

색인 ( Index ) 이란?
문서에서 키워드를 쉽게 찾을 수 있도록 정렬한 형식을 말합니다.
위의 그림의 오른쪽에서 키워드를 정렬한 것을 말합니다.
역색인 ( Inverted Index ) 이란?
키워드를 이용해서 문서를 찾는 방식을 말합니다.
위의 그림에 찾아보기 처럼 해당 키워드에 해당하는 문서의 위치를 표현합니다.
예를 들어 특정 키워드를 찾고 싶을 때 책 뒷쪽에 색인 ( index ) 즉 찾아보기를 이용해 정렬된 목록을 살펴본 이후에 해당 키워드에 해당하는 페이지를 확인하여 키워드를 찾을 수 있는데 이를 역색인 ( Inverted Index) 이라고 합니다.
탐색 속도
역색인의 검색 성능은 매우 빠릅니다. 그 이유는 색인 ( Index ) 같은 경우에 키워드를 찾기 위해 모든 데이터를 조회해야 하는데 역색인 ( Inverted Index ) 같은 경우에는 해당 키워드에 해당하는 주소값 ( 페이지 ) 만 읽으면 되기 때문에 속도가 빠릅니다.
색인을 사용한 검색

위의 그림을 보면 'fox' 라는 키워드를 검색할 때 모든 텍스트를 읽어야합니다. 따라서 많은 데이터를 검색할 경우 그만큼 성능이 저하될 수 있습니다.
RDBMS 에서는 Like 키워드를 사용하여 검색을 할 때 사용되며 데이터가 많아질수록 검색 성능이 떨어질 수 있습니다.
역색인을 사용한 검색
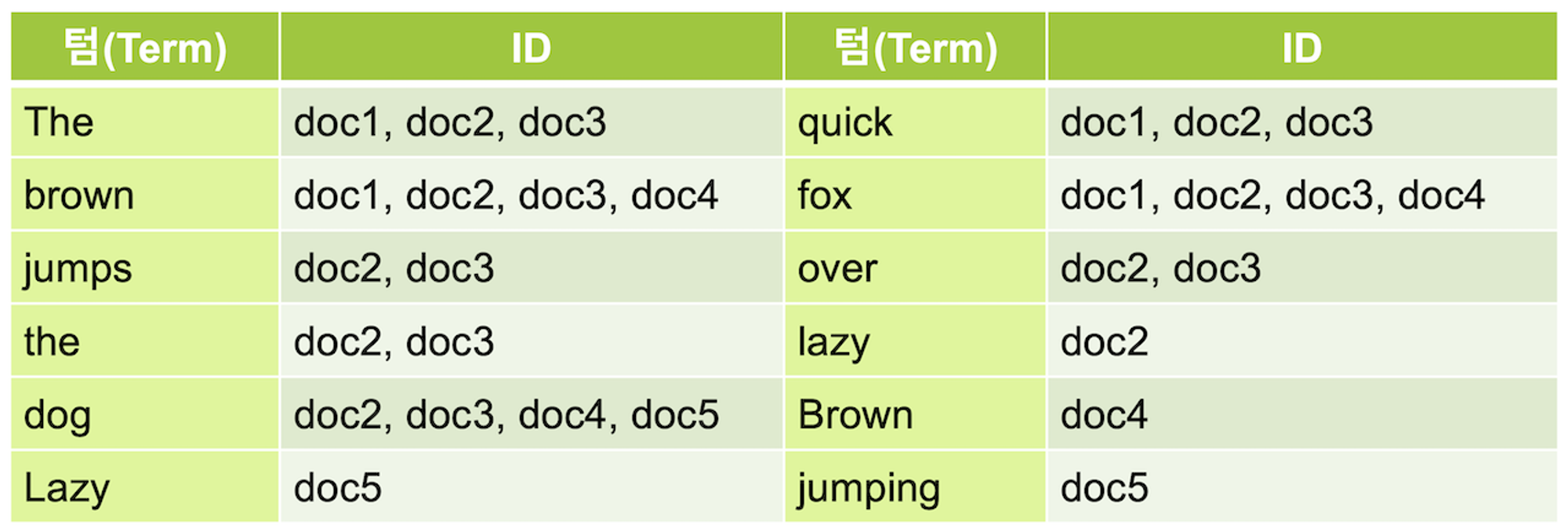
역색인은 책 뒤에 찾아보기와 같이 해당 Term ( 키워드 ) 에 해당하는 주소값만 읽으면 되기 때문에 속도가 빠릅니다. 역색인을 사용하면 데이터가 추가되어도 조회해야 하는 행이 늘어나느 것이 아니라 역색인이 가리키는 Term 의 ID 배열 값에 ID가 추가되는 것이기 때문에 성능에 큰 문제가 되지 않습니다.
여기서 ID는 PK , 물리적 주소를 말합니다.
역색인 생성 과정
- The quick brown fox jumps over the lazy dog.
- Fast jumping rabbits.
위의 두 예문을 역색인 한다고 가정합니다.
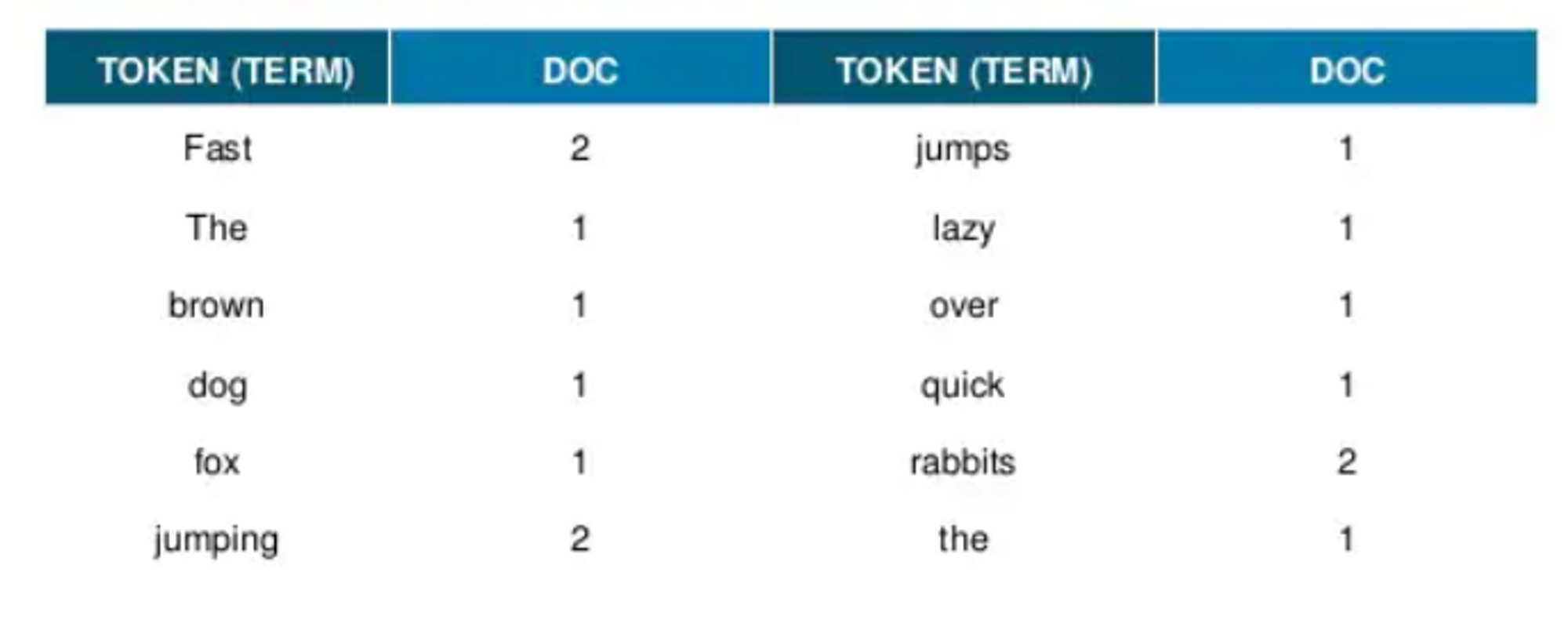
다음과 같은 문서를 역색인 한다고 한다면 먼저 모든 단어를 쪼갭니다.
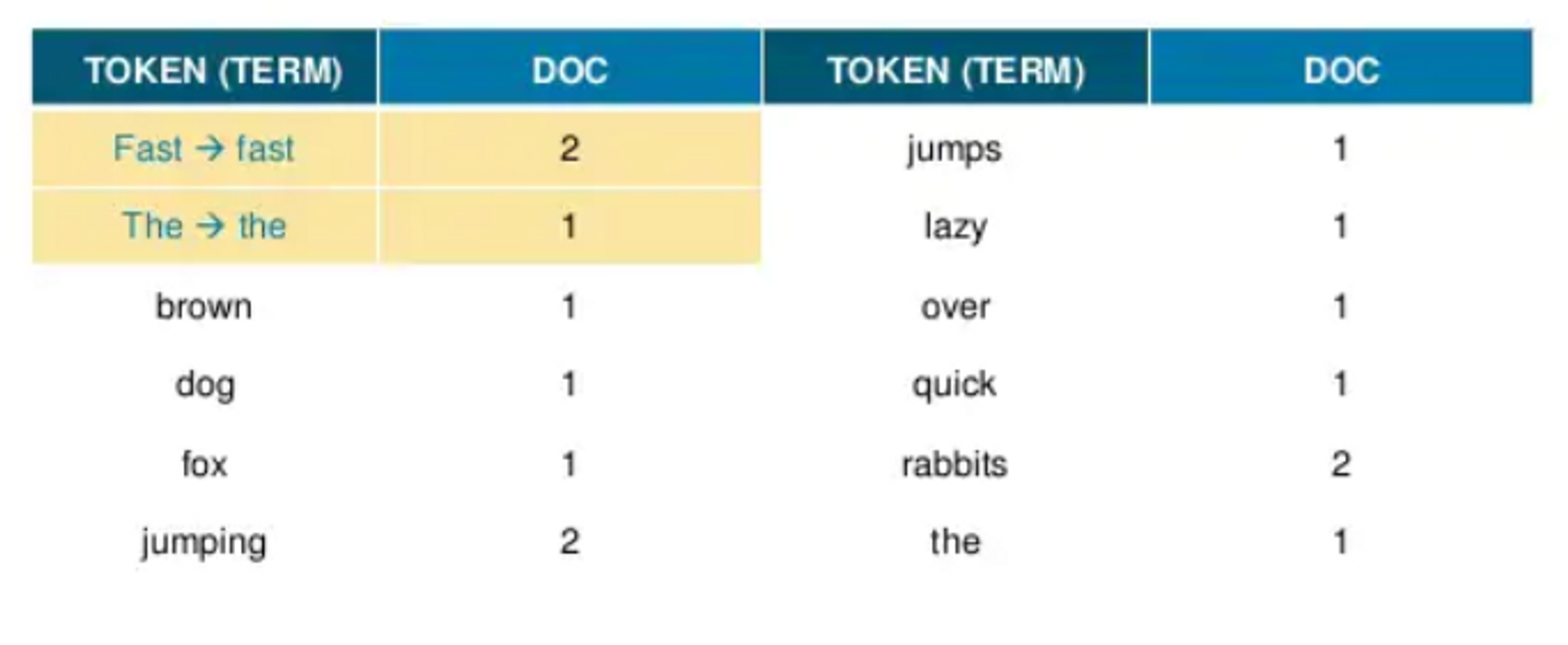
그 다음 대문자를 소문자로 변환한 다음에 각 토큰을 ascii 순서로 정렬합니다.
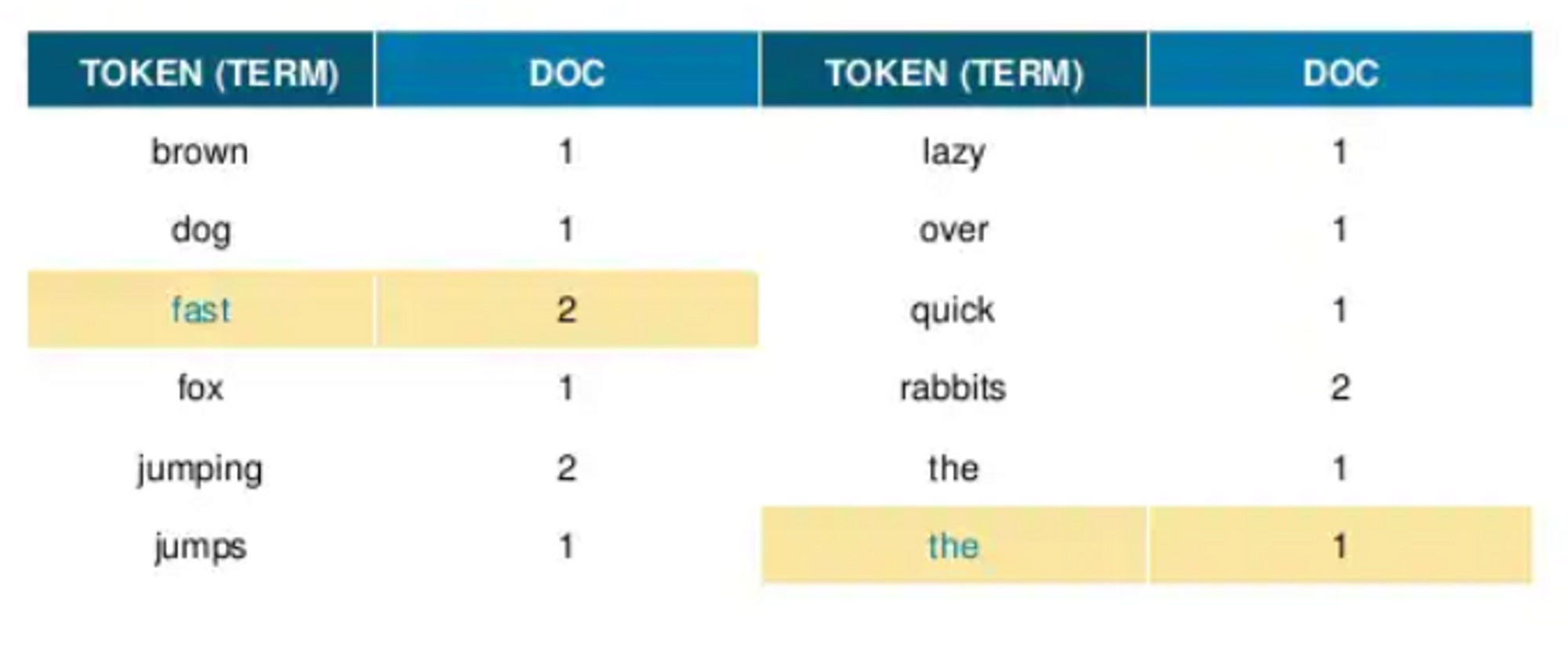
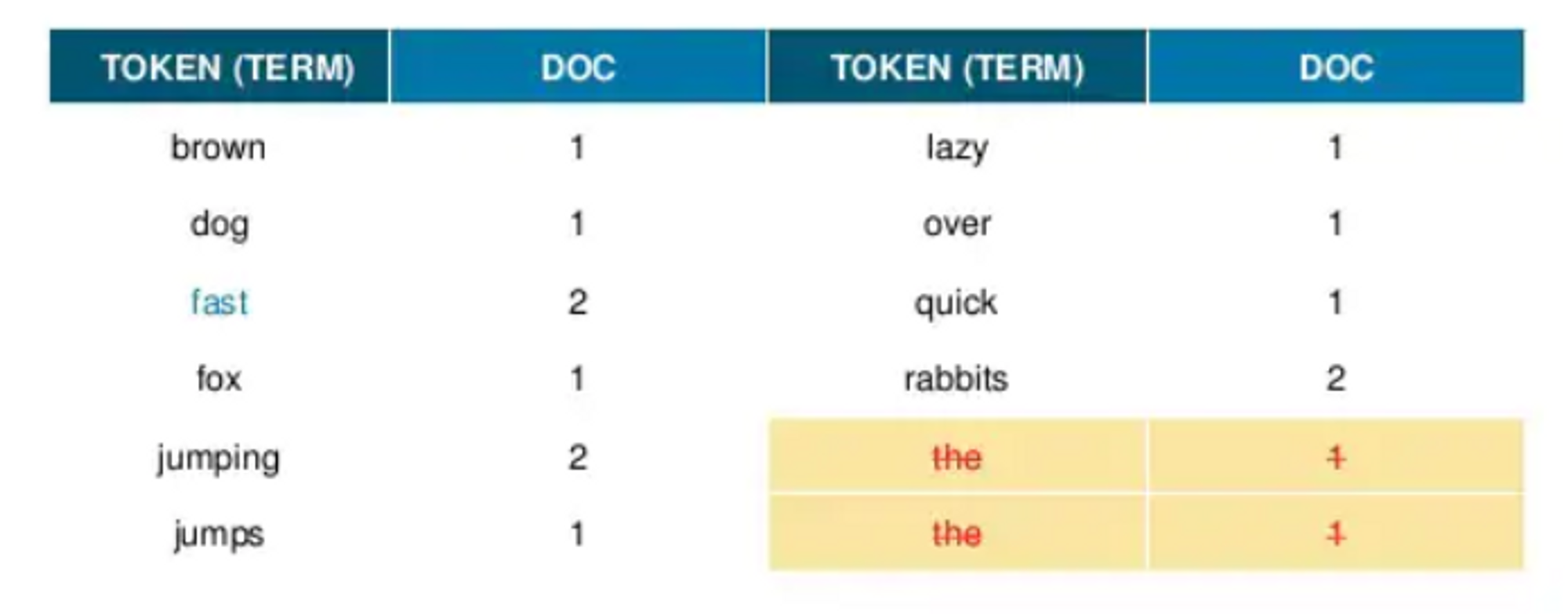
다음 and , a 와 같이 검색어로 가치가 없는 불 용어를 제거합니다.

형태소 분석 과정을 거칩니다. ( 보통 ~s , ~int 를 제거합니다. )
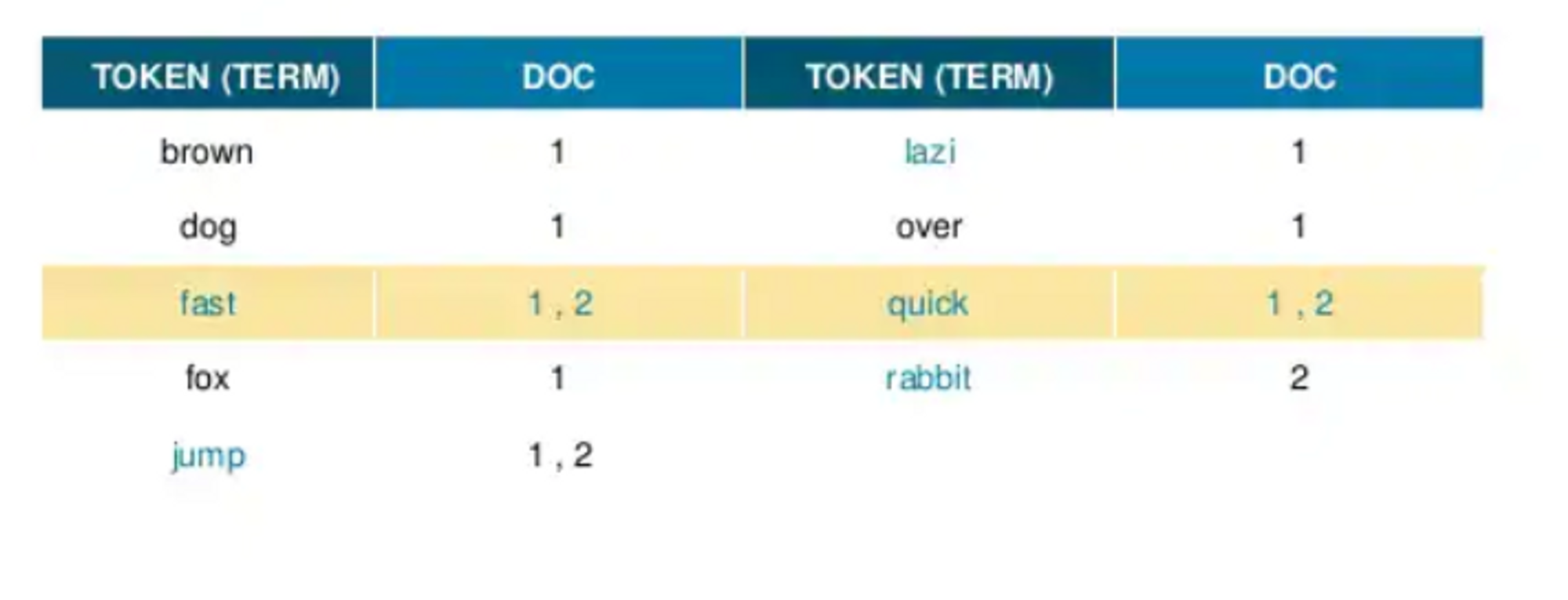
중복된 토큰을 하나로 병합하며 , 동의어를 처리합니다.
여기서 쪼개진 term 의 갯수가 많다면 term을 찾기 위해서 많은 비용이 들어갈 수 있다고 생각할 수 있지만 역색인 구조는 B-Tree와 유사하게 Skips-List와 FST를 활용하여 시간복잡도 O ( logN ) 을 보장합니다.
참고
참고 블로그 1 : https://steady-coding.tistory.com/581
참고 블로그 2 : https://the-dev.tistory.com/30
