데이터베이스의 상태를 변경시키기 위해 수행하는 작업 단위
이 단위라는게 뭘 말하냐하면
말 그대로 데이터베이스의 상태를 변경
= SELECT, UPDATE, INSERT, DELETE
이러한 작업단위를 트랜잭션이라고 한다.
트랜잭션 메커니즘
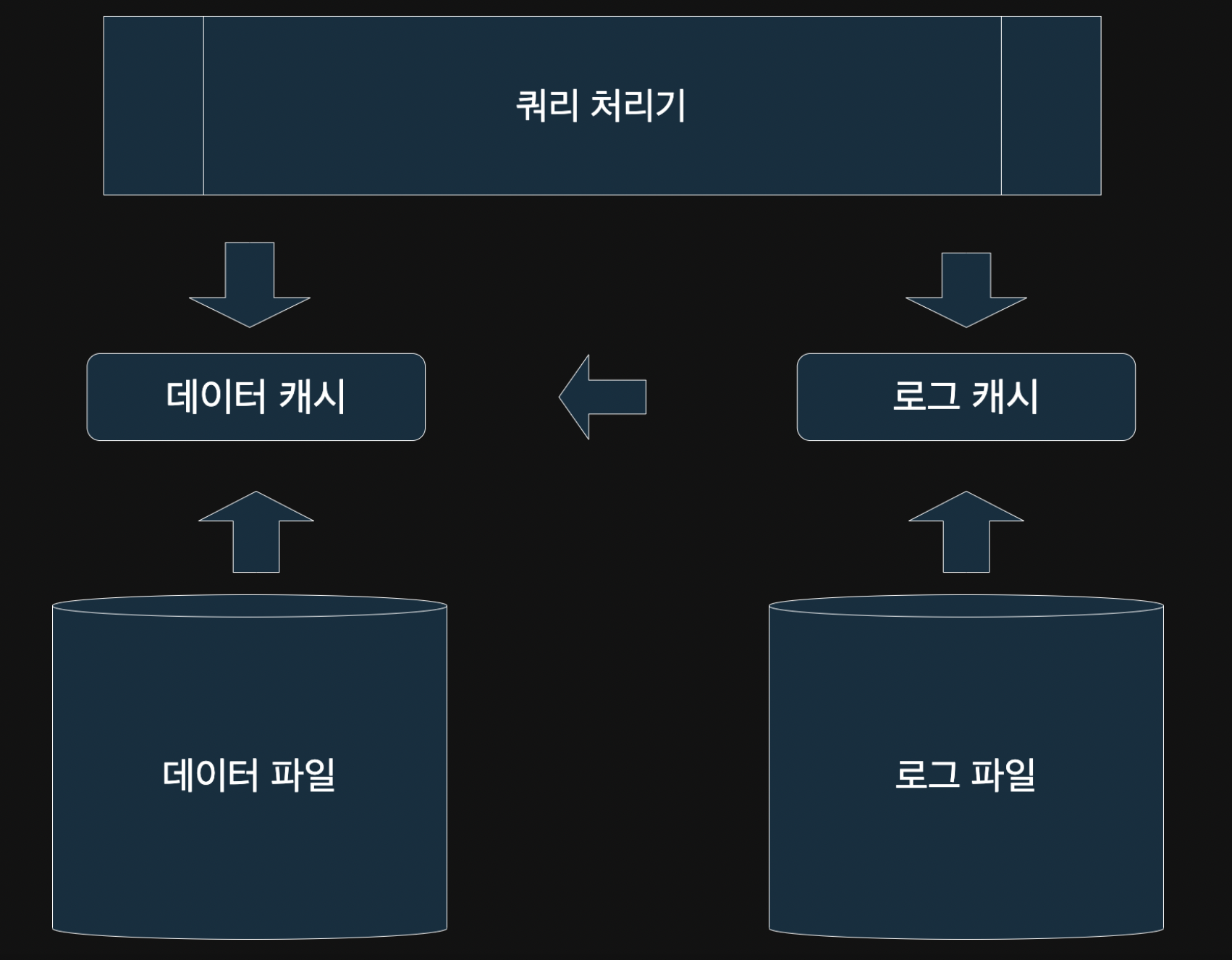
트랜잭션은 위 사진처럼 쿼리를 날리면 쿼리처리기에 의해 쿼리가 처리된다.
업데이트에 필요한 데이터를 데이터 캐시에 요청, 데이터 캐시에 해당 데이터가 없다 (쿼리가 처음 실행됐으므로)
데이터 파일에서 데이터를 가져와야 한다
그리고 데이터 캐시에 필요한 데이터가 로드 된다.
데이터가 로드 된 후, 업데이트를 하면 되는데 그 전에 로그 캐시에 로그를 기록해야 한다
ReDO 로그와 UnDO 로그에 기록하게 된다.

ReDO 로그
변경 후의 값을 기록
트랜잭션_1 START
트랜잭션_1 UPDATE accounts 구매자.balance 0 UnDo 로그
변경 전의 값을 기록
로그_1 accounts 구매자.balance 10000로그 기록 후 데이터 캐시에 있는 데이터를 업데이트
이렇게
트랜잭션의 한 단위가 끝이 나는데,
하나의 트랜잭션은 Commit (저장) 되거나 Rollback (철회)될 수 있다.
하나의 트랜잭션이 모두 실행되거나 아무 쿼리도 실행 되지 않는것을 '커밋' 혹은 '롤백'이라 한다
커밋
일종의 확인 도장으로 트랜잭션 묶인 모든 쿼리가 성공되어 트랜잭션 쿼리 결과를 실제 DB에 반영하는 것
롤백
쿼리실행 결과를 취소하고 DB를 트랜잭션 이전 상태로 되돌리는 것
UnDo 로그를 통해 롤백
UnDo를 통해 역순으로 기록을하게 되면 데이터가 이전 상태로 복구된다
트랜잭션의 역할
예상치못한 오류가 발생하게됐을 때에 redo와 undo log를 통해 데이터를 복구시킨다.
ReDo 로그를 순차적으로 실행 해서 데이터들을 다시 일관성있게 만들어 준다.
UnDo 로그를 역순으로 실행해서 다시 커밋이 되지 않은 것들을 이전 상태로 돌린다
트랜잭션의 특징
역할에서 눈치깠을 거 같은데, 트랜잭션의 특징은 바로
원자성
일관성
독립성
지속성
원자성
원자성은 트랜잭션이 DB에 모두 반영되거나, 전혀 반영되지 않거나를 뜻한다.
All or Nothing을 생각하면 된다.
일관성
일관성은 트랜잭션 작업 처리의 결과가 항상 일관되어야 한다를 뜻한다.
즉, 데이터 타입이 반환 후와 전이 항상 동일해야 한다.
독립성
독립성은 하나의 트랜잭션은 다른 트랜잭션에 끼어들 수 없고 마찬가지로 독립적임을 의미한다.
즉, 각각의 트랜잭션은 독립적이라 서로 간섭이 불가능하다.
지속성
지속성은 트랜잭션이 성공적으로 완료되면 영구적으로 결과에 반영되어야 함을 뜻한다.
보통 commit 이 된다면 지속성은 만족할 수 있다.
이 4가지 특징은 줄여서 ACID 라고도 부르니 알아두자.
선언적 트랜잭션
tx namespace
bean에 트랜잭션 매니저를 등록하고
속성과 대상을 정의해트랜잭션을 적용하겠다고 명시하는 것
<bean id="txManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<tx:advice id="txAdvice" transaction-manager="txManager">
<tx:attributes>
<tx:method name="*" propagation="REQUIRED" rollback-for="Exception"/>
</tx:attributes>
</tx:advice>
<tx:advice id="noTxAdvice" transaction-manager="txManager">
<tx:attributes>
<tx:method name="*Tx" propagation="NOT_SUPPORTED"
rollback-for="Exception"/>
</tx:attributes>
</tx:advice>
<aop:config>
<aop:pointcut id="requiredTx"
expression="execution(public * com.패키지명.패키지명2..service..*.*(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="requiredTx" />
</aop:config>
<aop:config>
<aop:pointcut id="noRequiredTx"
expression="execution(public * com.패키지명.패키지명2..service..*.*Tx(..))"/>
<aop:advisor advice-ref="noTxAdvice" pointcut-ref="noRequiredTx" />
</aop:config>@Transaction
트랜잭션 어노테이션은 클래스, 인터페이스, 메소드 선언 바로 위에 @Transaction을 달아줌으로서, 트랜잭션을 적용하는 방식이다.
트랜잭션 어노테이션이 중첩적으로 적용될 때에는
클래스메서드, 클래스, 인터페이스메서드, 인터페이스 순으로 우선순위가 적용됩니다,
어노테이션이 적용된 메서드는 메서드 시작부터 트랜잭션이 시작되고,
메서드 끝날때까지 작업이 성공하면 커밋, 작업이 실패하거나 중간에 오류가 난다면 롤백을 통해서 트랜잭션이 종료됩니다!
혼합형
@Transactional(value="txManager")
@Transactional(transactionManager="txManager")@Transaction 속성
propagation
트랜잭션 전파
트랜잭션의 경계에서 이미 진행하고 있는 트랜잭션이 있을 때 어떻게 할 지 결정하는 것
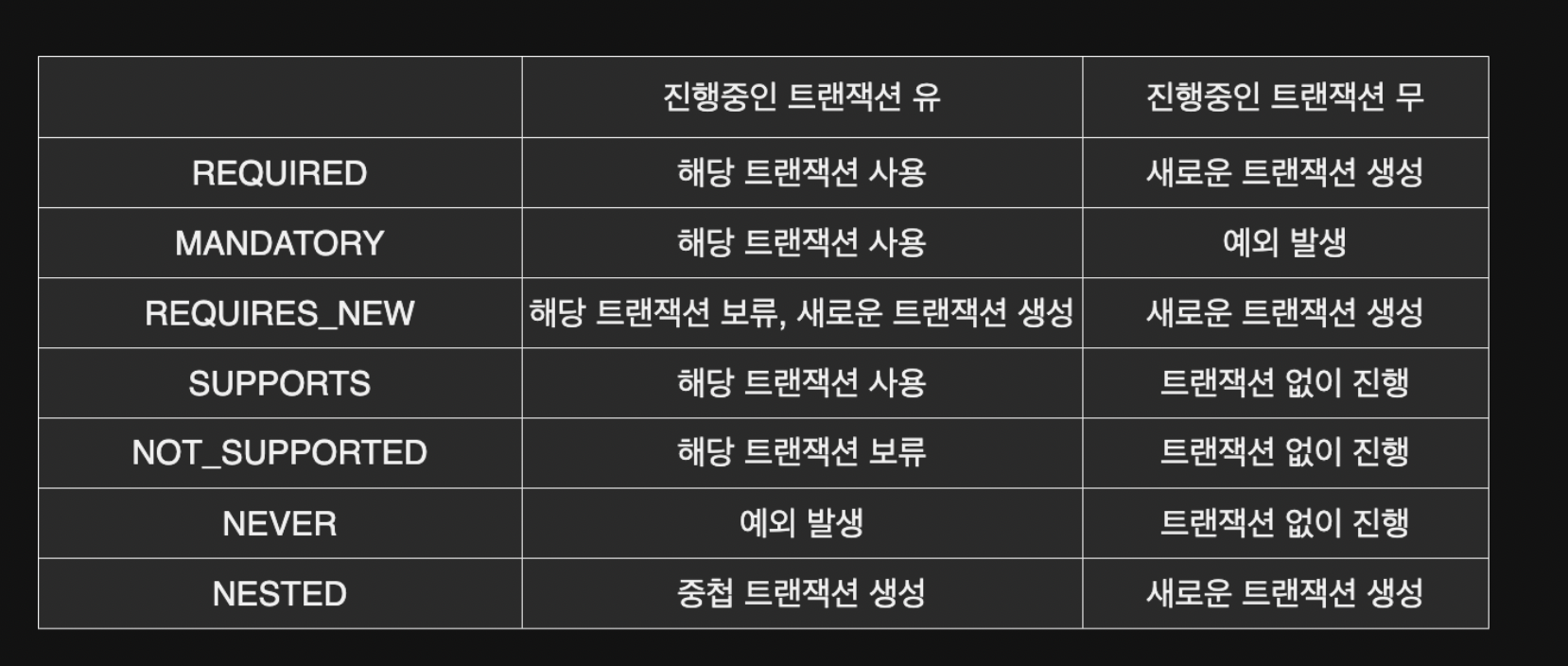
REQUIRED (디폴트 설정)
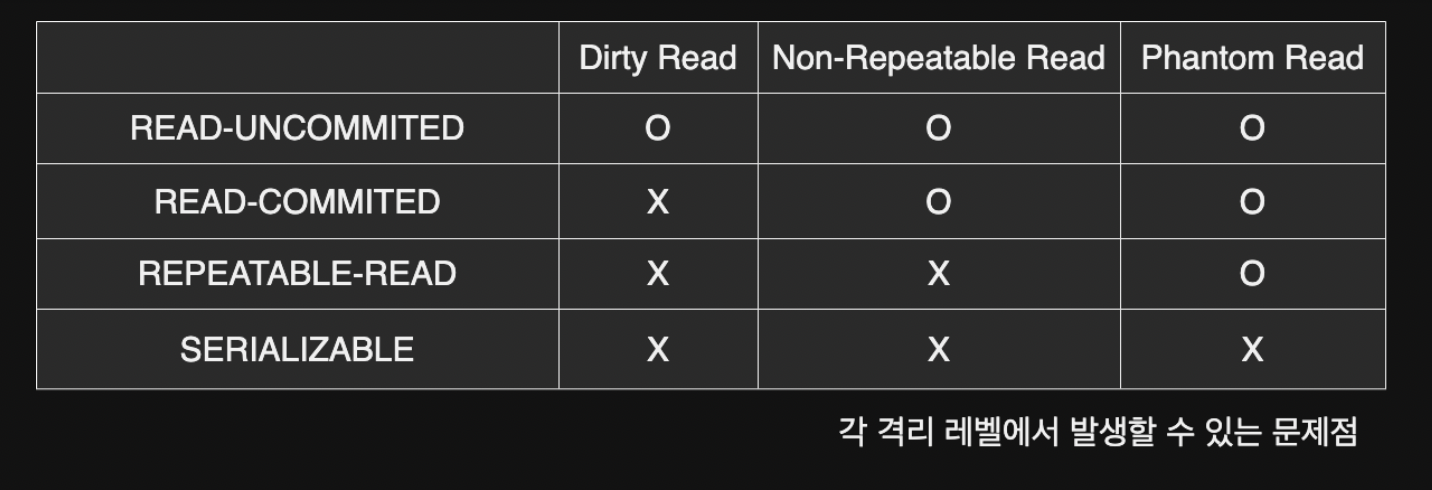
isolation (격리수준)
동시에 DB에 접근할 때 그 접근을 어떻게 제어할지에 대한 설정
대부분의 데이터베이스는 READ-COMMITED 격리수준을 따르지만,
정확히 확인해야한다.
밑으로 갈수록 격리 수준이 높아지지만 성능은 떨어진다
(데이터 정합성과 성능이 반비례한다, 케이스에 맞게 잘 선택하자)
격리수준이 높아지면 성능저하의 우려가 있으니 케이스에 맞게 잘 선택하자
-
READ-UNCOMMITTED
커밋 전의 트랜잭션의 데이터 변경 내용을 다른 트랜잭션이 읽는것을 허용 -
READ-COMMITTED (가장 많이 사용되는 격리수준)
커밋이 완료된 트랜잭션의 변경사항만 다른 트랜잭션에서 조회 가능 -
REPEATABLE-READ
트랜잭션 범위 내에서 조회한 내용이 항상 동일한 내용 보장 -
SERIALIZABLE
한 트랜잭션에서 사용하는 데이터를 다른 트랜잭션에서 접근 불가
격리수준에 따라 데이터베이스는 LOCK을 걸어 데이터베이스를 보호하고자 하는데, 격리수준이 높을수록 lock을 강하게 걸고, 트랜잭션이 종료되면 lock도 해제한다. 운영에서 락걸렸다는 얘기가 이런거였나보다..
⚠️ Dirty Read
Dirty page(메모리엔 변경 되었지만 디스크엔 아직 변경이 되지않은 데이터)에 있는 데이터를 검색, 커밋되지 않은 데이터를 Read 하기 때문에 Dirty Read 후 Dirty page가 롤백 되어 잘못된 데이터를 읽어온 상태가 된다
(이미지 예시)
트랜잭션 A가 만약 트랜잭션을 끝마치지 못하고 롤백 한다면 트랜젝션 B는 무효가 된 데이터 값을 읽고 처리를 하기 때문에 문제 발생
⚠️ NON-REPEATABLE READ
하나의 트랜젝션에서 같은 쿼리를 두 번 이상 수행 시, 똑같은 쿼리문임에도 다른 결과를 나타내는 현상
(위의 이미지 예시)
같은 트랜잭션 내에서 READ 시 값이 다르게 나오는 데이터 불일치 문제
트랜잭션 중 데이터가 변경되면 문제가 발생할 수 있다.
⚠️ Phantom Read
NON-REPEATABLE READ 의 한 종류 이며,
하나의 트랜젝션에서 일정 범위의 레코드를 두 번 이상 읽어올때, 똑같은 쿼리문임에도 첫 번째 쿼리에서 없던 레코드가 두번째 쿼리에서 나타나는 현상
time out
@Transactional(timeout="10")rollback For
@Transactional(rollbackFor=NoSearchElementException.class)NoSearchElementException이 발생하면 rollback 해라 라는 뜻이다!
readOnly
@Transactional(readOnly=true)트랜잭션을 읽기전용 모드로 설정하는 것
읽기 외의 다른 쿼리는 사용불가
따라서 효율이 좋아짐
왜 성능이어떻게 얼마나 좋아지는데?
readOnly=true인 상태이면 영속성 컨텍스트에 관리를 받지않아, 스냅샷 저장. 변경감지 수행등을 하지 않아 성능적으로 낫다.
PostgreSQL에서 readOnly동작 방식
해당 트랜잭션을 이용할 경우 SELECT를 제외한 DDL, DML, DCL은 동작하지 않는다.
Postgresql에서는 읽기 동작을 가정할 경우, Read/Write 속성과 성능 차이를 가지지 않으며 (해당 부분의 최적화 X) Deffered 속성(행 단위가 아닌 트랜잭션 단위의 제약조건 검증 처리)을 적용하였을 때, SERIALIZABLE 이거나 READ ONLY를 사용하게 되어 내부의 튜플이 수정되지 않는 안전한 동작을 하게끔 지원하는 용도이다.
→ Postgre의 Read Only 설정도 성능 이점이 아닌 동시성 제어를 위함이다.
→ Postgre는 Read Only 설정 시 트랜잭션 ID를 일반적인 ID가 아닌 가상 ID로 제공하기에 실제로 제공되는 트랜잭션 ID가 수가 줄어들어 성능이 개선될 수도 있다.
readOnly는 현재 해당 그 트랜잭션 내에서 데이터를 읽기만 할건지 설정하는 겁니다. 이걸 설정하면 DB 중에 read 락(lock)과 write 락을 따로 쓰는 경우 해당 트랜잭션에서 의도치 않게 데이터를 변경하는 일을 막아줄 뿐 아니라, 하이버네이트를 사용하는 경우에는 FlushMode를 Manual로 변경하여 dirty checking을 생략하게 해준다거나 DB에 따라 DataSource의 Connection 레벨에도 설정되어 약간의 최적화가 가능합니다. 아마 이 부분에서 특정 DB는 말씀하신대로 isolation 레벨이 READ_UNCOMMITED 처럼 동작할 여지도 있는 것 같습니다. 그런데 그게 꼭 좋은 건지는 생각해 봐야겠네요.
-백기선님의 말씀
출처
https://velog.io/@minthug94_
https://pjh3749.tistory.com/269
유튜브 우테크 셀리의 트랜잭션
https://www.inflearn.com/questions/7185/transactional-readonly-true-%EC%97%90%EB%8C%80%ED%95%9C-%EC%A7%88%EB%AC%B8%EC%9E%85%EB%8B%88%EB%8B%A4
