
⚽️ Main Goal
프로그램의 파일 이름과 인자를 분리하고 유저 스택에 인자 넣기!
⚙️ 구현하기
file name 및 token parsing을 위해 strtok_r() 이해
char *
strtok_r (char *s, const char *delimiters, char **save_ptr) {
char *token;
ASSERT (delimiters != NULL);
ASSERT (save_ptr != NULL);
/* If S is nonnull, start from it.
If S is null, start from saved position. */
if (s == NULL)
s = *save_ptr;
ASSERT (s != NULL);
/* Skip any DELIMITERS at our current position. */
while (strchr (delimiters, *s) != NULL) {
/* strchr() will always return nonnull if we're searching
for a null byte, because every string contains a null
byte (at the end). */
if (*s == '\0') {
*save_ptr = s;
return NULL;
}
s++;
}
/* Skip any non-DELIMITERS up to the end of the string. */
token = s;
while (strchr (delimiters, *s) == NULL)
s++;
if (*s != '\0') {
*s = '\0';
*save_ptr = s + 1;
} else
*save_ptr = s;
return token;
}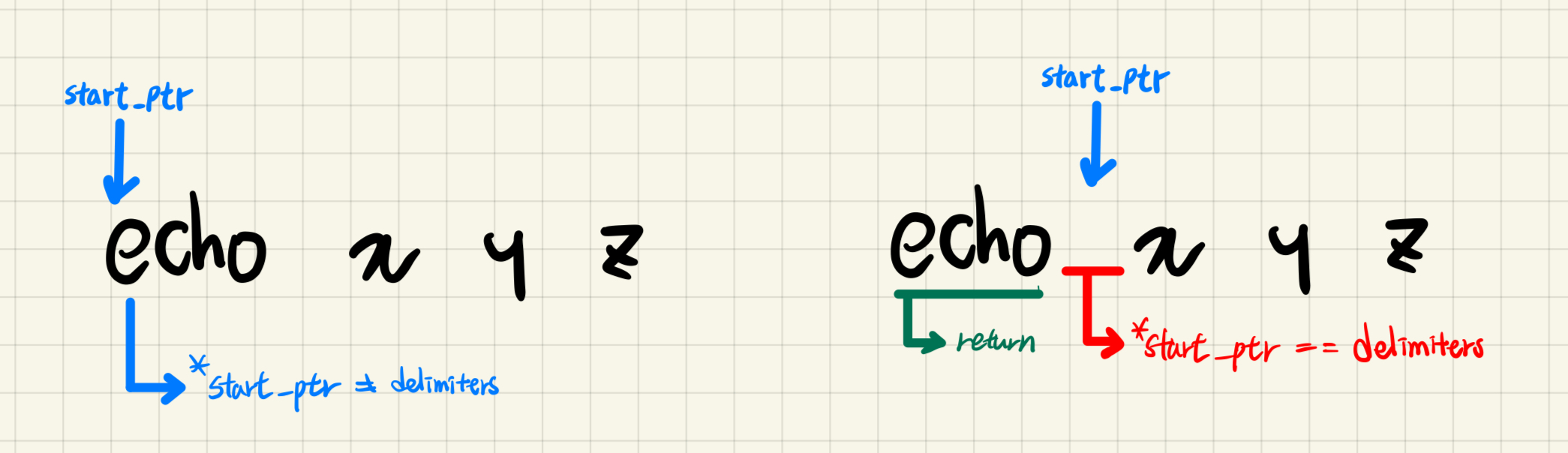
문자열 s 내부에 delimeter가 있으면 delimeter를 만날때 까지 반복을 돌고, 만났을 때해당 문자의 포인터 이전의 문자열을 return한다. 그리고 포인터를 이동하며 문자를 확인하기 때문에 다음 parsing을 시작할 때 delimeter 이후부터 다시 반복한다.
delimeter가 없는 경우, 문자열 전체를 돌면서 문자열 끝에 도달했을 때 해당 문제를 출력한다.
전달받은 f_name을 파싱하기 위해서는 모든 문자를 순회할 때까지 반복해서 strtok_r함수를 적용해주면 된다.
char *tokens[MAX_TOKEN_COUNT];
int count = 0;
token = strtok_r(f_name, " ", &token_ptr);
while (token != NULL && count < MAX_TOKEN_COUNT) {
tokens[count] = (char *)malloc(strlen(token) + 1); // 메모리 할당
strlcpy(tokens[count], token, strlen(token) + 1);
printf("%d : %s\n", count, tokens[count]);
count++;
token = strtok_r(NULL, " ", &token_ptr);
}
```
<br />
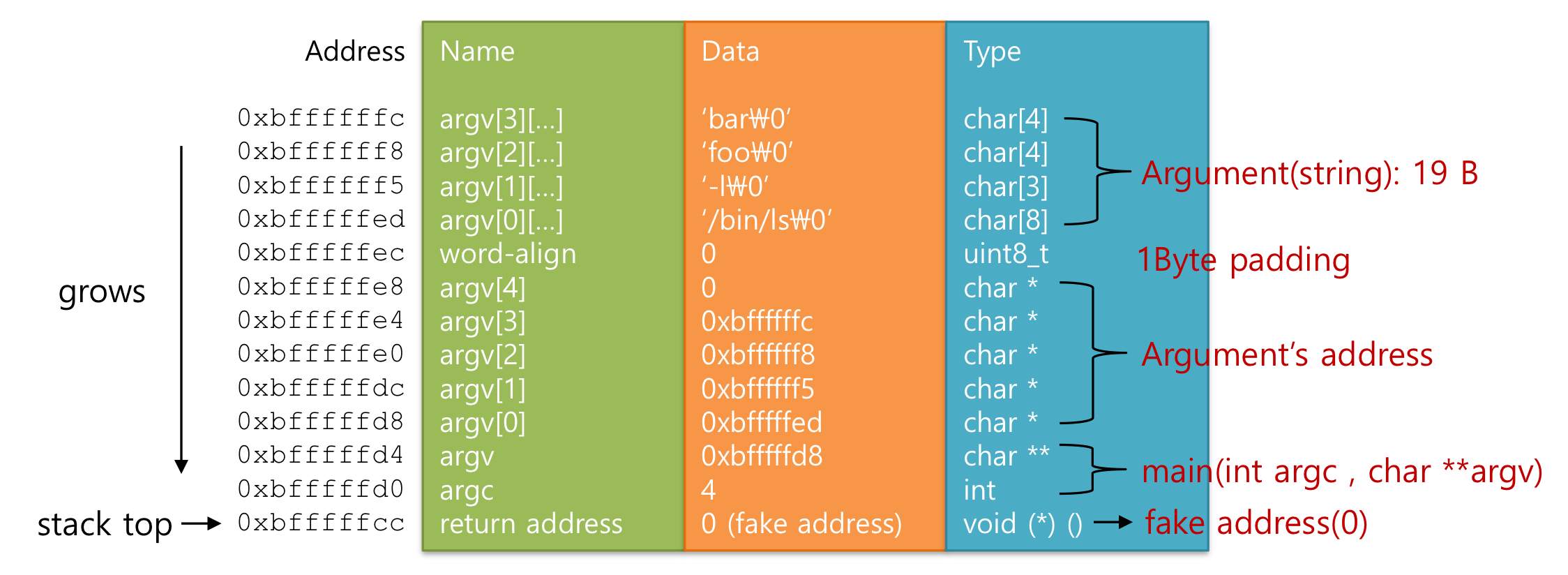
### User Stack
argument_stack()에 intrrupt frame의 rsp를 시작으로 tokens 내부의 데이터를 User Stack에 삽입한다. 이때 스택에는 위에서 아래 방향으로 삽입된다.
```c
void argument_stack (char *tokens[], int count, uintptr_t *rsp) {
uintptr_t *args = malloc(count * sizeof(uintptr_t)); // 포인터를 임시 저장할 배열
for (int j = count - 1; j >= 0; j--) {
int length = strlen(tokens[j]) + 1; // 널 종료 문자를 포함한 길이
*rsp -= length; // 스택 포인터를 감소시켜 공간 확보
memcpy((void*)*rsp, tokens[j], length); // 사용자 스택에 문자열 복사
args[j] = *rsp; // 복사된 문자열의 시작 주소 저장
free(tokens[j]);// 사용된 메모리 해제
}
// 8바이트 정렬을 가정하고 스택 정렬
int alignment = *rsp % 8;
if (alignment != 0) {
*rsp -= alignment; // 8바이트 정렬을 맞추기 위해 조정
memset(*rsp, 0, alignment); // 0으로 초기화
}
// 0을 추가
*rsp -= sizeof(char*);
memset((char*)*rsp, 0, sizeof(char*)); // 0으로 초기화
// 포인터 배열을 스택에 저장
for (int j = count - 1; j >= 0; j--) {
*rsp -= sizeof(char *); // 스택 포인터를 감소시켜 포인터 저장 공간 확보
*((char**)*rsp) = args[j]; // 포인터 저장
}
// 함수의 반환 값 주소 저장
*rsp -= sizeof(void *);
*(void **)(*rsp) = NULL;// 실제 사용시 반환 값이 저장될 주소를 지정
free(args); // 더 이상 사용하지 않는 args 배열 메모리 해제
}void process_exec (void *f_name) {
...
argument_stack (tokens, count, &_if.rsp);
_if.R.rdi = count; // %rsi 영역에 argument count 직접할당
_if.R.rsi = _if.rsp + sizeof(void*); // %rdi 영역에 argv(0번째 요소의 주소) 직접할당
...
}구현후 아래와 같이 완성된 결과를 확인할 수 있다.

💫 트러블 슈팅
- padding이 적게들어가는 현상
// 8바이트 정렬을 가정하고 스택 정렬
uintptr_t alignment = (uintptr_t)*rsp % 8;
if (alignment != 0) {
*rsp -= 8 - alignment; // 8바이트 정렬을 맞추기 위해 조정
memset((void*)*rsp, 0, 8 - alignment); // 0으로 초기화
}위 코드는 인자를 User Stack에 삽입후 8바이트 단위로 정렬을 맞추기 위해 Padding을 넣어주는 로직이다.
하지만 위 코드로 테스트했을때 Padding이 적게 들어가는 현상이 발생했다.

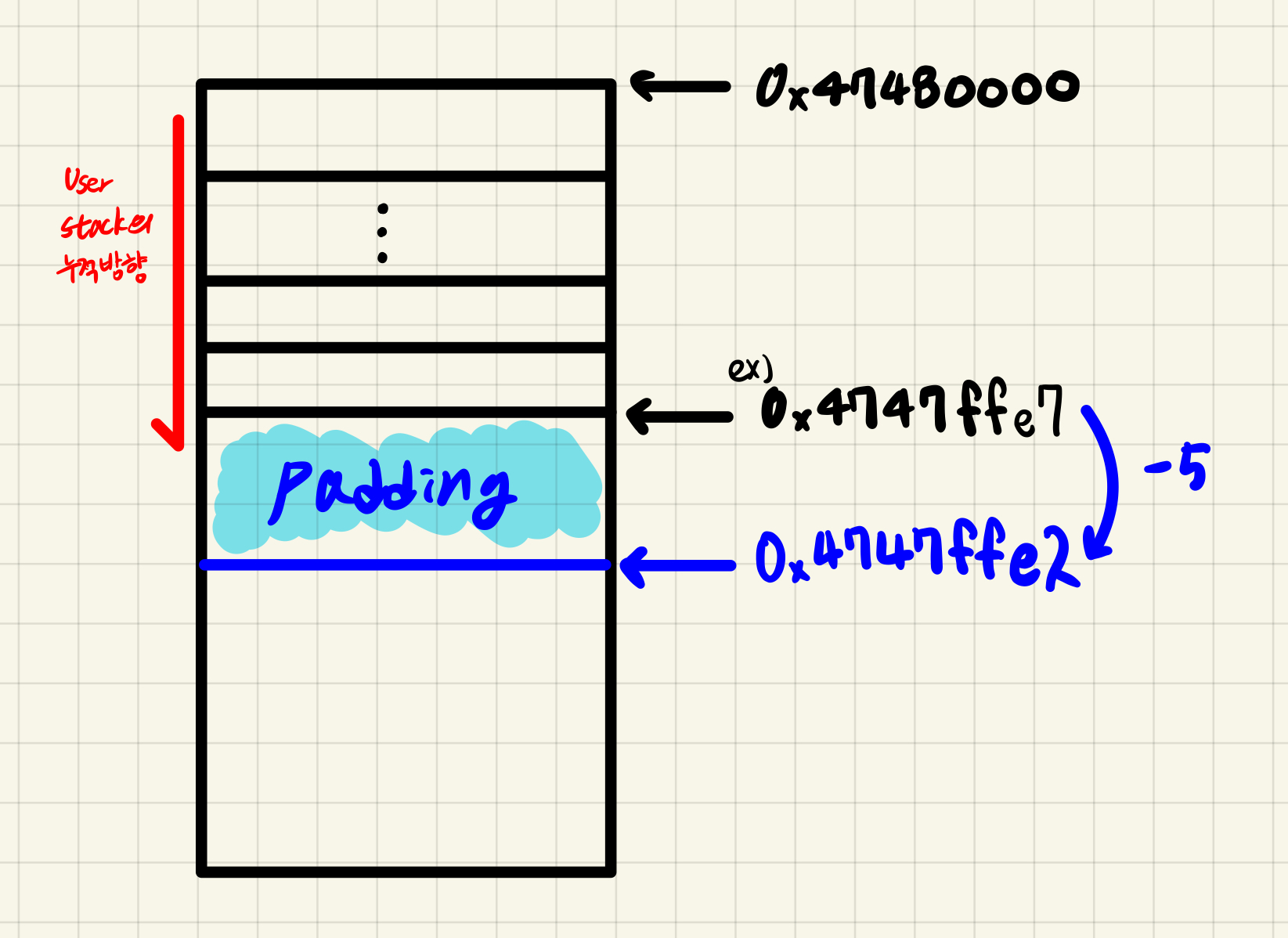
위 그림에서 보다시피 User Stack에서 주소값은 초기 값인 0x47480000 에서 시작해서 주소값을 줄여가며 인자를 삽입한다. 모든 인자를 넣은 주소 값이 0x4747ffe7 이라고 할때 해당 주소값에서 “8로 나눈 나머지만큼” 빼주어야 8바이트 정렬이 가능하다. 그렇다면 아래와 같이 수정해 볼 수 있다.
// 8바이트 정렬을 가정하고 스택 정렬
uintptr_t alignment = (uintptr_t)*rsp % 8;
if (alignment != 0) {
*rsp -= alignment; // 8바이트 정렬을 맞추기 위해 조정
memset((void*)*rsp, 0, alignment); // 0으로 초기화
}스택 주소 값이 줄어드는 점을 간과해서 발생한 실수였다.
