내가 보려고 만드는 자바 공부한 개념 통합본
jdk jre
- jre : java runtime environment. jvm이 자바 프로그램을 동작시킬 때 필요한 라이브러리 파일들과 기타 파일들을 가지고 있음.
- jdk : java development kit. 자바 개발 도구. jre + 개발에 필요한 도구 들을 포함한다.(java compiler 등)
인터프리터 언어 vs 컴파일 언어
- 인터프리터 언어: 런타임에 한 문장씩 실행
- 소스코드 분석하는것은 빠르지만 컴파일된 실행 파일이 만들어지는것이 아니라서 실행할때마다 새로 변환해야 한다
ex) python, javascript
- 소스코드 분석하는것은 빠르지만 컴파일된 실행 파일이 만들어지는것이 아니라서 실행할때마다 새로 변환해야 한다
- 컴파일 언어: 런타임 전에 전체 소스코드를 검사하여 실행 파일로 변환한다. 소스코드 분석하는것은 오래걸리지만 한번 실행하면 실행 파일이 만들어지기 때문에 이후에 실행할때는 효율적이다.
C vs java
프로그램이 실행되기 위해서 windows나 linux같은 운영체제(OS)가 메모리를 제어할 수 있어야 하는데, java 이전의 c같은 언어로 만들어진 프로그램은 이런 이유등으로 OS에 종속되어 실행되었다. java 프로그램은 JVM만 있으면 실행이 가능하며, JVM이 OS에게서 메모리 사용권한을 할당받고 JVM이 자바 프로그램을 호출하여 실행하게 된다.
- C
- 같은 소스라도 각 운영 체제에 맞는 컴파일러가 달라서 운영 체제마다 다른 실행 파일(.exe)이 만들어진다. 즉, os에 종속적인 실행 파일이 만들어진다
- java
- 소스 코드를 컴파일 하면 바이트 코드(.class)가 만들어지고, 이 바이트 코드는 자바 가상 머신(jvm) 위에서 실행되기 때문에 운영체제에 상관 없이 머신에 jvm만 깔려 있으면 실행할 수 있다. 즉, os에 종속적이지 않다.
JVM
자바 바이트 코드를 실행할 수 있는 주체로, 자바 코드를 컴파일해서 얻는 바이트 코드를 해당 운영체제가 이해할 수 있는 기계어로 바꿔 실행시킨다
- 구성: 크게 4가지(Class Loader, Execution Engine, Garbage Collector, Runtime Data Area)로 나뉜다.
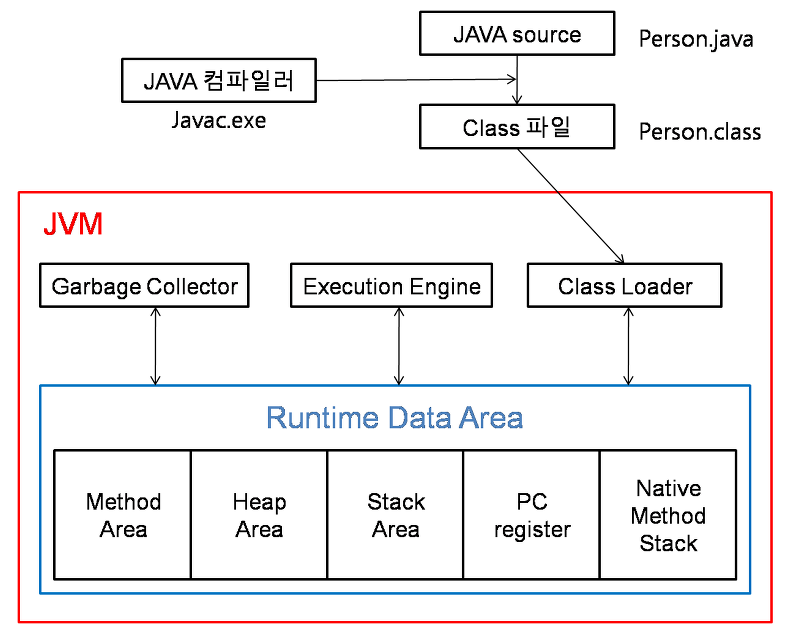
1. Class Loader
자바에서 소스를 작성하면 Person.java 처럼 .java파일이 생성된다.
.java 소스를 자바컴파일러가 컴파일하면 Person.class 같은 .class파일(바이트코드)이 생성된다. (컴퓨터가 이해할 수 있는 코드로 변환)
이렇게 생성된 클래스파일들을 엮어서 JVM이 운영체제로부터 할당받은 메모리영역인 Runtime Data Area로 적재하는 역할을 Class Loader가 한다. (자바 애플리케이션이 실행중일 때 이런 작업이 수행된다.)
2. Execution Engine
Class Loader에 의해 메모리에 적재된 바이트 코드들을 기계어로 변경해 명령어 단위로 실행하는 역할을 한다.
명령어를 하나 하나 실행하는 인터프리터(Interpreter)방식이 있고 JIT(Just-In-Time) 컴파일러를 이용하는 방식이 있다.
JIT 컴파일러는 적절한 시간에 전체 바이트 코드를 네이티브 코드로 변경해서 Execution Engine이 네이티브로 컴파일된 코드를 실행하는 것으로 성능을 높이는 방식이다.
(네이티브 코드: CPU와 OS가 직접 실행할 수 있는 코드. .exe, .dll ...)
3. Garbage Collector
Garbage Collector(GC)는 Heap 메모리 영역에 생성(적재)된 객체들 중에 참조되지 않는 객체들을 탐색 후 제거하는 역할을 한다.
또 다른 특징은 GC가 수행되는 동안 GC를 수행하는 쓰레드가 아닌 다른 모든 쓰레드가 일시정지된다.
특히 Full GC가 일어나서 수 초간 모든 쓰레드가 정지한다면 장애로 이어지는 치명적인 문제가 생길 수 있다.
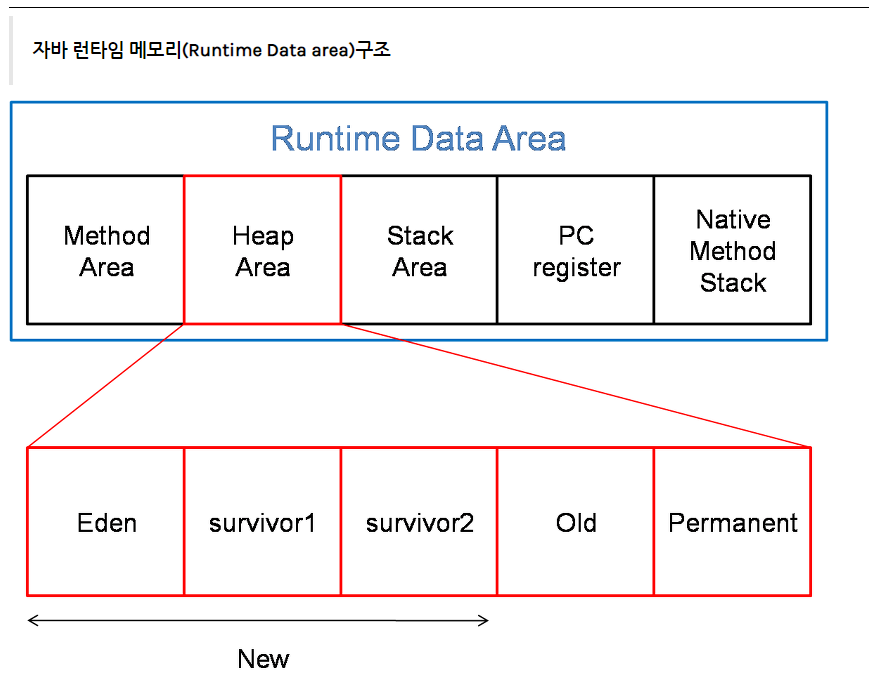
4. Runtime Data Area
JVM의 메모리 영역으로 JVM이 운영체제로부터 할당받은 메모리 공간이다. 자바 애플리케이션을 실행할 때 사용되는 데이터들을 적재하는 영역이다.
이 영역은 크게 Method Area, Heap Area, Stack Area, PC Register, Native Method Stack로 나눌 수 있다.
1. Method area (메소드 영역)
클래스 멤버 변수의 이름, 데이터 타입, 접근 제어자 정보같은 필드 정보와 메소드의 이름, 리턴 타입, 파라미터, 접근 제어자 정보같은 메소드 정보, Type정보(Interface인지 class인지), Constant Pool(상수 풀), 메소드에 대한 각종 정보, static 변수등이 생성되는 영역이다.
모든 스레드에서 정보가 공유된다.
2. Heap area (힙 영역)
new 키워드로 인스턴스가 생성되어 동적으로 메모리가 할당되는 영역이다. (또한 Array와 같은 동적으로 생성된 데이터가 저장되는 공간이다.)
메소드 영역에 로드된 클래스만 인스턴스로 생성이 가능하다. 스택 영역은 메서드 실행이 끝나면 자동으로 반환되지만, 힙 영역은 Garbage Collector가 참조되지 않는 메모리를 확인하고 제거한다.
모든 스레드에서 정보가 공유된다.
3. Stack area (스택 영역)
지역 변수, 매개 변수 등 연산에 사용되는 임시 값이 생성되는 영역이다. 메소드를 호출할 때마다 개별적으로 스택이 생성되고, 메서드 실행이 끝나면 자동으로 반환되는 메모리이다.
int a = 10; 이라는 소스를 작성했다면 정수값이 할당될 수 있는 메모리공간을 a라고 잡아두고 그 메모리 영역에 값이 10이 들어간다. 즉, 스택에 메모리에 이름이 a라고 붙여주고 값이 10인 메모리 공간을 만든다.
클래스 Person p = new Person(); 이라는 소스를 작성했다면 Person p는 스택 영역에 생성되고 new로 생성된 Person 클래스의 인스턴스는 힙 영역에 생성된다. 즉, 객체가 선언되면 이 객체는 스택 영역에 생성되고, 그 객체가 가지고 있는 내용들(attribute)은 힙 영역에 생성된다.
그리고 스택영역에 생성된 p의 값으로 힙 영역의 주소값을 가지고 있다. 즉, 스택 영역에 생성된 p가 힙 영역에 생성된 객체를 가리키고(참조하고) 있는 것이다.
이때, 같은 클래스의 다른 객체들이 여러개 생성되면 각각의 내용들이 독립적으로 힙 영역에 쌓인다.
스레드마다 하나씩 존재한다.
4. PC Register (PC 레지스터)
스레드가 생성되면서 생기는 공간. 각 스레드별로 PC Register가 존재하며 JVM 머신이 가장 최근에 실행한 명령어의 주소와 명령을 저장한다. 이것을 이용해서 쓰레드를 돌아가면서 수행할 수 있게 한다.
JVM이 실행하고 있는 현재 위치를 저장하는 역할
5. Native method stack
자바 외 언어로 작성된 네이티브 코드를 위한 메모리 영역이다.
보통 C/C++등의 코드를 수행하기 위한 스택이다. (JNI)
쓰레드가 생성되었을 때 기준으로
1,2번인 메소드 영역과 힙 영역을 모든 쓰레드가 공유하고,
3,4,5번인 스택 영역과 PC 레지스터, Native method stack은 각각의 쓰레드마다 생성되고 공유되지 않는다.
GC(Garbage Collection)
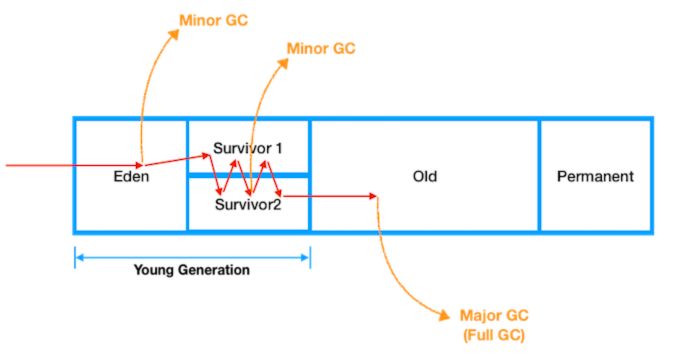
JVM에서는 GC의 스케줄링을 담당하여 자바 개발자에게 메모리 관리의 부담을 덜어준다. GC는 더 이상 사용되지 않는 객체들을 메모리에서 제거하여 효율적인 메모리 사용을 돕는다.
객체는 힙 영역에 저장되고 스택 영역에 이를 가르키는 주소값이 저장되는데 Garbage Collector는 참조되지 않는 객체를 메모리에서 제거한다.
JVM의 Heap 영역은 객체의 생존 기간에 따라 물리적인 Heap 영역을 Young, Old 두 영역으로 나누어 설계되었다.
Minor GC : Young 영역에서 일어나는 GC
- 최초에 객체가 생성되면 Eden영역에 생성된다.
- Eden영역에 객체가 가득차게 되면 첫 번째 CG가 일어난다.
- survivor1 영역에 Eden영역의 메모리를 그대로 복사된다. 그리고 survivor1 영역을 제외한 다른 영역의 객체를 제거한다.
- Eden영역도 가득차고 survivor1영역도 가득차게된다면, Eden영역에 생성된 객체와 survivor1영역에 생성된 객체 중에 참조되고 있는 객체가 있는지 검사한다.
- 참조 되고있지 않은 객체는 내버려두고 참조되고 있는 객체만 survivor2영역에 복사한다.
- survivor2영역을 제외한 다른 영역의 객체들을 제거한다.
- 위의 과정중에 일정 횟수이상 참조되고 있는 객체들을 survivor2에서 Old영역으로 이동시킨다.
- 위 과정을 계속 반복, survivor2영역까지 꽉차기 전에 계속해서 Old로 비움
Major GC(Full GC) : Old 영역에서 일어나는 GC
Old 영역의 메모리가 부족해지면 발생.
- Old 영역에 있는 모든 객체들을 검사하며 참조되고 있는지 확인한다.
- 참조되지 않은 객체들을 모아 한 번에 제거한다.
- Minor GC보다 시간이 훨씬 많이 걸리고 실행중에 GC를 제외한 모든 쓰레드가 중지한다.
GC의 물리적 공간(Heap 영역)
힙 영역은 우선 5개의 영역(eden, survivor1, survivor2, old, permanent)으로 나뉜다.
-
Young 영역(Young generation)
- 새롭게 생성된 객체가 할당되는 영역. 대부분의 객체가 금방 접근 불가능한 상태(Unreachable)가 되기 때문에, 많은 객체가 Young 영역에 생성되었다가 사라진다.
- Eden
- 새로 생성된 객체들이 위치
- Minor GC 발생
- Survivor 1,2
- Eden 영역에서 GC 실행 후 살아남은 객체들이 위치
- Minor GC 발생
-
Old 영역(Old generation)
- Survivor 영역에서 여러번의 GC 후 살아남은 객체가 복사되는 영역
- Young 영역보다 크게 할당되며, 영역의 크기가 큰 만큼 가비지는 적게 발생한다.
- Major GC 발생
Garbage Collection의 동작 방식
Young 영역과 Old 영역은 서로 다른 메모리 구조로 되어 있기 때문에, 세부적인 동작 방식은 다르다. 하지만 기본적으로 가비지 컬렉션이 실행된다고 하면 다음의 2가지 공통적인 단계를 따르게 된다.
- Stop The World
- Mark and Sweep
STW(Stop-The-World)
GC 처리하는 동안 GC를 실행하는 쓰레드를 제외한 모든 쓰레드들의 작업이 중단되는 현상이다.
Major GC(Full GC)가 일어나면, Old영역에 있는 참조가 없는 객체들을 표시하고 그 해당 객체들을 모두 제거하게 된다.
그러면서 Heap 메모리 영역에 중간중간 구멍(제거되고 빈 메모리 공간)이 생기는데 이 부분을 없애기 위해 재구성을 하게 된다. (디스크 조각모음처럼 조각난 메모리를 정리함)
따라서 메모리를 옮기고 있는데 다른 쓰레드가 메모리를 사용해버리면 안되기 때문에 모든 쓰레드가 정지하게 되는 것이다.
Old 영역이 가득 차면 major GC 가 동작하는데 이때 STW 상태가 되므로 이를 최소화 하는 것이 중요하다.
Mark and Sweep
- Mark: 사용되는 메모리와 사용되지 않는 메모리를 식별하는 작업
- Sweep: Mark 단계에서 사용되지 않음으로 식별된 메모리를 해제하는 작업
Stop The World를 통해 모든 작업을 중단시키면, GC는 스택의 모든 변수 또는 Reachable 객체를 스캔하면서 각각이 어떤 객체를 참고하고 있는지를 탐색하게 된다. 그리고 사용되고 있는 메모리를 식별하는데, 이러한 과정을 Mark라고 한다. 이후에 Mark가 되지 않은 객체들을 메모리에서 제거하는데, 이러한 과정을 Sweep라고 한다.
GC 처리 방식
- Serial GC
- Mark-sweep-compact 알고리즘
- 적은 메모리와 CPU 코어 갯수가 적을때 적합하다.
- Paraller GC
- Serial GC와 알고리즘은 같지만 GC를 처리하는 Thread가 여러개이다
- 메모리와 코어가 충분할 때 적합하다.
- Paraller Old GC
- Paraller GC에서 Old GC 알고리즘을 개선한 버전이다.
-> JDK7까지는 permanent영역이 heap에 존재했습니다. JDK8부터는 permanent 영역은 사라지고 일부가 "meta space 영역"으로 변경되었습니다.(위의 그림 JDK7 기준입니다.) meta space 영역은 Native stack 영역에 포함되었습니다.
(survivor영역의 숫자는 의미없고 두 개로 나뉜다는 것이 중요하다)
힙 영역을 굳이 5개로 나눈 이유는 효율적으로 GC가 일어나게 하기 위함이다. 자세한 것은 GC가 일어나는 프로세스를 보면서 설명한다.
GC 알고리즘
- mark -> sweep -> compaction 작업이 순서대로 동작
- mark: GC 대상을 고름
- sweep: GC 대상 제거
- compaction: 제거되고 빈 공간 없애기 위해 재구성
- Serial GC
- Mark-sweep-compact 알고리즘
- 위 세가지 작업이 진행되는 간단한 GC 알고리즘. 쓰레드 1개가 GC 수행
- 적은 메모리와 CPU 코어 갯수가 적을때 적합하다.
- Paraller GC
- Serial GC와 알고리즘은 같지만 여러개의 Thread가 Minor GC를 수행한다.
- 메모리와 코어가 충분할 때 적합하다.
- Paraller Old GC
- Paraller GC에서 Old GC 알고리즘을 개선한 버전이다.
출처
https://jeong-pro.tistory.com/148
https://12bme.tistory.com/142
GC 동작원리
변수와 자료형
2진수: 앞에 0B 붙여서 사용한다.
8진수: 앞에 0 붙여서 사용한다. 이진수 3bit를 한번에 표현 가능함(0B111 = 07)
16진수: 앞에 0X 붙여서 사용한다. 이진수 4bit를 한번에 표현 가능함(0B1111 = 0XF)
int num = 10;
int bNum = 0B1010; // 10
int oNum = 012; // 10
int hNum = 0XA; // 10변수: 프로그램에서 사용되는 자료를 저장하기 위해 할당 받은 메모리의 주소 대신 부르는 이름. 자바에서는 보통 camelCase를 사용한다.
리터럴
프로그램에서 직접 표현한 값으로, 숫자(정수, 실수), 문자, 논리, 문자열 리터럴이 있다. (ex. 10, 3.14, 'A', true)
- 리터럴에 해당되는 값들은 특정 메모리 공간인 상수 풀(constant pool)에 저장되어 있다.
- 이때 기본적으로 정수는 int(4byte), 실수는 double로 저장되어 있다. 따라서 long이나 float값으로 저장하는 경우 식별자(L, l, F, f)를 명시해야 한다.
int num = 10; //여기서 10은 상수 풀에 저장되어 있는 숫자(리터럴)
long num = 1234567890L; //32비트를 초과하는 숫자를 사용하려면 long으로 처리하도록 뒤에 식별자를 써서 명시해줘야 한다.상수
변하지 않는 값. C에서는 const, 자바에서는 final 키워드를 사용해 선언한다.
final int MAX_NUM = 100;
final float PI = 3.14f;
PI = 3.15f; //오류남문자 세트
문자를 위한 코드 값(숫자 값) 들을 정해 놓은 세트
- 아스키(ASCII): 1바이트로 영문자, 숫자, 특수 문자 등을 표현
- 유니코드(Unicode): 한글과 같은 복잡한 언어들은 EUC-KR과 같이 인코딩 방법이 따로 있다. 하지만 이러한 다국어를 모두 표현하기 위해 정한 표준이 유니코드이다. 유니코드에도 여러가지 종류가 있는데, 그 중에서 대표적 표준 인코딩은 UTF-8, UTF-16 등이 있다. 자바는 유니코드 UTF-16인코딩을 사용한다. (유니코드는 기본적으로 아스키 코드도 포함한다.)
자료형 없이 변수 사용하기
지역 변수 자료형 추론(local variable type inference):
-
변수에 대입되는 값을 보고 컴파일러가 자료형을 추론한다. (자바 10부터 제공하는 기능)
-
지역 변수에만 사용할 수 있다.
-
한번 타입이 정해지면 중간에 바꿀 수 없다.
var num = 10; //컴파일러가 정수로 추론해서 int로 저장된다.
num = 3.14; //이미 int로 저장되었기 때문에 실수로 저장하는 것은 불가능함클래스와 객체
- 하나의 java 파일에 하나의 클래스를 두는 것이 원칙이나, 여러 개의 클래스가 같이 있는 경우 public 클래스는 단 하나이며, public 클래스와 자바 파일의 이름은 동일해야한다.
naming convention
- 클래스 이름은 대문자로 시작(PascalCase)
- package 이름은 다 소문자
- 멤버변수, 메서드는 camelCase
메모리
Stack Memory: 함수가 호출될 때 사용하는 메모리로, 함수에서 사용하는 지역 변수, 파라미터 등 연산에 사용되는 임시 값이 생성되는 영역이다. 함수의 기능 수행이 끝나면 자동으로 반환되는 메모리이다.
클래스, 객체, 인스턴스
-
클래스(Class)
- 객체를 만들어 내기 위한 설계도 혹은 틀
-
객체(Object)
- 실세계에서 인식할 수 있는 모든 것들을 객체라고 할 수 있다.
- ‘클래스의 인스턴스(instance)’ 라고도 부른다.
- 객체는 모든 인스턴스를 포함하는 포괄적인 의미를 갖는다.
- oop의 관점에서 클래스의 타입으로 선언되었을 때 ‘객체’라고 부른다.
-
인스턴스(Instance)
-
클래스를 객체로 만들어서 메모리에 할당한 것.
-
인스턴스는 객체에 포함된다고 볼 수 있다.
-
oop의 관점에서 객체가 메모리에 할당되어 실제 사용될 때 ‘인스턴스’라고 부른다.
/* 클래스 */ public class Animal { ... } /* 객체와 인스턴스 */ public class Main { public static void main(String[] args) { Animal cat, dog; // 아직 메모리 할당은 안받았으니 그냥 '객체' // 인스턴스화 cat = new Animal(); // cat은 Animal 클래스의 '인스턴스'(객체를 메모리에 할당) dog = new Animal(); // dog은 Animal 클래스의 '인스턴스'(객체를 메모리에 할당) } }
-
-
Q. 클래스 VS 객체
- 클래스는 ‘설계도’, 객체는 ‘설계도로 구현한 모든 대상’을 의미한다.
-
Q. 객체 VS 인스턴스
- 클래스의 타입으로 선언되었을 때 객체라고 부르고, 그 객체가 메모리에 할당되어 실제 사용될 때 인스턴스라고 부른다.
- 클래스를 바탕으로 메모리에 할당해 실제 사용할 때 인스턴스라 하고, 이 클래스의 인스턴스는 모두 객체라고 할 수 있다.
-
추상화 기법
- 분류(Classification)
- 객체 -> 클래스
- 실재하는 객체들을 공통적인 속성을 공유하는 범부 또는 추상적인 개념으로 묶는 것
- 인스턴스화(Instantiation)
- 클래스 -> 인스턴스
- 분류의 반대 개념. 범주나 개념으로부터 실재하는 객체를 만드는 과정
- 구체적으로 클래스 내의 객체에 대해 특정한 변형을 정의하고, 이름을 붙인 다음, 그것을 물리적인 어떤 장소에 위치시키는 등의 작업을 통해 인스턴스를 만드는 것을 말한다.
- ‘예시(Exemplification)’라고도 부른다.
- 분류(Classification)
자바의 자료형
- 기본 타입(primitive type): 원래 언어에서 기본적으로 제공되는 자료형
- char, int, float, double, boolean
- 참조 타입(reference type)
- class, interface 등
- 참조 타입으로 선언된 변수가 참조 변수
- 참조 값은 힙 메모리에 생성된 인스턴스의 메모리 주소 값
- Wrapper class: 기본 자료타입을 객체로 다루기 위해서 사용하는 클래스들이다. 기본 타입의 값을 내부에 두고 포장한다. 래퍼 클래스로 감싸고 있는 기본 타입 값은 외부에서 변경 불가능하고, 만약 값을 변경하고 싶다면 새로운 포장 객체를 만들어야 한다.
- ex) int -> Integer, char -> Character
자바의 접근 제어자의 종류와 특징
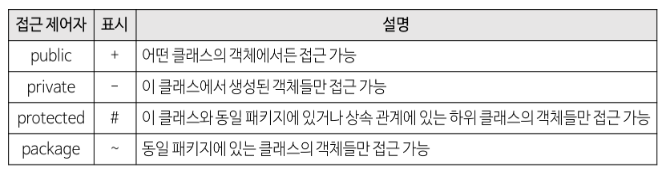
- default: 해당 패키지에 있는 클래스의 객체들만 접근 가능
this
- 자기 자신의 생성된 인스턴스의 메모리를 가리킴(자신의 인스턴스의 힙메모리 주소를 카리킴)
- 생성자에서 다른 생성자를 호출
public Person() {
this("이름없음",1);
// default constructor가 호출되면 name = "이름없음", age = 1 으로 설정
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// this를 이용해 다른 생성자를 호출할 때는 그 이전에 어떠한 statement도 사용할 수 없다
// 위와 같이 생성자가 여러 개이고 파라미터만 다른 경우 constructor overloading이라고 한다.non-static 멤버와 static 멤버 의 차이
-
non-static 멤버
- 공간적 특성: 객체마다 별도로 메모리 공간을 갖는다.
- 인스턴스 멤버 라고 부른다.
- 시간적 특성: 객체 생성 시에 멤버가 생성된다.
- 객체가 생길 때 멤버도 생성된다.
- 객체 생성 후 멤버 사용이 가능하다.
- 객체가 사라지면 멤버도 사라진다.
- 공유의 특성: 공유되지 않는다.
- 멤버는 객체 내에 각각의 공간을 유지한다.
- 공간적 특성: 객체마다 별도로 메모리 공간을 갖는다.
-
static 멤버
여러 개의 인스턴스가 같은 메모리의 값을 공유하기 위해 사용
-
공간적 특성: 멤버는 클래스당 하나가 생성된다.
- 멤버는 힙메모리의 인스턴스 내부가 아닌 데이터 영역에 별도로 생성된다.
- 클래스 멤버 라고 부른다.
-
시간적 특성: 클래스 로딩 시(프로그램이 메모리에 로드될 때)에 멤버가 생성된다.
- 객체가 생기기 전에 이미 생성된다.
- 객체가 생기기 전에도 사용이 가능하다. (즉, 객체를 생성하지 않고도 사용할 수 있다.)
- 객체가 사라져도 멤버는 사라지지 않는다.
- 멤버는 프로그램이 종료될 때 사라진다.
-
공유의 특성: 동일한 클래스의 모든 객체들에 의해 공유된다.
-
static 메소드에서는 인스턴스 변수를 쓸 수 없음

-
https://gmlwjd9405.github.io/2018/08/04/java-static.html
singleton 패턴
어떤 클래스에 대해 프로그램에서 단 하나의 인스턴스만 생성해야 할 때 사용하는 패턴이다.
// Company 인스턴스가 단 하나여야 하는 경우
public class Company {
// 유일하게 생성되는 인스턴스
private static Company instance = new Company();
private Company() { }
public static Company getInstance(){
if(instance == null)
instance = new Company();
return instance;
}
}- 생성자를 private으로 선언해서 외부에서 추가로 인스턴스 생성을 할 수 없도록 한다.
- 프로그램에서 사용될 단 하나의 인스턴스를 클래스 내부에 static 변수로 생성한다.
- public static 메서드로 getInstance() 를 만들고 이 메소드가 최초로 호출되는 시점에서 한번만 객체가 만들어지게 한다. 생성된 객체는 static 변수에 저장된다. 외부에서는 이 메서드를 통해 인스턴스에 접근하도록 한다.
배열
자바에서 배열은 new 생성자를 사용해 선언한다.
Book[] library = new Book[5];
int[][] arr = new int[2][3];
// length = 3 짜리 배열 초기화
int[] numbers = new int[] {0,1,2};
int[] numbers = new int[3] {0,1,2}; //오류남
int[] numbers = {0,1,2};배열 복사
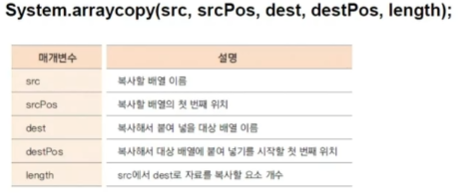
System.arraycopy(library, 0, librarycopy, 0, 5)- 얕은 복사: 주소만 복사되는 것이어서 배열 요소가 변경되면 복사된 배열의 값도 변경 된다. 이 문제를 해결하기 위해서는 값 자체를 복사하는 깊은 복사를 사용해야 한다.
배열을 이용한 for문
for(String lang:strArray){
System.out.println(lang);
}ArrayList
기존 배열은 길이를 정하여 선언해야 하고, 중간에 요소를 삭제하거나 삽입하는 것도 어려워서 자바에서는 ArrayList 클래스를 제공한다. 여러 메서드와 속성을 사용해 객체 배열을 편리하게 관리 할 수 있다.
ArrayList<String> list = new ArrayList<String>();
list.add("A");
list.get(0); // A 반환. list[0]은 안됨상속
- 하위 클래스가 생성될 때 상위 클래스가 먼저 생성 된다.
- 하위 클래스에서 명시적으로 상위 클래스를 호출하지 않으면 컴파일러는 super()를 코드에 넣어 준다.
- super(): 상위 클래스에 대한 주소값을 가진다.
- 만약 상위 클래스의 기본 생성자가 없는 경우(매개변수가 있는 생성자만 존재 하는 경우) 하위 클래스는 명시적으로 상위 클래스 생성자를 호출해야 한다.
오버로딩과 오버라이딩(Overloading vs Overriding)
- 오버로딩(Overloading)
- 두 메서드가 같은 이름을 갖고 있으나 인자의 수나 자료형이 다른 경우
- Ex)
- public double computeArea(Circle c) { ... }
- public double computeArea(Circle c1, Circle c2) { ... }
- public double computeArea(Square c) { ... }
- 오버라이딩(Overriding)
- 상위 클래스의 메서드 중 이름과 매개변수가 같은 함수를 하위 클래스에 재정의하는 것
- Ex) VIPCustomer에서 calcPrice() 메서드를 재정의한다.
형변환
-
상위 클래스로의 형 변환(Upcasting)
- 하위 클래스는 상위 클래스의 타입을 내포하고 있으므로 묵시적 형 변환이 가능하다.
- 상위 클래스 형으로 변수를 선언하고 하위 클래스 인스턴스를 생성할 수 있음
Parent parent = new Child();- 여기서 parent는 Parent 형이므로 Parent의 변수와 메서드만 접근할 수 있고, Child의 변수와 메서드는 접근할 수 없다.
-
하위 클래스로의 형 변환(Downcasting)
- Upcasting과 달리 명시적으로 해야한다.
- instanceof 키워드를 사용해 원래 인스턴스의 타입을 체크할 수 있다.
((Child)parent).childMethod(); if(parent instanceof Child){ // parent가 Child 인스턴스인지 확인할 수 있음 }
가상 메서드
Customer vc = new VIPCustomer();
// Customer이 상위 클래스, VIPCustomer이 하위 클래스
vc.calcPrice();
// 하위 클래스에서 오버라이딩된 메서드의 경우 객체 타입의 메서드가 아닌 인스턴스인 VIPCustomer 클래스의 calcPrice() 메서드가 호출된다.가상 메서드(virtual method): 타입과 상관 없이 실제 생성된 인스턴스의 메서드가 호출된다. C++에서는 virtual 키워드를 명시해줘야 하지만 자바는 모든 메서드가 가상 메서드임.
추상클래스와 인터페이스
추상 메서드(Abstract Method)
abstract 키워드와 함께 원형만 선언되고, 코드는 작성되지 않은 메서드
public abstract String getName(); // 추상 메서드
public abstract String fail() { return "Fail"; } // 추상 메서드 아님. 컴파일 오류 발생추상클래스(Abstract Class)
-
추상 클래스는 new(인스턴스화) 할 수 없음
-
개념: abstract 키워드로 선언된 클래스
a. 추상 메서드를 최소 한 개 이상 가지고 abstract로 선언된 클래스
최소 한 개의 추상 메서드를 포함하는 경우 반드시 추상 클래스로 선언하여야 한다.
b. 추상 메서드가 없어도 abstract로 선언한 클래스추상 메서드가 하나도 없는 경우라도 추상 클래스로 선언할 수 있다. -
추상 클래스의 구현
- 서브 클래스에서 슈퍼 클래스의 모든 추상 메서드를 오버라이딩하여 실행가능한 코드로 구현한다.
- 여기서 상속은 구현 상속이라고 한다.(extends 키워드 사용한 상속)
-
추상 클래스의 목적
-
객체(인스턴스)를 생성하기 위함이 아니며, 상속을 위한 부모 클래스로 활용하기 위한 것이다.
-
여러 클래스들의 공통된 부분을 추상화(추상 메서드) 하여 상속받는 클래스에게 구현을 강제화하기 위한 것이다. (메서드의 동작을 구현하는 자식 클래스로 책임을 위임)
-
즉, 추상 클래스의 추상 메서드를 자식 클래스가 구체화하여 그 기능을 확장하는 데 목적이 있다.
/* 개념 a의 예시 */ abstract class Shape { // 추상 클래스 Shape() {...} void edit() {...} abstract public void draw(); // 추상 메서드 }/* 개념 b의 예시 */ abstract class Shape { // 추상 클래스 Shape() {...} void edit() {...} }/* 추상 클래스의 구현 */ class Circle extends Shape { public void draw() { System.out.println("Circle"); } // 추상 메서드 (오버라이딩) void show() { System.out.println("동그라미 모양"); } }두시반
-
인터페이스(interface)
-
개념: 추상 메서드와 상수만을 포함하며, interface 키워드를 사용하여 선언한다.
-
인터페이스의 구현
- 인터페이스를 상속받고, 추상 메서드를 모두 구현한 클래스를 작성한다.
- 인터페이스를 상속받은 클래스가 모든 추상 메서드를 구현하지 않으면, 해당 클래스는 추상 클래스가 된다.
- implements 키워드를 사용하여 구현한다.(이를 타입 상속이라고 함)
-
인터페이스의 목적
- 상속받을 서브 클래스에게 구현할 메서드들의 원형을 모두 알려주어, 클래스가 자신의 목적에 맞게 메서드를 구현하도록 하는 것이다.
- 구현 객체의 같은 동작을 보장하기 위한 목적이 있다.
- 즉, 서로 관련이 없는 클래스에서 공통적으로 사용하는 방식이 필요하지만 기능을 각각 구현할 필요가 있는 경우에 사용한다.
- 설계용으로 사용. 어떤 클래스들에 대해 어떤 메서드를 구현해야 하는지 정의해야 할 때 사용한다.
-
인터페이스의 특징
-
인터페이스는 상수 필드와 추상 메서드만으로 구성된다.
-
모든 메서드는 추상 메서드로서, abstract public 속성이며 생략 가능하다.
-
상수는 public static final 속성이며, 생략하여 선언할 수 있다.
-
인터페이스를 상속받아 새로운 인터페이스를 만들 수 있다.(다중 상속 가능)
interface MobilePhone extends Phone { }/* 인터페이스의 개념 */ interface Phone { // 인터페이스 int BUTTONS = 20; // 상수 필드 (public static final int BUTTONS = 20;과 동일) void sendCall(); // 추상 메서드 (public abstract void sendCall();과 동일) abstract public void receiveCall(); // 추상 메서드 }/* 인터페이스의 구현 */ class FeaturePhone implements Phone { // Phone의 모든 추상 메서드를 구현한다. public void sendCall() {...} public void receiveCall() {...} // 추가적으로 다른 메서드를 작성할 수 있다. public int getButtons() {...} }
-
-
Client는 어떻게 구현되었는지 상관없이 interface 정의만을 보고 사용할 수 있다.
- ex: JDBC(Java DataBase Connectivity)
- 자바와 디비를 연결하기 위한 명세(interface)이다. 이에 대한 구현은 Oracle, mySql 등에서 하는데, Client Code에서는 이 구현을 모두 볼 필요 없이 JDBC에 있는 명세만 보고 코드 작성을 할 수 있다.
- ex: JDBC(Java DataBase Connectivity)
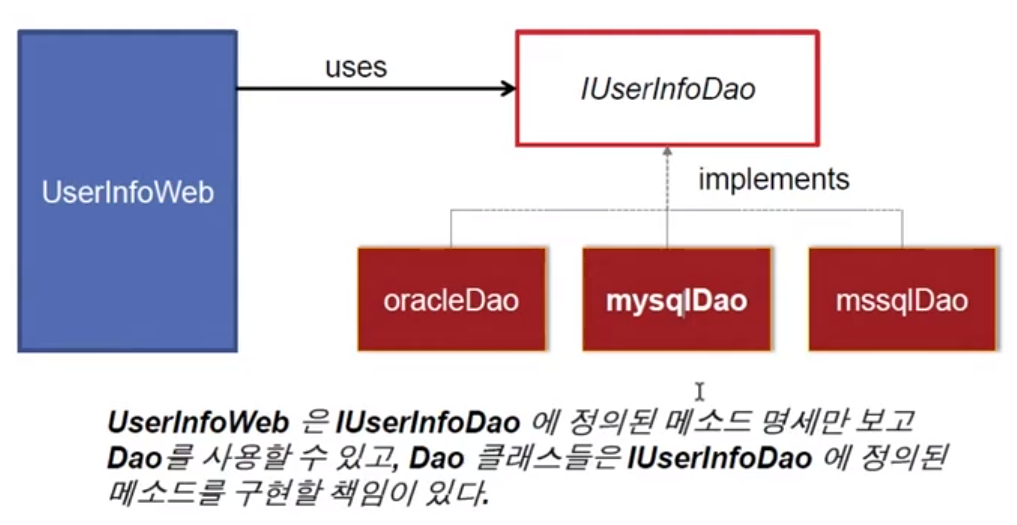
- 자바8부터 추가된 인터페이스 요소
- 디폴트 메서드: 기본 구현을 가지는 메서드
- 정적 메서드(static method)
- private method: 인터페이스를 구현한 클래스에서 사용하거나 재정의 할 수 없고, 인터페이스 내부에서만 기능을 제공하기 위해 구현하는 메서드
인터페이스와 추상 클래스의 차이(Interface vs Abstract Class)
-
추상 클래스와 인터페이스의 공통점
- 인스턴스(객체)는 생성할 수 없다.
- 선언만 있고 구현 내용이 없다.
- 자식 클래스가 추상 메서드의 구체적인 동작을 구현하도록 책임을 위임한다.
-
추상 클래스와 인터페이스의 차이점
-
서로 다른 목적을 가지고 있다.
-
추상 클래스는 추상 메서드를 자식 클래스가 구체화하여 그 기능을 확장하는 데 목적이 있다. (상속을 위한 부모 클래스)
-
인터페이스는 서로 관련이 없는 클래스에서 공통적으로 사용하는 방식이 필요하지만 기능을 각각 구현할 필요가 있는 경우에 사용한다. (구현 객체의 같은 동작을 보장)
-
-
-
추상 클래스는 클래스이지만 인터페이스는 클래스가 아니다.
- 추상 클래스는 단일 상속이지만 인터페이스는 다중 상속이 가능하다.
public class CompleteClass implements Interface1, Interface2-
추상 클래스는 “is a kind of” 인터페이스는 “can do this”
- Ex) 추상 클래스: Appliances(Abstract Class) - TV, Refrigerator
- Ex) 인터페이스: Flyable(Interface) - Plane, Bird
템플릿 메서드
- 추상 클래스를 이용해서 구현할 수 있는 디자인 패턴 종류 중 하나로, 프레임 워크에서 많이 사용되는 설계 패턴이다. 어떤 작업을 처리하는 일부분을 서브 클래스로 캡슐화해 전체 일을 수행하는 구조는 바꾸지 않으면서 특정 단계에서 수행하는 내역을 바꾸는 패턴이다.
- 추상 메서드와 구현된 메서드를 활용하여 전체 기능의 흐름(시나리오)을 정의하는 메서드로, final 키워드를 사용해 템플릿 메서드를 정의한다.
- 추상 클래스로 선언된 상위 클래스에 템플릿 메서드를 활용하여 전체적인 흐름을 정의하고 하위 클래스에서 다르게 구현되어야 하는 부분은 추상 메서드로 선언해서 하위 클래스가 구현하도록 한다.
public final void run(){
start();
going();
stop();
}
// 세부적인 메서드에 대한 구현은 하위 클래스에서 하도록 하되, 이 시나리오는 변할 수 없게 함- Hook 메서드: 추상 클래스에 선언되는 추상 메서드가 아닌 일반 메서드로, 기본적인 내용만 구현되어 있거나 아무 코드도 들어 있지 않은 메서드이다. 상황에 맞게 재정의하거나 안해도 되는 메서드이다.
java의 final 키워드 (final/finally/finalize)
- final 키워드
- 개념: 변수나 메서드 또는 클래스가 ‘변경 불가능’하도록 만든다.
- 원시(Primitive) 변수에 적용 시
- 해당 변수의 값은 변경이 불가능하다.
- 참조(Reference) 변수에 적용 시
- 조 변수가 힙(heap) 내의 다른 객체를 가리키도록 변경할 수 없다.
- 메서드에 적용 시
- 해당 메서드를 오버라이드할 수 없다.
- 클래스에 적용 시
- 해당 클래스의 하위 클래스를 정의할 수 없다.
- finally 키워드
- 개념: try/catch 블록이 종료될 때 항상 실행될 코드 블록을 정의하기 위해 사용한다.
- finally는 선택적으로 try 혹은 catch 블록 뒤에 정의할 때 사용한다.
- finally 블록은 예외가 발생하더라도 항상 실행된다.
- 단, JVM이 try 블록 실행 중에 종료되는 경우는 제외한다.
- finally 블록은 종종 뒷마무리 코드를 작성하는 데 사용된다.
- finally 블록은 try와 catch 블록 다음과, 통제권이 이전으로 다시 돌아가기 전 사이에 실행된다.
- finalize() 메서드
- 개념: GC(Garbage Collector)가 더 이상의 참조가 존재하지 않는 객체를 메모리에서 삭제하겠다고 결정하는 순간 호출된다.
- Object 클래스의 finalize() 메서드를 오버라이드해서 맞춤별 GC를 정의할 수 있다.

https://gmlwjd9405.github.io/2018/08/06/java-final.html
Object 클래스 메서드
java에서 ‘==’와 ‘Equals()’의 차이
- equals
- 객체끼리 값을 비교할 수 있는 '메소드'
- Object 클래스에 정의된 원형은 "=="와 같기 때문에 custom class에 대해서는 재정의 해줘야한다.
- String, Integer 등의 클래스에는 이미 재정의 되어있음
- ==
- 객체의 주소값을 비교하는 '연산자'
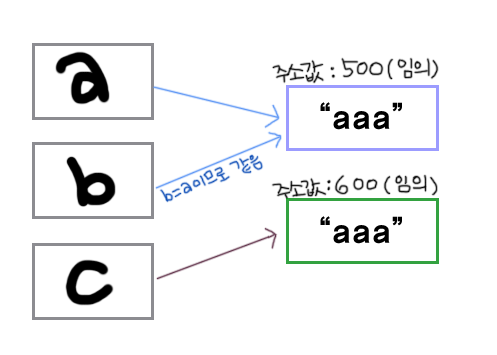
-
a==b -> true
-
a.equlas(b) -> true
-
a==c -> false
-
a.equals(c) -> true
hashCode()
인스턴스의 힙메모리 저장 주소를 반환하는 메서드이다. (힙메모리에 인스턴스가 저장되는 방식이 hash)
-
hash: 정보를 저장, 검색하기 위해 사용하는 자료구조로, 자료의 특정 값(키 값)에 대해 저장 위치를 반환해주는 해시 함수를 사용한다.
index = hash(key) // index는 저장위치 -
String, Integer 등의 클래스에서는 서로 다른 메모리의 두 인스턴스의 값이 동일하면 hashCode() 값도 동일하게 반환된다.(실제 힙메모리 주소는 다름)
- 논리적으로 동일함을 위해 equals() 메서드를 재정의 하였다면 hashCode() 메서드도 재정의 하여 동일한 값이 반환 되도록 했기 때문
String
String을 선언할 때 힙메모리에 인스턴스로 생성되는 경우와 상수 풀(constant pool)에 있는 주소를 참조하는 방법 두 가지가 있다. 이때 상수 풀의 문자열을 참조하면 모든 문자열이 같은 주소를 가리킨다.
String str1 = new String("abc"); //생성자의 매개변수로 문자열 생성
String str2 = "test"; //문자열 상수를 가리키는 방식String, StringBuilder, StringBuffer
-
String
- 새로운 값을 할당할 때마다 새로운 메모리 영역을 가르킨다. 그 전의 값을 할당했던 메모리 영역은 Garbage로 남아있다가 GC에 의해 사라진다.
- String에서 저장되는 문자열은 private final char[]의 형태이기 때문에 String 값은 바꿀수 없다.(immutable)
- 두 개의 문자열을 연결하면 새로운 인스턴스가 생성된다.
- 문자열 연결을 계속하면 Garbage Collector가 호출되기 전까지 생성된 String 객체들은 Heap에 garbage로 쌓이기 때문에 메모리 관리에 치명적이다.
- String을 직접 더하는 것보다는 StringBuffer나 StringBuilder를 사용하는 것이 좋다.
-
StringBuilder, StringBuffer
-
내부적으로 가변적인 char[] 배열을 가지고 있는 클래스이다. memory에 append 하는 방식으로 문자열을 변경할 수 있다. 따라서 문자열의 추가, 수정, 삭제가 빈번하게 발생할 경우라면 String 클래스가 아닌 StringBuffer/StringBuilder를 사용하는 것이 좋음.
-
StringBuilder
-
변경가능한 문자열
-
비동기 처리
-
싱글 쓰레드에서는 성능이 더 좋음
-
-
StringBuffer
- 변경가능한 문자열
- 동기 처리
- multiple thread 환경에서 안전한 클래스(thread safe)
-
동기화와 비동기화의 차이(Syncronous vs Asyncronous)
- 동기화 방식: 한 자원에 대해 동시에 접근하는 것을 제한하는 방식.
- system call이 끝날 때까지 다른 쓰레드의 접근을 막아버리는 것.
- 메서드에 synchronized 붙여서 사용하면 됨
- 비동기화 방식: 한 자원에 대해 동시 접근이 가능한 방식
- system call이 왔든 말든 상관 없이 계속 호출할 수 있다.
- Call back 함수를 통해 결과를 가져온다
Class 클래스
컴파일 후 생성된 class 파일에서 객체의 정보(멤버변수, 메서드, 생성자 등)를 가져올 수 있다.
reflection 프로그래밍
Class 클래스를 이용하여 클래스의 정보를 가져오고 이를 활용해서 인스턴스를 생성하고, 메서드를 호출하는 등의 프로그래밍 방식
- 로컬 메모리에 객체가 없어서 객체의 데이터 타입을 직접 알 수 없는 경우(원격 클래스를 가져다 쓰는 경우 등) 객체 정보만을 이용하여 프로그래밍 할 수 있다.
- 컴파일 시간(Compile Time)이 아니라 실행 시간(Run Time)에 동적으로 특정 클래스의 정보를 객체화를 통해 분석 및 추출해낼 수 있는 프로그래밍 기법이다.
- 생성자(Constructor), 멤버 필드(Member Variables) 그리고 멤버 메서드(Member Method) 등을 사용할 수 있다.
- 왜 사용할까?
- 실행 시간에 다른 클래스를 동적으로 로딩하여 접근할 때
- 클래스와 멤버 필드 그리고 메서드 등에 관한 정보를 얻어야할 때
- 리플렉션 없이도 완성도 높은 코드를 구현할 수 있지만 사용한다면 조금 더 유연한 코드를 만들 수 있다.
- 주의할 점
- 외부에 공개되지 않는 private 멤버도 Field.setAccessible() 메서드를 true로 지정하면 접근과 조작이 가능하기 때문에 주의해야 한다
클래스 정보 가져오기
- Object 클래스의 getClass() 메서드 사용
String s = new String();
Class c = s.getClass();- 클래스 파일 이름을 Class 변수에 직접 대입
Class c = String.class;- Class.forName("클래스 이름") 메서드 사용
Class c = Class.forName("java.lang.String"); //클래스 이름은 패키지까지 풀네임- 클래스 이름은 String이기 때문에 오타가 나도 컴파일 타임엔 에러가 나지 않으므로 예외처리를 해줘야한다.
- 런타임에 입력한 이름의 클래스가 있으면 메모리에 로딩시킨다.(동적 로딩)
제네릭(Generic) 프로그래밍
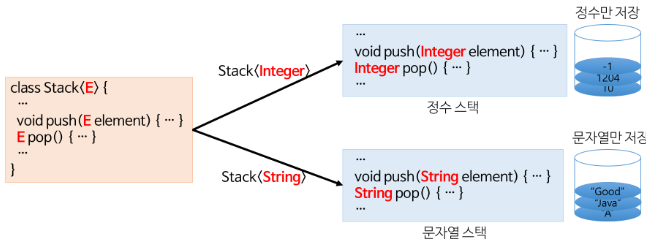
모든 종류의 타입을 다룰 수 있도록 일반화된 타입 매개 변수(generic type)로 클래스나 메서드를 선언하는 기법이다. 클래스 내부에서 사용하는 데이터 타입을 클래스의 인스턴스를 생성할 때 결정한다.
- 실제 사용되는 참조 자료형으로의 변환은 컴파일러가 검증하므로 안정적이다.
- 자료형 매개변수는 보통 type의 의미로 T를 많이 사용하고, 이는 생성될때 타입이 결정되므로 T 에 static 키워드는 사용할 수 없다.
-
처리 방법: 타입 제거(type erasure)라는 개념에 근거한다.
- 소스 코드를 JVM이 인식하는 바이트 코드로 변환할 때 인자로 주어진 타입을 제거하는 기술이다.
-
복수 제네릭도 가능하다.
-
특징
-
컴파일 시 강한 체크 타입 가능
- 기본 데이터 타입(int, long)으로는 지정 불가능하고, Wrapper 클래스(Integer, Boolean) 등 참조 자료형으로 가능하다.
-
제네릭 타입으로 특정 클래스나 자식 클래스 타입만 오도록 타입 매개변수를 제한할 수 있다.
class Stack<T extends 클래스> -
c++의 템플릿(Template)
-
개념: 템플릿은 하나의 클래스를 서로 다른 여러 타입에 재사용할 수 있도록 하는 방법
- 예를 들어 여러 타입의 객체를 저장할 수 있는 연결리스트와 같은 자료구조를 만들 수 있다.
-
처리 방법: 컴파일러는 인자로 주어진 각각의 타입에 대해 별도의 템플릿 코드를 생성한다.
-
예를 들어 MyClass가 MyClass와 정적 변수(static variable)를 공유하지 않는다.
-
하지만 java에서 정적 변수는 제네릭(Generic) 인자로 어떤 타입을 주었는지에 관계없이 MyClass로 만든 모든 객체가 공유한다.
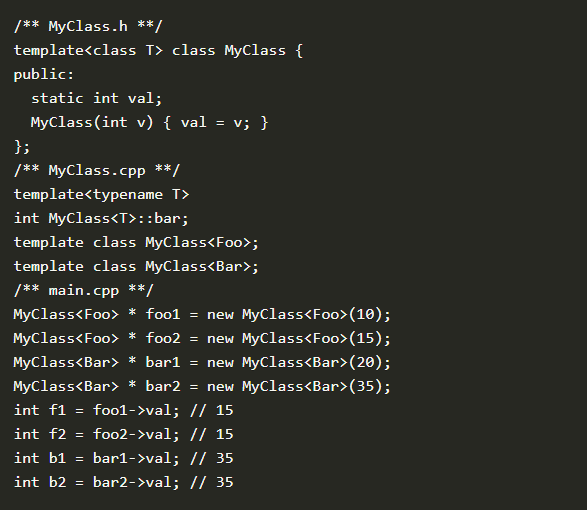
-
java의 제네릭(Generic)과 c++의 템플릿(Template)의 차이
- List처럼 코드를 작성할 수 있다는 이유에서 동등한 개념으로 착각하기 쉽지만 두 언어가 이를 처리하는 방법은 아주 많이 다르다.
- c++의 Template에는 int와 같은 기본 타입을 인자로 넘길 수 있지만, java의 Generic에서는 Integer을 대신 사용해야 한다.
- c++의 Template은 인자로 주어진 타입으로부터 객체를 만들어 낼 수 있지만, java에서는 불가능하다.
- java에서 MyClass로 만든 모든 객체는 Generic 타입 인자가 무엇이냐에 관계없이 전부 동등한 타입이다.(실행 시간에 타입 인자 정보는 삭제된다.)
- c++에서는 다른 Template 타입 인자를 사용해 만든 객체는 서로 다른 타입의 객체이다.
- java의 경우 Generic 타입 인자를 특정한 타입이 되도록 제한할 수 있다.
- 예를 들어 CardDeck을 Generic 클래스로 정의할 때 CardGame의 하위 클래스만 사용되도록 제한할 수 있다.
- java에서 Generic 타입의 인자는 정적 메서드나 변수를 선언하는 데 사용될 수 없다.
- 왜냐하면 MyClass나 MyClass가 이 메서드와 변수를 공유하기 때문이다.
- c++ Template은 이 두 클래스를 다른 클래스로 처리하므로 Template 타입 인자를 정적 메서드나 변수를 선언하는 데 사용할 수 있다.
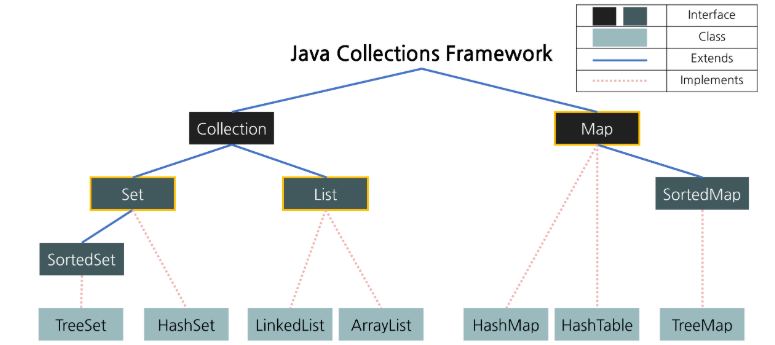
JAVA Collections Framework
-
Map
- 검색을 위한 자료구조
- 데이터를 삽입할 때 Key와 Value의 형태로 삽입되며, Key를 이용해서 Value를 얻을 수 있다.
- 내부적으로 hash 방식으로 구현되어 있다.
- HashMap & HashTable
- HashTable은 동기화를 지원하고 HashMap은 동기화를 지원하지 않음
- 지금은 대부분 HashMap 사용
- TreeMap
- key 객체를 기준으로 정렬
- key에 해당하는 클래스에 Comparable이나 Comparator 인터페이스를 구현해야함
-
Collection
-
List
- 선형 자료구조
- 순서가 있는 Collection
- 데이터를 중복해서 포함할 수 있다.
- Stack, Queue 등 포함
-
Set
- 집합적인 개념의 Collection
- 순서의 의미가 없다.
- 데이터를 중복해서 포함할 수 없다.
- 인덱스로 객체를 관리하지 않기 때문에 데이터를 검색하기 위해서는 iterator() 메서드로 반복자를 생성하고 데이터를 가져와야함.
-
HashSet
- 값을 저장할 때 인스턴스의 해시값을 기준으로 저장하기 때문에 순서대로 저장되지 않음
- 검색이 빠름
- hashCode() 를 통해 hash value 추출
-
TreeSet
- 객체의 정렬에 사용되는 클래스
- 이진탐색트리의 형태로 구현되어 있다.
- 객체 비교를 위해 정렬 대상이 되는 클래스에 Comparable이나 Comparator 인터페이스를 구현해야함(Comparator 사용시 TreeSet 생성자에 Comparator가 구현된 객체를 매개변수로 전달)
- 레드-블랙 트리로 구현
-
LinkedHashSet
- 입력된 순서대로 데이터를 관리
-
내부클래스
클래스 내부에 있는 클래스
- 인스턴스 내부 클래스
- 외부 클래스의 멤버 변수와 동일한 위치에 구현된다.
- 외부 클래스를 먼저 만든 후 내부 클래스 생성된다.
- static 변수와 메서드를 생성할 수 없다.
- 정적 내부 클래스
- 외부 클래스의 멤버 변수와 동일한 위치에 구현된다.
- 외부 클래스의 정적 변수만 사용 가능하다.
- 외부 클래스와 무관하게 생성된다.
- 지역 내부 클래스
- 메서드 내부에 구현된다.
- 메서드를 호출할 때 생성된다.
- 익명 내부 클래스(anonymous inner class)
- 지역 내부 클래스는 클래스 이름이 사용될 일이 거의 없어 이름을 없애 구현한 것이 익명 내부 클래스이다.
- 메서드 내부에 구현되거나, 변수에 대입하여 직접 구현된다.
- 메서드 안에 구현했을땐 메서드를 호출할 때 생성되거나, 인터페이스 타입 변수에 대입할 때 new 예약어를 사용하여 생성
람다식(lambda expression)
자바는 객체지향 프로그램 언어이기 때문에 자바에서 함수형 프로그래밍을 구현하는 방식으로 람다식을 제공한다. 클래스를 생성하지 않고 함수의 호출만으로 기능을 수행하는 방식이다.
함수형 프로그래밍
순수 함수(pure function)를 구현하고 호출함.
-
순수 함수
- 안정적이다. (외부 자료에 부수적인 영향을 주고받지 않고 매개 변수만을 사용해서 동작하도록 만든 함수여서 동일한 입력에 대해 동일한 결과를 리턴한다.)
-
병렬 처리가 가능하다. (외부 자료에 영향을 미치지 않기 때문에 side effect가 없어 여러 함수가 동시에 수행될 수 있다.)
람다식 구현
함수 이름과 반환 형을 없애고 ->를 사용한다. {}까지가 실행문을 의미
(int x, int y) -> {return x + y;}-
함수형 인터페이스
- 람다식을 선언하기 위한 인터페이스
- 익명 함수와 매개 변수만으로 구현되므로 단 하나의 메서드만 가져야 한다.
- @FunctionalInterface 어노테이션을 사용해 컴파일 에러를 막을 수 있음
-
자바는 객체 지향 언어로 객체를 생성해야 메서드가 호출된다. 따라서 람다식으로 메서드를 구현하고 호출하면 내부에서 익명 클래스가 생성된다. 이 람다식에서 외부 메서드의 지역변수는 상수로 처리 됨(지역 내부 클래스와 동일한 원리)
@FunctionalInterface interface StringConcat { public void makeString(String s1, String s2); } public class TestStringConcat { public static void main(String[] args) { StringConcat concat = (s1, s2) -> System.out.println(s1 + ", " + s2); concat.makeString("hello", "java"); // 내부적으로 생성되는 구현부 StringConcat concat = new StringConcat(){ @Override public void makeString(String s1, String s2){ System.out.println(s1 + ", " + s2); } }; } }
스트림
일관성 있는 연산을 처리할때, 자료를 더 효율적으로 연산할 수 있도록 제공되는 객체이다.
- 자료의 대상과 관계 없이 동일한 연산을 수행한다.
- 스트림이 제공하는 메서드들은 배열, 컬렉션 등에 상관 없이 동일한 연산을 수행함
- 일관성 있는 연산으로 자료의 처리를 쉽고 간단하게 함
- 한번 생성하고 사용한 스트림은 재사용 할 수 없음
- 자료에 대한 스트림을 생성하여 연산을 수행하면 스트림은 소모됨
- 다른 연산을 위해서는 새로운 스트림을 생성 함
- 스트림 연산은 기존 자료를 변경하지 않음
- 자료에 대한 스트림을 생성하면 별도의 메로리 공간을 사용하므로 기존 자료를 변경하지 않음
- 스트림 연산은 중간 연산과 최종 연산으로 구분됨
- 스트림에 대한 중간 연산은 여러 개 적용될 수 있지만 최종 연산은 마지막에 한번만 적용된다.
- 최종 연산이 호출되어야 중간연산의 결과가 모두 적용된다.
- 이를 '지연 연산(lazy evaluation)' 이라고 함
- 중간 연산 - filter(), map() 등
reduce() 연산
정의된 연산이 아닌 프로그래머가 직접 지정하는 연산을 적용할 수 있다.
최종 연산으로 스트림의 요소를 소모하여 연산을 수행
String[] greetings = {"안녕", "hello", "Good morning", "hi"};
// 직접 람다식 구현하는 방법
System.out.println(Arrays.stream(greetings).reduce("", (s1, s2) -> {
if(s1.getBytes().length >= s2.getBytes().length)
return s1;
else return s2;
}));
// 연산을 구현한 클래스를 사용하는 방법
String str = Arrays.stream(greetings).reduce(new CompareString()).get(); 자바 입출력
스트림의 구분 기준
-
대상 기준
-
자바에서는 입력과 출력 스트림을 동시에 쓰지 않고 구분해서 쓴다.
-
입력 스트림/출력 스트림
-
-
자료의 종류
- 바이트 단위로 읽고 쓰는 스트림: 동영상, 음악 파일 등을 읽고 쓸 때 사용
- FileInputStream, FileOutputStream 등
- 문자 단위로 읽고 쓰는 스트림: 바이트 단위로 자료를 처리하면 문자는 깨짐. 이에 따라 2바이트 단위로 처리하도록 구현된 스트림
- FileReader, FileWriter 등
- 바이트 단위로 읽고 쓰는 스트림: 동영상, 음악 파일 등을 읽고 쓸 때 사용
-
기능
- 기반 스트림: 입력을 받는 소스나 출력을 할 대상에 직접 생성돼서 읽고 쓰는 기능을 함
- 보조 스트림: 소스에서 직접 읽고 쓰는 기능은 없지만 원래 있는 스트림에 추가적인 기능을 더해주는 스트림. 단일 바이트 스트림에 버퍼링 제공, 멀티 바이트 스트림에 문자로 변환 등
- 직접 읽고 쓰는 기능은 없으므로 항상 기반 스트림이나 또 다른 보조 스트림을 생성자 매개변수로 포함한다.
- InputStreamReader, OutputStreamWriter 등(바이트 단위로 읽거나 쓰는 자료를 문자로 변환해주는 보조 스트림)
- Buffered 스트림: 내부적으로 8192 바이트 배열을 가지고 읽거나 쓰기 기능을 제공하여 속도가 빨라진다.
- BufferedInputStream, BufferedOutputStream, BufferedReader, BufferedWriter
- 직렬화, 역직렬화 지원하는 클래스: ObjectOutputStream, ObjectInputStream
객체 직렬화(Serialization)와 역직렬화(Deserialization)
직렬화
- 자바 직렬화란 자바 시스템 내부에서 사용되는 인스턴스를 파일에 쓰거나 네트워크로 전송하는 등 외부의 자바 시스템에서도 사용할 수 있도록 바이트(byte) 형태로 데이터를 변환하는 기술과 바이트로 변환된 데이터를 다시 객체로 변환하는 기술
- JVM의 메모리에 로드(힙 또는 스택)되어 있는 객체 데이터를 바이트 형태로 변환하는 기술
- Serializable 인터페이스를 상속받아 사용
- 인스턴스의 정보가 외부로 유출되는 것이기 때문에 이에 대해 허용한다는 뜻으로 사용
- 구현 코드가 없는 maker interface
- transient: 해당 멤버변수는 직렬화할 때 저장하지 않겠다는 뜻
class Person implements Serializable {
String name;
transient String title;
public Person(){}
public Person(String name, String title){
this.name = name;
this.title = title;
}
public String toString(){
return name + ", " + title;
}
}public class SerializationTest {
public static void main(String[] args) {
Person personLee = new Person("Lee", "Manager");
try(FileOutputStream fos = new FileOutputStream("serial.dat");
ObjectOutputStream oos = new ObjectOutputStream(fos)){
oos.writeObject(personLee);
} catch(IOException e){
System.out.println(e);
}
}
}역직렬화
- byte로 변환된 Data를 원래대로 Object나 Data로 변환하는 기술을 역직렬화(Deserialize)라고 부릅니다.
- 직렬화된 바이트 형태의 데이터를 객체로 변환해서 JVM으로 로드시키는 형태.
자바 직렬화의 장점
자바 직렬화는 자바 시스템에서 개발에 최적화되어 있다. 복잡한 데이터 구조의 클래스의 객체라도 직렬화 기본 조건만 지키면 큰 작업 없이 바로 직렬화가 가능하다. 물론 역직렬화도 마찬가지.
- 사용되는 곳:
- 서블릿 세션
- 캐시
예외처리
- 컴파일 오류(compile error): 프로그램 코드 작성 중 발생하는 문법적 오류
- 실행 오류(runtime error): 실행 중인 프로그램이 의도하지 않은 동작을 하거나(bug) 프로그램이 중지되는 오류
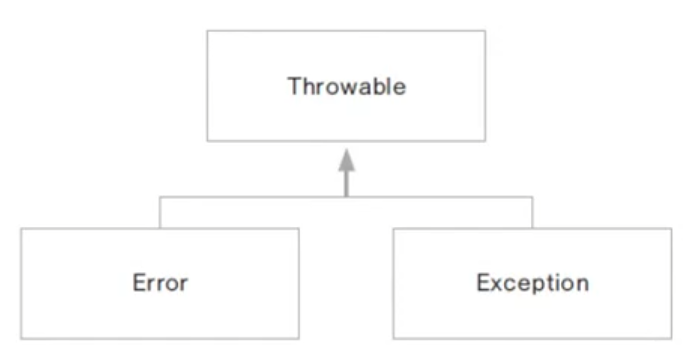
- 시스템 오류(error): 가상 머신에서 발생하는 오류로, 프로그래머가 처리 할 수 없다.
- 동적 메모리가 없는 경우, 스택 오버 플로우 등
- 예외(exception): 프로그램에서 제어할 수 있는 오류
- 읽어 들이려는 파일이 존재하지 않는 경우, 네트워크 연결이 끊어진 경우
예외 처리 방법
- try catch 문 사용
FileInputStream fis = null;
try{
fis = new FileInputStream("a.txt");
} catch (FileNotFoundException e){
System.out.println(e);
return;
} finally{ //finally 구문은 try 구문이 실행되면 무조건 실행된다.
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("Finally");
}-
try-with-resources
- 핸들링하는 리소스가 AutoCloseable을 구현 한 경우에는 close()를 명시적으로 호출하지 않아도 try 블록에서 열린 리소스는 정상적인 경우와 예외 발생안 경우 모두 자동 해제 된다.
try(FileInputStream fis = new FileInputStream("a.txt")) { } catch (FileNotFoundException e){ System.out.println(e); }
- throws로 예외 처리 미루기
-
throws로 예외 처리를 미루면 예외가 발생한 메서드에서 예외 처리를 하지 않고 이 메서드를 호출한 곳에서 예외 처리를 한다는 의미이다.
-
main() 에서 throws를 사용하면 가상머신에서 처리 됨
-
다중 예외 처리 시 주의 사항
- 예외가 다양한 경우 가장 최상위 클래스인 Exception 클래스에서 예외를 처리할 수 있음
- 단 Exception 클래스는 모든 예외 클래스의 최상위 클래스이므로 가장 마지막 블록에 위치 해야함.
try { ex.loadClass("b.txt", "java.lang.String"); } catch (FileNotFoundException e) { System.out.println(e); } catch (ClassNotFoundException e) { System.out.println(e); }catch (Exception e){ System.out.println(e); }
