
CSAPP 9장
9.9 동적 메모리 할당
동적 메모리 할당기
동적 메모리 할당기는 힙(heap)이라는 프로세스의 가상 메모리 영역을 관리한다. 이 데이터 영역은 미초기화된 영역 직후에 시작해서 위쪽으로 데이터가 흐른다고 가정한다.
할당기는 다양한 크기의 블록을 통해 집합으로 관리한다. 각 블록은 할당 되었거나 가용한 메모리의 연속적인 묶음이다.
할당기는 기본적으로 두가지 유형이 가능하다.
- 명시적인 할당기 → 명시적으로 할당된 블록을 반환할 것을 요구한다. C언어의 malloc을 대표적인 예시로 볼 수 있다. malloc은 호출하여 블록을 할당하고, free를 통해 블록을 반환한다.
- 묵시적인 할당기 → 할당기는 사용하지 않는 메모리 블록을 반환하는지 검출할 수 있도록 요구한다. List, ML, 자바와 같은 상위 언어들이 이런 할당된 메모리를 반환하기 위해서 가비지 컬렉션을 사용한다.
malloc & free
malloc은 함수를 호출해서 힙으로부터 블록을 할당받는다.
malloc은 블록 내에 포함될 수 있는 종류의 데이터 객체에 대해서 적절히 정렬된 최소 size 바이트를 갖는 메모리 블록의 포인터를 리턴한다. 32비트 모드의 경우 8의 배수 블록을 리턴하고 64비트 모드의 경우 16비트 배수의 블록을 리턴한다.
malloc은 블록을 할당받기만 할 뿐, 블록 내부를 초기화하진 않는데, calloc을 통해 선언과 함께 할당된 메모리를 0으로 초기화할 수 있다.
malloc와 같은 메모리 동적 할당기는 mmap와 mnumap 함수를 통해서 메모리를 동적할당하거나 반환하며 sbrk함수를 사용할 수 있다.
sbrk 함수는 커널 brk 포인터에 incr를 더해서 힙을 늘리거나 줄인다. 성공하면 brk의 값을 리턴하고 실패하는 경우 -1을 리턴하고 ENOMEM을 설정한다.
왜 동적할당인가?
동적 메모리 할당을 사용하는 가장 중요한 이유는 실행시 프로그램에서 사용하는 자료 구조의 크기를 알 수 없는 경우가 많기 때문이다.
정적 배열을 통해 정의를 했지만 실제 실행에서 그것보다 더 큰 크기의 데이터를 사용하게 되면 더 큰 정적배열을 다시 정의해서 프로그램을 다시 실행시켜야 한다. 이러한 경우 동적 메모리 할당을 사용하게 되면 불편을 해결할 수 있다. 하지만 무한정 메모리를 할당할 수 있는 것은 아니며, 가용할 수 있는 가상 메모리의 양에 의해 제한된다.
할당기의 제한사항과 목표
-
제한사항
- 임의의 요청 순서 처리하기 : 응용 프로그램은 각각의 가용 블록이 이전의 할당 요청에 의해 현재 할당된 블록에 대응되어야 한다는 제한 사항을 만족하면서 임의의 순서로 할당과 반환 요청을 할 수 있다. → 새로운 할당요청이 들어오면 사용 가능한 크기의 메모리 블록을 찾아야하며, 이 메모리 블록은 언제든 필요한 순간에 해제할 수 있어야 한다.
- 요청에 즉시 응답하기 : 어떤 종류의 데이터 형식이더라도 저장할 수 있어야 한다.
- 힙만 사용하기 : 확장성을 갖기 위해 할당기가 사용하는 비확장성 자료 구조들은 힙 자체에 저장되어 있어야한다.
- 블록 정렬하기 : 할당기는 블록들을 이들이 어떤 유형의 데이터 객체도 저장할 수 있는 방식으로 정렬되어야 한다.
- 할당된 블록 수정하지 않기 : 할당기는 가용 블록을 조작 또는 변경만 가능하다. 특히 가용블록이 할당되면 이 블록을 수정하거나 이동하지 않는다.
- 임의의 요청 순서 처리하기 : 응용 프로그램은 각각의 가용 블록이 이전의 할당 요청에 의해 현재 할당된 블록에 대응되어야 한다는 제한 사항을 만족하면서 임의의 순서로 할당과 반환 요청을 할 수 있다. → 새로운 할당요청이 들어오면 사용 가능한 크기의 메모리 블록을 찾아야하며, 이 메모리 블록은 언제든 필요한 순간에 해제할 수 있어야 한다.
-
목표
- 처리량 극대화하기 : 일반적으로 할당과 반환 요청을 만족시키기 위한 평균 시간을 최소화해서 처리량을 최대화한다.
- 메모리 이용도를 최대화하기 : 메모리는 유한한 자원임을 명심해야하며, 시스템에서 모든 프로세스에 의해 할당된 가상 메모리 양은 디스크 내의 스왑 공간의 양에 의해 제한된다.
단편화 ( 여기 더 알아보기 )
- 내부 단편화 : 할당된 블록이 데이터 자체 보다 더 클 때 발생한다. 내부 단편화는 정량화하기 간단하다. 할당된 블록의 크기와 이들 데이터 차이의 합이다.
- 외부 단편화 : 할당 요청을 만족할 수 있는 메모리 공간이 전체적으로 공간을 모았을 때는 충분한 공간이 존재하지만 요청을 처리할 수 있는 단일 가용블록이 없는 경우 발생한다. 외부 단편화를 정량화하는 것은 내부 단편화 보다 어렵다. 이전 패턴과 할당기 구현에만 의존하는 것이 아닌 미래의 요청 패턴이 외부 단편화에 영향을 주기 때문이다.
구현 이슈
묵시적 가용 리스트
모든 할당기는 내부 블록의 경게를 구분하고, 할당된 블록과 아직 할당되지 않은 가용블록을 구분하는 데이터 구조를 가지고 있다.
묵시적 할당기의 한 블록은 1워드 헤더, 데이터, 추가 패딩으로 구성되어 있다. 헤더에서는 현재 블록이 할당된 상태인지, 또는 가용 상태인지를 나타내고, 그 뒤부터 데이터가 들어간다. 그래서 항상 하위 3비트에는 이러한 정보들이 들어가기 위해 비워두고, 나머지 공간에 대해서만 데이터 저장을 위해 사용한다.
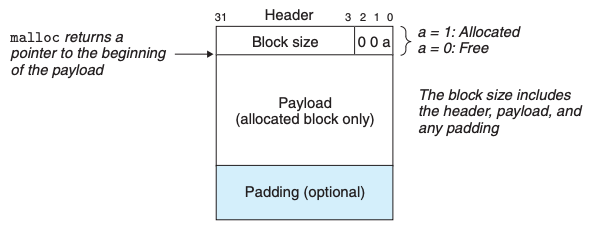
요구한 데이터를 넣고, 그 다음 사용하지 않는 가변 패딩을 추가한다. 이는 외부 단편화를 방지하고, 정렬 요구사항을 만족하기 위해 사용한다.
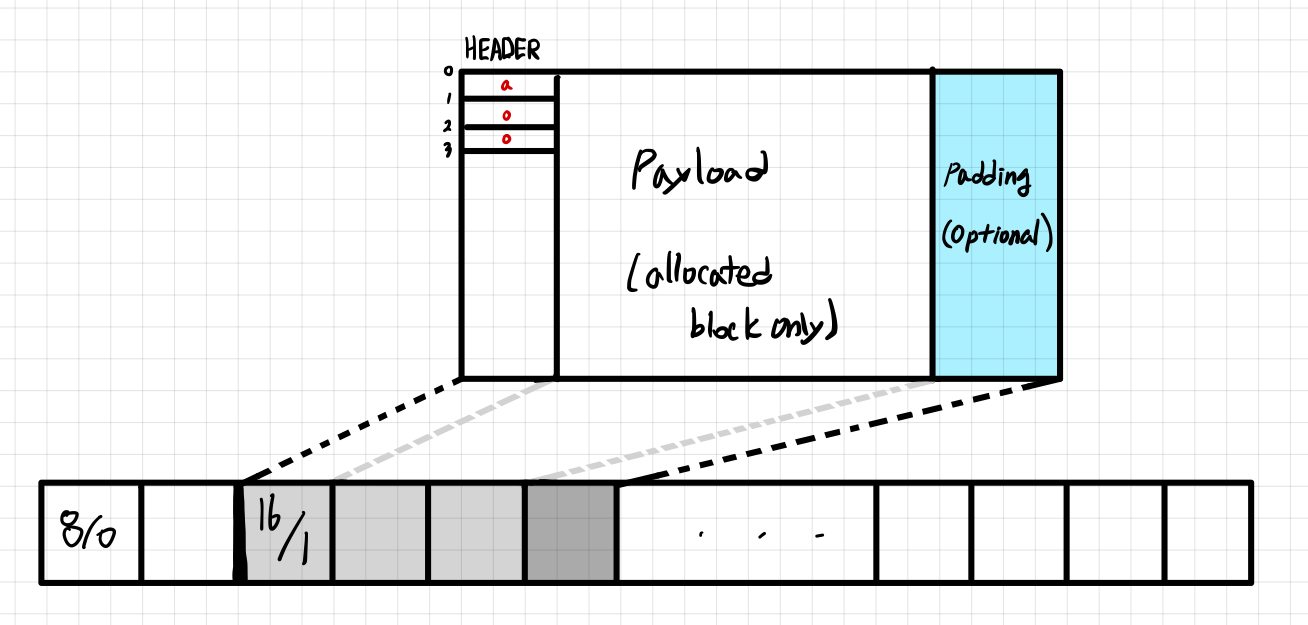
묵시적 가용리스트와 리스트를 이루는 블록의 구성을 위와 같이 보면 조금 편했다.
묵시적 가용 리스트는 헤더내 필드를 통해 암묵적으로 연결되어있는데 이를 통해서 힙 내부의 전체 블록을 다닐 수 있다. 이러한 특성에 의해서 단순성이라는 장점을 가진다.
하지만 묵시적 가용 리스트이 단점은 할당된 블록을 배치, 탐색과 같은 리스트의 연산이 할당된 블록과 가용 블록의 수에 비례하게 계산된다는 것이다.
할당한 블록의 배치
할당기는 요청한 블록을 저장하기 충분하게 큰 가용 블록을 리스트에서 검색한다. 이런 배치 정책은 first fit, next fit, best fit이 존재한다.
First fit은 가용리스트의 처음부터 연결해서 크기가 맞는 첫번째 가용 블록을 선택한다.
큰 가용 블록을 비교적 남겨두는 경향을 장점으로 꼽을 수 있고, 단점으로는 큰 가용 블록을 찾을 때는 작은 가용블록을 앞에 남겨두는 경향으로 인해서 큰 블록을 찾는데 오래걸린다는 점을 꼽을 수 있다.
Next fit은 first fit과 비슷하지만 검색 시작 지점이 이전에 삽입된?, 검색이 종료된? 위치에서 검색을 시작한다.
Next fit은 first fit의 대안으로 나왔다. 보다 더 빠른 검색 속도를 장점으로 꼽을 수 있지만, 3가지 배치 방법 중에서는 가장 최악의 메모리 이용도를 보인다는 단점이 있다.
🤨 이전에 삽입이 완료된 위치? 검색이 완료된 위치? 검색이 완료된 후 가용 블록에 삽입이 되었다면, 이후 검색이 완료된 위치에서부터 다시 검색을 시작한다. 하지만 검색 완료된 위치는 이미 블럭이 삽입됐는데 왜 이미 사용하는 것이 확실한 부분부터 검색하는 것이 궁금했다. 검색 완료된 위치부터 검색을 하는 이유는 검색이 완료된 위치부터 순서대로 헤더가 들어가게 되는데 이 헤더를 통해서 다음 헤더의 위치를 찾을 수 있게 된다. 블록 전체를 조사하는게 아니라 다음 블록으로 가기 위해서 이전 블록의 헤더에 있는 정보가 필요하기 때문이다.Best fit은 모든 가용 블록을 검사하며 크기가 맞는 가장 작은 블록을 선택한다.
Best fit의 경우 다른 두 배치 방법보다 더 효율적인 메모리 이용도를 갖지만, 힙의 모든 영역을 조사해야한다는 점을 단점으로 꼽을 수 있다.
가용 블록의 분할
가용 블록을 찾은 후 블록에 어느 정도 할당할 것인지 결정해야한다. 블록을 모두 사용하는 방법을 통해서 빠르게 처리할 수 있지만 내부 단편화가 발생한다. 그래서 가용 블록을 두 부분으로 나누어 블록을 할당하고 남은 부분은 새로운 가용블록이 된다.
추가적인 힙 메모리 획득하기
할당기가 블록을 찾을 수 없는 경우에 가용 블록을 조합해서 큰 블록을 만들기도 하지만 블록이 이미 충분히 사용된 경우 커널에 sork함수를 호출해 추가적인 힙 메모리를 요청한다. 추가 메모리를 큰 가용 블록으로 변환하고, 가용리스트에 삽입한 후 요청한 블록을 새로운 가용 블록에 배치한다.
🤨 힙 메모리를 얼마나 보내주는거죠? 특정 양이 정해져 있는 것이 아니라 시스템에 따라, 운영체제의 가용 메모리의 양, 프로세스가 요청한 메모리 양, 시스템 정책에 따라 결정된다.가용 블록 연결하기
할당기가 할당된 블록을 반환할 때, 새롭게 반환 하는 블록에 인접해서 가용 블록들이 있을 수 있다. 이러한 인접 가용 블록들은 오류 단편화(Falut Fragmentation)을 유발할 수 있다
오류 단편화를 극복하기 위해 연결(coalescing)이라는 과정으로 인접 가용 블록을 연결해야한다. 연결은 언제 연결하냐에 따라 즉시 연결, 지연 연결로 나뉜다.
- 즉시 연결 : 블록이 반환 될때 마다 인접 블록을 통합하는 방법
- 지연 연결 : 일정 시간 후에 가용 블록들을 연결하기 위해 기다렸다가 연결하는 방법
즉시 연결을 사용하는 경우 간단하게 상수 시간 내 수행이 가능하지만 일부 패턴에 대해서는 블록이 연결되고 잠시 다시 분할 되는 쓰레싱의 형태를 유발할 수 있다.
경계 태그로 연결하기
가용 블록을 연결하는 방법 중 하나로서, 각 블록 끝에 풋터(경계 태그)를 추가하는 방법이다. 이 풋터는 헤더를 복사한 것이고, 할당기는 시작 위치와, 이전 블록의 상태를 자신의 풋터를 조사해서 결정할 수 있다. 경계 태그를 사용하는 것은 메모리 블록의 크기를 추적할 수 있고, 오류 단편화를 해결할 수 있게 해주지만, 각 블록이 헤더와 풋터를 유지하고 있어야 하기 때문에, 작은 크기의 블록을 여러개 다루게 되면 상당한 양의 메모리 오버헤드가 발생한다는 단점을 가지고 있다.
