
동기 & 비동기
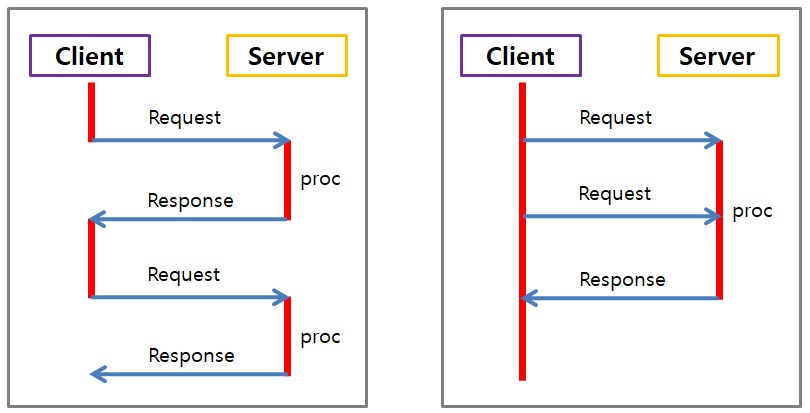
동기란?
서버에 대해 요청을 하고, 응답이 올 때 까지 대기한다.
즉, 요청을 하고 응답을 받아야 다음 작업을 수행한다.
동기 특징
동기 방식을 채택하면 코드와 흐름을 이해하기 쉽지만 블로킹이 발생한다.
블로킹이 발생하면 스레드를 하나 점유하게 된다.
이때 외부 API 혹은 DB , I/O 작업이 오래 걸리게 되면 하나의 스레드는 멈춘 상태로 놀게된다.
그리고 동기 방식은 작업을 순차적으로 처리하기 때문에 작업 순서가 지켜진다.
비동기란?
동기와 반대로 서버에 대해 요청을 하고 결과를 받기 전 다른 작업을 수행한다.
비동기 특징
대기 없이 바로 다른 작업을 수행하기 때문에 처리량이 증가하게 된다.
하나의 스레드가 여러 요청을 처리하기 때문에 효율적이며, 외부 API 혹은 DB, I/O 대기 시간동안 다른 요청을 처리할 수 있다.
단, 코드의 복잡도가 높아지고 디버깅 난이도가 높아진다는 단점을 가지고 있으며, 작업의 순서가 지켜지지 않을 수 있다.
| 구분 | 동기 | 비동기 |
|---|---|---|
| 대기 여부 | 작업 끝날 때까지 대기 | 대기 안 함 |
| 스레드 사용 | 요청당 1스레드 점유 | 효율적 사용 |
| 구현 난이도 | 쉬움 | 상대적으로 어려움 |
| 성능 | 트래픽 적을 때 충분 | 고트래픽에 유리 |
| 대표 기술 | Spring MVC | WebFlux, CompletableFuture |
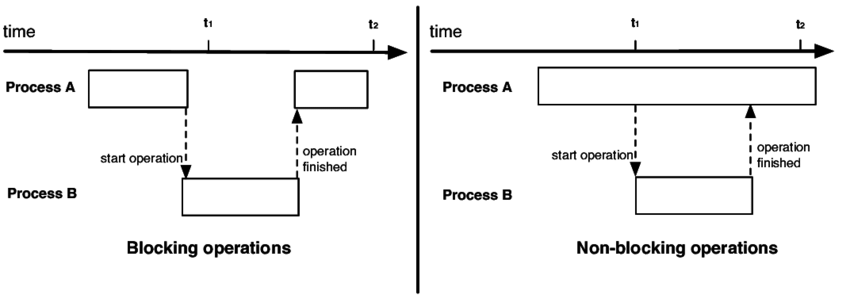
블로킹 & 논블로킹
블로킹과 논블로킹은 다른 요청을 처리하기 위해 현재 작업을 Block 하냐 안하냐의 유무를 나타내는 프로세스 실행 방식이다.

블로킹
블로킹은 호출한 스레드가 작업이 끝날 때 까지 다른 작업이 수행되지 않는 상태를 말한다.
예를 들어 A 작업이 수행 중일 때 I/O 작업이 실행되어 A 작업도 함께 멈추는 상태를 말한다.
이때 A 작업을 수행하던 스레드가 I/O 때문에 작업이 멈추게 된다.
논블로킹
논블로킹은 호출한 스레드가 작업이 끝나지 않아도 다른 작업이수행되는 상태이다.
예를 들면 A 작업이 수행 중일 때, I/O 작업이 수행되어도 A 작업은 멈추지 않는다.
Spring WebFlux 구조
[ Application (Spring WebFlux, Netty) ] ← USER SPACE
[ JVM ] ← USER SPACE
[ OS Kernel (epoll, socket) ] ← KERNEL SPACE
[ NIC / Disk ] ← HW
Spring WebFlux
├─ Event Loop (이벤트 루프)
├─ Reactive Pipeline (Flux / Mono)
└─ Worker Loop (Scheduler / Worker Thread Pool)
Spring WebFlux는 전적으로 USER SPACE( 유저 영역) 에서 동작하는 프레임워크이고 커널과는 대화하지 않는다.
OS 커널 위헤서 Netty / Reactor 와 같은 라이브러리와 함께 동작한다.
이벤트 루프
이벤트 루프는 하나의 루프당 하나의 스레드를 가지고 있고 Netty 내부에 존재하며 보통 CPU 코어 수 x 2 개 정도로 가지고 있다.
해당 루프 갯수는 사용자가 조정할 수 있다. 사용자가 스레드 수를 설정하면 해당 값에 고정하여 생성한다.
이벤트 루프는 Netty 를 통해 전달받은 작업을 워커 루프에게 넘겨주거나 직접 처리한다.
이벤트 루프가 직접 처리할지 혹은 워커 루프에게 전달할 지는 개발자가 선택할 수 있다.
아래의 코드는 워커 루프에게 작업을 전달한다. 만약 하단의 코드를 작성하지 않으면 기본적으로 이벤트 루프에서 작업을 처리하게 된다.
.publishOn(Schedulers.boundedElastic());
.subscribeOn(Schedulers.boundedElastic());이벤트 루프의 지연
만약 이벤트 루프에서 작업을 처리하는 과정에서 Blocking 이 걸리게 될 경우, 해당 이벤트 루프는 지연된다.
이때 해당 이벤트 루프가 담당하는 요청이 멈추게 된다.
해당 요청이 다른 요청으로 갈아타면 될 것 같지만, 이미 특정 이벤트 루프에 할당된 요청은 다른 이벤트 루프로 갈아탈 수 없다.
( 그 이유는 Netty의 스레드 안정성 보장 설계로 인해 TCP 커넥션이 생성되는 순간 하나의 이벤트 루프가 선택되고, 해당 이벤트 루프로 CRUD 작업을 하게 된다. )
즉, 해당 요청이 Blocking 으로 인해서 TPS 가 곤두박질 치게 된다.
따라서 이벤트 루프는 절대 블로킹 되면 안된다.
만약 블로킹이 발생하게 되면 해당 이벤트 루프 스레드가 담당하는 모든 요청이 멈추게 되기 때문에 블로킹 작업은 워커 루프에게 전달해야 한다.
모든 작업을 워커 루프에게 던져도 되나?
모든 작업을 워커 루프에게 던져도 되긴 하지만, 구조적으로 좋지 않은 설계가 나올 수 있다.
이벤트 루프에는 논블로킹 , 가벼운 작업만 남기는 것이 좋다.
이벤트 루프는 소수의 스레드로 많은 커넥션을 빠르게 처리하기 위한 구조이다. 이때 모든 작업을 워커 루프로 넘기게 될 경우 Context Switching 비용이 증가하고, 워커 풀 병목으로 응답 지연 발생할 수 있다.
즉, 워커 루프가 포화상태가 되어버릴 수 있다는 것이다. 그렇게 되면 Thread-per-request와 비슷해진다.
이는 요청이 워커 하나를 점유하기 때문에 WebFlux를 사용하는 이유가 사라진다.
따라서 WebFlux 에서는 논블로킹 작업은 이벤트 루프에서 처리하고, 블로킹 작업만 선택적으로 워커 스레드 풀로 위임하는 것이 좋다.
단, 워커 루프와 이벤트 루프 사이에 MQ 를 둔다면 이러한 문제를 개선할 수 있다.
MQ ( enqueue )
워커 루프와 이벤트 루프 사이에 MQ ( enqueue ) 를 위치하여 요청-처리를 분리시킬 수 있으며, 모든 작업을 큐를 통해 워커로 전달해도 된다.
이때 MQ 클라이언트가 논블로킹이여야 한다. ( Kafka Reactive, Reactive RabbitMQ, WebClient 기반 브로커 API )
return mqClient.send(message) // 논블로킹
.thenReturn("accepted");
rabbitTemplate.convertAndSend(...); // ❌ 블로킹
MQ ( enqueue ) 의 장단점
MQ 를 사용하게 되면, 느린 작업을 분리할 수 있어, 이벤트 루프가 보호된다. 그리고 트래픽이 순간 많아진다 하더라도 큐에 적재되기 때문에 두 루프 ( 워커 루프 , 이벤트 루프 ) 간에 처리 속도가 달라져도 된다. ( 부하 흡수 )
단, 요청-응답이 즉시 이뤄져야 하고 ( 해당 요청에 대한 성공, 실패를 바로 알려야할 때 ), 수 ms 정도로 짧은 처리일 경우엔 MQ 를 사용하지 않는 것이 좋을 수 있다.
워커 루프 ( 워커 쓰레드 풀 - Scheduler )
워커 풀에 있는 워커들은 기본적으로 CPU 코어 수 x 10 개 정도로 가지고 있으며, 모든 이벤트 루프가 모든 워커를 공유한다.
이때 워커 쓰레드 풀 안에는 워커들이 존재하며, 하나의 워커당 하나의 쓰레드를 가지고 작업한다.
워커 루프 역시 사용자가 갯수를 설정할 수 있다. 단, 이벤트 루프와는 다르게 갯수가 유동적으로 바뀔 수 있다. 이때 요청이 많으면 최대값 까지 쓰레드 갯수를 설정하고, 요청이 적으면 일부 스레드만 활성화 한다.
워커 루프는 특정 이벤트 루프의 소유가 아닌 공용으로써, 필요한 이벤트 루프가 워커 루프에게 작업을 던지고 결과만 다시 받는다.
워커 루프는 이벤트 루프에서 작업을 받아 처리 후 전달해준다.
워커 풀 내부 큐
워커 쓰레드 풀에 있는 쓰레드가 모두 사용중이면 대기할 수 있는 큐가 있다.
새로운 작업이 들어왔을 때 사용 가능한 스레드 ( 워커 쓰레드 풀 ) 가 없다면 큐에 들어가 대기 한다.
이때 대기 큐에 모두 찰 경우 처리할 수 없는 상태가 된다. 이때 reject ( 예외 발생 ) 하거나 backpressure ( 작업 생성 속도 제한 ) 할 수 있는 설정을 추가해야 한다.
워커 쓰레드 풀을 많게 설정한다 하더라도, 물리 쓰레드 풀은 많아지지 않는다.
말 그대로 사용자가 워커 쓰레드 풀을 100개로 설정한다 하더라도, 실제 물리 쓰레드는 늘어나지 않고 정해져 있다.
즉, 물리 쓰레드가 컨텍스트 스위칭을 통해 작업을 처리하게 된다.
물론 워커 쓰레드 풀을 많이 할당하면 물리 쓰레드로부터 할당받을 확률이 높아진다.
