먼저 트랜스포머에 대해서 이야기 하기전, 기존의 seq2seq를 이야기해볼 것이다.
seq2seq모델은 인코더-디코더 구조로 구성되어져 있다. 인코더는 입력 시퀀스를 하나의 벡터 표현으로 압축하고, 디코더는 이 벡터 표현을 통해서 출력 시퀀스를 만들어냈다. 하지만 인코더가 입력 시퀀스를 하나의 벡터로 압축한느 과정에서 입력 시퀀스의 정보가 일부 손실된다는 단점이 있고, 이것을 보정하기 위해 어텐션이 사용되었다.
트랜스포머(Transformer)란?
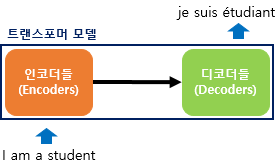
트랜스포머는 RNN을 사용하지 않지만 기존의 seq2seq처럼 인코더에서 입력 시퀀스를 입력받고, 디코더에서 출력 시퀀스를 출력하는 인코더-디코더 구조를 유지하고 있다.
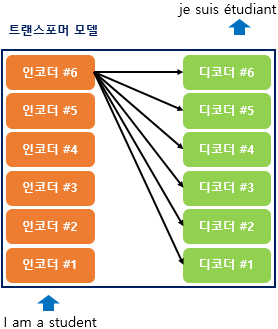
위의 그림은 인코더와 디코더가 6개씩 존재하는 트랜스포머의 구조이다.
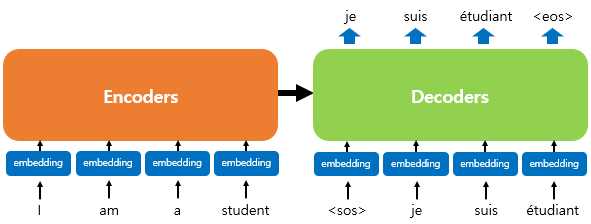
그리고 위의 그림은 인코더로부터 정보를 전달받아 디코더가 출력 결과를 만들어내는 트랜스포머 구조의 한 예이다.
포지셔널 인코딩(Positional Encoding)
RNN이 자연어 처리에서 유용했던 이유는 단어의 위치에 따라 단어를 순차적으로 입력받아서 처리하는 RNN의 특성으로 인해 각 단어의 위치 정보를 가질 수 있다는 점이였다. 하지만 트랜스포머는 단어 입력을 순차적으로 받는 방식이 아니므로 단어의 위치정보를 다른 방식으로 알려줄 필요가 있다. 그러기 위해서 트랜스포머에는 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여 사용한다. 이것을 포지셔널 인코딩(positional encoding)이라고 한다.
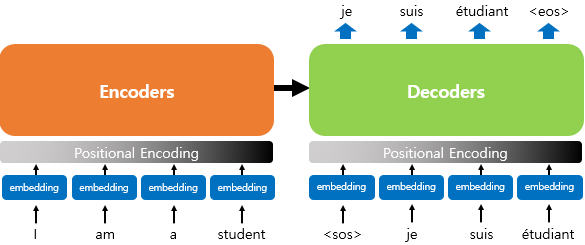
포지셔널 인코딩 값들은 sin함수와 cos함수의 값을 임베딩 벡터에 더해주므로서 단어의 순서 정보를 더하여 준다.
어텐션(Attention)
트랜스포머에서 사용되는 어텐션은 세가지이다.
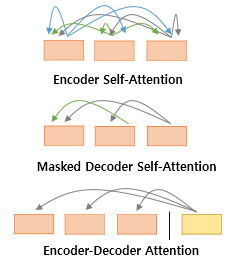
첫번째 그림인 셀프 어텐션은 인코더에서 이루어지지만, 두번째 그림인 셀프 어텐션과 세번째 그림인 인코더-디코더 어텐션은 디코더에서 이루어진다. 셀프 어텐션은 본질적으로 Query, Key, Value가 동일한 경우를 말한다. 반면, 세번째 그림 인코더-디코더 어텐션에서는 Query가 디코더의 벡터인 반면에 Key와 Value가 인코더의 벡터이므로 셀프 어텐션이라고 부르지 않는다.
*주의할 점은 여기서 Query, Key 등이 같다는 것은 벡터의 값이 같다는 것이 아니라 벡터의 출처가 같다는 의미
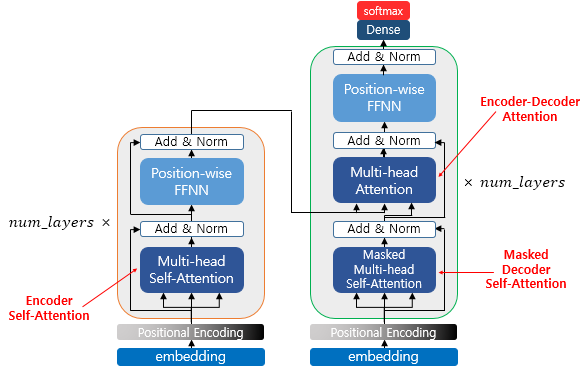
<트랜스포머의 아키텍쳐>
위 그림은 세 가지 어텐션이 각각 어디있는지 보여준다.
인코더(Encoder)
인코더 구조에 대해서 알아보자.
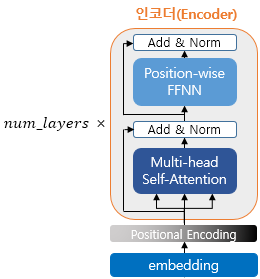
num_layers는 트랜스포머의 하이퍼파라미터중 하나이며, 개수만큼 인코더 층을 쌓는다. 위 그림은 하나의 인코더 층에서 총 2개의 서브층으로 나뉘어진다. 셀프 어텐션과 피드 포워드 신경망이다.
인코더의 셀프 어텐션
셀프 어텐션에 대한 구체적인 사항을 배우기 전에 셀프 어텐션을 통해 얻을 수 있는 대표적인 효과에 대해서 먼저 이해해보자.

위의 그림은 트랜스포머에 대한 구글 AI블로그 포스트에서 가져왔다고 한다. 위의 예시 문장을 번역하면 '그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다.' 라는 의미가 된다. 그런데 여기서 그것(it)에 해당하는 것은 과연 길(street)인지 동물(animal)인지 글을 읽는 사람들은 피곤한 주체가 동물이라는 것을 아주 쉽게 알 수 있지만 기계는 그렇지 않다. 하지만 셀프 어텐션은 입력 문장 내의 단어들끼리 유사도를 구하므로서 그것(it)이 동물(animal)과 연관되었을 확률이 높다는 것을 찾아낸다.
포지션-와이즈 피드 포워드 신경망(Position-wise FFNN)
포지션 와이즈 FFNN은 인코더와 디코더에서 공통적으로 가지고 있는 서브층이다. 포지션-와이즈 FFNN는 쉽게 말하면 완전 연결 FFNN(Fully-connected FFNN)이라고 해석할 수 있다.
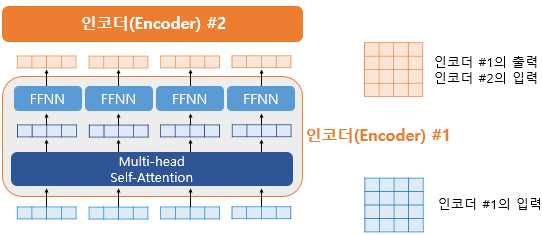
위의 그림에서 좌측은 인코더의 입력을 벡터 단위로 봤을 때, 각 벡터들이 멀티 헤드 어텐션 층이라는 인코더 내 첫번째 서브 층을 지나 FFNN을 통과하는 것을 보여준다. 이는 두번째 서브층인 Position-wise FFNN을 의미한다.
잔차 연결(Residual connection)과 층 정규화(Layer Normalization)
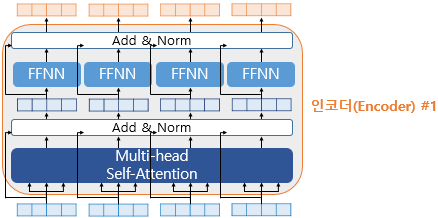
트랜스포머에서는 이러한 두 개의 서브층을 가진 인코더에 추가적으로 사용하는 기법이 있는데, 바로 Add & Norm이다. 더 정확히는 잔차 연결(residual connection) 과 층 정규화(layer normalization) 를 의미한다.
-
잔차 연결(Residual connection)
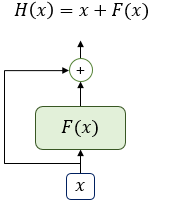
위 그림은 입력 와 에 대한 어떤 함수 의 값을 더한 함수 의 구조를 보여준다.
트랜스포머에서 서브층의 입력과 출력은 동일한 차원을 갖고 있으므로, 서브층의 입력과 서브층의 출력은 덧셈 연산을 할 수 있다. -
층 정규화(Layer Normalization)
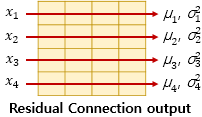
잔차 연결을 거친 결과는 이어서 층 정규화 과정을 거치게됩니다.
인코더에서 디코더로(From Encoder To Decoder)
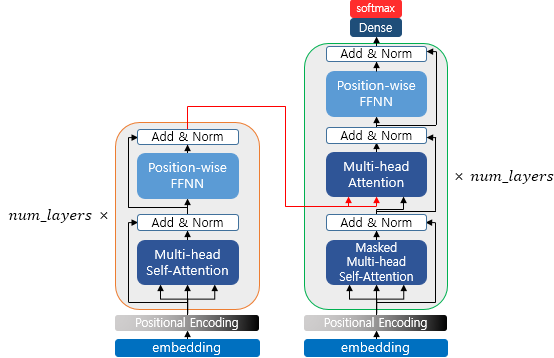
앞서 설명한 인코더에서 num_layers만큼의 층 연산을 순차적으로 한 후에 마지막 층의 인코더의 출력을 디코더에 전달한다. 인코더 연산이 끝났으면 디코더 연산이 시작되어 디코더 또한 num_layers만큼의 연산을 하는데, 이때마다 인코더가 보낸 출력을 각 디코더 층 연산에 사용한다.
디코더의 첫번째 서브층 : 셀프 어텐션과 룩-어헤드 마스크
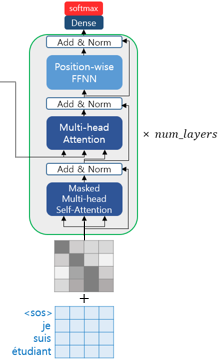
트랜스포머 또한 seq2seq와 마찬가지로 Teacher Forcing을 사용하여 훈련되므로 학습 과정에서 디코더는 번역할 문장에 해당되는 je suis étudiant의 문장 행렬을 한 번에 입력받는다. 그리고 디코더는 이 문장 행렬로부터 각 시점의 단어를 예측하도록 훈련된다.
Teacher Forcing은 https://m.blog.naver.com/sooftware/221790750668 여기를 보면 이해가 될 것이다.
RNN 계열의 seq2seq의 디코더에서는 입력 단어를 매 시점마다 순차적으로 입력받으르모 다음 단어 예측에 현재 시점을 포함한 이전 시점에 입력된 단어들만 참고할 수 있지만, 트랜스포머는 문장 행렬로부터 미래 시점의 단어까지도 참고할 수 있는 현상이 발생한다. 이를 위해 트랜스포머의 디코더에서는 현재 시점의 예측에서 현재 시점보다 미래에 있는 단어들을 참고하지 못하도록 룩-어헤드 마스크(look-ahead mask)를 도입했다.
디코더의 두번째 서브층 : 인코더-디코더 어텐션
디코더의 두번째 서브층은 멀티 헤드 어텐션을 수행한다는 점에서는 이전의 어텐션들(인코더와 디코더의 첫번째 서브층)과는 공통점이 있으나 이번에는 셀프 어텐션이 아니다.
참고 사이트
