요약
- Global Average Pooling을 사용하여overfitting을 방지하고, 각 클래스에 대한 공간적 정보를 유지하면서도 특징을 효과적으로 압축한다.
- Class Activation Mapping(CAM)는 특징 맵과 클래스별 가중치를 결합하여, 특정 클래스가 활성화되는 이미지 영역을 시각적으로 표시한다. 이를 통해 모델이 어떤 영역을 보고 객체를 인식하는지 이해할 수 있다. 이와 더불어 이미지 내 특정 객체의 위치를 추출하는 방법을 제시한다.
서론
기존 연구에서 CNN의 각 layer의 convolutional unit들이 object의 위치 정보를 주지 않았음에도 object detectors 처럼 동작한다는 것을 보였다.
이러한 주목할 만한 능력이 있는데, 분류를 위해 쓰이는 Fully-connected layers에서 이 능력들이 다 사라진다.
그래서 최근의 NIN, GoogLeNet 등 CNN모델들은 높은 성능을 유지하면서 파라미터 수를 줄이기 위해 FCN을 사용을 피하도록 제안되었다.
global average pooling: 학습하면서 오버피팅을 막는 structural regularizer처럼 동작한다.
근데, 우리는 이 연구에서 global average pooling이 단순히 regualrizer로 동작하는 것을 넘어 약간의 트릭을 쓰면, 주목할만한 localization 능력을 마지막 레이어까지 유지할 수 있게 만들 수 있다.
심지어, 학습하지 않은 task에 대해서도 이미지 영역 식별을 하는 것을 쉽게 확인할 수 있다.
객체 분류에 학습된 CNN이 사람이 상호작용하고 있는 객체를 중점적으로 인식하여 그 객체를 바탕으로 행동을 분류할 수 있다.
예를 들어 사람이 양치하고 있다면 칫솔을 중점적으로 인식해서 양치를 하는 행동으로 분류한다. 혹은, 나무를 배고 있다면 전기톱을 중점적으로 인식해서 나무를 배는 행동으로 분류한다.

간단한 방법이지만, 성능이 좋더라.
weakly supervised object localization on ILSVRC bench mark에서 37.1% top-5 test eror를 받았다.
게다가, deep features로부터 localization할 수 있는 점이 다른 연구에도 쉽게 활용될 수 있다.
-> 다른 recognition dataset이나 localization 그리고 concept discovery로 쉽게 전이될 수 있음을 보여준다.
- Weakly Supervised Object Localization(WSOL): 이미지 수준 레이블만으로 객체의 위치를 파악하는 방법을 학습하는 것
객체 수준 레이블(bonding boxes 등)은 비용이 비싸기 때문에, 저렴한 이미지 수준 라벨을 가지고 객체의 위치를 찾아보자!
관련 연구
Wealky-supervised Object Localization
CNN을 이용해서 Wealky-supervised object localization에 도전했다.
Bergamo et al. : 이미지의 특정 부분을 가려 네트워크가 가장 강하게 반응하는 부분을 찾아내어 객체의 위치를 파악하는 방법
Cinbis et al. : 다중 인스턴스 학습(Multiple-Instance Learning, MIL)'과 CNN의 특징들을 결합하여 객체를 위치시키는 방법을 제안함.
다중 인스턴스 학습은 학습 데이터가 여러 인스턴스(예: 이미지의 여러 부분)로 구성되어 있으며, 이 중 적어도 하나의 인스턴스가 긍정적인 예시일 때 전체 데이터가 긍정적으로 분류되는 학습 방식입니다.
Oquab et al. : 중간 수준의 이미지 표현을 전달(transfer)하는 방법을 제안하고, CNN의 출력을 여러 겹치는 패치(이미지의 부분 영역)에 대해 평가함으로써 일정 수준의 객체 위치 파악이 가능함을 보여줍니다. 이 접근법은 CNN이 이미지의 다양한 부분에 대해 반응하는 방식을 활용하여, 여러 개의 겹치는 영역을 분석함으로써 객체가 어디에 위치하는지 파악합니다.
=> 이런 연구들은 종단 간(end-to-end)으로 훈련되지 않았고, 여러 번의 네트워크 전달이 필요했기 때문에 대규모 데이터셋에 확장하기 어려웠다.
그리고 Global Max Pooling을 쓰지 않고, Global Average Pooling 을 썼더니 더 물체를 잘 식별하고 모든 물체의 discriminative regions에 대해서 loss가 max pooling보다 작았다.
Visualizing CNNs
CNN(합성곱 신경망) 내부 표현의 시각화에 대한 최근 연구를 다룬다.
Zeiler et al. : 이 연구는 역전파 네트워크(deconvolutional networks)를 사용하여 각 유닛이 활성화되는 패턴을 시각화합니다. 이를 통해 CNN이 이미지의 어떤 특징에 반응하는지를 파악할 수 있습니다.
Zhou et al. : 이들은 CNN이 장면을 인식하도록 훈련되는 동안 객체 감지기(object detectors)를 학습한다는 것을 보여줍니다. 이 연구는 CNN이 단일 전달에서 장면 인식과 객체 위치 파악을 모두 수행할 수 있음을 보여줍니다.
두 연구 모두 CNN의 합성곱 계층을 분석하는 데 중점을 두지만, 완전 연결 계층(FC layer)은 분석하지 않습니다. 이는 CNN의 전체적인 작동 방식에 대한 완전한 그림을 제공하지 못한다는 한계를 가집니다.
반면에, 이 논문의 접근 방식은 완전 연결 계층을 제거하고 대부분의 성능을 유지함으로써 네트워크의 처음부터 끝까지를 이해할 수 있게 합니다.
Mahendran et al. 및 Dosovitskiy et al. : 이 연구들은 CNN의 깊은 특징들을 역전파하여 CNN이 시각적으로 인코딩하는 정보를 분석합니다. 이들 방법은 완전 연결 계층을 역전파할 수 있지만, 이 정보의 상대적 중요성을 강조하지는 않습니다.
(what information is being preserved in the deep features without highlighting the relative importance of this information.)
이 논문은 이와 달리 어떤 이미지 영역이 판별에 중요한지 정확히 강조하는 방법을 제시합니다. 전반적으로, 이 논문은 CNN 내부의 작동 방식을 이해하는 데 도움이 되는 새로운 시각을 제공합니다.
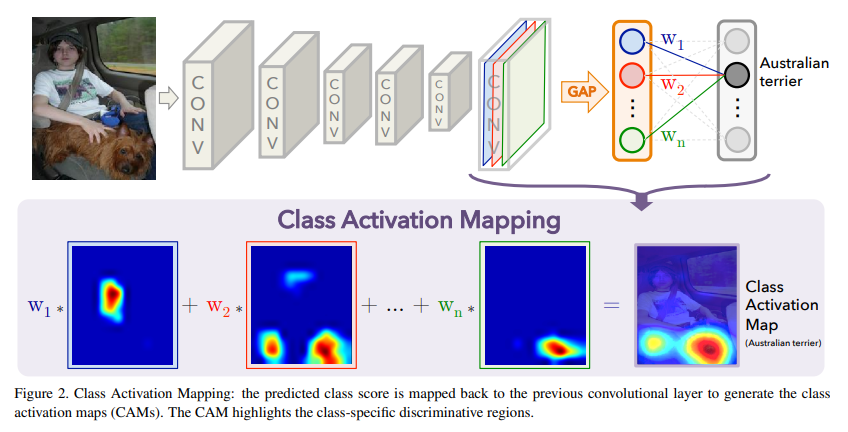
2. Class Activation Mapping
CAM은 특정 카테고리를 식별하는 데 CNN이 사용하는 차별적 이미지 영역을 나타냅니다. 이러한 맵은 각 이미지에 대해 생성되며, CNN이 어떤 이미지 영역이 특정 클래스를 식별하는 데 중요한지를 시각적으로 보여줍니다.
NIN이나 GoogLeNet과 유사한 네트워크 구조를 가진다. (FC layer를 지양함)
Convolutional layers를 많이 쌓고, 마지막 layer 전에(기존의 flatten하는 구간) global average pooling을 feature maps에 적용해서 (WxHxC)를 (1x1xC)로 만들어 버린다. 이후에 FC layer를 하나 연결해서 분류 등을 수행한다.
이 구조를 사용하면 FC layer의 weight를 feature map에 투영하여 이미지 영역의 중요성을 파악할 수 있다.
<CAM 생성 과정>
마지막 합성곱 계층의 특징 맵 활용: CAM 생성은 CNN의 마지막 합성곱 계층에서 추출한 특징 맵(feature map)을 기반으로 합니다. 이 계층에서는 이미지의 다양한 부분이 어떻게 네트워크에 의해 인식되는지에 대한 정보가 담겨 있습니다.
글로벌 평균 풀링 적용: 각 특징 맵에 대해 글로벌 평균 풀링(Global Average Pooling, GAP)을 수행합니다. 이는 각 특징 맵의 공간적 평균을 산출하여, 각 특징 맵이 전체 이미지에 걸쳐 어떤 평균적인 활성화를 보이는지를 나타냅니다.
가중 합 계산: 이러한 평균 활성화 값들에 대해, 클래스별 가중치를 적용하여 가중 합(weighted sum)을 계산합니다. 이 가중 합은 각 클래스에 대한 네트워크의 최종 응답을 나타내며, 각 클래스별로 다른 패턴을 보입니다.
클래스 활성화 맵 생성: 이 가중 합을 통해 각 클래스에 대한 클래스 활성화 맵(CAM)을 생성합니다. CAM은 이미지 내에서 해당 클래스를 인식하는 데 중요한 영역을 시각적으로 보여줍니다.
시각적 해석과 적용: CAM은 특정 클래스에 대해 CNN이 이미지의 어느 부분을 중요하게 여기는지를 시각적으로 나타내줍니다. 이를 통해 이미지 내 객체의 위치를 파악하거나 CNN의 결정 과정을 이해하는 데 활용할 수 있습니다.
수식 표현
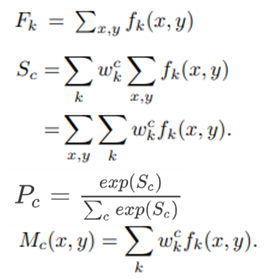 : Feature Map k의 가로(), 세로()에 해당하는 값
: Feature Map k의 가로(), 세로()에 해당하는 값
: 특징변수
: Feature Map의 index
: Feature Map의 가로, 세로 좌표
: 특징변수 가 클래스 에 기여하는 weight
: 각 클래스로 분류될 확률
는 클래스 c에 대한 의 기여도를 의미한다. 따라서 와 의 곱의 합을 class score 로 나타낼 수 있다.
이 식을 변형시키면 클래스 에 대한 CAM 를 구할 수 있다.
각 feature map 에 해당 클래스에 대한 가중치 를 곱한 후, 이를 모두 합산하여 클래스 의 활성화 맵을 생성한다.
특정 클래스가 이미지의 어느 부분에서 활성화되는지를 시각적으로 파악할 수 있습니다.
CAM은 이미지 내 객체의 위치를 파악하거나, 모델이 특정 결정을 내린 이유를 이해하는 데 유용합니다.
참고 문헌
[PAPER] Learning Deep Features for Discriminative Localization, CVPR 2016
https://joungheekim.github.io/2020/09/29/paper-review/
https://sudormrf.run/2016/04/10/object-localization-with-weakly-supervised-learning/
https://jays0606.tistory.com/m/4
