자료형의 종류와 구분
| 자료형 | 데이터 | 크기 | 범위 |
|---|---|---|---|
| boolean | 참과 거짓 | 1 바이트 | ture, flase |
| char | 문자 | 2 바이트 | 유니코드 문자 |
| byte | 정수 | 1 바이트 | -128 ~ 127 |
| short | 정수 | 2 바이트 | -32768 ~ 32767 |
| int | 정수 | 4 바이트 | -2,147,483,648 ~ 2,147,483,647 |
| long | 정수 | 8 바이트 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
| float | 실수 | 4 바이트 | 3.4E +/- 38(7자리 숫자) |
| double | 실수 | 8 바이트 | 1.7E +/- 308(15자리 숫자) |
자바 이름 규칙(Naming Rule)
클래스의 이름 규칙
- 클래스 이름의 첫 문자는 대문자로 한다.
- 둘 이상어 단어가 묶여서 하나의 이름을 이룰 때, 새로 시작하는 단어는 대문자로 한다. ex) CirclePoint
메소드와 변수의 이름 규칙(카멜)
- 첫 문자는 소문자로 한다.
ex) Add + Your + Money = addYourMoney
상수의 이름 규칙
- 변수와 구분가능하도록 모든 문자를 대문자로 한다.
ex) final int COLOR = 7;
자바의 일반적인 상수(Constants)
키워드 final가 붙는 변수이름은 모두 대문자로 짓는다.
- 값을 딱 한번만 할당할 수 있다.
- 한번 할당된 값은 변경이 불가능하다.
class Constants {
public static void mian(Stirng[] args) {
final int MAX_SIZE = 100;
final char CONST_CHAR ="상";
}
}형 변환
자바는 기본적으로 int 형 연산을 한다.
자동 형 변환(Implicit Conversion)
- 자료형의 크기가 큰 방향으로 형 변환이 일어난다.
- 자료형의 크기에 상관없이 정수 자료형보다 실수 자료형이 우선한다.
byte -> short, char -> int -> long -> float -> double
명시적 형 변환(Explicit Conversion)
double pi = 3.1415;
int wholeNumber = (int)pi;
클래스의 정의와 인스턴스화
데이터와 기능을 묶어놓은 것
class BankAcoount{
static int balance = 0;
public int deposit(int amount) {
balance += amount;
return balance;
}
public int withdraw(int amount) {
balance -= amount;
return balance;
}
public int checkMyBalance() {
System.out.println("잔액: " + balance);
return balance;- 인스턴스 = 객체
- 인스턴스 변수(or 멤버 변수, 필드) : 클래스 내에 선언된 변수
- 인스턴스 메소드 : 클래스 내에 정의된 메소드
인스턴스화
BankAccount myAcnt1; // 참조변수 myAcnt1의 선언
BankAccount myAcnt2; // 참조변수 myAcnt2의 선언
// 클래스 BankAccount의 인스턴스화(Instantiaion)
myAcnt1 = new BankAccount()
myAcnt2 = new BankAccount()
myAcnt1.deposit(1000) // myAcnt1이 참조하는 인스턴스의 deposit 호출
myAcnt2.deposit(2000);생성자와 String 클래스
String 클래스
String str = "Happy";
// String형인 Happy는 인스턴스이다.생성자(Constructor)
생성자 메소드는 값 초기화를 위한 것이다.
- 생성자의 이름은 클래스의 이름과 동일해야 한다.
- 생성자는 값을 반환하지 않고 반환형도 표시하지 않는다.
public BankAcoount(String acc, String ss, int bal){
accNumber = acc;
ssNumber = ss;
balance = bal;디폴트 생성자
인자가 없는 생성자, 정의해주지 않으면 자동삽입 된다.
public BankAccount() {
// empty
}클래스 패스(class path)
명령 프롬프트 상황에서의 '현재 디렉토리'는 다음과 같다.
C:\PackageStudy
명령 프롬프트 상에서 작업이 진행중인 디렉토리의 위치클래스 패스의 지정
명령 프롬프트
C:\PackageStudy>set classpath-- 클래스 패스는 '자바 가상머신의 클래스 탐색 경로'를 의미하며,
이는 프로그래머가 직접 지정할 수 있다.
클래스 패스에는 둘 이상의 경로를 지정할 수 있다. 둘 이상의 경로를 지정할때는 세미콜론(;)으로 이를 구분해준다.
- 경로1: 현재 디렉토리 -> 현재 디렉토리는 . 으로 표시
- 경로2: C:\PackageStudy/MyClass
절대 경로
C:\PackageStudy>set classpath=.;C:\PackageStudy\MyClass
상대 경로
.\MyClass패키지의 이해
자바 8을 기준으로 Java SE(Standard Edition)에서 제공하는 클래스의 수가 많은데, 같은 이름의 클래스는 반드시 존재할수 밖에 없다.
구분하기 위해선 다른 패키지(디렉토리)에 속해있는것이다.
패키지의 선언
- 인터넷 도메인 이름의 역순으로패키지 이름을 구성한다.
- 패키지 이름의 끝에 클래스는 정의한 주체 또는 팀을 구분하는 이름을 추가한다.
ex) com.wxfx.smart정보 은닉(Information Hiding)
정보의 은닉을 위한 private 선언을 하며 클래스 내부에서만 접근할 수 있도록 한다.
접근 수준 지시자(Access-level Modifiers)
- 클래스 정의 대상 : public, default
- 인스턴스 변수와 메소드 대상 : public, protected, default, private
캡슐화를 중요시 여긴다.
static 클래스
static으로 선언된 변수는 변수가 선언된 클래스의 모든 인스턴스가 공유하는 변수이다.
클래스 변수의 접근 방법
- 클래스 내부 접근 : 변수의 이름을 통해 접근
- 클래스 외부 접근 : 클래스 또는 인스턴스의 이름을 통해 접근
class AccessWay {}
class ClassAccess {
AccessWay way = new AccessWay();
way.num++; // 외부에서 인스턴스의 이름을 통한 접근
AccessWay.num++; // 외부에서 클래스의 이름을 통한 접근
}클래스 변수는 생성자 기반 초기화를 하면 안된다.
인스턴스 생성할때 마다 값이 리셋되기 때문
메소드 오버로딩(Method Overloading)
메소드 오버로딩의 조건
- 메소드의 이름
- 메소드의 매개변수 정보
메소드의 이름이 같아도 매개변수 선언이 다르면 메소드를 구분할 수 있다
메소드 오버라이딩
상위 클래스에 정의된 메소드를 하위 클래스에서 다시 정의하는 것
- 반환형, 메소드의 이름, 매개변수가 같으면 오버라이딩이 가능
enhanced for문
자바5에서 추가된 반복문이다.
for(int e: ar) {
System.out.println(e);
}상속
상속은 "연관된 일련의 클래스들에 대해 공통적인 규약을 정의할 수 있는 것"이다.
-- 하위 클래스의 인스턴스 생성 시 상위 클래스,하위 클래스의 생성자 모두 호출된다.
-- 하위 클래스의 인스턴스 생성시 상위 클래스의 생성자가 먼저 호출된다.
자바 다형성
하나의 객체가 여러가지 형태를 가질 수 있는 것을 의미한다.
자바에서 다형성은 한 타입의 참조 변수를 통해 여러 타입의 객체를 참조할 수 있도록 허용하여 상위 클래스가 동일한 메시지로 하위 클래스들이 서로 다른 동작을 할 수 있도록 한다.
다형성을 활용하면, 부모 클래스가 자식 클래스의 동작 방식을 알 수 없어도 오버라이딩을 통해 자식 클래스에 접근할 수 있다.
다형성의 장점
- 유지보수 : 여러 객체를 하나의 타입으로 관리할 수 있어 유지보수가 용이하다.
- 재사용성 : 객체의 재사용이 쉬워 재사용성이 높아진다.
- 느슨한 결합 : 클래스 간의 의존성을 줄여 확장성은 높아지고 결합도는 낮아진다.
다형성의 조건
- 상위 클래스와 하위 클래스는 상속 관계여야 한다.
- 다형성이 보장되기 위해 오버라이딩(하위 클래스 메서드의 재정의)이 반드시 필요하다.
- 자식 클래스의 객체가 부모 클래스의 타입으로 형변환(업캐스팅) 해야 한다.
instanceof 연산자
instanceof는 참조의 유무를 따져 true or false를 반환하는 것
if (ref instanceof ClassName)
// ref가 ClassName 클래스의 인스턴스를 참조하면 true 반환
// ref가 ClassName 상속하는 클래스의 인스턴스이면 true 반환Interface(인터페이스)
기본 정의
interface Printable{
public void print(String doc); // 추상 메소드
}클래스가 인터페이스를 상속하는 행위는 "상속"이 아닌 "구현(Implementation)"이라 한다. 문법 관계는 상속과 동일하지만 본질은 "구현"이기 때문이다.
- 인스턴스 생성 불가, 참조변수 선언 가능
- 인터페이스의 형을 대상으로 참조변수의 선언이 가능하다.
- 인터페이스의 추상 메소드와 이를 구현하는 메소드 사이에 오버라이딩 관계가 성립한다. (@Override의 선언이 가능)
- 반드시 선언과 동시에 값으로 초기화를 해야 한다.
- 모든 변수는 public static final이 선언된 것으로 간주한다.
인터페이스 간 상속
interface Printable {
void print(String doc);
}
interface ColorPrintable extends Printable{
void printCMYK(String doc);
}
제네릭(Generic)의 이해
제네릭이 갖는 의미는 "일반화"이다. 그리고 자바에서 그 일반화의 대상은
자료형이다.
인스턴시 생성시 결정이 되는 자료형의 정보를 T로 대체한다.
class Box<T> {
private T ob;
public void set(T o) {
ob = o;
}
public T get() {
return ob;
}
} T로 자료형을 임의로 비워둔다는 것을 암시하며, T에 들어갈 자료형은
인스턴스를 생성할 때 정의한다.
Box<Apple> aBox = new Box<Apple>();
혹은
Box<Apple> aBox = new Box<>();
타입 매개변수 (Type Parameter) : Box<T>에서 <T>
타입 인자 (Type Argument) : Box<Apple>에서 Apple
매개변수화 타입 (Parameterized Type) : Box<Apple>기본 자료형에 대한 제한 그리고 래퍼 클래스
Box<int> box = new Box<int>(); // 사용불가
Box<Integer> box = new Box<Integer>(); // 사용가능 "매개변수화 타입"을 "타입인자"로 전달하기
class Box<T> {
private T ob;
public void set(T o) {
ob = o;
}
public T get() {
return ob;
}
}
class BoxInBox{
public static voide main(String[] args) {
Box<String> sBox = new Box<>();
sBox.set("I am so happy.");
Box<Box<String> wBox = new Box<>();
wBox.set(sBox);
Box<Box<Box<String>>> zBox = new Box<>();
zBox.set(wBox);
System.out.println(zBox.get().get().get());
}
}제네릭 클래스의 타입 인자 제한하기
class Box<T extends Number> {...}인스턴스 생성 시 타입 인자로 Number 또는 이를 상속하는 클래스만 올 수 있음
타입 인자를 제한하지 않았을 때
class Box<T> {
private T ob;
....
public int toIntValue() {
return ob.intValue(); // ERROR
}
}
타입 인자를 제한했을 때
class Box<T extens Number>{
private T ob;
....
public int toIntValue() {
return ob.intValue(); // OK
}
}위의 예시처럼 참조변수 ob가 참조하게 될 것은 인스턴스이다. 하지만 어떠한 클래스의 인스턴스를 참조하게 될지 알 수 없기 때문에 ob를 통해서 호출할 수 있는 메소드는 Object 클래스의 메소드로 제한이 된다.
반면, 타입 인자를 제한하면 Number 클래스의 intValue 메소드를 호출할 수 있다. ob가 참조하는 인스턴스는 intValue 메소드를 가지고 있음을 보장할 수 있기 때문이다.
제네릭 클래스의 타입 인자를 인터페이스로 제한하기
interface Eatable { public String eat();}
class Apple implements Eatable {
public String eat() {
return "It tastes so good";
}
}
class Box<T extends Eatable> {
T ob;
public void st(T o) {
ob = o;
}
public T get() {
System.out.println(ob.eat()); //Eatable로 제한하였기에 eat 호출 가능
return ob;
하나의 클래스와 하나의 인터페이스에 대해 동시 제한
class Box<T extends Number & Eatable> {...}제네릭 메소드
클래스 전부가 아닌 일부 메소드에 대해서만 제네릭으로 정의하고 싶을 때
메소드는 인스턴스 메소드 뿐만 아니라 클래스 메소드에도 가능하다.
public static <T> Box<T> makeBox(T o) {...}
메소드의 이름은 makeBox이고 반환형은 Box<T>이다."제네릭 메소드의 T는 메소드 호출 시점에 결정한다.
class BoxFactory {
public static <T> Box<T> makeBox(T o) {
Box<T> box = new Box<T>();
box.set(o);
return box;
}
}
// 오토 박싱 전
Box<String sBox = BoxFactory.<String>makeBox("Sweet");
Box<String dBox = BoxFactory.<Double>makeBox("7.59");
// 오토 박싱 후
Box<String sBox = BoxFactory.makeBox("Sweet");
Box<String dBox = BoxFactory.makeBox("7.59");제네릭 메소드의 제한된 타입 매개변수 선언
public static <T extends Number> Box<T> makeBox(T o) {
...
// 타입 인자 제한으로 intValue 호출 가능
System.out.println("Boxed data: " + o.intValue());
return box;
}
// 타입 인자를 Number를 상속하는 클래스로 제한
public static <T extends Number> T openBox(Box<T> box) {
// 타입 인자 제한으로 intValue 호출 가능
System.out.println("Unboxed data: "+ box.get().intValue());
return box.get();
}와일드카드 ( ? )
어떤 형태의 타입이든 다 받는것
public static void peekBox(Box<?> box) {
System.out.println(box);
}public static <T> void peekBox(Box<T> box) {
System.out.println(box)
} // 제네릭 메소드의 정의
public static void peekBox(Box<?> box) {
System.out.println(box)
} // 와일드 카드 기반 메소드 정의와일드 카드의 상속
상한 제한된 와일드 카드(Upper-Bounded Wildcards), extends
public static void peekBox(Box<? extends Number> box){
System.out.println(box);
}
-- box는 Box<T> 인스턴스를 참조하는 참조변수이다.
-- 이때 Box<T> 인스턴스의 T는 Number 또는 이를 상속하는 하위 클래스이어야 함하한 제한된 와일드 카드(Lower-Bounded Wildcards), super
public static void peekBox(Box<? super Integer> box) {
System.out.println(box);
}
-- box는 Box<T> 인스턴스를 참조하는 참조변수이다.
-- 이때 Box<T> 인스턴스의 T는 Integer 또는 Integer가 상속하는 클래스어야 함언제 와일드카드에 제한을 걸어야 하나? : 도입
Box<T>의 T를 Number 또는 Number를 직간접적으로 상속하는
클래스로 제한하기 위한것도 좋은 설명이다.그리고 인자를 전달되는 대상을 제한하는 것은 그 자체로 프로그램에 안정성을 높여 의미가 있다.
상한 제한의 목적
먼저 다음 메서드를 봅시다.
class BoxHandler {
// 매개변수 box가 참조하는 상자에서 인스턴스를 꺼내는 기능
public static void outBox(Box<Toy> box) {
Toy toy = box.get(); // 상자에서 꺼내기
System.out.println(toy);
}
}이 메서드를 정의할 당시 프로그래머의 생각은 다음과 같을 것 입니다.
'상자에서 내용물을 꺼내는 기능의 메서드를 정의하자'
그러나 현재는 매개변수 box를 대상으로 get은 물론 set의 호출도 가능합니다.
public static void outBox(Box<Toy> box) {
Toy toy = box.get(); // 꺼내는 것! OK!
box.set(new Toy()); // 넣는 것! 이것도 OK!
}위와 같은 실수는 누구나 할 수 있지만 이러한 오류는 컴파일 과정에서 발견되지 않습니다.
다음과 같이 매개변수를 선언하면 상자에서 꺼내는 것은 가능하지만 넣는 것은 불가능하게 됩니다. 넣으려고 하면 컴파일 오류가 발생합니다.
public static void outBox(Box<? extends Toy> box) {
Toy toy = box.get(); // 꺼내는 것! OK!
box.set(new Toy()); // 넣는 것! ERROR!
}위의 상황에서 set 메서드의 호출이 불가능한 이유는 위 메서드의 매개변수로 Toy 인스턴스를 저장할 수 있는 상자만(Box<T> 인스턴스만) 전달된다는 사실을 보장할 수 없기 때문입니다.
Toy 클래스는 다음과 같이 다른 클래스들에 의해 얼마든지 상속이 될 수 있습니다.
class Car extends Toy { ... }
class Robot extends Toy { ... }그리고 이렇게 상속 관계를 맺으면 위의 outBox메소드에 Box<Car> 또는 Box<Robot> 인스턴스가 인자로 전달될 수 있습니다. 이러한 상황에서 다음과 같이 Toy인스턴스를 상자에 담을 수 있을까요?
public static void outBox(Box<? extends Toy> box) {
// box로 Box<Car> 또는 Box<Robot> 인스턴스가 전달된다면?
box.set(new Toy()); // 넣는 것! ERROR!
}바로 이러한 문제점 때문에 다음과 같이 선언된 매개변수를 대상으로는 저장하는(전달하는) 메서드의 호출이 불가능 합니다.
Box<? extends Toy> box
정리하자면 다음과 같은 매개변수 선언을 보았을 때,
public static void outBox(Box<? extends Toy> box) {
/*
이 안에서는 box가 참조하는 인스턴스에
Toy 인스턴스를 저장하는(전달하는) 메서드 호출은 불가능하다.
*/
}"box가 참조하는 인스턴스를 대상으로 저장하는 기능의 메서드 호출은 불가능하다." 라는 판단을 할 수 있어야 합니다.
class Box<T> {
private T ob;
public void set(T o) { ob = o; }
public T get() { return ob; }
}
class Toy {
@Override
public String toString() {
return "I am a Toy";
}
}
class BoxHandler {
public static void outBox(Box<? extends Toy> box) {
Toy toy = box.get(); // 상자에서 꺼내기
System.out.println(toy);
}
public static void inBox(Box<Toy> box, Toy toy) {
box.set(toy); // 상자에 넣기
}
}하한 제한의 목적
이번에는 다음 메서드를 봅시다.
class BoxHandler {
public static void inBox(Box<Toy> box, Toy toy) {
box.set(toy); // 상자에 넣기
}
}위의 inBox 메서드도 좋은 코드가 되기 위한 다음 조건을 만족하지 못 합니다.
"필요한 만큼의 기능을 허용하여, 코드의 오류가 컴파일 과정에서 최대한 발견되도록 한다."
이 메서드는 상자에 인스턴스를 저장하는 것이 목적이니, 다음과 같이 get 메서들르 호출하는 코드가 삽입된다면 이는 분명 프로그래머의 실수입니다.
public static void inBox(Box<Toy> box, Toy toy) {
box.set(toy); // 넣는 것! OK!
Toy myToy = box.get(); // 꺼내는 것! 이것도 OK!
}그러나 이러한 실수는 컴파일 과정에서 발견되지 않습니다. 따라서 이러한 실수가 컴파일 과정에서 발견될 수 있도록 매개변수를 다음과 같이 선언해야 합니다.
public static void inBox(Box<? super Toy> box, Toy toy) {
box.set(toy); // 넣는 것! OK!
Toy myToy = box.get(); // 꺼내는 것! ERROR!
}위와 같이 매개변수를 선언하면 get 메서드의 호출문에서 컴파일 오류가 발생합니다. 이유는 반환형을 Toy로 결정할 수 없기 때문입니다. 즉 get 메서드 호출 자체는 문제되지 않으나, 반환되는 값을 저장하기 위해 선언한 참조변수 형을 Toy로 결정했다는 사실에서 문제가 발생합니다.
Toy 클래스의 상속관계가 다음과 같다고 가정합시다.
class Plastic { ... }
class Toy extends Plastic { ... }그러면 inBox 메서드의 첫 번째 인자로 전달 가능한 두 가지 유형의 Box<T> 인스턴스는 Box<Toy>, Box<Plastic> 입니다.
inBox 메서드에 인자로 Box<Toy> 의 인스턴스가 전달되면 메서드 내에서 다음 문장을 실행하는데 문제가 없지만,
// get이 반환하는 것이 Toy 인스턴스이므로 문제가 없음
Toy myToy = box.get();Box<Plastic> 의 인스턴스가 전달되면 메서드 내에서 다음 문장을 실행하는데 있어서 문제가 됩니다. 그래서 컴파일러는 이 문장 자체를 허용하지 않습니다.
// get이 반환하는 것이 Plastic 인스턴스이므로 문제가 됨
Toy myToy = box.get();정리하자면 다음과 같은 매개변수 선언을 보았을 때,
public static void inBox(Box<? super Toy> box, Toy toy) {
/*
이 안에서는 box가 참조하는 인스턴스에서
Toy 인스턴스를 꺼내는(반환하는) 메서드 호출은 불가능하다.
*/
}"box가 참조하는 인스턴스를 대상으로 꺼내는 기능의 메서드 호출은 불가능하다" 라는 판단을 할 수 있어야 합니다.
class Box<T> {
private T ob;
public void set(T o) { ob = o; }
public T get() { return ob; }
}
class Toy {
@Override
public String toString() {
return "I am a Toy";
}
}
class BoxHandler {
public static void outBox(Box<? extends Toy> box) {
Toy toy = box.get(); // 상자에서 꺼내기
System.out.println(toy);
}
public static void inBox(Box<? super Toy> box, Toy toy) {
box.set(toy); // 상자에 넣기
}
}참조변수를 Object형으로 선언한다면
public static void inBox(Box<? super Toy> box, Toy toy) {
Object myToy = box.get();
}위의 메서드 정의는 컴파일이 됩니다. 그러나 자바는 Object형 참조변수의 선언이나 Object형으로의 형 변환이 불필요하도록 문법을 개선시켜 봤습니다. Object라는 이름이 코드에 직접 등장하는 것은 컴파일러를 통한 오류의 발견 가능성을 낮추는 행위이기 때문입니다. 그러므로 지금 설명하는 부분에서 참조변수를 Object형으로 선언하는 것은 논외로 해야하며, 동시에 당연히 피해야할 일입니다.
제한된 와일드카드 선언을 갖는 제네릭 메서드
앞서 Toy 클래스를 담은 상자를 기준으로 inBox, outBox 메서드를 정의하였습니다.
class BoxHandler {
public static void outBox(Box<? extends Toy> box) {
Toy toy = box.get(); // 상자에서 꺼내기
System.out.println(toy);
}
public static void inBox(Box<? super Toy> box, Toy toy) {
box.set(toy); // 상자에 넣기
}
}위의 두 메서드는 Box<Toy> 인스턴스를 대상으로 정의된 메서드 입니다. 이 상황에서 다음 클래스를 정의했다고 가정해봅시다.
class Robot { ... }그리고 Box<Robot>의 인스턴스를 대상으로 outBox, inBox 메서드를 호출하고 싶다면, 오버로딩을 하여 메서드를 정의하는 방법을 고려할 수 있습니다.
public static void outBox(Box<? extends Toy> box) { ... }
public static void outBox(Box<? extends Robot> box) { ... }public static void inBox(Box<? super Toy> box, Toy n) { ... }
public static void inBox(Box<? super Robot> box, Robot n) { ... }그 이유는 자바는 제네릭 등장 이전에 정의된 클래스들과의 상호 호환성 유지를 위해 컴파일 시 제네릭과 와일드카드 관련 정보를 지우는 과정을 거치는데, 그로 인해 위의 두 매개변수 선언은 컴파일 과정에서 다음과 같이 수정되고 이로 인해 메소드의 오버로딩이 성립 불가능한 상태가 됩니다.
그런데 다음 두 메서드 정의는 오버로딩이 성립하지 않습니다.
해결책
위와 같은 상황을 해결하는 답은 '제네릭 메서드'에 있습니다.
class BoxHandler {
public static <T> void outBox(Box<? extends T> box) {
T t = box.get();
System.out.println(t);
}
public static <T> void inBox(Box<? super T> box, T n) {
box.set(n);
}
}컬렉션 프레임워크
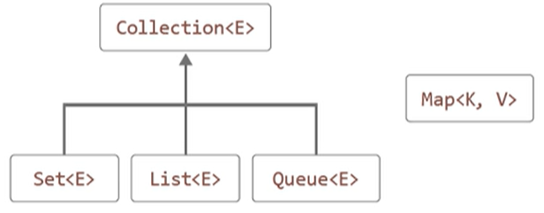
List 인터페이스
List<E>인터페이스를 구현하는 대표적인 컬렉션 클래스
ArrayList<E>: 배열 기반 자료구조LinkedList<E>: 리스트 기반 자료구조
List<E>인터페이스를 구현하는 클래스들의 공통 특성
- 인스턴스의 저장 순서 유지
- 동일 인스턴스의 중복 저장을 허용한다
ArrayList<E>의 단점
-- 저장 공간을 늘리는 과정에서 시간이 비교적,많이 소요된다
-- 인스턴스의 삭제 과정에서 많은 연산이 필요할 수 있다. 따라서 느릴 수 있다
ArrayList<E>의 장점
-- 저장된 인스턴스의 참조가 빠르다.
LinkedList<E>의 단점
-- 저장된 인스턴스의 참조 과정이 배열에 비해 복잡하다. 따라서 느릴 수 있다
LinkedList<E>의 장점
-- 저장 공간을 늘리는 과정이 간단하다.
-- 저장된 인스턴스의 삭제 과정이 단순한다.
반복자로 순차적 접근(Iterable, Iterator)
Iterator<String> itr = list.iterator(); // 반복자 획득
while(itr.hasNext()) { // next 메소드가 반환할 대상이 있다면
str = itr.next(); // next메소드를 호출한다.
}
}Iterator 반복자의 세 가지 메소드
- E next() : 다음 인스턴스의 참조 값을 반환
- boolean hasNext() : next 메소드 호출 시 참조 값 반환 가능 여부 확인
- void remove() : next 메소드 호출을 통해 반환했던 인스턴스 삭제
다음 두 가지 이유로 배열보다 ArrayList<E>가 더 좋다.
-- 인스턴스의 저장과 삭제가 편하다.
-- 반복자를 쓸 수 있다.
List는 배열처럼 선언과 동시에 초기화가 불가능하다. 다만 다음으로 가능
List<String> list = Arrays.asList("Toy","Robot","Box");
// 인자로 전달된 인스턴스들을 저장한 컬렉션 인스턴스의 생성 및 반환
// 이렇게 생성된 리스트 인스턴스는 Immutable 인스턴스이다.
list = new ArrayList<>(list);
// 수정하고싶으면 위와같이 새롭게 생성리스트만 갖는 양방향 반복자
ListIterator<String> litr = list.listIterator();
// List<E> 인터페이스의 메소드- E previous() : next 메소드와 기능은 같고 방향만 반대
- boolean hasPrevious() : hasNext 메소드와 기능은 같고 방향만 반대
- void add(E e) : 인스턴스의 추가
- void set(E e) : 인스턴스의 변경
while(itr.hasNext()) {
str = str.next();
if(str.eqals("Box))
itr.remove(); // 위에서 next 메소드가 반환환 인스턴스 제
}Set 인터페이스
HashSet<E>인터페이스의 특성
- 저장 순서가 유지되지 않는다.
- 데이터의 중복 저장을 허용하지 않는다.
Set<String> set = new HashSet<>();해쉬 알고리즘의 이해

class Num{
private int num;
public Num(int n) {num = n;}
@Override
public String toString() { return String.valueOf(num);
@Override
public int hashCode() {
return num % 3;
}
@Override
public boolean equals(Object obj) {
if(num == ((Num)obj.num)
return true;
else
return false;
}
}TreeSet<E> 클래스
Set<E> 인터페이스를 구현하는 TreeSet<E> 클래스
-- 트리 자료구조를 기반으로 인스턴스를 저장, 이는 정렬 상태가 유지되면서 인스턴스가 저장됨을 의미
TreeSet<Integer> tree = new TreeSet<Integer>();그렇다면 인스턴스의 크고 작음에 대한 기준을 프로그래머가 정해주어야 한다.
public interface Comprable<T>
-> 이 인터페이스에 위치한 유일한 추상 메소드 int compareTo(T o)Comparable<T> 인터페이스를 구현할 때 정의해야 할 추상 메소드는
int compareTo(T o)
이 메소드의 정의 방법
- 인자로 전달된 o가 작다면 양의 정수 반환
- 인자로 전달된 o가 크다면 음의 정수 반환
- 인자로 전달된 o와 같다면 0을 반환
TreeSet 인스턴스에 저장될 것을 고려한 클래스의 예
class Person implements Comparable<Person> {
private String name;
private int age;
@Override
public int compareTo(Person p) {
return this.age - p.age;
}
}따라서 TreeSet<T>에 저장할 인스턴스들은 모두 Comparable<T> 인터페이스를 구현한 클래스 인스턴스이어야 한다.
Queue 인터페이스
스택과 큐의 이해
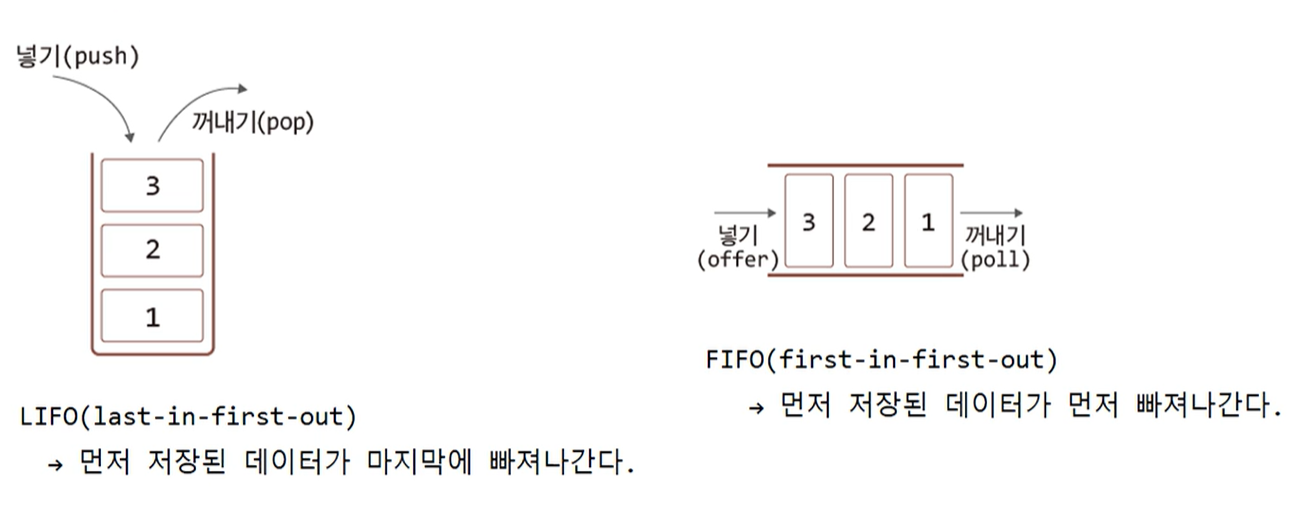
Queue<E>인터페이스의 메소드들
예외처리를 반환
- boolean add(E e) : 넣기
- E remove() : 꺼내기
- E element() : 확인하기
값을 반환
- boolean offer(E e) : 넣기, 넣을 공간이 부족하면 false 반환
- E poll() : 꺼내기, 꺼낼 대상 없으면 null 반환
- E peek() : 확인하기, 확인할 대상이 없으면 null 반환
Queue<String> que = new LinkedList<>();
// LinkedList<E>는 List<E>와 동시에 Queue<E>를 구현하는 컬렉션 클래스다.스택의 구현
Deque(덱)을 기준으로 스택을 구현하는것이 원칙
Deque<E> 인터페이스의 메소드
값 반환
- boolean offerFirst(E e) : 넣기, 공간 부족하면 false 반환
- E pollFirst() : 꺼내기, 꺼낼 대상 없으면 null 반환
- E peekFirst() : 확인하기, 확인할 대상 없으면 null 반환
- boolean offerLast(E e) : 넣기, 공간 부족하면 false 반환
- E pollLast() : 꺼내기, 꺼낼 대상 없으면 null 반환
- E peekLast() : 확인하기, 확인할 대상 없으면 null 반환
예외 반환
- void addFirst(E e) : 넣기
- E removeFirst() : 꺼내기
- E getFirst() : 확인하기
- void addLast(E e) : 넣기
- E removeLast() : 꺼내기
- E getLast() : 확인하기
Map 인터페이스
HaspMap<K,V> 클래스
HashMap<Integer, String> map = new HashMap<>();
// key-value 기반 데이터 저장
map.put(45, "Brown");
map.put(37, "James");
map.put(24, "Martin");HashMap<K,V>클래스는 Iterable<T>인터페이스를 구현하지 않으니
for-each문을 통해서, 혹은 반복자를 얻어서 순차적 접근이 불가능하다.
대신 Key를 따로 모아 놓은 컬렉션 인스턴스를 얻을 수 있다.
그리고 이때 반환된 컬렉션 인스턴스를 대상으로 반복자를 얻을 수 있다.
public Set<K> KeySet()
// key만 담고 있는 컬렉션 인스턴스 생성
Set<Integer> ks = map.keySet();
// 전체 key 출력 (for-each문 기반)
for (integer n : ks)
System.out.println(n.toString() + '\t';
System.out.println();
// 전체 value 출력 (for-each문 기반)
for (integer n : ks)
System.out.println(n.toString() + '\t';
System.out.println();
// 전체 value 출력(반복자 기반)
for(Iterator<Integer> itr = ks.iterator(); itr.hasNext(); )
System.out.println(map.get(itr.next()) + '\t');
System.out.println();Set<E>는 Iterable<E>를 상속하므로 for-each문을 통하거나 또는 반복자를 얻어서 순차적 접근을 진행할 수 있다.
TreeMap<K,V> 클래스
Hashmap과 다를거 없이 정렬 기준만 다르다.
컬렉션 기반 알고리즘
sort 메소드의 제네릭 선언
// 임시
public static <T extends Comparable<T>> void sort(List<T> list)
// 실제
public static <T extends Comparable<? super T>> void sort(List<T> list)열거형, 가변 인자, 어노테이션
열거형
enum Scale { // 열거 자료형 Scale의 정의
DO, RE, MI, FA
}참조변수도 선언이 가능하다.
Scale sc = Scale.DO;
클래스 내에서도 열거형 정의 가능
class Customer {
enum Gender {
MALE, FEMALE
// 클래스 내에서만 사용 가능
}열거형의 정의에도 생성자가 없으면 디폴트 생성자가 삽입된다.
다만 이 생성자는 private으로 선언이 되어 직접 인스턴스를 생성하는 것이 불가능하다.
enum Person {
MAN, WOMAN;
private Person() {
System.out.println("Person constructor called");
}매개변수의 가변 인자 선언과 호출
class Varargs {
// vargs참조변수로 가변인자를 받으며 몇개든 간의 다 받아들이고 배열로 간주
public static void showAll(String...vargs) {
System.out.println("LEN: " + vargs.length);
for(String s : vargs)
System.out.print(s+ '\t');
System.out.println();
}
public static void main(String[] args) {
showAll("Box"); // new String[]{"Box"});
showAll("Box","Toy"); // new String[]{"Box","Toy"});
showAll("Box","Toy","Apple");
// new String[]{"Box","Toy","Apple"});
}
}
네스티드(Nested) 클래스와 이너(Inner) 클래스
네스티드 클래스
클래스 안에 정의된 클리이스이다.
class Outer{ // 외부 클래스
class Nexted{...} // 네스티드 클래스
}네스티드 클래스는 두종류로 나뉘는데
- static이 붙은 클래스 : static 네스티드 클래스
- static이 붙지 않은 클래스 : Non-static 네스티드 클래스
(이너 클래스라고도 부름)
이너 클래스는 다시 정의되는 위치나 특성에 따라 세종류로 나뉘어진다
- 멤버 클래스 : Member class
-- 인스턴스 변수, 인스턴스 메소드와 동일한 위치에 정의 - 로컬 클래스 : Local class
-- 중괄호 내에, 특히 메소드 내에 정의 - 익명 클래스 : Anonymouts class
-- 클래스인데 이름이 없는 것
멤버 클래스
멤버 클래스의 인스턴스는 외부 클래스의 인스턴스에 종속적이다.
class Outer {
private int num = 0;
class Member { // 멤버 클래스 정의
void(int n) { num += n; }
int get() { return num; }
}
}
class MemberInner {
public static void main(String[] args) {
Outer o1 = new Outer();
Outer o2 = new Outer();
// o1기반으로 두 인스턴스 생성
Outer.Member o1m1 = o1.new Member();
Outer.Member o1m2 = o1.new Member();
// o2기반으로 두 인스턴스 생성
Outer.Member o2m1 = o2.new Member();
Outer.Member o2m2 = o2.new Member();
// o1기반으로 생성된 두 인스턴스의 메소드 호출
o1m1.add(5);
System.out.println(o1m2.get());
// o2기반으로 생성된 두 인스턴스의 메소드 호출
o2m1.add(7);
System.out.println(o2m2.get());
}
}멤버 클래스는 언제 사용하는가?
멤버 클래스는 클래스의 정의를 감추어야 할 때 유용하게 사용이 된다.
알아야 할 클래스의 개수가 줄어둠
interface Printable {
void print();
}
class Papers {
private String con;
public Papers(String s) { con = s; }
public Printable getPrinter() {
return new Printer();
}
// 멤버 클래스를 감춤
private class Printer implements Printable {
public void print() {
System.out.println(con);
}
}
}
public static void main(String[] args) {
Papers p = new Papers("서류 내용");
Printable prn = p.getPrinter();
prn.print();
}
// 클래스 사용자 입장에서 Printable 인터페이스는 알지만
// Printer 클래스는 모르며, 알 필요도 없다.로컬 클래스
로컬 클래스는 멤버클래스와 비슷하다.
interface Printable { void print(); }
class Papers {
private String con;
public Papers(String s) { con = s; }
public Printable getPrinter() {
// 메소드 안으로 넣음
class Printer implements Printable {
public void print() {
System.out.println(con);
}
}
return new Printer();
}
}익명 클래스
public Printable getPrinter() {
class Printer implements Printable {
public void print() {
System.out.println(con);
}
}
return new Printer();
}
1. 인터페이스의 이름으로 객체를 생성한다.
2. 인터페이스의 내용을 넣어준다.
// 익명 클레스로 바꿈
public Printable getPrinter() {
// Printable인터페이스를 구현한 인스턴스를 만들기 위함
return new Printable() {
// Printable 인터페이스의 내용을 넣어줘야함
public void print() {
System.out.println(con);
}
};람다
interface Printable{ void print(String s); }
Printable prin = new Prinatable() {
public void print(String s) {
System.out.println(s);
}
}
// 컴파일러가 s가 매개변수라고 판단해 주길 바라는것은 무리니까
Printable prn = (String s) -> { System.out.println(s); };
// s가 string형 임은 Printable 인터페이스를 보면 알 수 있으니까
// 최종 람다식
Printable prn = (s) -> {System.out.println(s); };
Printable prn = s -> System.out.println(s);정의되어 있는 함수형 인터페이스
Pridicate<T>
- boolean test(T t)
전달 인자를 근거로 참 또는 거짓을 반환
Suplier<T>
- T get()
메소드 호출 시 무엇인가를 제공함
Comsumer<T>
- void accept(T t)
무엇인지를 받아 들이기만 함
Function<T, R>
- Function<T, R>
입출력 출력이 있음
메소드 참조와 Optional
메소드 참조의 4가지 유형
- static 메소드의 참조
- 참조변수를 통한 인스턴스 메소드 참조
- 클래스 이름을 통한 인스턴스 메소드 참조
- 생성자 참조
static 메소드의 참조
class ArrangeList {
public static void main(String[] args) {
List<Integer> ls = Arrays.asList(1, 3, 5, 7, 9);
ls = new ArrayList<>(ls);
// 람다식
Comsumer<List<Integer>> c = 1 -> Collections.reverse(1);
// Collection::reverse
c.accept(ls); // 순서 뒤집기 진행
System.out.println(ls); // 출력
}
}Optional 클래스
Iterable을 메소드의 반환 타입으로 사용하는 이유
클래스마다 자료구조 방식이 다르니까 반복자로 기준을 정해줘서
각자 다른 자료구조에 인스턴스를 참조할수 있게 된다. 다시 말해서
for-each문을 통한 순차적 접근의 대상이 되기 위한 조건이 컬렉션 클래스가 Iterable 인터페이스를 구현해야 한다
Collection 인터페이스가 Iterable를 상속하니까 메소드 반환타입에도 제한없이 받아들이기 위해서 Iterable 타입으로 하는것
-
유연성과 호환성
Iterable은 컬렉션 프레임워크의 일반적인 인터페이스입니다.
이는 메소드가 구체적인 컬렉션 유형을 반환하지 않고도 여러 종류의 컬렉션을 반환할 수 있도록 해줍니다.
이렇게 함으로써 클라이언트 코드가 특정 컬렉션 유형에 의존하지 않고 메소드를 사용할 수 있습니다. -
코드 재사용
메소드가 Iterable을 반환하면, 해당 메소드는 컬렉션을 직접 만들어 반환할 필요가 없습니다. 대신, 이미 존재하는 컬렉션을 반환하거나, 컬렉션을 생성하는 다른 메소드를 호출하여 그 결과를 반환할 수 있습니다. 이는 코드를 더 간결하게 만들고, 유지보수를 쉽게 해줍니다. -
확장성
반환 타입으로 Iterable을 사용하면, 나중에 컬렉션의 구현을 변경하더라도 클라이언트 코드를 변경할 필요가 없습니다. 예를 들어, 메소드가 List를 반환하도록 구현되어 있다면, 나중에 Set으로 변경하고 싶을 때 클라이언트 코드도 변경해야 합니다. 하지만 Iterable을 사용하면 이러한 변경이 더 쉬워집니다. -
효율성
Iterable은 컬렉션을 순회할 수 있는 인터페이스를 제공하므로, 메소드가 반환한 컬렉션을 반복해서 사용할 수 있습니다. 이는 메모리 사용량과 성능을 향상시킬 수 있습니다. 예를 들어, 한 번에 모든 요소를 반환하는 대신 필요한 만큼 요소를 반복적으로 가져올 수 있습니다.
따라서 Iterable을 반환 타입으로 사용함으로써 코드의 유연성, 재사용성, 확장성 및 효율성을 향상시킬 수 있습니다.
