✔️ 프로그램, 프로세스, 스레드
| - | Program | Process | Thread |
|---|---|---|---|
| 정의 | 코드 덩어리 - 컴퓨터에서 실행 할 수 있는 파일 | 실행 중인 프로그램 - 운영체제로부터 자원을 할당받은 작업의 단위 | 프로세스가 할당받은 자원을 이용하는 실행 흐름의 단위 |
| memory 공유 | - | Process 끼리 memory share X | Thread 끼리 memory share O |
| 예시 | Excel, Word | 실행 중인 Excel, Word | 작성, 저장, 자동 완성 |
⚙️ 프로그램(Program)과 프로세스(Process)
📌 정적 프로그램 (Static Program)
프로그램은 윈도우의 *.exe 파일이나 Mac의 *.dmg 파일과 같은 컴퓨터에서 실행 할 수 있는 파일을 통칭한다. 단, 아직 파일을 실행하지 않은 상태이기 때문에 정적 프로그램(Static Program) 줄여서 프로그램(Program)이라고 부른 것이다.
어떠한 프로그램을 개발하기 위해선 자바나 C언어와 같은 언어를 이용해 코드를 작성하여 완성된다. 즉, 프로그램은 쉽게 말해서 그냥 코드 덩어리인 것이다.
📌 프로세스 (Process)
프로그램이 그냥 코드 덩어리이면, 프로세스는 프로그램을 실행 시켜 정적인 프로그램이 동적으로 변하여 프로그램이 돌아가고 있는 상태를 말한다. 즉, 컴퓨터에서 작업 중인 프로그램을 의미한다.
'작업' 관리자를 열어보면 실행중인 프로그램인 프로세스를 확인할 수 있다.
모든 프로그램은 운영체제가 실행되기 위한 메모리 공간을 할당해 줘야 실행될 수 있다. 그래서 프로그램을 실행하는 순간 파일은 컴퓨터 메모리에 올라가게 되고, 운영체제로부터 시스템 자원(CPU)을 할당받아 프로그램 코드를 실행시켜 우리가 서비스를 이용할 수 있게 되는 것이다.

어플리케이션을 실행했는지 안했는지의 차이일 뿐이라서, 일반적으로 프로세스와 프로그램을 같은 개념으로 이야기할 때가 많지만, 사실 둘은 다른 개념이다.
이 둘을 간단하게 정리하자면 아래와 같다.
| 프로그램 (Program) | 프로세스 (Process) |
|---|---|
| 어떤 작업을 하기 위해 실행할 수 있는 파일 | 실행되어 작업중인 컴퓨터 프로그램 |
| 파일이 저장 장치에 있지만 메모리에는 올라가 있지 않은 정적인 상태 | 메모리에 적재되고 CPU 자원을 할당받아 프로그램이 실행되고 있는 상태 |
| 코드 덩어리 | 그 코드 덩어리를 실행한 것 |
⚙️ 스레드 (Thread)
하나의 프로세스 내에서 동시에 진행되는 작업 갈래, 흐름의 단위를 말한다.
과거에는 파일을 다운받으면 실행 시작부터 실행 끝까지 프로세스 하나만을 사용하기 때문에 다운이 완료될때까지 하루종일 기다려야 했다. 스레드(Thread)는 프로세스 특성의 한계를 해결하기 위해 나왔다.
크롬 브라우저가 실행 되면 프로세스 하나가 생성될 것이다. 그런데 우리는 브라우저에서 파일을 다운 받으며 온라인 쇼핑을 하면서 게임을 하기도 한다.
즉, 하나의 프로세스 안에서 여러가지 작업들 흐름이 동시에 진행되기 때문에 가능한 것인데, 이러한 일련의 작업 흐름들을 스레드라고 하며 여러 개가 있다면 이를 멀티(다중) 스레드 (Multi Thread) 라고 부른다.

📌 멀티 스레드 (Multi Thread)
main method(메인 메소드) > main thread(메인 스레드) > work thread(워크 스레드)일반적으로 하나의 프로그램은 하나 이상의 프로세스를 가지고 있고, 하나의 프로세스는 반드시 하나 이상의 스레드를 갖는다. 즉, 프로세스를 생성하면 기본적으로 하나의 main thread(메인 스레드) 가 생성되게 된다. 스레드 2개 이상은 개발자가 직접 프로그래밍하여 위치 시켜주어야 한다.
work thread(워크 스레드) 는 용량이 허용하는 만큼 생성이 가능하고, 이것을 멀티 스레드 (Multi Thread) 라고 한다.
- main method 는 thread 를 동작하게 해주는 method 이다.
- main method 에서 main thread 를 생성하고 main thread 는 자기를 위해 일할 수 있는 work thread를 생성한다.
- main thread 가 종료되더라도 실행 중인 thread 가 하나라도 있으면 프로세스는 종료되지 않는다.
📌 클럭(Clock) 처리
클럭 주기마다 CPU가 하나의 명령어 또는 연산을 처리한다. 클럭 처리는 CPU가 클럭 주기에 맞추어 명령어를 실행하고 데이터를 처리하는 과정이다. (클럭 처리 == CPU의 동작)
- 클럭 주기에 따라 CPU가 동작하면, CPU는 주어진 클럭 주기 동안에 수행할 수 있는 작업을 처리한다.
- 스레드는 CPU가 작업을 처리하는 단위이고, CPU가 클럭 주기에 따라 동작하는 동안 각 스레드는 할당된 CPU 시간 동안 작업을 처리하게 된다.
- 따라서 클럭 주기와 스레드는 각각 CPU 동작과 작업 처리를 담당하는 요소이다.
여러 스레드가 동시에 실행될 때는 CPU 스케줄러가 각 스레드에 CPU 시간을 할당하고 전환하여 다양한 작업을 병렬로 처리할 수 있다. 따라서 CPU는 클럭 주기에 따라 동작하고, 각 클럭 주기 동안 스레드에 할당된 작업을 처리한다.
✔️ CPU가 동작하면 뜨거워지는 이유
CPU는 전기 에너지를 사용하여 작업을 수행하고, 이 과정에서 일부 전기 에너지는 열로 변환된다. 이 뜨거운 열은 CPU 주변의 열 이송 장치(히트싱크, 팬 등)를 통해 제거되어야 한다. 그렇지 않으면 CPU가 과열되어 오작동하거나 손상될 수 있다. 따라서 컴퓨터 시스템에는 CPU의 온도를 모니터링하고 냉각하기 위한 여러 가지 장치와 기술이 포함되어 있다.
⚙️ 프로세스와 스레드의 메모리
📌 프로세스 자원 구조
프로그램이 실행되어 프로세스가 만들어지면 다음 4가지의 메모리 영역으로 구성되어 할당 받게 된다.
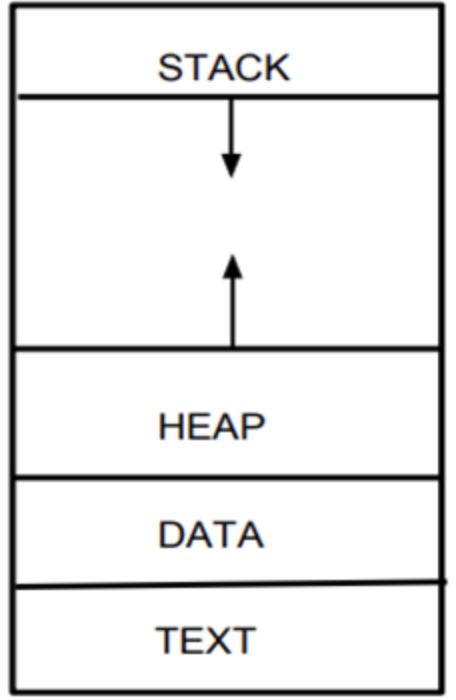
코드 영역과 데이터 영역은 선언할 때 크기가 결정되는 정적 영역이지만, 스택 영역과 힙 영역은 프로세스가 실행되는 동안 크기가 늘어났다 줄어들기도 하는 동적 영역이기 때문에 위아래로 화살표 표시가 되어있다.
- 코드 영역(Code / Text) : 프로그래머가 작성한 프로그램 함수들의 코드가 CPU가 해석 가능한 기계어 형태로 저장되어 있다.
- 데이터 영역(Data) : 코드가 실행되면서 사용하는 전역 변수나 각종 데이터들이 모여있다. 데이터영역은 .data ,.rodata, .bss 영역으로 세분화 된다.
-.data: 전역 변수 또는 static 변수 등 프로그램이 사용하는 데이터를 저장
-.BSS: 초기값 없는 전역 변수, static 변수가 저장
-.rodata: const같은 상수 키워드 선언 된 변수나 문자열 상수가 저장 - 스택 영역(Stack) : 지역 변수와 같은 호출한 함수가 종료되면 되돌아올 임시적인 자료를 저장하는 독립적인 공간이다. Stack은 함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸한다. 만일 stack 영역을 초과하면 stack overflow 에러가 발생한다.
(함수 호출 시 전달되는 인자, 되돌아갈 주소값, 함수 내에서 선언하는 변수 등을 저장) - 힙 영역(Heap) : 생성자, 인스턴스와 같은 동적으로 할당되는 데이터들을 위해 존재하는 공간이다. 사용자에 의해 메모리 공간이 동적으로 할당되고 해제된다.
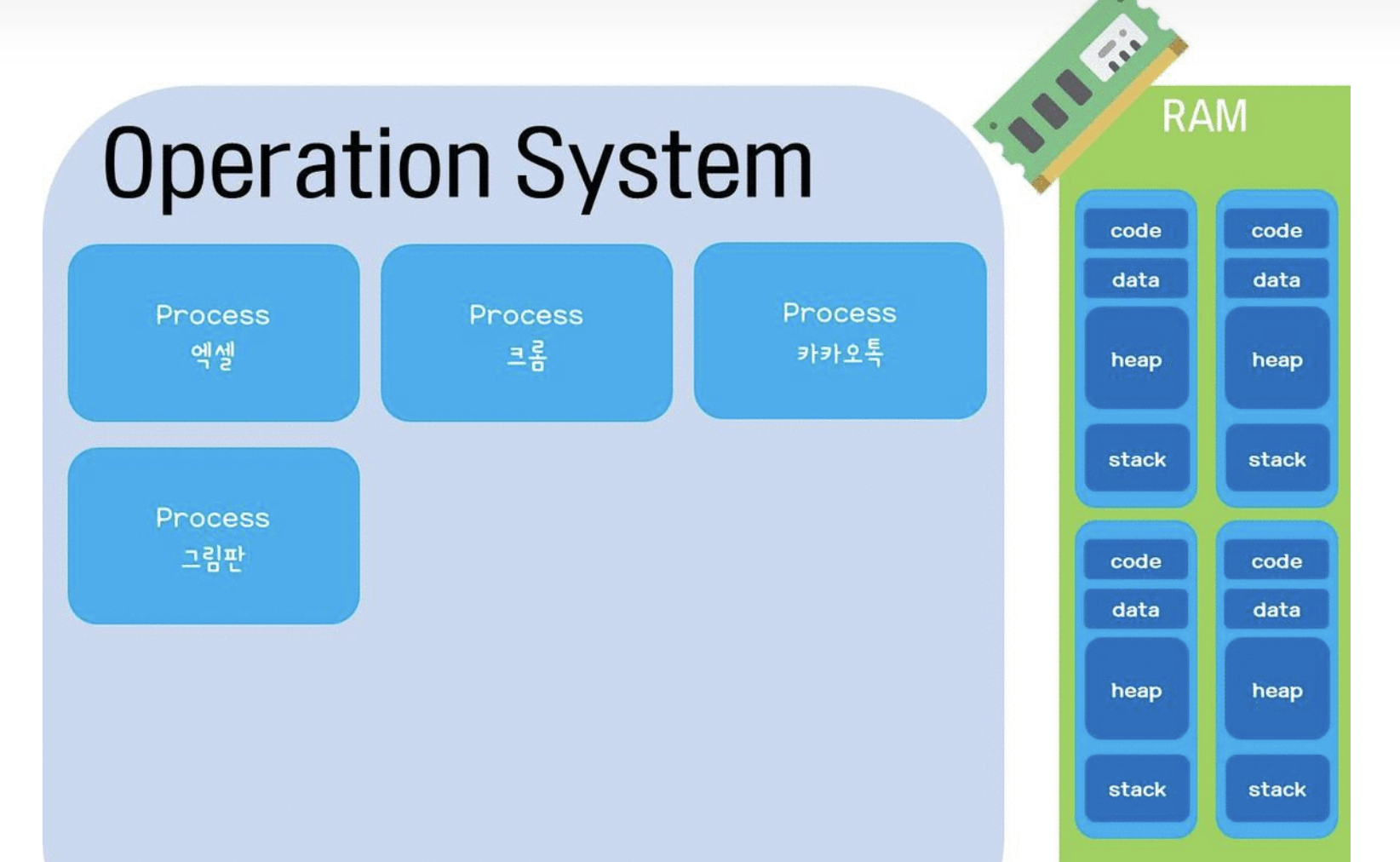
아래 그림과 같이 프로그램이 여러개 실행된다면 메모리에 프로세스들이 담길 주소 공간이 생성되게 되고 그 안에 Code, Data, Stack, Heap 공간이 만들어지게 된다.
📌 스레드의 자원 공유
스레드는 프로세스가 할당 받은 자원을 이용하는 실행의 단위로서, 스레드가 여러 개 있으면 우리가 파일을 다운 받으며 동시에 웹 서핑을 할 수 있게 해준다. 스레드끼리 프로세스의 자원을 공유하면서 프로세스 실행 흐름의 일부가 되기 때문에 동시 작업이 가능하다. 그래서 아래 사진과 같이 하나의 프로세스 내에 여러 개의 스레드가 들어있는 상태인 것이다.
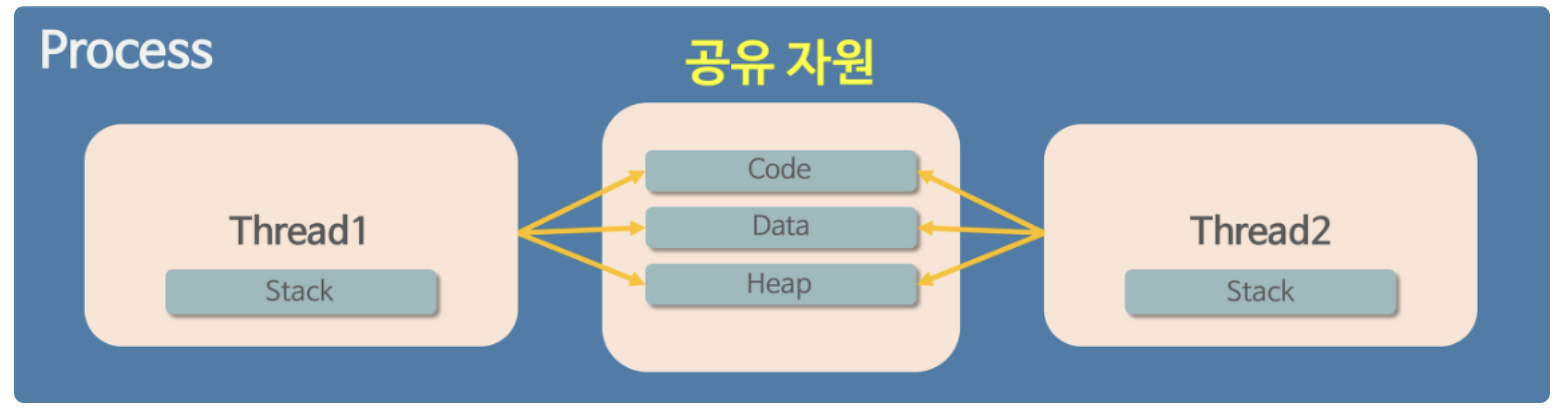
이 때 스레드는 Stack만 할당받아 복사하고 Code, Data, Heap은 프로세스내의 다른 스레드들과 공유된다. 따라서 각각의 스레드는 별도의 Stack을 가지고 있지만 Heap 메모리는 공유하기 때문에 서로 다른 스레드에서 가져와 읽고 쓸 수 있게 된다.
Stack은 함수 호출 시 전달되는 인자, 되돌아갈 주소값, 함수 내에서 선언하는 변수 등을 저장하는 메모리 공간이기 때문에, 독립적인 스택을 가졌다는 것은 독립적인 함수 호출이 가능하다 라는 의미이다. 그리고 독립적인 함수 호출이 가능하다는 것은 독립적인 실행 흐름이 추가된다는 말이다.
즉, Stack을 가짐으로써 스레드는 독립적인 실행 흐름을 가질 수 있게 되는 것이다.
하나의 프로세스를 다수의 실행 단위인 스레드로 구분하여 자원을 공유하고, 자원의 생성과 관리의 중복성을 최소화하여 수행 능력을 올릴 수 있다.
📌 프로세스의 자원 공유
기본적으로 각 프로세스는 메모리에 별도의 주소 공간에서 실행되기 때문에, 한 프로세스는 다른 프로세스의 변수나 자료구조에 접근할 수는 없다.
하지만 특별한 방법을 통해 프로세스가 다른 프로세스의 정보에 접근하는 것은 가능하다.
프로세스 간 정보를 공유하는 방법
- IPC(Inter-Process Communication) 사용
- LPC(Local inter-Process Communication) 사용
- 별도로 공유 메모리를 만들어서 정보를 주고받도록 설정
그러나 프로세스 자원 공유는 단순히 CPU 레지스터 교체뿐만이 아니라 RAM과 CPU 사이의 캐시 메모리까지 초기화되기 때문에 자원 부담이 크다는 단점이 있다. 그래서 다중 작업이 필요한 경우 스레드를 이용하는 것이 훨씬 효율적이다. 따라서 현대 컴퓨터의 운영체제에선 다중 프로세싱을 지원하고 있지만 다중 스레딩을 기본으로 하고 있다.
⚙️ 프로세스와 스레드의 동시 실행 원리
우리가 음악을 들으면서, 웹서핑을 하고, 메신저의 메시지를 확인할 수 있는 이유는 컴퓨터 내부적으로 프로세스와 스레드를 동시에 처리하는 멀티 태스킹(multi tasking) Visit Website 기술 때문이다. 하지만 여기서 동시에 처리한다는 것이 심플하게 CPU 프로세서가 프로그램들을 동시에 실행하는 것으로 생각하겠지만, 내부적으로 복잡한 원리에 의해 처리가 된다.
📌 멀티 코어와 스레드
CPU 한 개는 여러 개의 코어를 가질수 있다. 코어는 말그대로 CPU 코어 유닛이다. 즉, 명령어를 메모리에서 뽑아 해석하고 실행하는 반도체 유닛이 4개가 있는 것이다. 4 코어가 물리적 코어 갯수면, 8 스레드는 논리적 코어 갯수를 말한다. 이 경우 물리적 코어 하나가 스레드 두 개 이상을 동시에 실행 가능하다는 의미가 된다. 즉, 운영체제가 8개의 작업을 동시에 처리할 수 있다는 뜻이다. 이를 하이퍼 스레딩(Hyper-Threading) 기술이라 말한다.
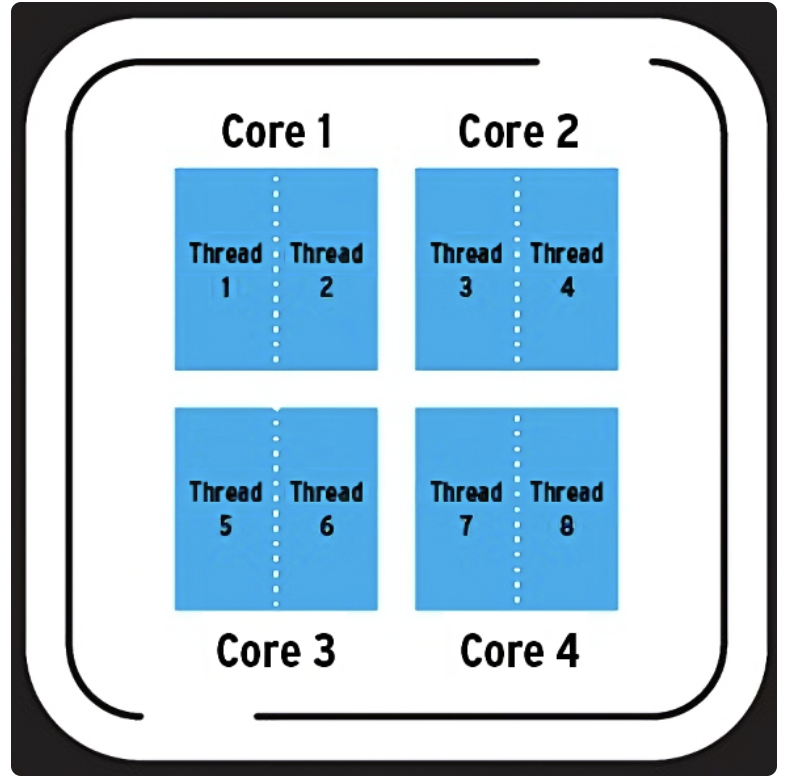
단, 여기서 CPU의 쓰레드는 우리가 배운 프로세스의 스레드와는 조금 다른 개념이다. 엄밀히 말하자면 CPU의 스레드는 하드웨어적 스레드이고 프로그램의 스레드는 소프트웨어적 스레드로 구분한다.
그럼 수십수백개의 프로세스들을 고작 8개의 논리적인 스레드로 어떻게 처리하는 것일까?
이 원리를 알기위해선 병렬성(Parallelism) 과 동시성(Concurrency) 이라는 개념을 알아야 한다.
📌 CPU의 작업 처리 방식
✔️ 병렬성 (Parallelism)
직관적으로 명령어를 메모리에서 뽑아 해석하고 실행하는 반도체 유닛인 여러 개의 코어에 맞춰 여러 개의 프로세스, 스레드를 돌려 병렬로 작업들을 동시 수행하는 것을 말한다.
✔️ 동시성 (Concurrency)
둘 이상의 작업이 동시에 실행되는 것을 의미한다. Parallelism가 물리적으로 정말로 동시에 실행하는 것이라고 하면, Concurrency는 동시에 실행하는 것처럼 보이게 하는 것으로 이해하면 된다.
예시)
1개의 코어가 있고 4개의 작업이 있다고 가정하다면, 프로세스들을 계속 번갈아가면서 조금씩 처리함으로써 마치 프로그램이 동시에 실행되는 것 처럼 보이는 것이다. 이 때 프로세스들을 번갈아가면서 매우 빠르게 처리하기 때문에 컴퓨터를 모르는 사람들이 보면 마치 동시에 돌아가는 것처럼 보이게 된다.
작업들을 아주 잘게 나누어 아주 조금씩만 작업을 수행하고 다음 작업으로 넘어가는 식으로 동작된다. 이렇게 하는 이유는 여러 작업을 동시에 처리하는 것처럼 보이게 만들어, 사용자에게 더 빠른 반응성을 제공하기 위함이다. 그리고 이렇게 진행 중인 작업들을 A → B → C → D 로 번갈아 바꾸는 것을 Context Switching (문맥 교환) 이라고 부른다.
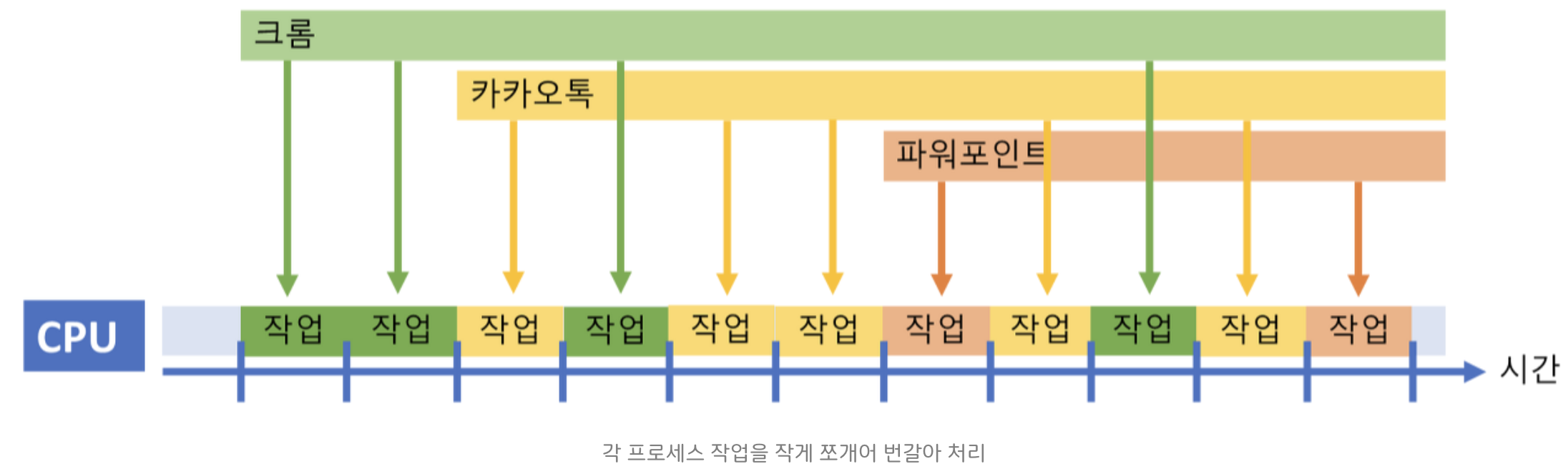
동시성이 필요한 이유는?
-
하드웨어적 한계 극복
CPU 발열 때문에 클럭으로 성능을 올리기에는 한계가 있기 때문에 코어의 성능을 올리는 대신 코어를 여러 개 탑재하여 쿼드 코어, 옥타 코어 CPU 들을 출시했다. 하지만 아무리 코어를 많이 넣어도 수십개의 코어를 넣을 순 없으니 결국 하드웨어적 제한이 걸리게 되고 수십수백개의 프로세스를 돌리기 위해서는 결국 동시성이 필요하다. -
논리적인 효율성
4코어 8스레드의 CPU 환경에서 현재 총 16개의 작업이 있다고 가정했을 때, 논리적인 8개의 코어이니 최대 8개까지 동시에 실행할 수 있다. 만약 8개의 오래 걸리는 작업이 먼저 동시에 처리되기 시작했다면, 나머지 8개의 작업은 처리하는데 짧은 시간이 걸리더라도 먼저 시작한 8개의 작업이 다 끝날 때까지 기다려야 한다.
이러한 비효율적인 부분을 극복하기 위해 작업을 아주 잘게 나누어 번갈아 가면서 처리하는 동시성 개념을 채택한 것이다.
따라서 최대 8개의 작업에 대해서 8개의 논리적인 스레드가 병렬적으로 아주 빠르게 동시적으로 작업을 하면서, 그보다 많은 수십개의 소프트웨어적 스레드가 있다면 적절히 병렬성과 동시성을 섞어 동시에 돌리게 된다.
⚙️ 프로세스와 스레드의 생명 주기
💡 참조 블로그 : 완전히 정복하는 프로세스 vs 스레드 개념
