✨ 스프링 입문 - 코드로 배우는 스프링 부트, 웹 MVC, DB 접근 기술
🔅 목차
✅회원 관리 예제 - 백엔드 개발
#1 비즈니스 요구사항 정리
✔#2 회원 도메인과 리포지토리 만들기
#3 회원 리포지토리 테스트 케이스 작성
#4 회원 서비스 개발
#5 회원 서비스 테스트
🔅 회원 도메인과 리포지토리 만들기
🌱 회원 객체 만들기
✅ 소스
package hello.hellospring.domain;
public class Member {
private Long id;
private String name;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
✅ 소스 설명
회원 객체 Member을 만들면서, 변수로 id와 name을 만들어 주었다.
그런데 왜 class는 public이고, 변수는 private이며, getter/setter을 왜 만들어 주었을까?
이를 알기 위해 public과 private에 대해 알아보자.
💡public
public은 class 외부에서 접근할 수 있는 변수이다.
이는 곧 외부에서 값을 마음대로 바꿀 수 있다는 뜻이다.
예시를 들어 알아보자.
package hello.hellospring;
public class testClass {
public static void main(String[] args) {
Car car = new Car();
car.fual = 10;
car.show();
car.fual = -10;
car.show();
}
public static class Car {
int fual;
void show() {
System.out.println("연료의 양은 " + fual + "입니다.");
}
}
}
Car 객체는 public 멤버 변수로 되어있다.
자동차의 연료 특성상 음수가 될 수 없음에도, 외부에서 값이 접근이 가능하기 때문에 음수를 직접 대입하여 설정 할 수 있다.
출력을 해보면 다음과 같다는 걸 알 수 있다.
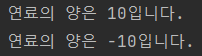
💡private
private 멤버는 class 외부에서 접근할 수 없는 변수이다.
즉, 외부에서 값을 직접적으로 대입시킬 수 없으며, 외부에서 private 변수에 값을 대입하기 위해서는 set 함수(setter)을 사용해야 한다.
set 함수는 private 멤버에 제약조건을 걸어서 예기치 않은 값에 대해 문제를 방지 할 수 있는 것이다.
예제로 알아보자.
package hello.hellospring;
public class testClass {
public static void main(String[] args) {
Car car = new Car();
car.setFual(50);
System.out.println(car.getFual());
car.setFual(-20);
System.out.println(car.getFual());
}
public static class Car {
private int fual;
public int getFual() {
return fual;
}
public void setFual(int inputFual) {
if(inputFual>0 && inputFual <= 100) {
this.fual = inputFual;
} else {
System.out.println("값이 올바르지 않습니다.");
}
}
}
}
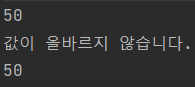
이렇게 private를 사용함으로써 잘못된 값이 실수로라도 들어오는 경우를 방지할 수 있다.
이처럼 클래스에 데이터(필드)와 기능(메소드)를 한 곳에 모아둔 다음 보호하고 싶은 멤버에 private을 붙여 접근을 제한하는 기능을 캡슐화라고 한다.
보통 필드(변수)는 private을, 함수(메소드)는 public으로 지정한다.
🌱 회원 리포지토리 인터페이스 만들기
✅ 소스
회원 객체를 저장하는 저장소 기능을 하는 회원 리포지토리 인터페이스이다.
package hello.hellospring.repository;
import hello.hellospring.domain.Member;
import java.util.List;
import java.util.Optional;
public interface MemberRepository {
Member save(Member member); // 회원 저장
Optional<Member> findById(Long id); // 아이디로 회원 찾기
Optional<Member> findByName(String name); // 이름으로 회원 찾기
List<Member> findAll(); // 모든 회원의 리스트를 반환
}
1. Repository는 왜 interface로 이루어져 있을까?
개방폐쇄원칙을 따르기 때문이다. Repository의 구현체에서 변경이 발생하더라도 Repository를 사용하는 부분에는 영향이 끼치지 않는다.
위의 말을 이해하기 위해 자바 interface 개념에 대해 자세히 알아보자.
💡interface
자식 클래스가 여러 부모 클래스를 상속 받을 수 있다면, 다양한 동작을 수행할 수 있다는 장점을 가지게 될 것이다.
하지만 클래스를 이용하여 다중 상속을 할 경우 메소드 출처의 모호성 등 여러 가지 문제가 발생할 수 있어 자바에서는 클래스를 통한 다중 상속은 지원하지 않는다.
하지만 다중 상속의 이점을 버릴 수는 없기에 자바에서는 인터페이스라는 것을 통해 다중 상속을 지원하고 있다.
인터페이스(Interface)란 다른 클래스를 작성할 때 기본이 되는 틀을 제공하면서, 다른 클래스 사이의 중간 매개 역할까지 담당하는 일종의 추상 클래스를 의미한다.
자바에서 추상 클래스는 추상 메소드뿐만 아니라 생성자, 필드, 일반 메소드도 포함할 수 있다. 하지만 인터페이스(interface)는 오로지 추상 메소드와 상수만을 포함한다.
이 외의 자세한 인터페이스(interface) 설명은 링크를 통해 확인하면 되겠다.
2. MemberRepository에 쓰인 각종 메소드에 대한 설명
메소드를 이해하기 전에 먼저 Spring Data JPA에 대한 개념을 알아야한다. 이는 링크를 걸어둘테니 미리 보고 오자.
MemberRepository에 쓰인 메소드들은 CrudRepository에서 쓰이는 메소드들이다. CrudRepository 인터페이스는 관리되는 엔티티 클래스에 대한 CRUD 기능을 제공한다.
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity); // 주어진 엔티티를 저장
Optional<T> findById(ID primaryKey); // 지정된 ID로 식별되는 엔티티를 반환
Iterable<T> findAll(); // 모든 엔티티를 반환
long count(); // 엔티티 수를 반환
void delete(T entity); // 지정된 엔티티를 삭제
boolean existsById(ID primaryKey); // 주어진 ID를 가진 엔티티가 있는지 여부를 나타냄
}💡findby로 시작하는 메소드
Spring Data JPA 에서는 인터페이스에 선언한 메서드 이름으로 쿼리(JPQL)를 생성해주는 기능이 있다. findBy 뒤에 원하는 엔티티를 붙여주면 되고, 메소드에 AND나 OR 등의 키워드를 작성함으로써 쿼리에서 WHERE 조건에 쓰이는 표현을 사용할 수 있다. 예시로 알아보자.
public interface MemberRepository extends JpaRepository<Member, Long> {
List<Member> findByEmailAndName(String email, String name);
}위와 같이 작성하면 Spring Data JPA가 메서드 이름을 분석해서 JPQL을 생성한다. 해당 JPQL은 다음과 같다.
SELECT m FROM Member m WHERE m.email =?1 AND m.name = ?2메소드에 사용할 수 있는 키워드는 다음과 같다.
| Keyword | Sample | JPQL snippet |
|---|---|---|
| Distinct | findDistinctByLastnameAndFirstname | select distinct ... where x.lastname = ?1 and x.firstname = ?2 |
| And | findByLastnameAndFirstname | ... where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | ... where x.lastname = ?1 or x.firstname = ?2 |
| Is, Equals | findByFirstname | ... where x.firstname = ?1 |
| Between | findByStartDateBetween | ... where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | ... where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | ... where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | ... where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | ... where x.age >= ?1 |
| After | findByStartDateAfter | ... where x.startDate > ?1 |
| Before | findByStartDateBefore | ... where x.startDate < ?1 |
| IsNull, Null | findByAge(Is)Null | ... where x.age is null |
| IsNotNull, NotNull | findByAge(Is)NotNull | ... where x.age is not null |
| Like | findByFirstnameLike | ... where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | ... where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | ... where x.firstname like ?1(parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | ... where x.firstname like ?1(parameter bound with prepended %) |
| Containing | findByFirstnameContaining | ... where x.firstname like ?1(parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | ... where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | ... where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | ... where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection ages) | ... where x.age not in ?1 |
| True | findByActiveTrue() | ... where x.active = true |
| False | findByActiveFalse() | ... where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | ... where UPPER(x.fisrtname) = UPPER(?1) |
3. Optional 에 대한 설명
💡Optional 이란?
자바8에서 Optional 클래스를 이용해 NPE(NullPointerException)을 방지할 수 있도록 함. Optional은 Null이 올 수 있는 값을 감싸는 Wrapper 클래스로, 참조하더라도 NPE가 발생하지 않도록 함.
Optional 클래스는 아래와 같은 value에 값을 저장하기 때문에 값이 Null이더라도 바로 NPE 이 발생하지 않음.
또한, 클래스이기 때문에 각종 메소드를 지원해줌
public final class Optional<T> {
private fianl T value;
}💡Optional 이 만들어진 이유와 의도
자바8부터는 Null이나 Null이 아닌 값을 저장하는 컨테이너 클래스인 Optional이 추가되었다. Java 언어의 아키텍트(설계자)인 Brain Goetz은 Optional에 대해 다음과 같이 말한다.
Optional은 Null을 반환하면 오류가 발생할 가능성이 매우 높은 경우에 '결과 없음'을 명확하게 드러내기 위해, 메소드의 반환 타입으로 사용되도록 매우 제한적인 경우로 설계되었다. 이 설계 목적이 아닌 Optional을 잘못 사용할 경우, 많은 부작용이 발생할 수 있다.
💡Optional 활용 방법
✔ Optional 생성하기 - 값이 Null인 경우
Optional은 Wrapper 클래스이기 때문에 값이 없을 수도 있는데, 이때는 Optional.empty()로 생성할 수 있음.
Optional<String> opt = Optional.empty();
System.out.println(opt); // Otpional.empty();
System.out.println(opt.isPresent()); // false✔ Optional 생성하기 - 값이 Null인 아닌 경우
만약 어떤 데이터가 절대 Null이 아니라면 Optional.of() 로 생성할 수 있음. 만약 Optional.of()로 Null을 저장하려고 하면 NullPointerException이 발생.
// Optional의 value는 절대 null이 아님
Optional<String> opt = Optional.of("name");✔ Optional.ofNullable() - 값이 Null일 수도, 아닐 수도 있는 경우
만약 어떤 데이터가 Null이 올 수도 있고, 아닐 수도 있는 경우 Optional.ofNullable로 생성할 수 있음. 그리고 이후에 orElse 또는 orElseGet 메소드를 이용해서 값이 없는 경우라도 안전하게 값을 가져올 수 있음.
//Optional의 value는 값이 있을 수도 있고, Null일 수도 있음
Optional<String> opt = Optional.ofNullable(getName());
String name = opt.orElse("anonymous"); // 값이 없다면 "anonymous" 리턴💡Optional 사용 예시 (1)
// 우편번호를 꺼낼 때의 null 검사 코드
// Optional을 사용 안했을 때
public String findPostCode() {
UserVO usr = getUser();
if(usr != null) {
Address address = user.getAddress();
if(address != null){
String postCode = address.getPostCode();
if(postCode != null) {
return postCode;
}
}
}
return "우편번호 없음";
}
// Optional을 사용했을 때
public String findPostCode() {
// 위의 코드는 다음과 같이 쓸 수 있다
Optional<UserVO> usr = Optional.ofNullable(getUser());
Optional<Address> address = usr.map(UserVO::getAddress);
Optional<String> postCode = address.map(Address::getPostCode);
String result = postCode.orElse("우편번호 없음");
// 위의 코드를 다음과 같이 축약해서 쓸 수 있다.
String result = usr.map(UserVO::getAddress)
.map(Address::getPostCode)
.orElse("우편번호 없음");
}💡Optional 사용 예시 (2)
// 이름을 대문자로 변경해주는 코드.
// Optional을 안쓰고, NPE 처리를 해주는 코드
String name = getName();
String result = "";
try{
result = name.toUpperCase();
} catch (NullPointerException e){
throw new CustomUpperCaseException();
}
// Optional을 사용한 코드
Optional<String> nameOpt = Optional.ofNullable(getName());
String result = nameOpt.orElseThrow(CustomUpperCaseException::new)
.toUpperCase(); 4. findAll() 메소드
- Spring Data JPA가 제공하는 메서드
- 모든 엔티티를 조회
- JpaRepository 인터페이스에 선언되어 있는 메서드
5. 소스를 이해하기 위한 기본 개념 링크
소스를 이해하기 위해서는 다음과 같은 개념은 기본으로 알고 있어야한다.
정리해놓은 내용을 링크로 걸어두었으니 한번 살펴보고 오자.
🌱 회원 리포지토리 메모리 구현체 만들기
package hello.hellospring.repository;
import hello.hellospring.domain.Member;
import java.util.*;
// 구현체 만들기
public class MemoryMemberRepository implements MemberRepository {
// 저장
// <id, 값>
private static Map<Long, Member> store = new HashMap<>();
private static long sequence = 0L; // 키값을 생성해주는 변수
@Override
public Member save(Member member) {
member.setId(++sequence); // 아이디 세팅
store.put(member.getId(), member); // store에 멤버 저장
return member;
}
@Override
public Optional<Member> findById(Long id) {
return Optional.ofNullable(store.get(id));
}
@Override
public Optional<Member> findByName(String name) {
return store.values().stream()
.filter(member -> member.getName().equals(name))
.findAny(); // 람다 사용. 루프로 돌림. 파라미터로 넘어온 name이랑 같으면 반환을 한다.
}
@Override
public List<Member> findAll() {
return new ArrayList<>(store.values());
}
}✅ 소스 설명
1.implements
public class MemoryMemberRepository implements MemberRepository{...}- 인터페이스 구현
- 부모 객체는 선언만 하며, 정의는 반드시 자식이 오버라이딩해서 사용
- "부모의 특징을 도구로 사용해 새로운 특징을 만들어 사용"하는 것
cf. extends
- 부모에서 선언/정의를 모두하며, 자식은 오버라이딩 할 필요 없이 부모의 메소드/변수를 그대로 사용
- "부모의 특징을 연장해서 사용"하는 것
2.@Override
@Override- 자식 클래스에 여러 개의 메서드가 정의되어 있을 경우, 해당 메소드가 부모 클래스에 있는 메서드를 Override 했다는 것을 명시적으로 선언하는 기능
- 이 어노테이션을 사용하지 않으면 자식 클래스에 있는 여러 개의 메서드 중 어떤 메서드가 Override 되었는지 파악하기 어려움
- 컴파일러에게 문법 체크를 하도록 알림
오버라이딩을 하기 위해서는 부모 클래스의 있는 메서드명과 매개변수를 동일하게 가져가야 함. 그런데 제대로 오버라이딩을 했다고 생각했는데, 매개변수를 잘못 지정했을 수도 있음. 이 때, @Override 어노테이션을 사용하면 해당 메서드는 Override 했다고 컴파일러에게 알려줄 수 있다.
3.HashMap
✔ HashMap의 정의
HashMap은 Map 인터페이스를 구현한 대표적인 Map 컬렉션이다. 키와 값으로 구성된 객체를 저장하는 구조이며, 값은 중복될 수 있지만, 키는 중복 저장이 불가하다. HashMap은 해싱(Hashing)을 사용하기 때문에 많은 양의 데이터를 검색하는 데 있어서 뛰어난 성능을 보인다.
✔ HashMap 선언 방법
Map<String, String> Map = new HashMap<>();그런데 왜 선언시 앞은 Map을 쓰고, 뒤에는 HashMap을 사용할까?
그 이유는 Map이 인터페이스이기 때문이다.
인터페이스는 선언만 가능하고, 객체 생성이 불가능하기 때문에 자식인 HashMap으로 객체를 생성하는 것이다.
리스트도 같은 이치라고 볼수 있다.
HashMap의 또 다른 선언 방법은 다음과 같다.
HashMap<String, String> Map = new HashMap<>();✔ HashMap 사용 방법
Map<String, Object> map = new HashMap<String, Object>();
// 데이터 저장
map.put("이름","sunny");
map.put("직업","개발자");
// 저장한 데이터 가져오기
map.keySet(); // key 출력: [이름, 직업]
map.values(); // value 출력: [sunny, 개발자]
map.toString(); // key,value 출력: {이름=sunny, 직업=개발자}
map.get("이름"); // 해당 키의 값을 출력 : sunny
// 데이터 삭제
map.remove("직업");
// 데이터 수정
map.replace("이름", "sun");- Stream
✔ Stream의 정의
스트림(Stream)은 자바 8부터 추가된 컬렉션(배열 포함)의 저장 요소를 하나씩 참조해서 람다식(함수적 스타일(functional style))으로 처리할 수 있도록 해주는 반복자이다.
✔ 스트림 파이프라인
대량의 데이터를 가공해서 축소하는 것을 일반적으로 리덕션(Reduction)이라고 하는데, 데이터의 합계, 평균값, 카운팅, 최대값, 최소값 등이 대표적인 리덕션의 결과물이라고 볼 수 있다. 그러나 컬렉션의 요소를 리덕션의 결과물로 바로 집계할 수 없을 경우에는 집계하기 좋도록 필터링, 매핑, 정렬, 그룹핑 등의 중간 처리가 필요하다.
✔ 스프림 파이프라인 - 중간 처리와 최종 처리
스트림은 데이터의 필터링, 매핑, 정렬, 그룹핑 등의 중간 처리와 합계, 평균, 카운팅, 최대값, 최소값 등의 최종 처리를 파이프라인(pipelines)으로 해결한다. 파이프라인은 여러 개의 스트림이 연결되어있는 구조를 말한다. 파이프라인에서 최종 처리를 제외하고는 모두 중간 처리 스트림이다.
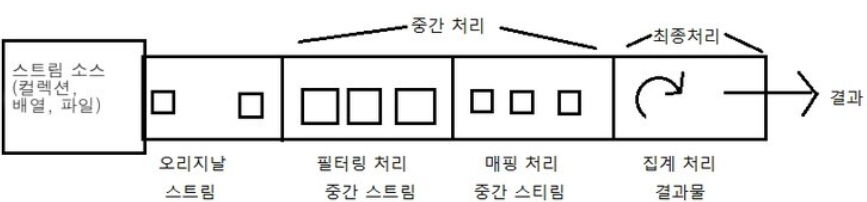
Stream 인터페이스에는 필터링, 매핑, 정렬 등의 많은 중간 처리 메소드가 있는데, 이 메소드들은 중간 처리된 스트림을 리턴한다. 그리고 이 스트림에서 다시 중간 처리 메소드를 호출해서 파이프라인을 형성하게 된다.
예를 들어 회원 컬렉션에서 남자만 필터링하는 중간 스트림을 연결하고, 다시 남자의 나이로 매핑하는 스트림을 연결한 후, 최종 남자 평균 나이를 집계한다면 다음 그림처럼 파이프라인이 형성된다.
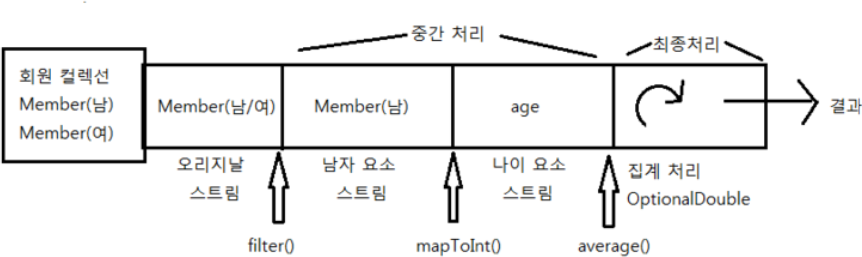
위의 파이프라인을 자바 코드로 표현하면 다음과 같다.
double ageAvg = list.stream() // 오리지날 스트림
.filter(m -> m.getSex() == Member.MALE) // 중간 처리 스트림
.mapToInt(Member:: getAge) // 중간 처리 스트림
.average() // 최종 처리
.getAsDouble();.filter(m -> m.getSex() == Member.MALE) 는 남자 Member를 요소로 하는 새로운 스트림을 생성. mapToInt(Member :: getAge())는 Member 객체를 age 값으로 매핑해서 age를 요소로 하는 새로운 스트림을 생성. average() 메소드는 age 요소들의 평균을 OptionalDouble에 저장. OptionalDouble에서 저장된 평균값을 읽으려면 getAsDouble() 메소드를 호출하면 된다.
@Override
public Optional<Member> findByName(String name) {
return store.values().stream() // 오리지널 스트림
.filter(member -> member.getName().equals(name))
.findAny(); // 람다 사용. 루프로 돌림. 파라미터로 넘어온 name이랑 같으면 반환을 한다.
}findAny()는 Stream에서 가장 먼저 탐색되는 요소를 리턴하고, 조건에 일치하는 요소 1개를 리턴하는 메소드이다.
[출처]
- public/private 개념 출처 : https://mozi.tistory.com/471
- Optional 개념 출처 : https://mangkyu.tistory.com/70, https://mangkyu.tistory.com/203
- @Override 개념 출처 : https://velog.io/@pearl0725/Override-%EC%96%B4%EB%85%B8%ED%85%8C%EC%9D%B4%EC%85%98%EC%9D%98-%EC%9D%98%EB%AF%B8%EC%99%80-%EC%82%AC%EC%9A%A9-%EC%9D%B4%EC%9C%A0%EB%8A%94-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C
