Object Detection이란?
CNN(Convolutional Neural Network)모델이 하는일인 이미지를 Classification(분류)하는 것이다. 그래서 어떤 이미지가 들어오면 해당 이미지 내의 객체들이 무엇인지 알려주었다.
Object Detection에서는 Classification뿐만 아니라 localization이라는 개념도 포함되어 있다. Localization이란 객체라고 판단되는 곳에 직사각형(bounding box)를 그려주는 것이다.
왼쪽(CNN) 오른쪽(Object Detection)

Methods
- neural approach methods
1.CNN, YOLO, Retina-Net, FCOS 등
->regional proposal과 classification이 순차적으로 이루어지는 모델 - non-neural approach methods
1.non-neural approach methods는 deep learning based detection methods의 고안 이전에 진행되었던 방식으로, classification을 위한 feature들을 해당 방법들을 통해 구한 다음, feature들을 사용한 classification 기술(e.g. SVM)을 사용하여 detection을 진행한다.
2.최근에는 non-neural approch method가 neural approach method의 성능을 따라오지 못하기에 neural approach method를 발전시키는 방법으로의 연구가 활발히 이루어지고 있다.
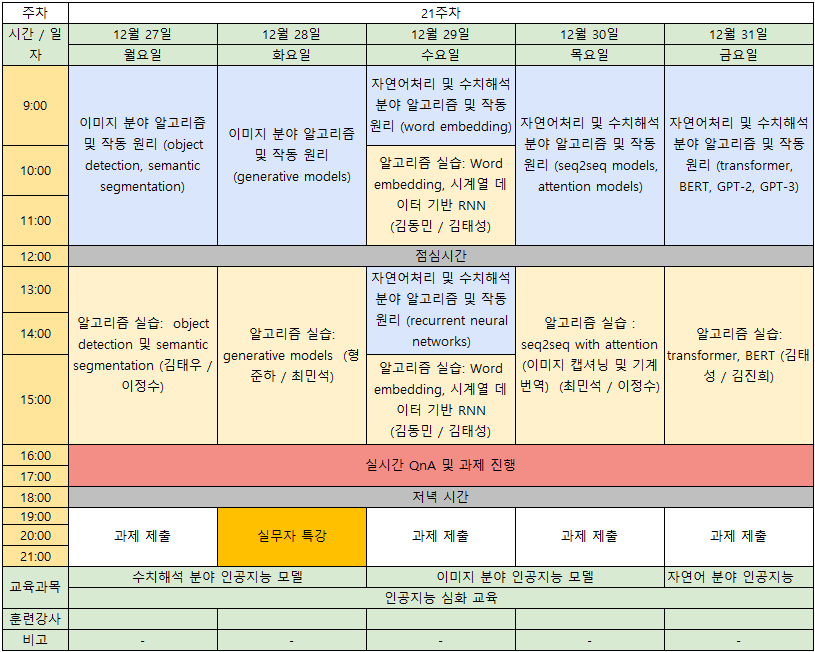
2-Stage Detector
2-stage detector의 경우, regional proposal과 classification이 순차적으로 이루어지는 모델이다. Regional Proposal 과정이 먼저 이루어지며, 이 과정에서 image 내에 object가 있을 법한 영역인 RoI(Region of Interest)를 찾아낸다. 이러한 영역들을 발견하고 나면 그 이후에 RoI들에 대하여 object classification을 진행하게 된다.
- 대표모델: CNN 계열 모델(R-CNN, Faster R-CNN, DenseNet)
- RoI를 먼저 찾아내고나서 classification을 순차적으로 진행하게 되므로, 비교적 느리다.
- RoI를 먼저 찾아내기 때문에 classification 과정에서의 noise가 적어 정확도는 비교적 높다.
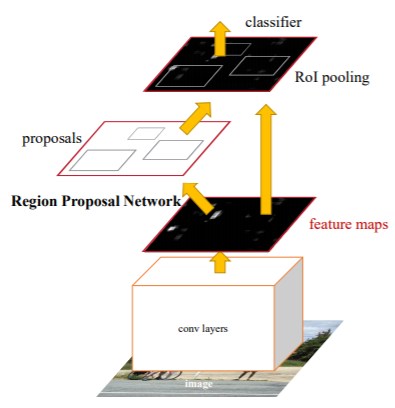
1-Stage Detector
1-stage detector의 경우, regional proposal과 classification이 동시에 이루어지는 모델이다. Regional Proposal 과정과 classification 과정이 동시에 진행된다는 차이점이 존재한다. RoI를 추출하지 않고, image 전체에 대해 clssification을 수행 하게된다. 예를 들어, 1-stage detector의 대표주자인 YOLO의 경우, 전체 이미지를 특정 크기의 grid로 분할하여 object의 중심이 cell에 존재할 경우 해당 cell이 object detection을 진행하는 방식으로 classification을 진행하여 바로 Bounding Box(BBox, object가 존재하는 image 내 사각형)를 예측하게 된다.
- 대표모델: YOLO, SSD, RetinaNet
- regional proposal과 classification이 동시에 이루어지기 때문에 비교적 빠르다
- 특정 object 하나만 담고 있는 RoI에 비해, 여러 noise와 object가 들어있는 image에서 수행하기 때문에 평균적으로 정확도는 더 낮다는 단점이 있다.
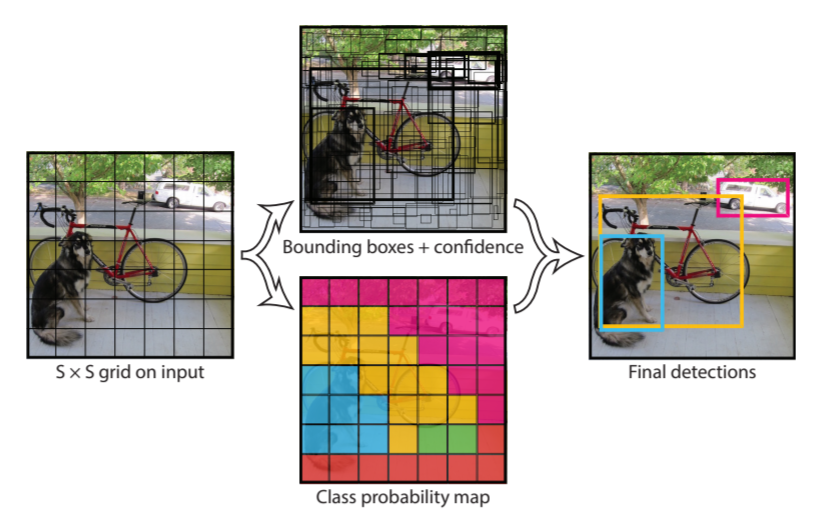
Semantic Segmentation이란?

위 그림처럼, 이미지 내에 있는 물체들을 의미 있는 단위로 분할해내는 것이다.
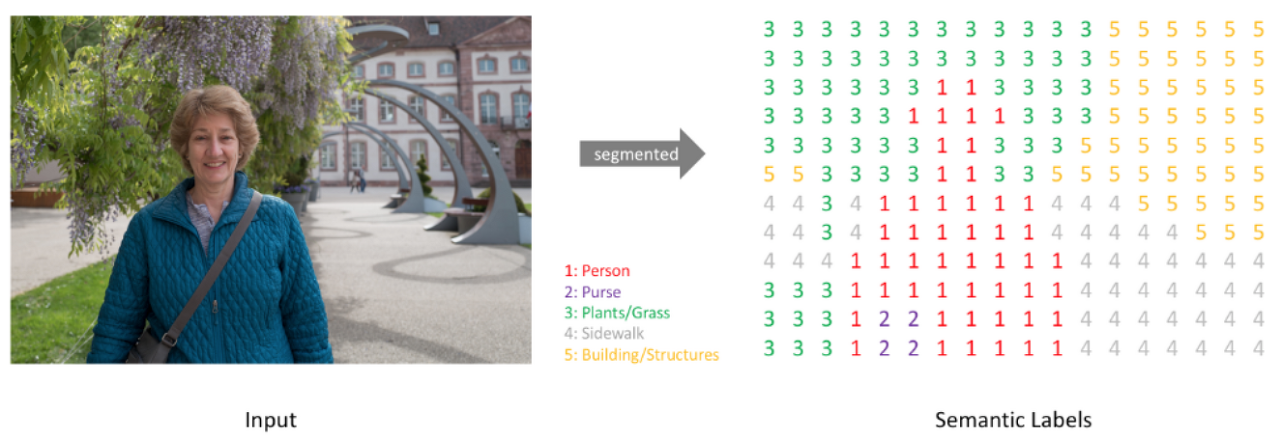
더 구체적으로는 아래 그림처럼, 이미지의 각 픽셀이 어느 클래스에 속하는지 예측하는 것이다. 그리고 Semantic Segmentation은 다른 컴퓨터비젼 문제들과 마찬가지로, Deep Convolution Neural Network (깊은 신경망)을 적용해서 많은 발전을 이루었다.
- Classification (분류)
- 인풋에 대해서 하나의 물체를 구분하는 작업
- LeNet, AlexNet, VGG Nets, GooLeNet, ResNet, Xception 등의 모델
- Object Detection (객체 탐지)
- 물체를 구분함과 동시에, 그 물체가 어디에 있는지까지 Boxing하는 작업
- RCNN, Fast RCNN, Faster RCNN, SPP Net, YOLO, SDD, Attention Net 등의 모델
- Segmentation (분할)
- 모든 픽셀에 대해, 각 픽셀이 어떤 물체의 class인지 구분하는 작업
- FCN, DeepLab, U-Net, ReSeg 등의 모델
따라서, Semantic Segmentation의 목적은 사진에 있는 모든 픽셀을, 해당하는 class로 분류하는 것이다. 이미지에 있는 모든 픽셀에 대한 예측을 하는 것이기 때문에, dense prediction 이라고도 불린다.

Semantic Segmentation
위에 오른쪽처럼, 픽셀 단위로 어떤 class인지만 구분한다.
Instance Segmentation
위에 왼쪽처럼, 픽셀 단위로 어떤 class인지 구분한 이후, 동일한 class내에서도 다른 Instance를 구분한다.
참고사이트
