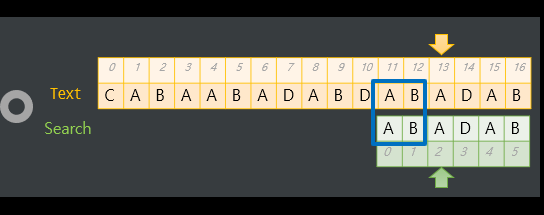
개념
커누스-모리스-프랫 알고리즘(Knuth–Morris–Pratt algorithm, KMP)은 lps(접두사와 접미사가 일치하는 최대길이 배열)을 사용하여 문자열 중에 특정 패턴을 찾아내는 문자열 검색 알고리즘
구현과정
1.패턴의 lps생성
2.전체 문자열과 패턴문자열 비교
3.문자열과 패턴문자열이 같아질때까지 lps최신화(최대한 겹치는 접미사가 있는지 확인하는 과정)
4.패턴문자열의 인덱스가 패턴길이와 같다면 문자열 찾기 성공
시간복잡도
전체 문자열을 탐색하며 특정 패턴의 문자열만 비교하기 때문에 O(N+M)이다.기존의 단순 탐색 시간복잡도인 O(N*M)과 비교하면 큰 성능차이를 보여준다.
코드
import time
import random
import string
def computeLPS1(pattern):
pi = [0] * len(pattern)
j=0
for i in range(1, len(pi)): # i끝, j앞
while j > 0 and pattern[i] != pattern[j]:
j = pi[j - 1] #순간이동
if pattern[i] == pattern[j]:
j += 1
pi[i] = j
return pi
def KMPSearch1(word, pattern):
pi = computeLPS1(pattern)
results = []
j=0
for i in range(len(word)): #i word, j pattern
while j > 0 and word[i] != pattern[j]:
j = pi[j - 1]
if word[i] == pattern[j]:
if j==len(pattern)-1:
results.append(i-len(pattern)+1)
j=pi[j]
else:
j+=1
return results
n=10000000
rand_str = ""
for i in range(n):
rand_str += str(random.choice(string.ascii_lowercase))
txt=rand_str
pat ="abc"
start = time.time()
kmp1_result=KMPSearch1(txt, pat)
print(len(kmp1_result))
print(time.time() - start)출력
571
0.8948123455047607*1000000개의 랜덤한 문자열에서 abc라는 문자열을 찾는데 0.9초가 걸린다.
단순 문자열찾기,find메서드,kmp알고리즘의 비교
import time
import random
import string
def computeLPS1(pattern):
pi = [0] * len(pattern)
j=0
for i in range(1, len(pi)): # i끝, j앞
while j > 0 and pattern[i] != pattern[j]:
j = pi[j - 1] #순간이동
if pattern[i] == pattern[j]:
j += 1
pi[i] = j
return pi
def KMPSearch1(word, pattern):
pi = computeLPS1(pattern)
results = []
j=0
for i in range(len(word)): #i word, j pattern
while j > 0 and word[i] != pattern[j]:
j = pi[j - 1]
if word[i] == pattern[j]:
if j==len(pattern)-1:
results.append(i-len(pattern)+1)
j=pi[j]
else:
j+=1
return results
def simple_for_find_pat(txt,pat):
result=[]
for i in range(len(txt)):
if pat==txt[i:i+len(pat)]:
result.append(i)
return result
def find_pat(txt,pat):
index = -1
result=[]
while True:
index =txt.find(pat, index + 1)
if index == -1:
break
pat_index=index
result.append(pat_index)
return result
n=10000000
rand_str = ""
for i in range(n):
rand_str += str(random.choice(string.ascii_lowercase))
txt=rand_str
pat ="abc"
start = time.time()
kmp1_result=KMPSearch1(txt, pat)
print(len(kmp1_result))
print(time.time() - start)
start = time.time()
simple_result=find_pat(txt, pat)
print(len(simple_result))
print(time.time() - start)
start = time.time()
find_result=simple_for_find_pat(txt, pat)
print(len(find_result))
print(time.time() - start)
출력
589
0.9308450222015381
589
0.005004405975341797
589
1.6393330097198486*위에서부터 차례대로 kmp,find메서드,단순찾기의 결과이다.성능순위는 find>kmp>단순찾기 이므로 find메서드는 kmp를 보다 효율적이게 구현하였거나 또는 좀더 빠른 알고리즘으로 구현한 듯하다.
크롤링된 문자열 속에서 특정 키워드가 들어간 문장 찾기
1.메인코드(크롤링+저장+키워드가 포함된 문장 찾기)
import aiohttp
import time
import asyncio
from get_book import get_book_request
import os
from bs4 import BeautifulSoup
from algos import *
import random
import string
import aiofiles
text_dir=os.getcwd()+"/texts/"
base_url="https://n.news.naver.com/mnews/article/"
#컨텐츠 분야에 따른 글의 주소
urls={
"politics":base_url+"018/0005500263?sid=100",
"economy":base_url+"310/0000107364?sid=101",
"society":base_url+"215/0001105445?sid=102",
"life":base_url+"052/0001892699?sid=103",
"science":base_url+"031/0000750057?sid=105",
"world":base_url+"421/0006845258?sid=104",
"book":"https://download.blog.naver.com/open/62f77ecede85865a7698f7c2fe1e6511baea13f7ef/vGXVqVMlXJWK4rHAjuX4ey2JSP81XhC_upd8RZr3qWIxOuBqyw4CD4BO38rGhXYiNj3mSHuEn1QhOCesPDG9QA/%28%ED%85%8D%EC%8A%A4%ED%8A%B8%EB%AC%B8%EC%84%9C%20txt%29%20%EC%9C%84%EB%8C%80%ED%95%9C%20%EC%9C%A0%EC%82%B0%20%28%EC%9A%B0%EB%A6%AC%EB%A7%90%20%EC%98%AE%EA%B9%80%29%282%EC%B0%A8%20%ED%8E%B8%EC%A7%91%EC%B5%9C%EC%A2%85%29%28%EB%B8%94%EB%A1%9C%EA%B7%B8%EC%97%85%EB%A1%9C%EB%93%9C%EC%9A%A9%202018%EB%85%84%20%EC%B5%9C%EC%A2%85%29%20180104.txt"
}
#기사의 줄바꿈 문장을 모두 제거 및 저장
def extract_text_from_article_and_save(html,content,text_dir):
soup=BeautifulSoup(html,'html.parser')
div_tag=soup.find("div","go_trans _article_content")
text=div_tag.get_text()
text=text.replace("\n","")
with open(text_dir+content+".txt","w",encoding='utf-8') as f:
f.write(text)
async def main():
file_contents=urls.keys()
#없는 텍스트만 다운주소추가
download_contens=[content for content in file_contents if not os.path.exists(text_dir+content+".txt")]
#다운로드를 해야할 것이 있을때만
if len(download_contens)>=1:
async with aiohttp.ClientSession() as session:
result=await asyncio.gather(*[get_book_request(session,urls[content],content) for content in download_contens])
for [res,content] in result:
#book의 주소로 크롤링한 파일은 인코딩 방식이 다르기 때문에 따로 디코드
if content=="book":
with open(text_dir+content+".txt","w",encoding='utf-8') as f:
text=res.decode('CP949')
removed_text=text.replace("\n","")
f.write(removed_text)
else:
extract_text_from_article_and_save(res,content,text_dir)
print("입력키워드를 입력해주세요:")
keyword=input()
print("입력한 키워드: ",keyword)
result={}
process_time=0
start = time.time()
#컨텐츠별 글 속에서 원하는 키워드가 들어간 문장을 찾음
for content in file_contents:
encoding_mode="utf-8"
with open(text_dir+content+".txt","r",encoding=encoding_mode) as f:
text=f.read()
start = time.time()
result[content]=kmp_search(text,keyword)
process_time+=time.time() - start
print("소요시간:",process_time)
for content in file_contents:
print(content)
print(result[content])
return
if __name__=="__main__":
asyncio.run(main())
*컨텐츠(운동,세계,과학,사회)마다 네이버의 기사 url을 저장 후 크롤링한다.만약 이미 컨텐츠.txt파일이 존재한다면 크롤링을 하지 않는다.
2.kmp알고리즘구현
def compute_lps(pat):
pi=[0]*len(pat)
j=0
for i in range(1,len(pi)):
while j>0 and pat[i]!=pat[j]:
j=pi[j-1]
if pat[i]==pat[j]:
j+=1
pi[i]=j
return pi
def kmp_search(txt,pat):
pi=compute_lps(pat)
j=0
results=[]
for i in range(len(txt)):
while j>0 and txt[i]!=pat[j]:
j=pi[j-1]
if txt[i]==pat[j]:
if j==len(pat)-1:
#"."문자 사이가 문장이므로 시작과 끝을 나누어 "."에 도달할 떄까지 증감 후 문장 추출
start_index=j
while (0<=start_index<len(txt)) and (txt[start_index]!="."):
start_index-=1
end_index=j
while (0<=end_index<len(txt)) and (txt[end_index]!="."):
end_index+=1
results.append(txt[start_index+1:end_index+1])
results.append(i)
j=pi[j]
else:
j+=1
return results
3.결과
입력키워드를 입력해주세요:
전쟁
입력한 키워드: 전쟁
소요시간: 0.09408450126647949
politics
['북한 김여정 노동당 부부장도 지난 1일 담화를 통해 “군사정찰위성은 머지않아 우주궤도에 정확히 진입하여 임무수행에 착수하게 될 것”이라며 “우리는 미국과의 대결의 장기성을 잘 알고있으며 전망적인 위협과 도전
들을 의식하고 포괄적인 방면에서 전쟁억제력제고에 모든것을 다해나갈 것”이라고 말하면서 2차 발사 의지를 재확인했다.']
economy
[]
society
[]
life
[]
science
[]
world
['헤비는 전쟁 초기 러시아군이 점령한 수미 지역의 한 마을 출신이다.', ' 그는 자신이 전쟁으로 가까운 사람들을 잃었으며, 지난해 9월에 군에 입대했다고 밝혔다.', '이어 "러시아군은 전문 군대이며, 방어선을 구축
하고 참호를 만드는 방법을 확실히 알고 있다"며 "그들의 장비는 현대적이지 않지만, 엄청난 양의 장비가 있어 전쟁을 계속하기에 충분하다"고 분석했다.', '이어 "러시아군은 전문 군대이며, 방어선을 구축하고 참호를
만드는 방법을 확실히 알고 있다"며 "그들의 장비는 현대적이지 않지만 엄청난 양의 장비가 있어 전쟁을 계속하기에 충분하다"고 분석했다.']
book
[' 그리고 펌블추크 씨와는 마치 전우(전쟁동료)와 전우가 헤어지는 것처럼 헤어졌다.', ' (전쟁 때 돈 쉽게 끌어 모으려고 만든 영국 중앙은행은 17세기 말에 설립된 이후 처음 몇 년을 제외하 곤 매년 거의 매년
부채기록을 갈아치우고 있었음.', ' 그 시의 구절 중에, “복수” 역을 맡은 웹슬 씨가 피로 얼룩진 자신의 칼을 천둥 속으로 내던지며 괴멸(멸망)적인 시선으로 전쟁 종결을 알리는 나팔을 집어드는 장면이 나오는데 그럴
때면 나는 그를 특히 존경했다.', '\n\u3000웹슬 씨는 캠버웰(런던남부)에서 온화하게 죽어가고 있었고, 보즈워스 필드(‘장미전쟁’이라는 영국내전 당시 리처드 3세라는 왕이 죽임을 당한 곳)에서는 사냥개들에게 미친
듯이 뒤쫓기고 있었으며, 글래스턴 베리(영국남서부의 도시, 영국최초로 그리스도교가 전파된 곳, 십자가에 못 박히신 그리스도의 피를 넣었다는 잔이 있었다고 하는 도시)에서는 극심한 고뇌로 몸부림 치고 있었다
.', ' 넷째 워털루(영국이 이긴 전쟁이름) 다리, 다섯째 웨스트민스터(의사당 있는 곳) 다리, 여섯째 복스홀(????) 다리까지.', ' 다 지나간 얘기지만)의 죽음을 그리고 있는 채색된 판화(그림)와 배의 진수식(
배를 물에 띄움)을 묘사하고 있는 판화와 쿡 선장의 군주인 ‘조지 3세’ 왕(미국독립전쟁 때 영국 왕)이 마부용 가발과 가죽반바 지와 ‘톱 부츠’(승마용 장화)를 착용한 채 윈저(영국왕궁) 테라스 위에서 있는 장면을 묘
사한 판화가 걸려 있었다.', ' 중국에 세력의 공백이 생기면 중국 쪽으로 서서히 밀려 들어오고 동유럽 쪽에 세력의 공백이 생기면 중국 대신 동유럽 쪽으로 서서히 밀려들면서 두 쪽 다 몇 천 년에 걸쳐 서서히 쇠락하
게 한 장 본인들임-_-;; 지속적인 대외전쟁에 남아날 강대국은 없음)족 역할을 하는 것을 보았지 뭐야.', ' “하지만 여전히 우리 영국인들에게 있어서 집은 자신의 ‘성’(왕이 사는 성)이잖 니, 성은 전쟁 시에도 부
수고 들어가는 곳이어선 안 되지.']
(coding_test_env) 
숲을 보는 코더