
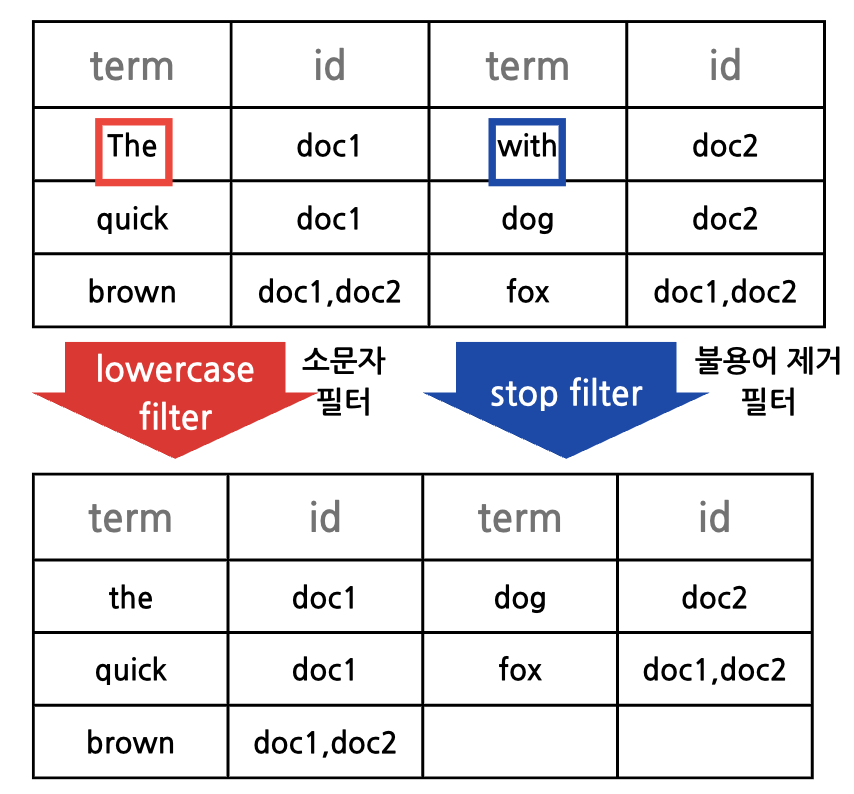
색인과 역 색인
색인과 역 색인의 차이점은 방향성
색인
- 특정한 데이터가 어느 위치에 있는지 미리 저장해두어 검색 시에 빠른
속도로 찾을 수 있도록 하는 것(인덱스에 자료를 매핑)
- 특정한 데이터가 어느 위치에 있는지 미리 저장해두어 검색 시에 빠른
역색인
- 데이터를 색인하는 과정에서 찾고자 하는 키워드를 기준으로 위치를 저장해두어 속도를 개선한 것(자료에 인덱스를 매핑)
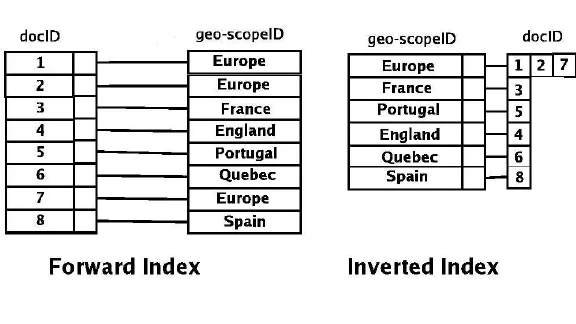
역색인의 필요성
한 개의 문장으로 이루어진 document들이 있을 때 dog란 단어가 나온 document들을 조회하려면 기존의 인덱스로는 모든 document들을 훑어보고 dog가 포함되어있으면 가져온다.하지만 역 색인을 이용한다면 아래의 인덱스 구조가 만들어진다.
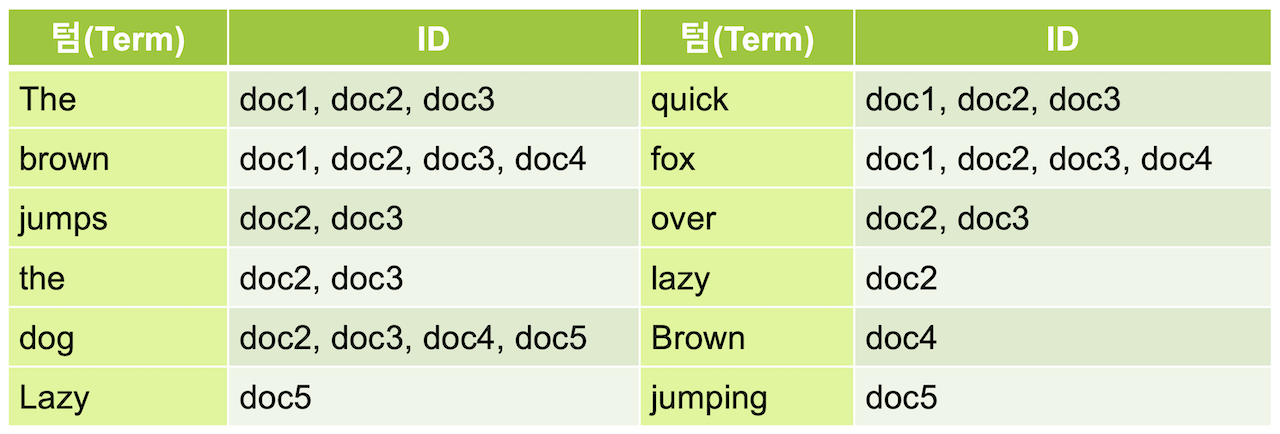
이미 단어에 자료에 매핑된 인덱스를 알고있기 때문에 dog라는 곳에서 doc2,doc3,doc4,doc5만 빠르게 접근해서 조회할 수 있다.
역 색인 과정
Elasticsearch는 문자열 필드가 저장될 때 데이터에서 검색어 토큰을 저장하기 위해 여러 단계의 처리 과정을 거친다. 이 전체 과정을 텍스트 분석(Text Analysis) 이라고 하고 이 과정을 처리하는 기능을 애널라이저(Analyzer) 라고 한다.
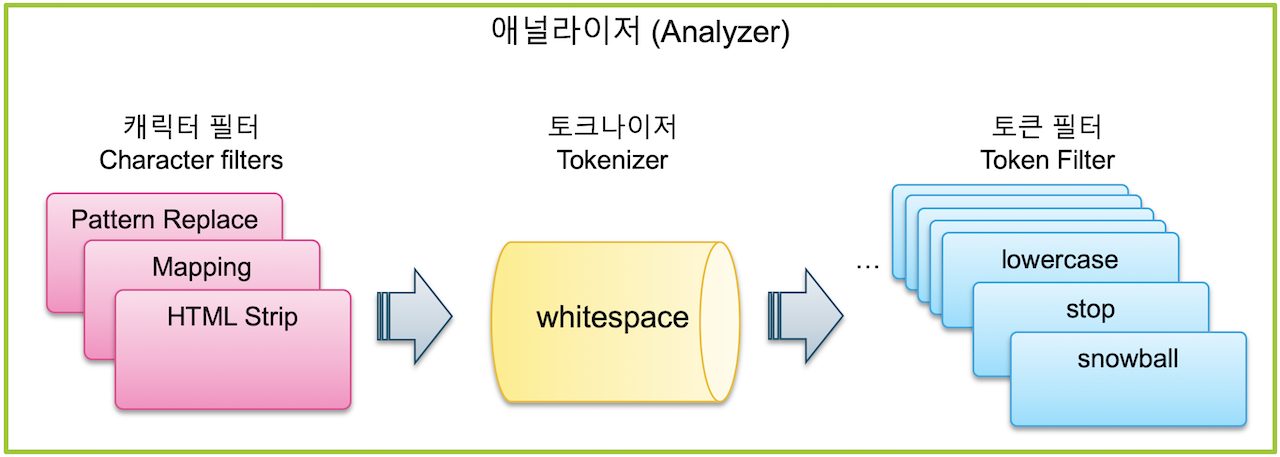
1.캐릭터 필터
전체 문장에서 특정 문자를 대치하거나 제거하는 과정

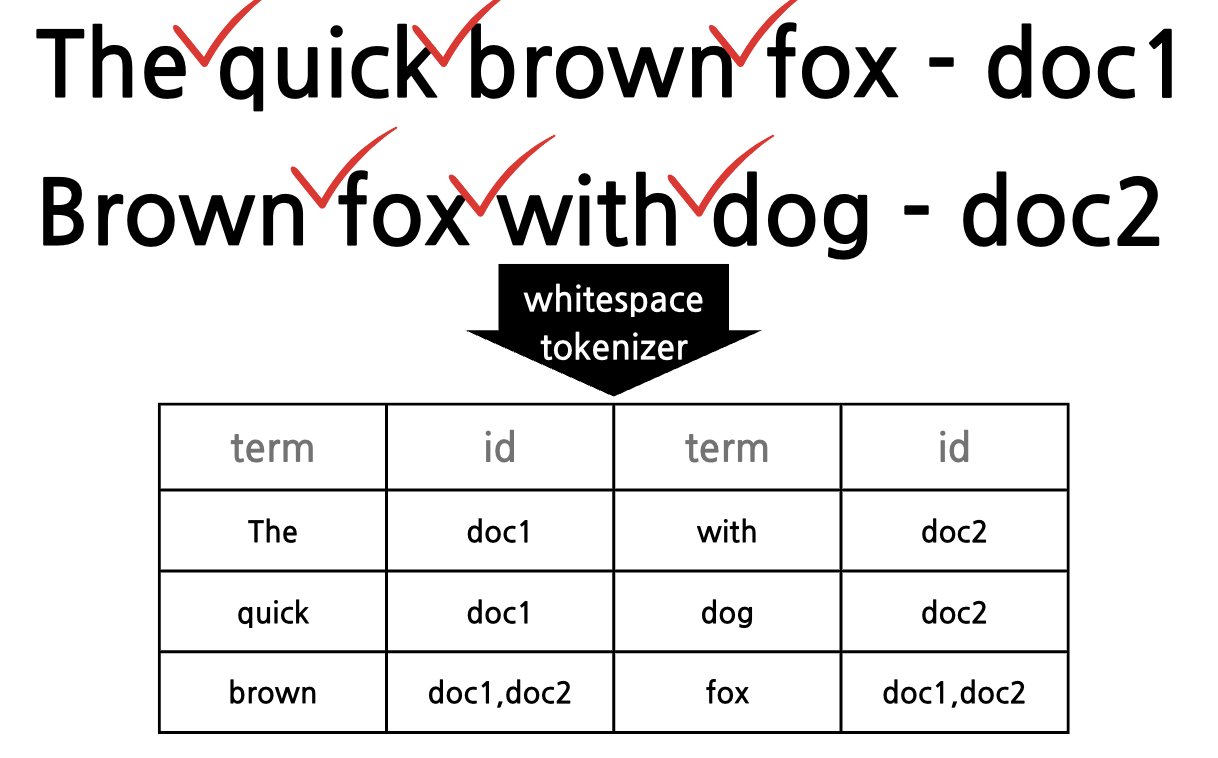
2.토크나이저
문장에 속한 단어들을 텀(키워드) 단위로 하나씩 분리 해 내는 처리 과정(토크나이저는 반드시 1개만 적용이 가능)
3.토큰 필터
분리된 텀 들을 하나씩 가공하는 과정
구현
길이가 긴 유튜브의 영상에서 원하는 키워드가 나온 시간들을 역색인을 활용하여 찾기
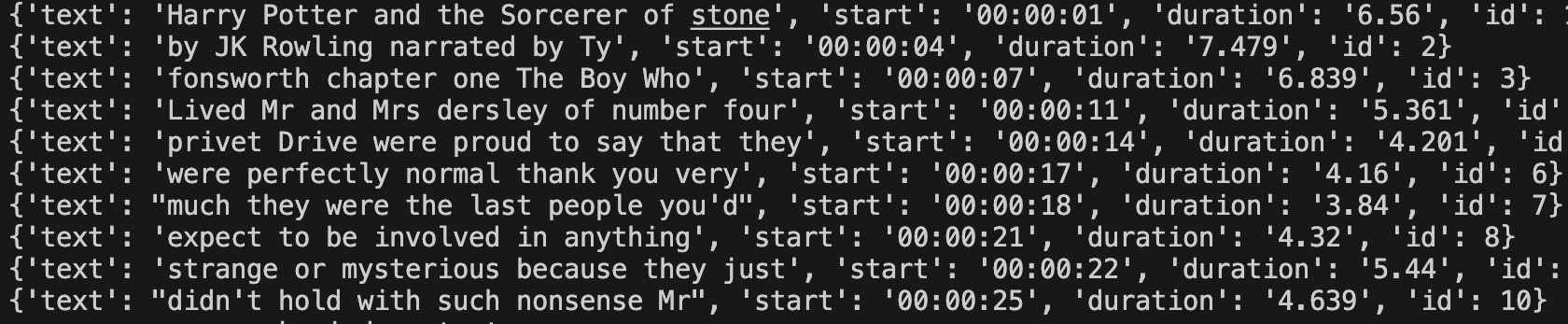
1. youtube_transcript_api를 이용한 영상 자막 변환
from youtube_transcript_api import YouTubeTranscriptApi as yta
import pickle
import os
harry_potter_dir = f"{os.getcwd()}/harry_potter"
def getScript():
if not os.path.isfile(f"{harry_potter_dir}/the_sorcerer's_stone.pickle"):
#해리포터와 마법사의 돌 영상 id
video_id = "R87MEJUfPxE"
transcript = yta.get_transcript(video_id, languages=("en", "English"))
for i in range(len(transcript)):
transcript[i]["id"] = i + 1
t = transcript[i]["start"]
#보기 쉬운 형태인 00:00형식의 시간으로 변경
hours = int(t // 3600)
min = int((t // 60) % 60)
sec = int(t % 60)
transcript[i]["start"] = str(f"{hours:02d}:{min:02d}:{sec:02d}")
transcript[i]["duration"] = str(transcript[i]["duration"])
with open(f"{harry_potter_dir}/the_sorcerer's_stone.pickle", "wb") as fw:
pickle.dump(transcript, fw)
with open(f"{harry_potter_dir}/the_sorcerer's_stone.pickle", "rb") as fr:
data = pickle.load(fr)
return data
2. 자료를 저장할 db 정의
import re
from essential_generators import DocumentGenerator
import math
import time
from getScriptFromYoutube import getScript
DG = DocumentGenerator()
class Appearance:
"""
document를 참조하는 id와 얼마나 자주 등장했는지를 나타낸 빈도를 저장하는 class
(1,13)->1번문서에 13번 등장
"""
def __init__(self, docId, frequency):
self.docId = docId
self.frequency = frequency
def __repr__(self):
"""
해당 객체의 변수들을 반환
"""
return str(self.__dict__)
class Database:
"""
인덱싱된 문서들의 실제 저장된 자료구조
"""
def __init__(self):
self.db = dict()
def __repr__(self):
"""
String representation of the Database object
"""
return str(self.__dict__)
def get(self, id):
# 해당 id를 조회
return self.db.get(id, None)
def add(self, document):
"""
# 해당 id를 갖는 문서를 삽입
"""
return self.db.update({document["id"]: document})
def remove(self, document):
"""
# 해당 id를 갖는 문서를 삭제
"""
return self.db.pop(document["id"], None)3. 엔덱스를 저장할 db 정의
class InvertedIndex:
"""
역색인 클래스
"""
def __init__(self, db):
# 인덱스를 저장하는 변수
self.index = dict()
self.db = db
def __repr__(self):
"""
String representation of the Database object
"""
return str(self.index)
def text_processing(self, text):
# 공백과 일반 문자(숫자포함)이 아닌 것을 없애는 작업(특수문자 삭제)
clean_text = re.sub(r"[^\w\s]", "", text)
# 소문자 변환
lowered_text = clean_text.lower()
# 공백 제거
terms = lowered_text.split(" ")
return terms
def index_document(self, document):
"""
주어진 문서를 인덱싱하고,Database에 저장
"""
# The,a등의 불용어 필터링과정도 추가해야함
appearances_dict = dict()
# 각 토큰의 빈도수를 계산하여 삽입 및 업데이트
for term in self.text_processing(document["text"]):
term_frequency = (
appearances_dict[term].frequency if term in appearances_dict else 0
)
appearances_dict[term] = Appearance(document["id"], term_frequency + 1)
update_dict = {
key: (
[appearance]
if key
not in self.index # 존재하지 않았던 키라면 바로 키와 appearance리스트 삽입
else self.index[key] + [appearance]
) # 이미 존재하던 키라면 해당 키값에 다른 appearance 추가 삽입
for (key, appearance) in appearances_dict.items()
} # 모든 토큰에 대해 순회
self.index.update(update_dict) # 현재 데이터 기준으로 업데이트
# db에 자료 추가
self.db.add(document)
return document
def lookup_query(self, query):
"""
입력받은 쿼리를 토큰화 하고 각 토큰들의 문서주소들을 인덱스에서 찾아 반환
"""
return {
term: self.index[term] for term in query.split(" ") if term in self.index
}4. 검색결과 시각화
def highlight_term(id, term, document):
replaced_text = document["text"].replace(
term, "\033[1;32;40m {term} \033[0;0m".format(term=term)
)
time_stamp = "\033[31m" + document["start"] + "\033[0;0m"
return "--- document {id}: {replaced} : time_stamp:{time_stamp}".format(
id=id, replaced=replaced_text, time_stamp=time_stamp
)5. Main구현
def main():
document_list = getScript()
db = Database()
index = InvertedIndex(db)
print("===============make index start=================")
start = time.time()
for document in document_list:
index.index_document(document)
end = time.time()
print("===============make index done=================")
print(f"index making time: {end - start:.5f} sec")
search_term = input("Enter term(s) to search: ").lower()
result = index.lookup_query(search_term)
print(result)
print("===============search query start=================")
start = time.time()
cnt = 0
for term in result.keys():
for appearance in result[term]:
cnt += 1
document = db.get(appearance.docId)
print(highlight_term(appearance.docId, term, document))
print("-----------------------------")
end = time.time()
print(f"===============search query end================= {cnt} docs was found")
print(f"search query time:{end - start:.5f} sec")6. harry라는 키워드를 검색

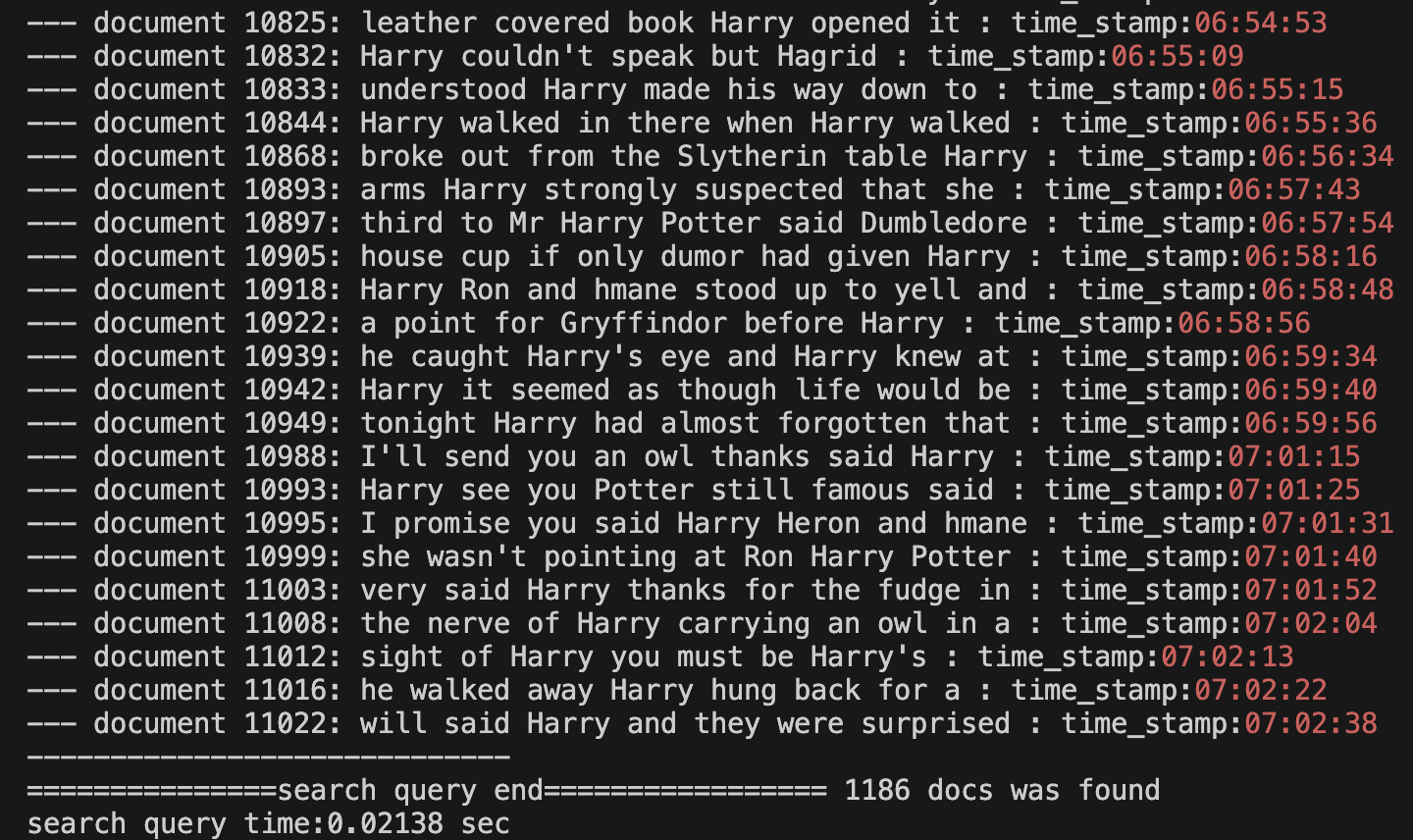
harry가 언급된 자막이 총 1186개의 문장들을 찾았고 0.02초가 소요되었다.
참조

숲을 보는 코더