속성이 있다.
name : 매핑할 테이블의 이름, 기본값은 클래스명이다.
catalog : catalog 기능이 있는 데이터베이스에서 catalog를 매핑한다.
schema : schema 기능이 있는 데이터베이스에서 schema를 매핑한다.
다양한 매핑 사용
기존에 사용하던 Member 엔티티에 등급 구분, 가입일과 수정일, 회원을 설명하는 필드가 추가되었다.
import javax.persistence.*;
import java.util.Date;
@Entity
@Table(name="MEMBER")
public class Member {
@Id
@Column(name = "ID")
private String id;
@Column(name = "NAME")
private String username;
private Integer age;
@Enumerated(EnumType.STRING)
private RoleType roleType;
@Temporal(TemporalType.TIMESTAMP)
private Date createdDate;
@Temporal(TemporalType.TIMESTAMP)
private Date lastModifiedDate;
@Lob
private String description;
//getter setter
}
public enum RoleType {
ADMIN, USER
}
이때 추가된 매핑 에노테이션은 다음과 같다.
@Enumerated(EnumType.STRING)
자바의 enum을 사용하려면 @Enumerated 어노테이션으로 매핑해야 한다.@Temporal(TemporalType.TIMESTAMP)
자바의 날짜 타입은 @Temporal을 사용해서 매핑한다.@Lob
회원을 설명하는 필드는 길이 제한이 없다. 따라서 데이터베이스의 VARCHAR 타입 대신에 CLOB 타입으로 저장해야 한다. @Lob을 사용하면 CLOB, BLOB 타입을 매핑할 수 있다.
데이터베이스 스키마 자동 생성
JPA는 데이터베이스 스키마를 자동으로 생성하는 기능을 지원한다. 클래스의 매 핑정보를 보면 어떤 테이블에 어떤 컬럼을 사용하는지 알 수 있다. JPA는 이 매핑 정보와 데이터베이스 방언을 사용해서 데이터베이스 스키마를 생성한다.
스키마 자동 생성 기능을 사용해보자. 먼저 persistence.xml에 다음 속성을 추 가하자.
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- ddl이란 Data Definition Language 의 줄임말이다.-->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL8Dialect" />
<!-- mysql 방언 설정에도 버전 정보를 추가해줘야한다. 그렇지 않으면 MySQL 5이하 버전의 SQL문으로 DDL을 실행한다. -->이 속성을 추가하면 애플리케이션 실행 시점에 데이터베이스 테이블을 자동으로 생성한다. 참고로 hibernate.show_sql 속성을 true로 설정하면 콘솔에 실행되 는 테이블 생성 DDL을 출력할 수 있다.
출력되는 SQL문을 보면, 기존 MEMBER 테이블을 없애고 새로운 MEMBER 테이블을 생성하는 것을 볼 수 있다.
Hibernate:
drop table if exists MEMBER
Hibernate:
create table MEMBER (
ID varchar(255) not null,
age integer,
createdDate datetime(6),
description longtext,
lastModifiedDate datetime(6),
roleType varchar(255),
NAME varchar(255),
primary key (ID)
) engine=InnoDB기존 정보는 다 날아가나...?
하지만 스키마 자동 생성 기능이 만든 DDL은 운영 환경에서 사용할 만큼 완벽하지는 않으므로 개발 환경에서 사용하거나 매핑을 어떻게 해야 하는지 참고하는 정도로만 사용하는 것이 좋다.
hibernate.hbm2ddl.auto 속성
- create
기존 테이블을 삭제하고 새로 생성한다. - create-drop
create 속성에 추가로 애플리케이션을 종료할 때 생성한 DDL을 제거한다. - update
데이터베이스 테이블과 엔티티 매핑정보를 비교해서 변경 사항만 수정한다. - validate
데이터베이스 테이블과 엔티티 매핑정보를 비교해서 차이가 있으면 경고를 남기고 애플리케이션을 실행하지 않는다. 이 설정은 DDL을 수정하지 않는다. - none
자동 생성 기능을 사용하지 않으려면 hibernate.hbm2ddl.auto 속성 자체를 삭제 하거나 유효하지 않은 옵션 값을 주면 된다(참고로 none은 유효하지 않은 옵션 값이 다).
HBM2DDL 주의사항
운영 서버에서 create, create-drop, update처럼 DLL을 수정하는 옵션은 절대 사용하면 안 된다. 오직 개발 서버나 개발 단계에서만 사용해야 한다. 이 옵션들은 운영 중인 데이터베이스의 테이블 이나 컬럼을삭제할수있다.
개발환경에따른추천전략은다음과같다.
- 개발 초기 단계는 create 또는 update
- 초기화 상태로 자동화된 테스트를 진행하는 개발자 환경과 CI 서버는 create 또는 create-drop
- 테스트 서버는 update 또는 validate
- 스테이징과 운영 서버는 validate 또는 none
hibernate.ejb.naming_strategy
DB는 관행적으로 칼럼명에 role_type과 같이 언더바를 이용하고, Java는 관행적으로 roleType 처럼 카멜 표기법을 이용한다.
칼럼명과 변수명 사이의 불일치를 @Column(name="role_type") 로 해결할 수 있지만, persistence.xml 에 hibernate.ejb.naming_strategy 설정을 이용하여 이름 매핑을 자동화 할 수 있다. 그 속성값으로 표준화된 방법을 제공하는데 아래의 xml 설정과 같다.
<property name="hibernate.ejb.naming_strategy"
value="org.hibernate.cfg.ImprovedNamingStrategy"/>이렇게 하고 다시 코드를 돌려보면 필드명은 카멜스타일이지만, 생성되는 칼럼명은 언더바 스타일이 됨을 알 수 있다.
DDL 생성 추가 기능
이하의 기능들은 단지 DDL을 자동 생성할 때만 사용되고 JPA의 실행 로직에는 영향을 주지 않는다. 따라서 스키마 자동 생성 기능을 사용하지 않고 직접 DDL을 만든다면 사용할 이유가 없다.
DDL 칼럼 조건 추가
JPA를 이용해서 DDL을 생성시 제약조건을 추가하는 방법을 알아보자.
@Entity @Table(name="MEMBER")
public class Member {
@Id
@Column(name = "ID")
private String id;
@Column(name = "NAME", nullable = false, length = 10) //추가
private String username;
...
}다시 한번 코드를 돌려보면 create SQL문에서 NAME 칼럼을 생성하는 부분이 다음과 같이 바뀐것을 확인할 수 있다.
NAME varchar(10) not null
DDL 유니크 제약 조건
유니크 제약조건을 만들어보자.
@Entity
@Table(name="MEMBER", uniqueConstraints = {@UniqueConstraint( //추가 name = "NAME_AGE_UNIQUE",
columnNames = {"NAME", "AGE"} )})
public class Member {
@Id
@Column(name = "ID")
private String id;
@Column(name = "NAME", nullable = false, length = 10)
private String username;
...
}SQL 문에 다음이 추가된다.
alter table MEMBER
add constraint UKa0fi0krwhs381s253r50pybpe unique (NAME, age)기본키(Primary Key) 매핑
지금까지는 기본키를 @Id 에노테이션으로 매핑해서 사용했다. 그런데 기본 키를 애플리케이션에서 직접 할당하는 대신에 데이 터베이스가 생성해주는 값을 사용하려면 어떻게 매핑해야 할까? 예를 들어 오라클의 시퀀스 오브젝트라던가 아니면 MySQL의 AUTO_INCREMENT 같은 기능을 사 용해서 생성된 값을 기본 키로 사용하려면 어떻게 해야 할까?
JPA가 제공하는 데이터베이스 기본 키 생성 전략은 다음과 같다.
■ 직접 할당: 기본 키를 애플리케이션에서 직접 할당한다.
■ 자동 생성: 대리키사용방식
- IDENTITY: 기본 키 생성을 데이터베이스에 위임한다.
- SEQUENCE: 데이터베이스 시퀀스를 사용해서 기본 키를 할당한다.
- TABLE: 키 생성 테이블을 사용한다.
자동생성 전략이 이렇게 다양한 이유는 DB 벤더마다 제공하는 방법이 다르기 때문이다.
오라클 데이터베이스는 시퀀스를 제공하지만 MySQL은 시퀀스를 제공하지 않는다.
대신에 MySQL은 기본 키 값을 자동으로 채워주는 AUTO_INCREMENT 기능을 제공한다. 따라서 SEQUENCE, IDENTITY 전략은 사용하는 데이터베이스에 의존한다. TABLE 전략은 키 생성용 테이블을 하나 만들어두고 마치 시퀀스처럼 사용하는 방법이다. 이 전략은 테이블을 활용하므로 모든 데이터베이스에서 사용할 수 있다.
기본 키를 직접 할당하려면 @Id만 사용하면 되고, 자동 생성 전략을 사용하려면 @Id에 @GeneratedValue를 추가하고 원하는 키 생성 전략을 선택하면 된다.
자동 생성 전략을 이용하려면 persistence.xml 에 hibernate.id.new_generator_mappings=true 속성을 반드시 추가해야 한다
<property name="hibernate.id.new_generator_mappings" value="true" />직접 할당
직접 기본키를 할당하려면 엔티티 객체에서 기본키로 사용할 필드에 @Id 에노테이션을 붙여주면 된다.
이때 @Id 에노테이션을 사용할 수 있는 필드의 타입은 다음과 같다.
- Java 기본형 변수
- 자바 래퍼(Wrapper)형 변수
- String
- java.util.Date
- java.sql.Date
- java.math.BigDecimal
- java.math.BigInteger
엔티티 설정이 끝났다면, em.persist 하기 전에 엔티티 객체에 setId() 메서드를 호출하여 직접 설정해야 한다.
자동 생성
(1) IDENTITY 전략
IDENTITY는 기본 키 생성을 데이터베이스에 위임하는 전략이다.
주로 MySQL, PostgreSQL, SQL Server, DB2에서 사용한다.
mysql 에 다음과 같은 테이블을 만들고 INSERT 문을 두개 시행해보자.
그러면 ID 칼럼에 1, 2 값이 들어가 있는것을 알 수 있다.
CREATE TABLE BOARD (
ID INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
DATA VARCHAR(255)
);
INSERT INTO BOARD(DATA) VALUES('A');
INSERT INTO BOARD(DATA) VALUES('B');java 엔티티는 다음과 같이 만들면 된다.
@Entity
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "NAME", nullable = false, length = 32)
private String data;
//getter setter
}그리고 직접 시행을 해보자
public class BoardMain {
static EntityManagerFactory emf =
Persistence.createEntityManagerFactory("jpabook");
public static void main(String[] args) {
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
try {
tx.begin();
Board board = new Board();
board.setData("C");
em.persist(board);
System.out.println("ID = " + board.getId());
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}
}auto ddl 이 설정되어 있다면 AUTO_INCREMENT 가 설정된 테이블이 새로 만들어진다.
persist된 순간에 이미 id 값이 생성된다는 것을 알 수 있다. 기본 키값을 자동으로 생성하는 전략을 할 경우 persist 시점에 JPA가 DB에서 id 값을 조회하여 엔티티에 입력한다.
그런데 이 방식은 기존에 알던 지연 쓰기 SQL 저장소에 INSERT문을 저장하고 있다가 트랜잭션이 커밋되는 순간에 DB로 SQL문을 보내는 것과는 다른 방식이다. 즉 이 전략은 트랜잭션을 지원하는 쓰기 지연이 동작하지 않는다. 쓰기 지연 SQL을 사용하는 이점이 사라지는게 아닐까?
IDENTITY 전략과 최적화
JDBC3에 추가된 Statement.getGeneratedKeys()를 사용하면 데이터를 저장하면서 동시에 생성된 기본 키 값도 얻어 올 수 있다. 하이버네이트는 이 메소드를 사용해서 데이터베이스와 한 번만 통신한다.
(2) SEQUENCE 전략
데이터베이스 시퀀스는 유일한 값을 순서대로 생성하는 특별한 데이터베이스 오 브젝트다. SEQUENCE 전략은 이 시퀀스를 사용해서 기본 키를 생성한다. 이 전 략은 시퀀스를 지원하는 오라클, PostgreSQL, DB2, H2 데이터베이스에서 사용할 수 있다.
CREATE TABLE BOARD (
ID BIGINT NOT NULL PRIMARY KEY,
DATA VARCHAR(255)
)
CREATE SEQUENCE BOARD_SEQ START WITH 1 INCREMENT BY 1;엔티티 매핑시에는 @SequenceGenerator 에노테이션을 추가하여 Generator의 이름과 참조할 시퀀스 테이블 등을 설정해주고, 식별자 필드에서 해당 Generator 를 명시해줍니다.
@Entity
@SequenceGenerator(
name = "BOARD_SEQ_GENERATOR",
sequenceName = "BOARD_SEQ", //매핑할 데이터베이스 시퀀스 이름
initialValue = 1, allocationSize = 1)
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,
generator = "BOARD_SEQ_GENERATOR")
private Long id;
@Column(name = "NAME", nullable = false, length = 32)
private String data;
//getter setter IDENTITY 전력과 동일한 main문으로 동작한다고 할때, 코드는 동일하지만 내부 동작 방식은 다릅니다.
- em.persist() --> 먼저 데이터베이스 시퀀스를 사용해서 식별자를 조회
- 조회한 식별자를 엔티티에 할당한 후에 엔티티를 영속성 컨텍스트에 저장
- 이후 트랜잭션을 커밋해서 플러시가 일어나면 엔티티를 데이터베이스에 저장
IDENTITY 전략의 경우에는 엔티티를 데이터베이스에 저장한 후에 식별자를 조회해서 엔티티의 식별자에 할당합니다. 두 방식 모두 DB에 2번 접근하는 것은 동일한데, IDENTITY이 INSERT문을 시행하고 식별자를 조회해서 가져온다는 점에서 차이를 가집니다.
@SequenceGenerator
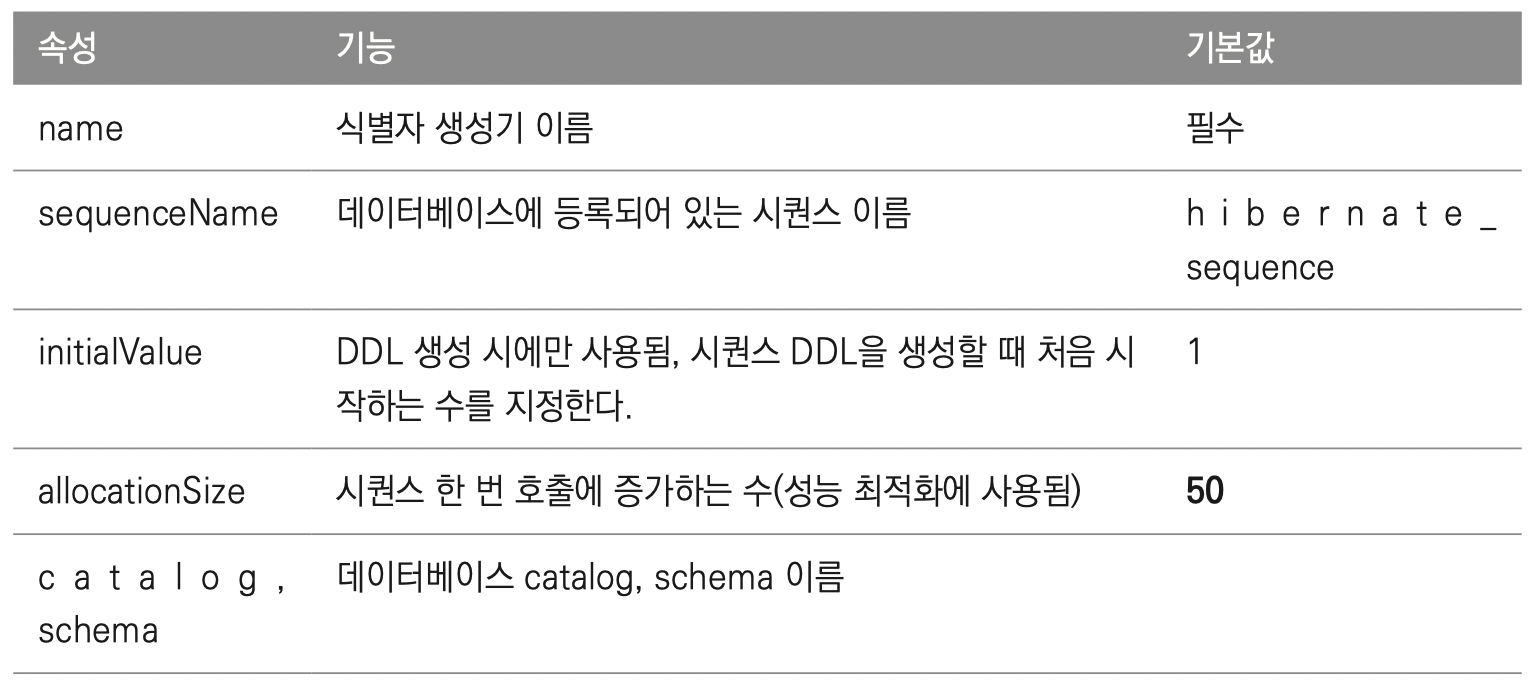
@SequenceGenerator 에노테이션은 클래스외에 식별자 필드에 사용해도 된다.
SEQUENCE 전략과 최적화
SEQUENCE 전략은 데이터베이스 시퀀스를 통해 식별자를 조회하는 추가 작업이 필요하다. 따라 서 데이터베이스와 2번 통신한다.
- 식별자를 구하려고 데이터베이스 시퀀스를 조회한다.
-SELECT BOARD_SEQ.NEXTVAL FROM DUAL - 조회한 시퀀스를 기본 키 값으로 사용해 데이터베이스에 저장한다.
-INSERT INTO BOARD
JPA는 시퀀스에 접근하는 횟수를 줄이기 위해 @SequenceGenerator.allocationSize를 사용한다.
간단히 설명하자면 여기에 설정한 값만큼 한 번에 시퀀스 값을 증가시키고 나서 그만큼 메모리에 시퀀스 값을 할당한다. 예를 들어 allocationSize 값이 50이면 DB에 시퀀스 값을 한번에 50씩 증가시키되, JVM 메모리에는 한번에 50개씩 시퀀스 값을 가져와서 1~50, 51~100 처럼 50씩 자른 시퀀스 값중에서 식별자 값을 할당한다.
이 최적화 방법은 시퀀스 값을 선점하므로 여러 JVM이 동시에 동작해도 기본 키 값이 충돌하지 않는 장점이 있다. 반면에 데이터베이스에 직접 접근해서 데이터를 등록할 때 시퀀스 값이 한 번에 많이 증가한다는 점을 염두해두어야 한다. 이런 상황이 부담스럽고 INSERT 성능이 중요하지 않으 면 allocationSize의 값을 1로 설정하면 된다.
(3) TABLE 전략
TABLE 전략은 키 생성 전용 테이블을 하나 만들고 여기에 이름과 값으로 사용할 컬럼을 만들어 데이터베이스 시퀀스를 흉내내는 전략이다. 이 전략은 테이블을 사 용하므로 모든 데이터베이스에 적용할 수 있다.
시퀀스 테이블을 만든다.
create table MY_SEQUENCES (
sequence_name varchar(255) not null ,
next_val bigint,
primary key ( sequence_name )
)sequence_name 컬럼을 시퀀스 이름으로 사용하고 next_val 컬럼을 시퀀스 값 으로 사용한다.
엔티티 맵핑은 다음과 같다.
@Entity
@TableGenerator(
name = "BOARD_SEQ_GENERATOR",
table = "MY_SEQUENCES",
pkColumnValue = "BOARD_SEQ",
allocationSize = 1)
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.TABLE,
generator = "BOARD_SEQ_GENERATOR")
@Column(name = "ID")
private Long id;
@Column(name = "NAME", nullable = false, length = 32)
private String data;
// getter setter
}TABLE 전략은 시퀀스 대 신에 테이블을 사용한다는 것만 제외하면 SEQUENCE 전략과 내부 동작방식이 같다.
지금까지 언급된 자동 전략들은 모두 자동 ddl이 설정되어 있었다면 따로 DB에 설정을 추가할 필요가 없었다.
<property name="hibernate.hbm2ddl.auto" value="create" />@TableGenerator
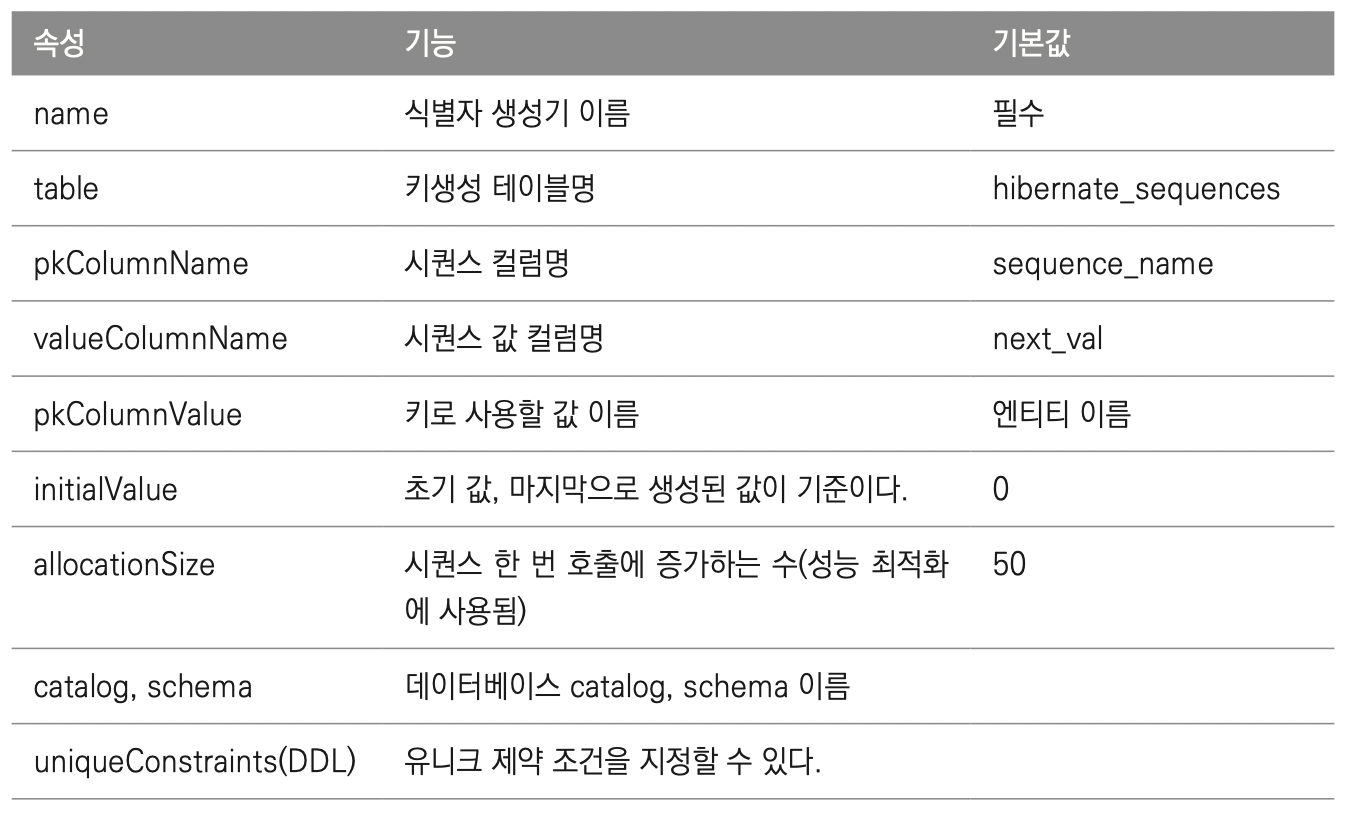
TABLE 전략과 최적화
TABLE 전략은 값을 조회하면서 SELECT 쿼리를 사용하고 다음 값으로 증가시키기 위해 UPDATE 쿼리를 사용한다. 이 전략은 SEQUENCE 전략과 비교해서 데이터베이스와 한 번 더 통신하는 단점이 있다. TABLE 전략을 최적화하려면 @TableGenerator.allocationSize를 사용하면 된다. 이 값을 사용해서 최적화하는 방법은 SEQUENCE 전략과 같다.
(4) Auto 전략
데이터베이스의 종류도 많고 기본 키를 만드는 방법도 다양하다. GenerationType.AUTO 는 선택한 데이터베이스 방언에 따라 IDENTITY, SEQUENCE, TABLE 전략 중 하나를 자동으로 선택한다.
@GeneratedValue(strategy = GenerationType.AUTO) 를 설정하면 된다.
@Entity
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name = "ID")
private Long id;
@Column(name = "NAME", nullable = false, length = 32)
private String data;
// getter setterAUTO 전략의 장점은 데이터베이스를 변경해도 코드를 수정할 필요가 없다는 것이다. 특히 키 생성 전략이 아직 확정되지 않은 개발 초기 단계나 프로토타입 개발 시 편리하게 사용할 수 있다.
AUTO를 사용할 때 SEQUENCE나 TABLE 전략이 선택되면 시퀀스나 키 생성 용 테이블을 미리 만들어 두어야 한다. 만약 스키마 자동 생성 기능을 사용한다면 하이버네이트가 기본값을 사용해서 적절한 시퀀스나 키 생성용 테이블을 만들어 줄 것이다.
식별자에 대하여
식별자의 조건
데이터베이스 기본 키는 다음 3가지 조건을 모두 만족해야 한다.
- null값은 허용하지 않는다.
- 유일해야 한다.
- 변해선안된다.
식별자 전택 전략
테이블의 기본 키를 선택하는 전략은 크게 2가지가 있다.
-
자연 키(natural key)
- 비즈니스에의미가있는키
- 예: 주민등록번호, 이메일, 전화번호 -
대리 키(surrogate key)
- 비즈니스와 관련 없는 임의로 만들어진 키, 대체 키로도 불린다.
- 예: 오라클 시퀀스, auto_increment, 키생성 테이블 사용
자연 키보다는 대리 키를 권장한다
자연 키는 비즈니스 환경의 변화로 누락될 수도 있으며 변경될 수도 있다. 자연 키를 이용하는 것보다는 대리 키를 이용하는 것이 보다 더 안전한 방법이다.
JPA 엔티티의 기본키는 변하면 안된다.
기본 키는 변하면 안 된다는 기본 원칙으로 인해, 저장된 엔티티의 기본 키 값은 절대 변경하면 안 된다. 이 경우 JPA는 예외를 발생시키거나 정상 동작하지 않는다.
필드와 칼럼 매핑
필드와 칼럼을 매핑하는 방법은 다양하므로 책 한권에서 모두 다루기는 어렵다.
기본적인 매핑 방법을 레퍼런스 형식으로 정리하였고, 이외에 필요한 내용은 직접 찾아봐야 한다.

정확히 모르는 개념
catalog 와 schema
XML을 이용한 엔티티 매핑
DDL
DB 유니크 제약조건
