
NLP(Natural Language Processing)
자연어(Nautral Language)란 인간이 일상에서 사용하는 언어를 말한다. 자연어 처리(Natural Laguage Processing)란 기계가 자연어를 이해하고 해석하여 처리할 수 있도록 하는 일을 말한다. 자연어 처리(Natural Laguage Processing)를 줄여서 NLP라고 부른다.
자연어 처리(NLP)와 텍스트 분석(Text Mining)은 엄밀히 말하면 다른 개념이다. 자연어 처리는 기계가 인간의 언어를 해석하는데 중점이 두어져 있다면, 텍스트 분석은 텍스트에서 의미 있는 정보를 추출하여 인사이트를 얻는데 더 중점이 두어져 있다. 다만, 머신러닝이 보편화되면서 자연어 처리와 텍스트 분석을 구분하는 것이 큰 의미가 없어졌다.
Word Representation(Sparse Representation, Local Representation)
단어들을 벡터로 표현
Word Representation은 1아니면 0으로 표현하는 1-hot 인코딩을 사용.
즉 총 10000개의 단어가 있다하면 10000개의 벡터값중 단어의 해당값만 1이고 나머지는 0
하지만 모든 단어들을 이용하여 유사성(관계)를 알아낼 수 없다. 그러므로 유사성(관계)를 알아낼 수 있는 특징적인 표현을 학습하는 것이 필요하며 그것이 Word Embedding이다.

Word Embedding이란?
텍스트를 컴퓨터가 이해하고, 효율적으로 처리하게 하기 위해서는 컴퓨터가 이해할 수 있도록 텍스트를 적절히 숫자로 변환해야 한다. 단어를 표현하는 방법에 따라서 자연어 처리의 성능이 크게 달라지기 때문에 단어를 수치화 하기 위한 많은 연구가 있었고, 현재에 이르러서는 각 단어를 인공 신경망 학습을 통해 벡터화하는 워드 임베딩이라는 방법이 가장 많이 사용되고 있다.

Word Embeddings의 특징
- Dense Representation
Word Embedding은 어떤 것(새로운 차원)을 통한 Dense Representation이다. Word Embedding은 0 ,1(원핫인코딩)이 아닌 어떤 것(새로운 차원)를 표현하는 실수값으로 이루어져있다. 이 실수값이 계산하면서 유사성(관계)를 찾아낼 수 있고, 곱해도 0이 되어지지 않는다. 그리고 이 어떤 것(새로운 차원)으로 이루어진 벡터는 빽빽하게 밀집되어 있는 벡터이며, 저차원으로 이루어진다. (10000개 -> 300개) 그리하여 Dense Representation 이라고 명칭한다.
- Distributed Representation
Word Embedding은 빽빽하게 밀집되어 있는 벡터이며, 저차원으로 이루어진다. 이를 통해 300개의 여러 어떤 것(새로운 차원)에 유사성(관계)를 계산할 수 있는 단어의미를 내장하게 된다.
이처럼 여러 곳에 단어의미를 분포한다 하여 Distributed Representation이라고 한다.
Word2Vec
Word2Vec 정의
Word(단어) 2(to) Vec(벡터),즉 단어를 벡터로 바꾼다.
Word2Vec 종류
-
CBOW(Continuous Bag of Words)
주변단어들을 확인하여 중심에 있는 Target을 예측
ex) The fat cat sat on the mat
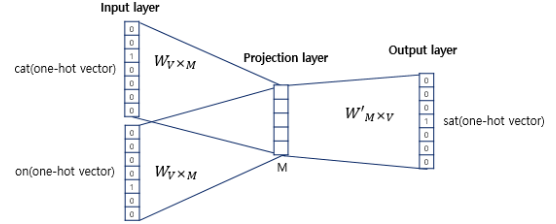
-
Skip-Gram
중심에 있는 단어로 주변의 Target을 예측
ex) The fat cat sat on the mat
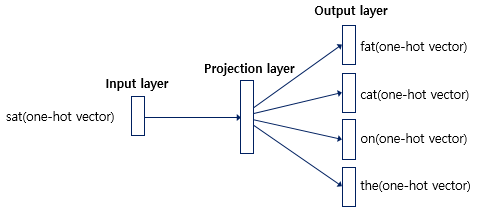
Word2Vec 모델링 과정
ex) The fat cat sat on the mat
참고 사이트
