맵리듀스란?
맵리듀스는 여러 node에 task를 분배하는 방법으로 각 node process data는 가능한 경우, 해당 노드에 저장된다. 맵리듀스 task는 맵(Map)과 리듀스(Reduce) 총 두단계로 구성된다. 하둡에서 큰 데이터가 들어왔을때 64MB 혹은 128MB단위 블럭으로 분할하고, 각각 블럭에 대한 연산을 한다. 그렇게 분산을 통해 계산을 한 블럭의 결과 정보를 합치는 작업(Reduce)를 수행하게 되는 방식이다.
맵리듀스 과정
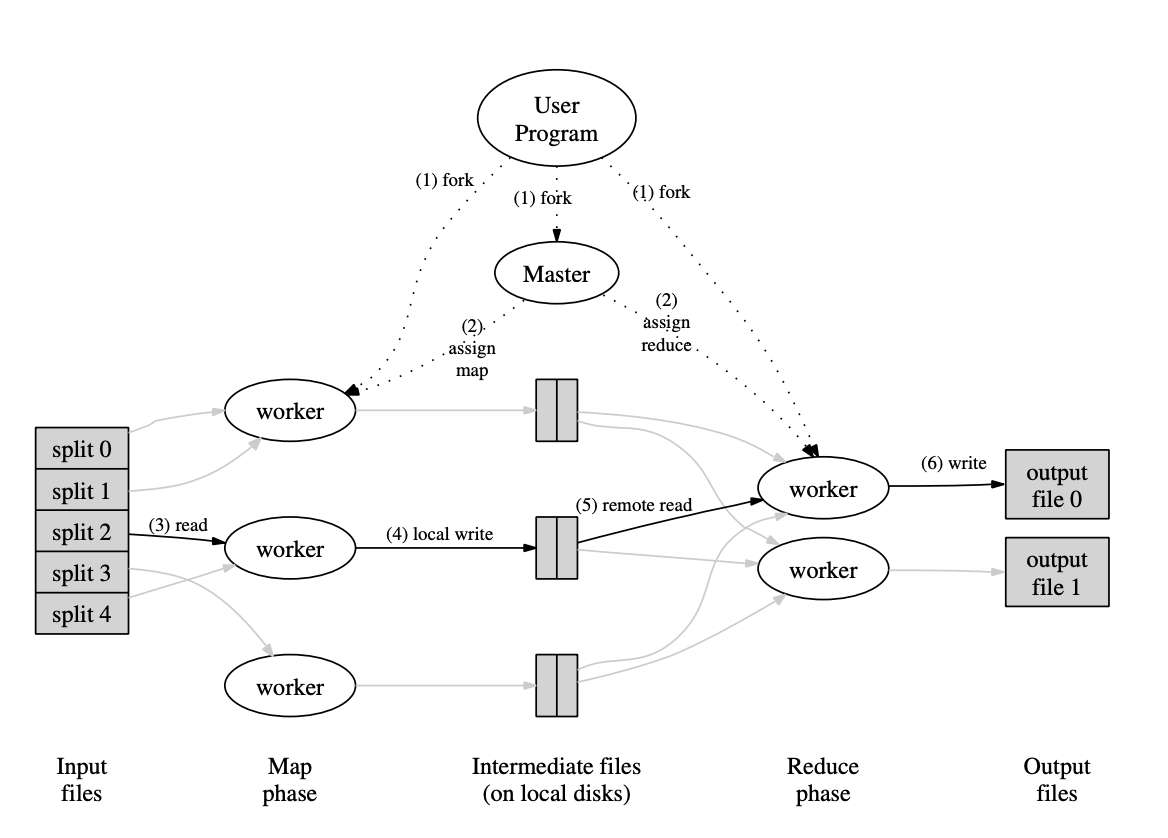
1. fork
인풋 파일은 미리 쪼개져서 분산 파일 시스템에 저장되어 있다고 가정하겠다. 사용자가 map과 reduce 함수를 정의한 프로그램을 실행시켜서 프로세스를 실행하면 이는 마스터 노드, map을 실행할 워커 노드(이하 Mapper 노드), reduce를 실행할 워커 노드(이하 Reducer 노드)들에 복사된다.
2. assign map and reduce
마스터 노드는 Mapper워커들에게 mapping 역할을, reducer 노드들에게는 reduce 역할을 수행하라고 지정해준다. 이 때, mapper 노드의 개수나 reducer 노드의 개수는 사용자가 설정할 수 있다.
3,4. read, map, local write
Mapper 노드들은 쪼개어진 데이터 청크를 분산 파일 시스템으로부터 읽어온다. 그 다음 이 데이터에 Map 함수를 실행하여 Key:Value 형태의 Intermediate 데이터를 생성하고 이를 자기 자신의 로컬 디스크에 저장한다. 그 다음 Mapper 노드는 마스터 노드에게 Mapping 작업을 모두 완료하였다고 알려준다.
5,6 reduce, write
그러면 마스터 노드는 리듀서 노드들에게 reduce를 시작하라고 명령을 내려준다. reducer 노드들은 mapper 노드들의 디스크 공간에 저장되어 있는 Intermediate 데이터를 읽어온다. 그리고 reduce 함수를 실행하여 최종 결과물을 산출한 다음 파일 형태로 데이터를 출력한다.
맵리듀스 예제
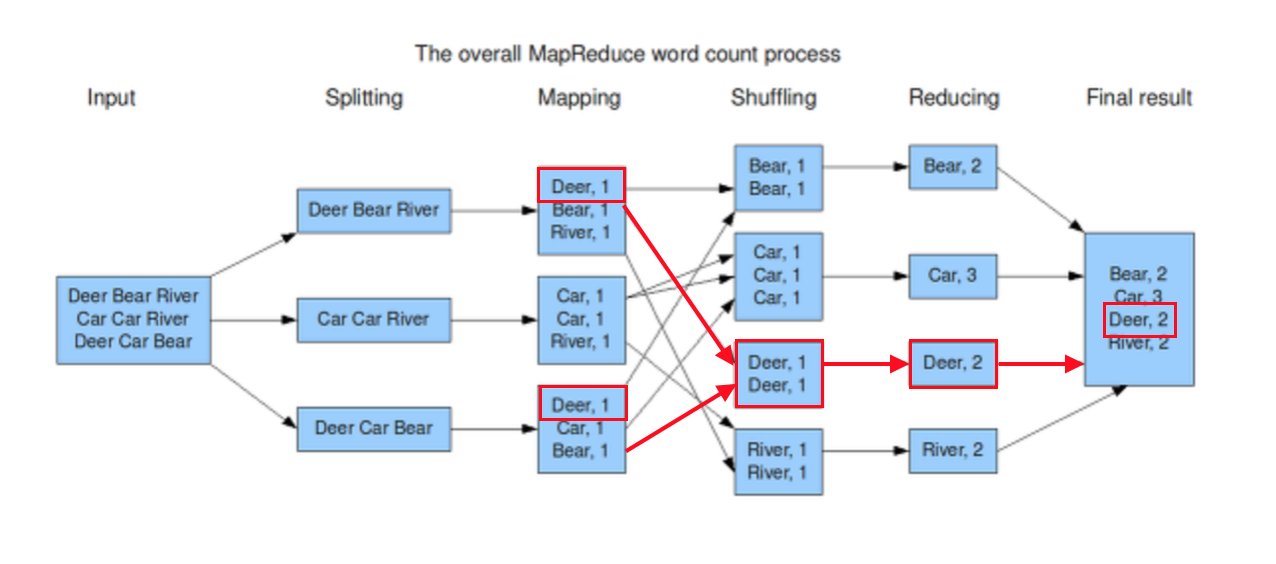
위의 이미지는 워드 카운팅을 통해서 MapReduce를 하는 과정이다. 3대의 Mapper와 4대의 Reducer노드로 이루어진 클러스터에서 워드 카운팅을 수행하는 것이다.
1.Splitting 그리고 Mapping
먼저 input 텍스트 파일을 쪼개어 분산 파일 시스템에 저장한다. 쪼개어진 텍스트 데이터는 3대의 Mapper노드에 각각 전달된다, 그리고 각 노드들은 Map함수를 실행하여 입력으로 들어온 텍스트 데이터를 파싱하여 Dear:1, Bear:1, River:1과 같은 Key:Value를 생성한다.
2.Shuffling
Mapping으로 생성된 Key:Value형태의 값을 Reducer 노드에 입력으로 전달하기 이전의 과정 전체를 Shuffling이라고 부른다. 그럼 Shuffling은 왜 필요할까?
이전에 MapReduce를 통해서 알고 싶은 전체 텍스트에서 특정 단어가 얼마나 자주 등장했는지 알 수 있다. 이를 위해서 전체 데이터를 3조각으로 나누었고, 이를 Mapper 노드들에 분산시켜서 워드 카운팅을 진행했다. 문제는 이렇게 생성된 Key:value 들에서 노드는 서로 다르지만 같은 키 값을 지닌 쌍들이 있는 것이다.
위에 이미지에서는 1번 Mapper에서 Dear와 3번 Mapper Dear라는 값이 있다. 이를 적절히 Reduce해주기 위해서는 이 값들이 모두 동일한 Reducer에게 전달이 되어야 하기 때문에 Shuffling과정이 필요하다.
Shuffling 과정은 Partitioner과 Combiner과정이 있다.
Partitionerd은 서로 다른 Mapper에서 생성된 중간결과 Key:Value Pair들을, Key중심으로 같은 키 가진 데이터는 물리적으로 동일한 Reducer로 데이터를 보내는 과정이다.
Combiner는 파티션 내의 Key Value 데이터들에 대해서 리듀스 작업을 진행하여 리듀서 노드들의 부하를 줄여주는 작업을 말한다.
- Reduce, Write
Shuffling 과정을 마친 데이터를 각각의 Reducer가 읽어와서 단어별 개수 카운팅을 완료하였다. 그리고 그 결과를 파일 형태로 출력하게 된다. MapReduce는 reduce 결과로 생성된 Key Value 값들을 별도로 취합하지 않고 input file을 쪼개어 저장했을 때 처럼 분산 파일 시스템에 저장한다. 이는 reduce 결과물들을 다시 취합해야하는 수고를 덜어주고, 결과 데이터들을 가지고 다시 MapReduce 작업을 진행하기가 편리하다.
참고 사이트
