Index
테이블에 대한 동작속도를 높여주는 자료구조를 말하며
무분별하게 적용하면 Insert, Update, Delete 등 시 성능에 악영향을 미친다.
RDB에서는 일반적으로 분포도가 좋은지?
수정이 빈번하게 발생되는 컬럼이 아닌지 등을 고려해서 설계한다.
그럼 많은 자료구조 중 B-Tree가 보편적으로 사용되는 이유와
다른 자료구조들에 대해서도 알아보자.B-Tree
B-Tree의 시간복잡도는 O(logN)이다
B-Tree보다 시간복잡도가 빠른 자료구조는 많다
대표적으로 해시 테이블은 O(1)인데, 왜 해시테이블을 보편적으로 안쓸까?
(물론 해시 충돌 같은 경우엔 최악의 경우에 O(N)이 될 수 있지만 평균적으로는 O(1)이라 볼 수 있다.)
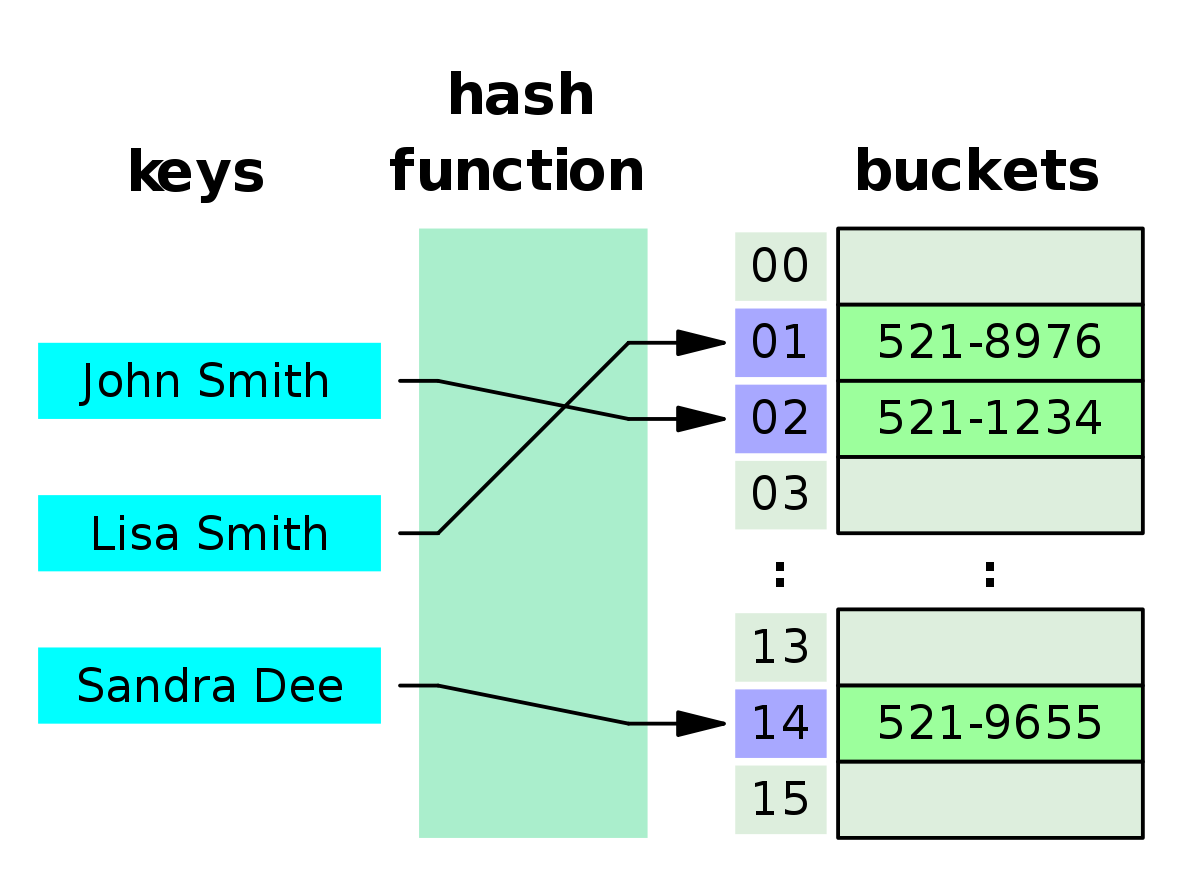
이유는 간단하다 예를 들어 데이터가 Hello,Hi,Bye가 저장되어 있는 해시 테이블에서 Hello라는 데이터를 찾을 경우 Hello라는 데이터의 해시값으로 저장된 메모리공간에 접근 할 것이기 때문에 Hello라는 데이터를 찾을 때만 O(1)인 것이다.
DB에서 데이터를 조회 할 때 등호(=) 뿐만 아니라 부등호(>,<)도 사용 된다는 점에서 탈락이다.
모든값이 정렬되어 있지 않은 자료구조 이므로 특정 기준보다 크거나 작은값을 찾는데 O(1)을 보장 할 수 없기 때문이다.
그래서 해시 알고리즘은 메모리 기반의 데이터베이스에서 많이 사용된다.
그렇다면 데이터 접근이 빠른 자료구조인 배열은 사용하지 않는 이유는 뭘까?
모든 데이터가 메모리 상 차례대로 저장되어 있어서 랜덤 엑세스를 활용해 접근이 빠르며 데이터들을 정렬 상태로 유지되어 있어서 부등호 연산에도 문제가 없다.
하지만 가장 큰 단점이 있다.
바로 데이터를 삽입, 삭제시 모든 데이터를 재 정렬 해야하므로 시간복잡도가 O(N)이 걸린다는 것이다.
그럼 이렇게 생각 하시는 분들이 있을 수 있다.
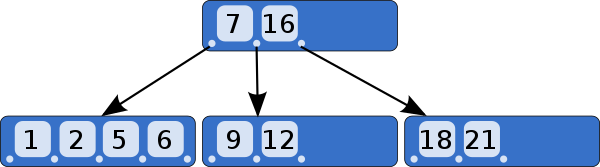
B-Tree도 각 노드들은 배열이 아닌가? 마찬가지로 노드가 무한정 늘어나면 최악의 경우 시간복잡도가 O(N)인 경우가 발생하는거 아니냐고 생각 할 수 있다.
하지만 B-Tree는 각 노드가 가질 수 있는 수를 제한한다. 가질 수 있는 최대 수를 넘어버리면 분할을 수행하기에 배열과 같은 문제가 발생할 일은 거의 없다.
그렇기에 항상 정렬된 상태로 부등호 연산에도 문제없고
대량의 데이터에도 빠르게 접근 할 수 있는 구조며 탐색 및 저장,수정,삭제 시에도 동일한 시간복잡도O(logN)를 보여주기에 보편적으로 선택된 이유라 볼 수 있다.
LSM-Tree
NoSql에서 주로 사용되는 되며
B-Tree보다 쓰기 성능이 월등히 좋은 자료구조이다.
작은 메모리 기반 컴포넌트와 큰 디스크 기반 컴포넌트로 구성된다
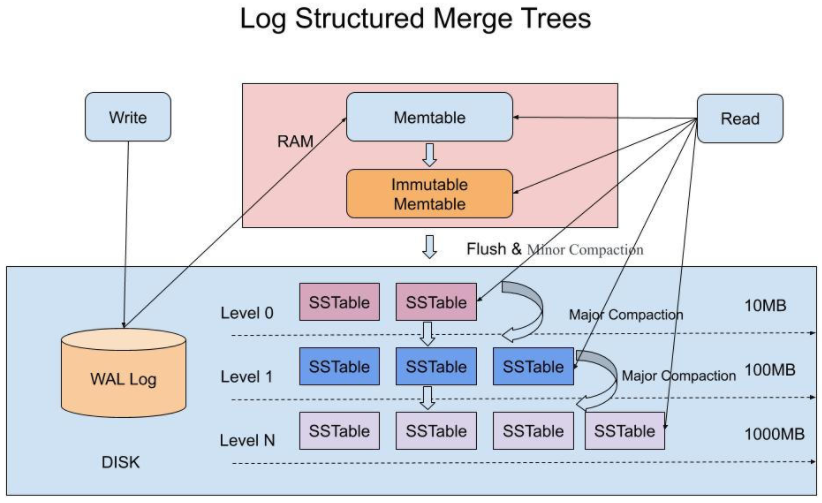
크게 Memtable, SSTable(세그먼트 파일)로 나누어 관리한다.
그리고 B-Tree와 다르게 데이터를 추가 및 수정시 Sequential으로 처리되기에 Random Write 보다 빠르다.
- 쓰기 요청이 왔을 경우
1. 인메모리 banlanced tree(순서를 유지하기 위해 red-black tree 등을 사용) 자료구조에 데이터를 저장한다. 이때 저장되는 곳을 Memtable라 한다.
2. Memtable이 특정 크기(세그먼트의 크기)를 초과하면 Immutable Memtable로 되고 새로운 Memtable이 생성된다.
3. Immutable Memtable은 SSTable로 flush하게 됩니다. 이때를 Minor Compaction이라 부른다.
4. Minor Compaction 후 첫번째 계층(Level)은 각 SSTable이 병합되지 않았으므로 중복된 Key들이 존재 한다.
5. SSTable의 디스크 각 계층(Level)의 볼륨을 일정 값을 초과하면 병합이 된다. 이때를 Major Compaction이라 부른다.
° 이때 Compaction작업은 쓰기작업의 성능 하락의 주요 원인이며 해결하기 위해 Compaction 관련 다양한 자료구조를 사용하고 있다 Leveled Compaction 등
- 읽기 요청이 왔을 경우
Memtable에서부터 키를 찾으며 없으면 최신 SSTable부터 차례대로 키를 찾을때까지 반복합니다.
° 없는 키를 조회할땐 최악이다. 이러한 해결 방안으로 Bloom Filter(확률적으로 해당 키가 있는지 없는지 알려주는 자료구조)등 을 사용하기도 한다.
B-Tree가 읽기,쓰기 등에서 안정적인 퍼포먼스를 보여주는 반면에
Lsm-Tree는 Compaction시 lag을 발생시키기에 읽기,쓰기 퍼포먼스가 불안정해진다. (읽기도 기본적으로 O(N)이지만 인덱스,캐시 최적화시 O(logN))
그러므로 Compaction시엔 많은 CPU와 스토리지 IO를 소모하기에 멀티 코어 환경의 SSD 저장 장치 기반 서버 환경에서 성능이 극대화 된다.
Fractal-Tree
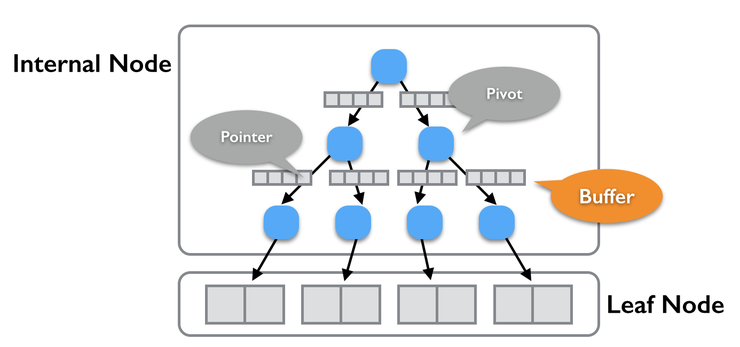
기존 B-Tree와 크게 다르지 않은 모습이지만 각 부모,자식 노드 사이에 별도의 Buffer 공간이 있다는 점이 다르다.
B-Tree는 데이터 사이즈가 커지면 메모리 자원은 한계가 있기에
모든 데이터가 메모리에 위치 할 수 없게되며 대부분 디스크에 존재할 가능성이 크다.
대부분의 디스크 I/O는 성능이 좋지 못하고 잦은 디스크 I/O가 발생되면 성능 저하의 큰 요소로 작용 할 수 밖에 없다.
이러한 잦은 디스크 I/O를 문제를 해결하기 위해 나온 자료구조로써
데이터를 Buffer에 담아뒀다가 Buffer가 가득차면 한번에 데이터를 노드로 전달하는 구조로 처리된 자료구조이다.
- 성능비교
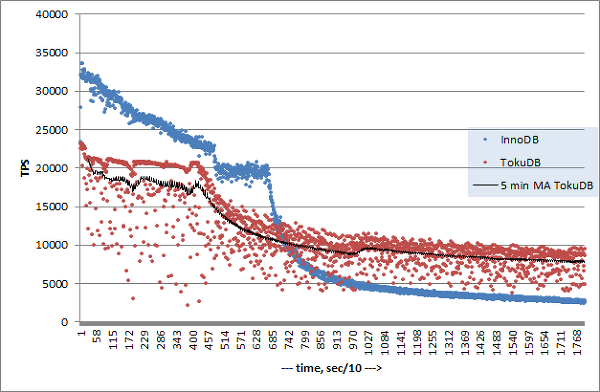
* 참고자료

잘 정리된 글 감사합니다.
잘 보고 갑니다. - 깐부 -