DML 문
INSERT
- ORACLE은 VARCHAR에 ''을 입력하면 NULL로 입력된다.
- SQL Server는 VARCHAR에 ''을 입력하면 ''로 입력된다.
DELETE
- FROM 키워드는 생략 가능하다. ex) DELETE FROM 주문; = DELETE 주문
SELECT
- 두 개 이상의 테이블을 참조하는 FROM절에 테이블에 대한 ALIAS를 사용했을 때, 테이블들이 중복된 칼럼을 가지고 있을 경우 반드시 ALIAS명을 사용해야 함.
로깅을 하고 싶지 않다면 NOLOGGING 옵션을 사용한다.
ALTER TABLE EMP NOLOGGING;ALIAS
- SELECT 절에만 사용 가능
- WHERE, FROM, GROUP BY 절 등에서는 사용 불가
- AS 는 생략 하고 띄어쓰기로 대체 가능
ESCAPE
와일드카드(_ , %)를 문자로 취급하는 함수
- LIKE 연산자에서 '%' 와 '' 는 특수한 용도로 사용되는 문자인데, 만약 LIKE을 통해 검색하고자 하는 단어에 '%' 와 '' 를 포함할 경우에는 'ESCAPE' 를 사용하면 된다.
- 원하는 특수문자를 앞에 작성하고 '%' 와 '_' 를 사용하면 된다.
- 아래 예시는 '#' 이라는 특수한 문자를 지정하여 '_' 를 포함하는 NAME 을 검색한다.
SELECT * FROM EMP WHERE NAME LIKE '%#_%' ESCAPE '#';
ROWNUM / TOP
ROWNUM (Oracle)
- WHERE절에서 ROWNUM = 1 인 경우를 무조건 포함해야 함 (?)
- ROWNUM 은 WHERE 절에 사용하기 때문에 ORDER BY 로 데이터가 정렬되기 전 조건으로 데이터를 뽑은 후 ORDER BY로 정렬해서 출력
# 행 9개 조회
SELECT * FROM table1 WHERE rownum < 10;TOP (SQL Server)
- SELECT 절에서 사용 → TOP(n)<컬럼명> 은 해당 컬럼명의 상위 n개의 행을 가져오는 함수
SELECT TOP 10 col1, col2, col3 FROM table1;IN, NOT IN
- IN 절에 NULL이 있을 경우, 무시함
- NOT IN 절에 NULL이 있을 경우, 항상 true로 리턴하게 되어 NOT IN 결과가 항상 0건임.
CASE 조건문
# Searched CASE (조건 컬럼이 여러 개일 때)
SELECT
CASE
WHEN 조건A = 'a' THEN 1
WHEN 조건B = 'b' THEN 2
ELSE 3 # 조건에 만족하지 않으면 나타낼 값
END AS 원하는 컬럼명 # 마지막에 컬럼명 없으면 'END' 로 닫아주기
FROM TABLE;
# Simple CASE (조건 컬럼이 하나일 때)
SELECT
CASE 조건A
WHEN 'a' THEN 1
WHEN 'b' THEN 2
ELSE 3
END AS 원하는 컬럼명
FROM TABLE;- ELSE 부분은 생략이 가능하며 생략할 경우 조건에 맞지 않으면 NULL을 반환한다.
DECODE (oracle)
DECODE(값, IF1, THEN1, IF2, THEN2, .... )
SELECT
employee_id,
DECODE(department_id,
10, 'Sales',
20, 'Marketing',
30, 'IT',
'Other') AS department_name
FROM employees;NULL 관련 함수
NULL 의 정의
- 공백이나 0 과는 다르다.
- 산술 연산에 NULL 이 들어가면 NULL 로 출력된다. (+, - 등)
- WHERE 절에 NULL 사용시 → IS NULL 또는 IS NOT NULL 로 사용한다.
- 집계 함수에서 NULL 은 제외된다. (SUM, COUNT 등)
- SQL server 에서는 NULL 을 가장 작은 값으로 간주하고, 오라클에서는 가장 큰 값으로 간주한다.
- NULL 포함시 ASC 오름차순으로 정렬하면 오라클에서는 NULL 이 가장 마지막에 위치하고, SQL server 에서는 가장 먼저 위치한다.
NVL (oracle) / ISNULL (SQL server)
- EXPR1 이 NULL 이면 0 을 반환하고, 그렇지 않으면 EXPR1 를 반환한다.
- 데이터 타입이 일치해야 한다.
NVL(EXPR1, 0)
ISNULL(EXPR1, 0)
# 문자열을 반환하고 싶으면 컬럼도 문자열이어야 한다.
NVL(TO_CHAR(EXPR1), 'zero')
# commission_pct 열이 NULL이면 0을 반환, 그렇지 않으면 commission_pct 반환
ISNULL(commission_pct, 0)NULLIF
- EXPR1 과 EXPR2 가 같으면 NULL을 반환하고, 그렇지 않으면 EXPR1 을 반환한다.
NULLIF(EXPR1, EXPR2);
# department가 'Sales'이면 NULL을 반환하고, 그렇지 않으면 department의 값을 반환
NULLIF(department, 'Sales')COALESCE
- 여러 개의 표현식 중에서 NULL이 아닌 첫 번째 값을 반환한다.
- 모든 표현식이 NULL 이면 NULL 을 반환한다.
# discounted_price가 NULL이면 regular_price를 반환하고, 그렇지 않으면 discounted_price를 반환
COALESCE(discounted_price, regular_price)
# email이 NULL이면 phone을 반환하고, 그렇지 않으면 'Contact information not available' 메시지를 반환
COALESCE(email, phone, 'Contact information not available')DISTINCT
- 아래와 같이 DISTINCT 뒤에 컬럼이 2개 이상 나오면 col1, col2 의 값이 모두 같지 않은 것만 조회한다.
SELECT DISTINCT col1, col2 FROM table
ORDER BY
- ORDER BY 절의 숫자는 SELECT 절의 컬럼 순서를 의미한다.
- ORDER BY 는 SELECT 절보다 나중에 실행되기 때문에 SELECT 절의 ALIAS 사용이 가능하다.
- COUNT(*)은 가능하다.
- SQL server 에서는 SELECT 절에 기술되지 않는 컬럼은 ORDER BY 에서 사용할 수 없지만, 오라클에서는 SELECT 절에 기술되지 않는 컬럼도 ORDER BY 에서 사용할 수 있다.
- 오라클은 행기반 DATABASE 이므로 데이터를 액세스할 때 행 전체 칼럼을 메모리에 로드하기 때문이다.
- NULL 포함시 오름차순으로 정렬하면 오라클에서는 NULL 이 가장 마지막에 위치하고, SQL server 에서는 가장 먼저 위치한다.
- 정렬시 같은 값이 있는 경우, 다른 컬럼으로 추가 정렬할 수 있다. (2차 정렬)
# salary 컬럼으로 내림차순 정렬 후 동일값이 있으면 hire_date 으로 오름차순 정렬한다. ORDER BY salary DESC, hire_date ASC
GROUP BY - HAVING
- GROUP BY 절에 온 컬럼만 SELECT 절에 올 수 있음
- 또는 집계 함수만 SELECT 절에 올 수 있음 (MAX, MIN, SUM 등)
- GROUP BY, HAVING 절은 SELECT 보다 먼저 실행되기 때문에 SELECT 문에서 사용된 ALIAS 는 사용 불가
- GROUP BY 없이 HAVING 절을 사용해도 오류는 발생하지 않는다.
집계 함수 (그룹 함수)
- WHERE 절에서는 사용 불가하고, GROUP BY - HAVING 절에서 사용 가능
- GROUP BY 절에 의해 그룹별 연산 결과를 반환한다.
- NULL 은 무시하고 연산한다.
- 반드시 한 컬럼만 전달한다.
| 함수 | 반환 값 |
|---|---|
| COUNT(*) | NULL 값을 포함한 행의 수 |
| COUNT(표현식) | NULL 값을 제외한 행의 수 |
| SUM([DISTINCT | ALL] 표현식) | NULL 값을 제외한 합계 |
| AVG([DISTINCT | ALL] 표현식) | NULL 값을 제외한 평균 |
| MAX([DISTINCT | ALL] 표현식) | 최대값 (문자, 날짜 데이터 타입도 사용 가능) |
| MIN([DISTINCT | ALL] 표현식) | 최소값 (문자, 날짜 데이터 타입도 사용 가능) |
| STDDEV([DISTINCT | ALL] 표현식) | 표준 편차 |
| VARIAN([DISTINCT | ALL] 표현식) | 분산 |
COUNT
- 전체 행을 세고 싶으면, * 또는 NOT NULL 컬럼인 PK 로 하면 된다.
- 테이블 2개에 대한 COUNT 연산
SELECT COUNT(*) FROM A, B -- A데이터 개수 * B데이터 개수
AVG
- NULL 을 포함한 평균을 리턴하고 싶으면 아래와 같이 한다.
# comm 컬럼에 값이 null 이면 0 으로 치환하여 평균 계산 SELECT AVG(NVL(comm, 0)) AS avg2 FROM emp;
MIN / MAX
- 날짜, 숫자, 문자를 오름차순으로 출력
산술 함수
- 파라미터 사용법은 모두 같다.
- n 을 d 번째 자리까지 반올림, 올림 또는 버림
- d가 양수이면 소수점 이하 자릿수, 음수이면 소수점 이상의 자릿수를 반올림, 올림, 버림한다.
| 함수 | 반환 값 |
|---|---|
| ROUND(n, d) | 반올림 (5 이상이면 올림, 5 이하이면 내림) |
| CEIL(n, d) (oracle) | 올림 (소수점 상관 없이 무조건 올림 처리) 주어진 수보다 크거나 같은 가장 작은 정수를 반환 |
| CEILING(n, d) (SQL) | 올림 |
| TRUNCATE(n, d) / TRUNC | 버림 |
| FLOOR(n, d) | 버림 주어진 수보다 작거나 같은 가장 큰 정수를 반환 |
| ABS | 절대값 |
# 소수점 이하 두 번째 자리까지 반올림
ROUND(123.4567, 2) -- 123.46
# 소수점 이상의 첫 번째 자리까지 반올림
ROUND(123.4567, -1) -- 120
# 0 의 자리에서 반올림하여 정수로 나타냄
ROUND(123.4567) -- 123
# 소수점 이하 두 번째 자리까지 버림
SELECT TRUNCATE(135.375, 2); -- 135.37
# 올림
CEIL(123.12) -- 124
SELECT CEIL(-4.2) AS result FROM dual; -- 결과: -4
SELECT CEIL(-5.0) AS result FROM dual; -- 결과: -5
# 버림
FLOOR(4.8) -- 4
SELECT FLOOR(-4.8) AS result FROM dual; -- 결과: -5
SELECT FLOOR(-5.0) AS result FROM dual; -- 결과: -5
# 절대값
ABS(-22) -- 22문자형 함수
| 함수 | 반환 |
|---|---|
| ASCII(문자) | 문자나 숫자를 ASCII 코드로 변환 |
| CHR/CHAR(ASCII번호) | ASCII 코드 번호를 문자나 숫자로 변환 |
| CONCAT(문자열1, 문자열2) | 문자열1과 문자열2를 연결 (oracle의 || 와 SQL의 + 와 동일) |
| SUBSTR/SUBSTRING(문자열, m, n) | 문자열에서 m 번째 문자부터 n 개의 문자를 출력 (n 이 생략되면 마지막 문자까지 출력, 음수 파라미터 사용 불가) |
| INSTR(문자열1, 문자열2) | 문자열1 에서 문자열2 를 찾아서 첫번째 자리수 반환 (없으면 0 반환) |
| LENGTH/LEN(문자열) | 문자열의 개수 |
| TRIM([LEADING|TRAILING|BOTH] 지정문자 FROM 문자열) | 문자열에서 머리말(leading), 꼬리말(trailing), 양쪽(both)에 있는 지정문자를 제거 SQL server 에서는 지정문자 사용 불가능 (공백만 제거 가능) |
| LTRIM(문자열, 지정문자) | 문자열의 왼쪽부터 확인해서 지정문자가 나타나면 해당 문자를 제거 (지정문자 생략시 공백) SQL server 에서는 지정문자 사용 불가능 (공백만 제거 가능) 다른 문자 사이 또는 오른쪽에 있는 문자는 제거하지 않는다. |
| RTRIM(문자열, 지정문자) | 문자열의 오른쪽부터 확인해서 지정문자가 나타나면 해당 문자를 제거 SQL server 에서는 지정문자 사용 불가능 (공백만 제거 가능) |
| LPAD(문자, 총자릿수, 채울문자) | 특정자리수를 정하고 왼쪽부터 채워줌 |
| RPAD(문자, 총자릿수, 채울문자) | 특정자리수를 정하고 오른쪽부터 채워줌 |
# 양쪽에 있는 'x' 문자를 제거하여 'Hello World'를 반환
TRIM('x' FROM 'xxxHello Worldxxx')
TRIM(BOTH 'x' FROM 'xxxHello Worldxxx')
# 앞쪽에 있는 'x' 문자를 제거하여 'Hello Worldxxx'를 반환
TRIM(LEADING 'x' FROM 'xxxHello Worldxxx')
# 뒤쪽에 있는 'x' 문자를 제거하여 'xxxHello World'를 반환
TRIM(TRAILING 'x' FROM 'xxxHello Worldxxx')
# 'Hello World' (양쪽 공백 제거)
LTRIM(RTRIM(' Hello World '))
TRIM(' Hello World ')
# 채우기
SELECT LPAD('A', 5, '*') FROM table1; -- ****A
SELECT LPAD('AB', 5, '*') FROM table1; -- ***AB
SELECT RPAD('A', 5, '*') FROM table1; -- A****날짜 함수
- SQL Server:
CONVERT,CAST, 그리고 날짜 형식 변환에는FORMAT사용 - MySQL:
DATE_FORMAT과STR_TO_DATE사용
TO_DATE (oracle)
- 문자형 데이터를 날짜형으로 출력
- 날짜를 계산해야될 때 사용
- 'YYYY-MM-DD HH24:MI:SS'
- 년도(YYYY)의 포맷을 RR로 사용할 경우 50~99년은 1900년대로, 00~49년은 2000년대로 변환된다.
- 문자 타입 형식
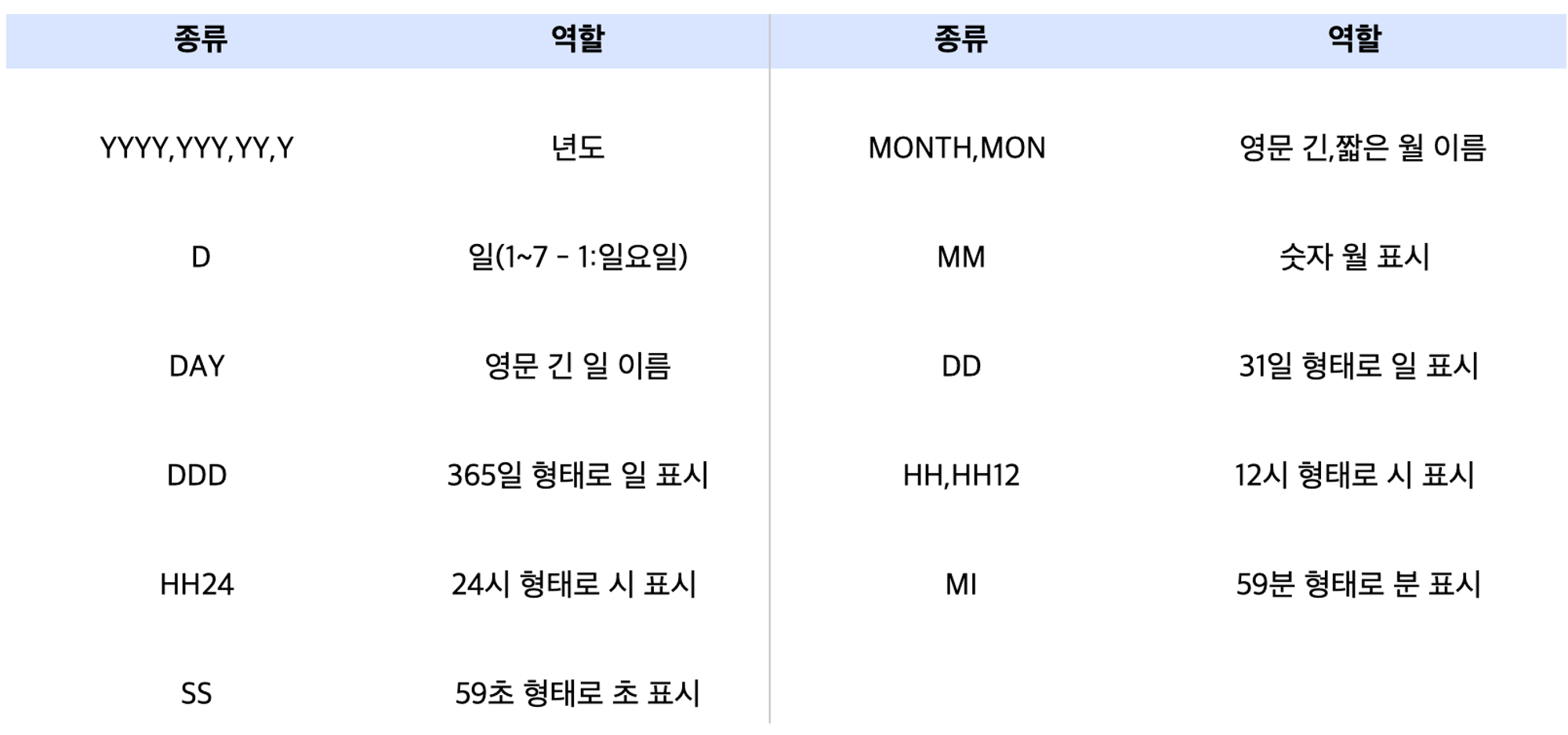
- 현재 날짜 출력 함수 : SYSDATE (oracle) / GETDATE() (SQL server)
TO_CHAR (oracle)
- 날짜형 데이터를 문자로 출력
DATE 타입 연산
- 오라클에서 DATE 타입에 숫자를 더하거나 빼는 연산을 할 때, Oracle은 그 숫자를 일(day) 단위로 간주한다.
- ‘일 / 시간 / 분’
1/24 -- 1시간 (하루가 24시간이라서 24로 나누면 1시간)
1/24/60 -- 1분 (1시간은 60분이라서 60으로 나누면 1분)
1/24/30 -- 2분
1/24/12 -- 5분
1/24/(60/10) -- 10분
1/24/60/6 -- 10초
1/24/60/60 -- 1초
2/24 -- 2시간
10/24/60 -- 10분
# 1분은 하루를 24시간으로 나눈 1/24를 다시 60으로 나눈 1/24/60 = 1/1440
1/1440 = 1/24/60 -- 1분
# 1초는 하루를 24시간으로 나눈 1/24를 다시 60으로 나눈 1/24/60 을 다시 60으로 나눈 1/24/60/60 = 1/86400
1/86400 = 1/24/60/60 -- 1초
# 1/12
1/12/(60/30) = 1/12/2 = 1/24 -- 1시간 EXISTS / NOT EXISTS
- IN 연산자와 비슷 → IN 연산자는 비교할 값을 직접 대입할 수 있지만 EXISTS 연산자는 서브 쿼리만 사용할 수 있다.
- EXISTS 에 사용된 쿼리가 연관 서브쿼리인 경우 IN 으로 변경할 수 없다.
- 조건을 만족하는 건이 여러건이라도 1건만 찾으면 더이상 검색하지 않는다.
- 서브 쿼리의 SELECT 절에는 1 외에도 아무 표현식이나 들어갈 수 있다.
# employees 테이블에서 departments 테이블에 매칭되는 department_id가 있는 직원의 이름을 반환 SELECT employee_name FROM employees e WHERE EXISTS ( SELECT 1 FROM departments d WHERE d.department_id = e.department_id );
관계 대수 연산자
관계 대수란? (Relational Algebra)
원하는 결과를 얻기 위해 데이터의 처리 과정을 순서대로 기술하는 절차 언어
순수 관계 연산자
SELECT (σ)
- WHERE 절로 구현
- σ조건식(릴레이션)
PROJECT (π)
- SELECT 절로 구현
- π속성리스트(릴레이션)
JOIN (▷◁)
DIVIDE (DIVISION) (÷)
일반 집합 연산자 (SET OPERATOR)
UNION / UNION ALL (∪) 합집합
- UNION 은 중복된 행은 하나의 행으로 만든다. == UNION DISTINCT
- 중복 행을 제거하기 위해 정렬을 하는데, 중복 데이터가 없을 때에도 불필요한 정렬을 하기 때문에 성능 상 좋지 않다.
- UNION ALL 은 중복된 행도 그대로 표시한다.
INTERSECTION (∩) 교집합
- 중복된 행은 하나의 행으로 만든다.
DIFFERENCE (-) 차집합
- EXCEPT 기능 (오라클은 MINUS)
- 중복된 행은 하나의 행으로 만든다.
PRODUCT (x) 교차곱
= Cartesian Product (카타시안곱), CROSS JOIN 기능
- Degree(차수)는 더하고, Cardinality(기수)는 곱한다.
JOIN
여러 테이블의 데이터를 사용하여 동시 출력하거나 참조할 경우에 사용한다.
형태에 따른 분류
EQUI JOIN (등가 조인, 동등 조인)
- JOIN 조건이 동등 조건인 경우 (=)
NON EQUI JOIN
- JOIN 조건이 동등 조건이 아닌 경우 (between, <, > 등)
결과에 따른 분류
INNER JOIN (JOIN)
- JOIN 조건에 성립하는 데이터만 출력
- EQUI JOIN 이라고도 함
- USING 이나 ON 조건을 필수로 사용
- ON 조건에서 괄호는 생략이 가능하다.
- USING 은 조건이 컬럼의 형태일 때, 두 테이블간 컬럼명이 같은 경우에만 사용한다.
- 조인하는 양쪽 테이블의 연결 정보 컬럼명을 반드시 ( ) 안에 명시하고, ALIAS 사용 불가
오라클은 JOIN 시 FROM 절에 테이블을 ,로 구분하여 나열하고 JOIN 조건도 WHERE 절에 기술한다.
ANSI 표준은 JOIN 시 조건을 ON, USING 절에 기술한다. (SQL server 는 USING 지원 X)# Oracle 표준 SELECT * FROM order1, review WHERE order1.id = review.order_id; # ANSI 표준 SELECT * FROM task JOIN alarm USING(title); SELECT * FROM order1 o INNER JOIN review r ON (r.order_id = o.id);
OUTER JOIN
- JOIN 조건에 성립하지 않는 데이터도 출력
- LEFT / RIGHT / FULL OUTER JOIN
- FULL OUTER JOIN == RIGHT OUTER JOIN + LEFT OUTER JOIN == UNION (MySQL)
- 중복 제거한 합집합 도출
- 오라클에서는 (+) 로 OUTER JOIN 처리
-
RIGHT OUTER JOIN 은 (+) 를 왼쪽에 위치
-
LEFT OUTER JOIN 은 (+) 를 오른쪽에 위치
WHERE A.게시판ID = B.게시판ID(+) WHERE A.게시판ID(+) = B.게시판ID
-
NATURAL JOIN (oracle)
- 두 테이블 간의 동일한 이름과 데이터 유형을 갖는 모든 컬럼에 대해 EQUI JOIN 수행
- USING, WHERE, ON 등의 조건 정의 불가
CROSS JOIN
- JOIN 에 WHERE 나 ON 조건 생략시 두 테이블의 발생 가능한 모든 행을 출력
- 일반 집합 연산자의 PRODUCT (Cartesian product) 카타시안 곱 출력
SELF JOIN
- 한 테이블에서 두 개의 컬럼이 연관 관계를 가지고 있는 경우
- 계층형 데이터 구조에서 사용
- 하나의 테이블이기 때문에 별칭을 사용
SELECT e1.manager_id, e1.first_name, e2.employee_id FROM employees e1, employees e2 WHERE e1.manager_id = e2.employee_id;

슬기로운 개발 생활