자료구조란 무엇인가?
- 프로그램에서 사용할 많은 데이터를 메모리 상에서
관리하는 여러 구현 방법들 - 효율적인 자료구조가 성능 좋은 알고리즘의 기반이 된다.
- 자료의 효율적인 관리는 프로그램의 수행속도와 밀접한 관련이 있다.
- 여러 자료 구조 중에서 구현하려는 프로그램에 맞는 최적의 자료구조를 활용해야 하므로 자료구조에 대한 이해가 중요하다.
자료구조에는 어떤 것들이 있나?
- 한 줄로 자료를 관리하기 (선형 자료구조)

배열 (Array)
선형으로 자료를 관리, 정해진 크기의 메모리를 먼저 할당받아 사용하고, 자료의 물리적 위치와 논리적 위치가 같다.
Array의 특징
- 동일한 데이터 타입을 순서에 따라 관리하는 자료 구조
- 정해진 크기가 있음
- 요소의 추가와 제거시 다른 요소들의 이동이 필요함
- 배열의 i 번째 요소를 찾는 인덱스 연산이 빠름
- jdk 클래스 : ArrayList, Vector
연결 리스트(LinkedList)
선형으로 자료를 관리, 자료가 추가될 때마다 메모리를 할당 받고, 자료는 링크로 연결되며, 자료의 물리적 위치와
논리적 위치가 다를 수 있다.
LinkedList 특징
- 동일한 데이터 타입을 순서에 따라 관리하는 자료 구조
- 자료를 저장하는 노드에는 자료와 다음 요소를 가리키는 링크(포인터)가 있음
- 자료가 추가 될때 노드 만큼의 메모리를 할당 받고 이전 노드의 링크로 연결함(정해진 크기가 없음)
- 연결 리스트의 i 번째 요소를 찾는게 걸리는 시간은 요소의 개수에 비례
- jdk 클래스 : LinkedList
리스트에 자료 추가하기
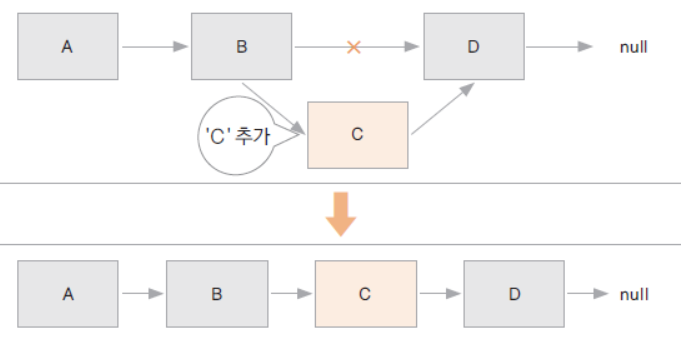
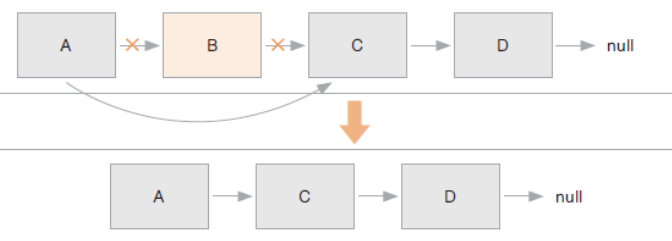
리스트에 자료 삭제하기
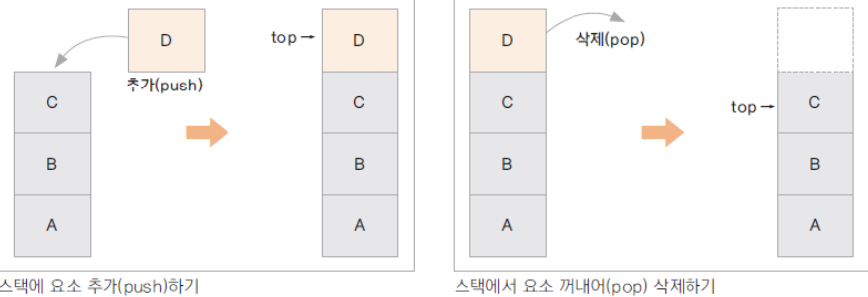
스택 (Stack)
가장 나중에 입력 된 자료가 가장 먼저 출력되는 자료 구조
(Last In First Out)
Stack의 특징
- 맨 마지막 위치(top)에서만 자료를 추가,삭제,꺼내올 수 있음
(중간의 자료를 꺼낼 수 없음) - Last In First Out(후입선출) 구조
- 택배 상자가 쌓여있는 모양
- 가장 최근의 자료를 찾아오거나 게임에서 히스토리를 유지하고 이를 무를 때 사용할 수 있음
- 함수의 메모리는 호출 순서에 따른 stack 구조
- jdk 클래스 : Stack
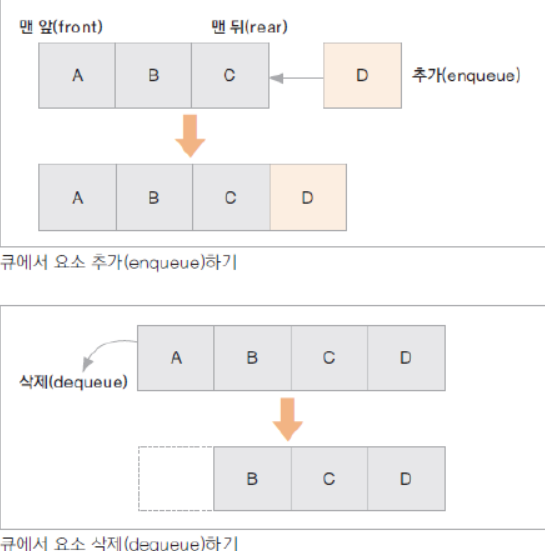
큐(Queue)
가장 먼저 입력된 자료가 가장 먼저 출력되는 자료 구조
(First In First Out)
Queue의 특징
- 맨 앞(front)에서 자료를 꺼내거나 삭제하고 맨 뒤(rear)에서 자료를 추가
- Fist In Fist Out(선입선출) 구조
- 일상 생활에서 줄 서 있는 모양
- 순차적으로 입력된 자료를 순서대로 처리하는데 많이 사용되는 구조
- 콜센터에 들어온 문의 전화, 메세지 큐 등에 활용됨
- jdk 클래스: ArrayList
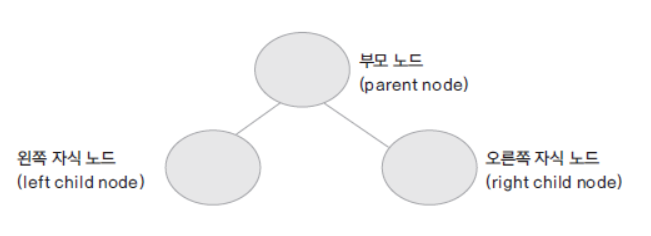
트리(Tree)
부모 노드와 자식 노드간의 연결로 이루어진 자료 구조
힙(heap)
Priority queue를 구현(우선 큐) -> 우선순위 큐는 우선순위가 높은 순으로 꺼내므로 힙을 이용해서 구현한다.
(최대힙이 부모노드가 자식노드보다 항상 크기때문에 반대인 최소힙으로도 가능)
이진트리 (binary tree)
부모노드에 자식노드가 두 개 이하인 트리
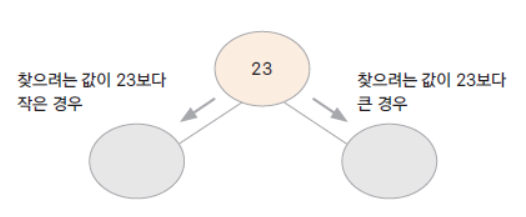
이진 검색 트리 (binary search tree)
해싱(Hasing)
자료를 검색하기 위한 자료 구조, 검색을 위한 자료 구조이다.
키(key에 대한 자료를 검색하기 위한 사전(dictionary)개념의 자료 구조
key는 유일하고 이에 대한 value를 쌍으로 저장
index = h(key) : 해시 함수가 key에 대한 인덱스를 반환해주며 해당 인덱스 위치에 자료를 저장하거나 검색하게 된다.
저장되는 메모리 구조를 해시테이블이라 한다.
jdk 클래스 : HashMap,Properties
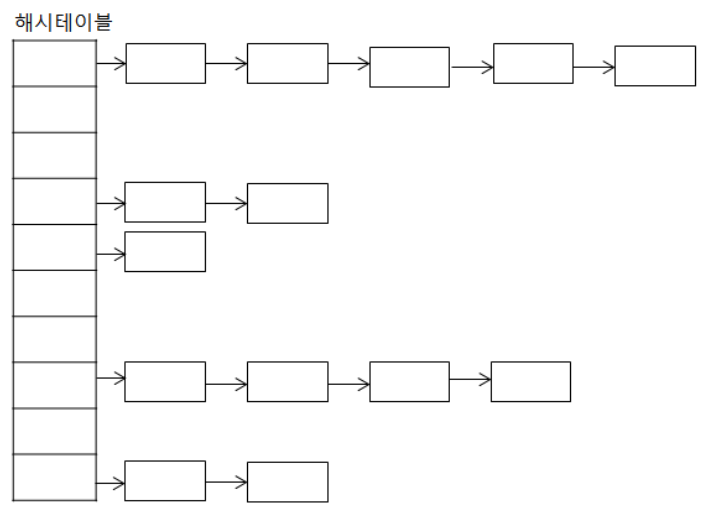
해시는 키에 대한 밸류가 있다.
키는 중복될 수 없고 키만 알면 밸류를 꺼낼 수 없다.
해시는 들어가는 순서와 상관이 없다. 해시펑션에 의해 정해져서 순서랑은 무관하다.
무엇이든 담을 수 있는 제네릭(Generic)
제네릭 자료형 정의
- 클래스에서 사용하는 변수의 자료형이 여러개 일수 있고, 그 기능(메서드)는 동일한 경우 클래스의 자료형을 특정하지 않고 추후 해당 클래스를 사용할 때 지정 할 수 있도록 선언
- 실제 사용되는 자료형의 변환은 컴파일러에 의해 검증되므로 안정적인 프로그래밍 방식
- 컬렉션(Collection) 프레임워크에서 많이 사용되고 있음
자료구조 구현 클래스 - 컬렉션 프레임워크
- 프로그램 구현에 필요한 자료구조(Data Structure)를 구현해 놓은 jdk 라이브러리
- java.util 패키지에 구현되어 있음
- 개발에 소요되는 시간을 절약하면서 최적화 된 알고리즘을 사용할 수 있음
- 여러 구현 클래스와 인터페이스의 활용에 대한 이해가 필요함
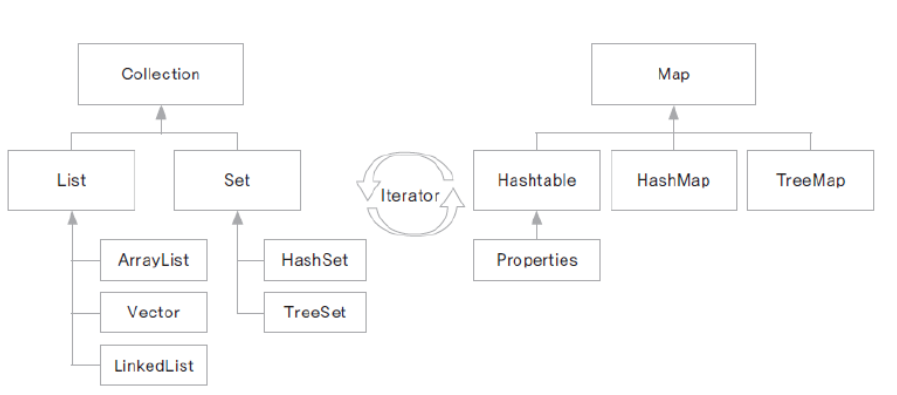
Collection 인터페이스
- 하나의 객체를 관리하기 위한 메서드가 선언된 인터페이스
- 하위에 List와 Set 인터페이스가 있음
List 인터페이스
- 객체를 순서에 따라 저장하고 관리하는데 필요한 메서드가 선언된 인터페이스
- 자료구조 리스트(배열,연결리스트)의 구현을 위한 인터페이스
- 중복을 허용함
- ArrayList, Vector, LinkedList, Stack, Queue 등
Set 인터페이스
- 순서와 관계없이 중복을 허용하지 않고 유일한 값을 관리하는데 필요한 메서드가 선언됨
- 아이디, 주민번호, 사번등을 관리하는데 유용
- 저장된 순서와 출력되는 순서는 다를 수 있음
- HashSet, TreeSet 등
Map 인터페이스
- 쌍(pair)로 이루어진 객체를 관리하는데 사용하는 메서드들이 선언된 인터페이스
- 객체는 key-value의 쌍으로 이루어짐
- key는 중복을 허용하지 않음
- HashTable, HashMap, Properties, TreeMap 등
Collection 요소를 순회하는 Iterator, List 인터페이스를 구현하는 컬렉션 클래스들
요소의 순회란
- 컬렉션 프레임워크에 저장된 요소들을 하나씩 차례로 참조하는 것
- 순서가 있는 List 인터페이스의 경우는 Iterator를 사용 하지 않고
get(i) 메서드를 사용할 수 있다. - Set 인터페이스의 경우 get(i) 메서드가 제공되지 않으므로 Iterator를 활용하여 객체를 순회한다.
Iterator 사용하기
// Iterable 인터페이스
public interface Iterable<T> {
Iterator<T> iterator();- boolean hasNest() : 이후에 요소가 더 있는지를 체크하는 메서드
요소가 있다면 true를 반환 - E next() : 다음에 있는 요소를 반환
- void remove() : next 메소드 호출을 통해 반환했던 인스턴스 삭제
public static void main(String[] args) {
List<String> list = new LinkedList<>();
...
Iterator<String> itr = list.iterator();
...
// 반복자를 이용한 순차적 참조
while(itr.hasNext()) { // next 메소드가 반환할 대상이 있다면
str = itr.next(); // next 메소드를 호출한다.
if(str.equals("Box"));
itr.remove(); // next 메소드가 반환한 인스턴스 삭제
...
}
}다음 두 가지 이유로 배열보다 ArrayList<E>가 더 좋다.
- 인스턴스의 저장과 삭제가 편하다.
- 반복자를 쓸 수 있다.
단, 배열처럼 선언과 동시에 초기화가 불가능한다.하지만 방법이 있다.
List<String> list = Arrays.asList("Toy","Robot","Box");
-> 인자로 전달된 인스턴스들을 저장한 컬렉션 인스턴스의 생성 및 반환
-> 이렇게 생성된 리스트 인스턴스는 Immutable 인스턴스이다.(변경 불가능)
하지만 이것도 방법이 있다.
public static void main(String[] args) {
List<String> list = Arrays.asList("Toy","Box","Robot","Box");
// 생성자 public ArraysList(Collection<? extends E> c)를 통한 인스턴스 생성
list = new ArrayList<>(list);public ArraysList(Collection<? extends E> c) {...}
-> Collection<E>를 구현한 컬렉션 인스턴스를 인자로 전달받는다.
-> 그리고 E는 인스턴스 생성 과정에서 결정되므로 무엇이든 될 수 있다.
-> 덧붙여서 매개변수 c로 전달된 컬렉션 인스턴스에서는 참조만(꺼내기만) 가능하다.배열 기반 리스트를 연결 기반 리스트로
public static void main(String[] args) {
List<String> list = Arrays.asList("Toy","Box","Robot","Box");
list = new ArraysList<>(list); // 배열 기반 리스트
...
//ArraysList<E> 인스턴스 기반으로 LinkedList<E> 인스턴스 생성
list = new LinkedList<>(list);연결 리스트만 갖는 양방향 반복자
class ListIteratorCollection {
public static vod main(String[] args) {
List<String> list = Arrays.asList("Toy","Box","Robot","Box");
list = new ArrayList<>(list);
ListIterator<String> litr = list.listIterator();
// 양방향 반복자 획득
String str;
// 왼쪽에서 오른쪽으로 이동을 위한 반복문
while(litr.hasNext()){
str = litr.next();
System.out.print(str+'\t');
if(str.equals("Toy"))
litr.add("Toy2);
}
System.out.println();
// 오른쪽에서 왼쪽으로 이동을 위한 반복문
while(litr.hasPrevious()){
str = litr.previous();
System.out.print(str+'\t');
if(str.equals("Robot"))
litr.add("Robot2");
}
}
}Set 인터페이스를 구현하는 컬렉션 클래스들
HashSet 클래스
Set 인터페이스를 구현하는 제네릭 클래스의 특성 두가지는 다음과 같다.
- 저장 순서가 유지되지 않는다.
- 데이터의 중복 저장을 허용하지 않는다.
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("Toy"); set.add("Box");
set.add("Robot"); set.add("Box");
System.out.println("인스턴스 수: "+set.size());
// 인스턴스 수: 3그렇다면 동일 인스턴스의 기준은?
public boolean equals(Object obj)
Object 클래스의 equal 메소드 호출 결과를 근거로 동일 인스턴스를 판단한다.
public int hashCode()
그런데 그에 앞서 Object 클래스의 hashCode 메소드 호출 결과가 같아야 한다.
TreeSet 클래스
트리(Tree) 자료구조를 기반으로 인스턴스를 저장, 이는 정렬 상태가 유지되면서 인스턴스가 저장됨을 의미한다.
public static void main(String[] args) {
TreeSet<Integer> tree = new TreeSet<Integer>();
tree.add(3); tree.add(1);
tree.add(2); tree.add(4);
System.out.println("인스턴스 수: "+tree.size());
// 인스턴스 수: 3
//for-each문에 의한 반복
for(Integer n : tree)
System.out.print(n.toString()+'\t');
// 1 2 3 4인스턴스의 비교 기준을 정의하는 것은 Comparable 인터페이스의 기준
class Person implements Comparable<Person> {
private String name;
private int age;
...
@Override
public int compareTo(Person p) {
return this.age-p.age;
}
}따라서 TreeSet에 저장할 인스턴스들은 모두 Comparable 인터페이스를 구현한 클래스 인스턴스여야한다.
Comparator 인터페이스 기반으로 TreeSet 정렬 기준 제시하기
기존의 기준말고 새로운 정렬기준을 만들어 주는것이다.
class StringComparator implements Comparator<String> {
public int compare(String s1, String s2) {
return s1.length() - s2.length();
}
}
public static void main(String[] args) {
TreeSet<String> tree = new TreeSet<>(new StringComparator());
tree.add("Box");
tree.add("Rabbit");
tree.add("Robot");
for(String s : tree)
System.out.print(s.toString() + '\t');
//Box Robot Rabbit