오늘은 탐색 알고림즘 중에서 bfs/dfs에 대해 알아보겠습니다.
알고리즘을 안 푼지 4달정도 지나서 머리가 백지 상태가 되어서 처음부터 다시 가야되는 상황입니다. 😭😭
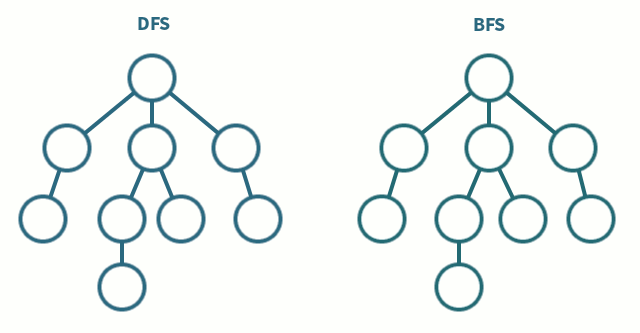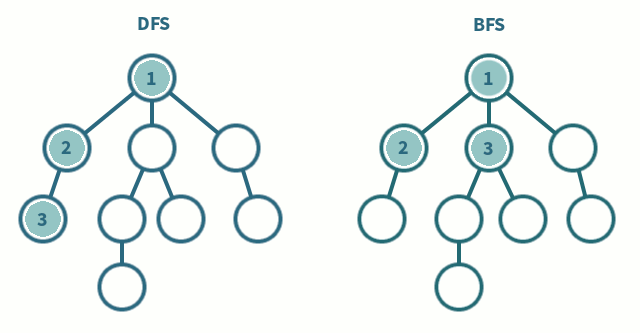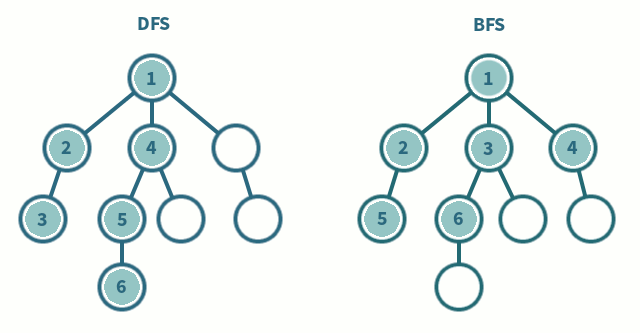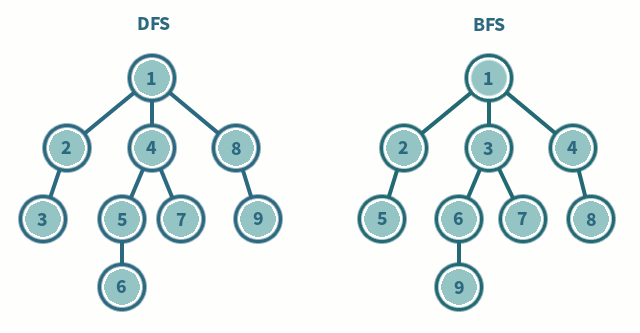
DFS (깊이 우선 탐색)
트리나 그래프에서 한 루트로 탐색하다가 특정 상황에서 최대한 깊숙이 들어가서 확인한 뒤 다시 돌아가 다른 루트로 탐색하는 방식
DFS는 가장 깊은 노드까지 방문한 후 더 이상 방문할 노드가 없으면 방문한 노드로 돌아온 다음, 해당 노드(돌아온 노드)에서 방문할 노드가 있는지 확인합니다.
자료구조로 스택 또는 재귀함수를 사용합니다.
저는 재귀로 예시를 들어봤습니다.
import javax.swing.*;
import java.lang.reflect.Array;
import java.util.ArrayList;
import java.util.Arrays;
public class Solution {
private static ArrayList<Integer>[] adjList;
private static boolean[] visited;
private static ArrayList<Integer> answer;
private static int[] solution(int[][] graph, int start, int n) {
// 인접 리스트 초기화
adjList = new ArrayList[n + 1];
for (int i = 0; i < adjList.length; i++) {
adjList[i] = new ArrayList<>();
}
for (int[] edge : graph) {
adjList[edge[0]].add(edge[1]);
}
visited = new boolean[n + 1];
answer = new ArrayList<>();
dfs(start);
return answer.stream().mapToInt(Integer::intValue).toArray();
}
private static void dfs(int now) {
visited[now] = true;
answer.add(now);
for (int next : adjList[now]) {
if (!visited[next]) {
dfs(next);
}
}
}
public static void main(String[] args) {
System.out.println(Arrays.toString(solution(new int[][]{{1, 2}, {2, 3}, {3, 4}, {4, 5}}, 1, 5)));
}
}
-
코드 설명
private static ArrayList<Integer>[] adjList; private static boolean[] visited; private static ArrayList<Integer> answer;- adjList: 인접리스트(그래프)를 담기위한 리스트
- visited: 방문 여부를 확인하는 배열
- answer: 결과 값을 넣을 리스트
private static int[] solution(int[][] graph, int start, int n) { // 인접 리스트 초기화 adjList = new ArrayList[n + 1]; for (int i = 0; i < adjList.length; i++) { adjList[i] = new ArrayList<>(); } for (int[] edge : graph) { adjList[edge[0]].add(edge[1]); } visited = new boolean[n + 1]; answer = new ArrayList<>(); dfs(start); return answer.stream().mapToInt(Integer::intValue).toArray(); }
- solution 메서드의 매개변수
- graph: 2차원 배열 주어진 배열
- start: 시작 노드
- n: 노드 개수
- 인접리스트(그래프) 만들기
// 인접 리스트 초기화
adjList = new ArrayList[n + 1];
for (int i = 0; i < adjList.length; i++) {
adjList[i] = new ArrayList<>();
}
for (int[] edge : graph) {
adjList[edge[0]].add(edge[1]);
}그래프 만드는 법입니다.
-
adjList = new ArrayList[n + 1];- 예를들어 n(노드)가 5개면 + 1을 해서 6의
ArrayList를 초기화 합니다.
- 예를들어 n(노드)가 5개면 + 1을 해서 6의
-
첫번째
for문- 초기화한
adjList는ArrayList의 배열입니다. 즉,ArrayList을 6개 담을 수 있는 그릇이 6개가 생겼습니다. 하지만 기본값이null이기 때문에 다시 for문을 돌려서 초기화를 해줍니다.
- 초기화한
-
두번째
for문- 인접 리스트를 만들어 줍니다.
{{1, 2}, {2, 3}, {3, 4}, {4, 5}}를 넣어준다면-
1 - [2]
2 - [3]
3 - [4]
4 - [5]라는 결과가 나옵니다. 1은 2와 간선으로 연결되있다라는 뜻입니다.
다른 예시로
{{1, 2}, {1, 3}, {2, 4}, {2, 5}, {3, 6}, {5, 6}}을 넣으면 -
1 - [2, 3]
2 - [4, 5]
3 - [6]
4 - []
5 - [6]
6 - []라는 리스트가 만들어집니다.
-
- 인접 리스트를 만들어 줍니다.
-
방문 여부 및, 정답 리스트
visited = new boolean[n + 1]; answer = new ArrayList<>();- visited : 방문 여부 확인여부 boolean 배열
- answer: 결과를 넣을 리스트
-
dfs 함수
private static void dfs(int now) { visited[now] = true; answer.add(now); for (int next : adjList[now]) { if (!visited[next]) { dfs(next); } } }코드 흐름도를 봅시다. 아까 만든 인접리스트를 활용해봅시다.
DFS 탐색 과정 (재귀)
예시 그래프:
{{1, 2}, {2, 3}, {3, 4}, {4, 5}}시작 노드:
11️⃣. 시작 노드
1방문
-visited[1] = true로 설정 노드1을 방문 처리합니다.
-answer리스트에1을 추가 (answer = [1])
- 노드1의 이웃 노드인2를 확인합니다.2️⃣. 노드
2방문
-visited[2] = true로 설정하여 노드2을 방문 처리합니다.
-answer리스트에2를 추가 (answer = [1, 2])
- 노드2의 이웃 노드인3을 확인합니다.3️⃣. 노드
3방문
-visited[3] = true로 설정하여 노드3을 방문 처리합니다.
-answer리스트에3을 추가 (answer = [1, 2, 3])
- 노드3의 이웃 노드인4를 확인합니다.4️⃣. 노드
4방문
-visited[4] = true로 설정하여 노드4을 방문 처리합니다.
-answer리스트에4를 추가 (answer = [1, 2, 3, 4])
- 노드4의 이웃 노드인5를 확인합니다.5️⃣. 노드
5방문
-visited[5] = true로 설정하여 노드5을 방문 처리합니다.
-answer리스트에5를 추가 (answer = [1, 2, 3, 4, 5])
- 노드5의 이웃 노드가 없으므로, 재귀 호출을 종료하고 이전 단계로 돌아갑니다.6️⃣. 노드
4로 돌아감
- 노드4의 이웃 노드인5는 이미 방문했으므로, 더 이상 탐색할 노드가 없습니다.
- 재귀 호출을 종료하고 이전 단계로 돌아갑니다.7️⃣~9️⃣. 노드
3~ 노드1까지 돌아갑니다.
BFS (너비 우선 탐색)
BFS는 갈림길에 연결되어 있는 모든 길을 한번씩 탐색한 뒤 다시 연결되어 있는 모든 길을 넓게 탐색한다.
이제 앞의 dfs와 bfs는 인접 리스트(노드)를 만드는거 까지는 똑같습니다.
달라진 점은 bfs의 자료구조는 queue(큐)를 사용합니다.
private static void bfs(int start) {
ArrayDeque<Integer> queue = new ArrayDeque<>();
queue.add(start);
visited[start] = true;
while (!queue.isEmpty()) {
int now = queue.poll();
answer.add(now);
for (int next : adjList[now]) {
if (!visited[next]) {
queue.add(next);
visited[next] = true;
}
}
}
}{{1, 3}, {3, 4}, {3, 5}, {5, 2}} 로 예시를 들어보겠습니다.
BFS 탐색 과정
- 시작 노드
1을 큐에 넣고 방문합니다. 큐 =[1]->visited[1] = true. - 큐에서
1을 꺼내고 이웃인3을 큐에 넣고 방문합니다. 큐 =[3]->visited[3] = true. - 큐에서
3을 꺼내고 이웃인4,5를 큐에 넣고 방문합니다. 큐 =[4, 5]->visited[4] = true,visited[5] = true. - 큐에서
4를 꺼내지만 이웃이 없으므로 넘어갑니다. 큐 =[5]. - 큐에서
5를 꺼내고 이웃인2를 큐에 넣고 방문합니다. 큐 =[2]->visited[2] = true. - 큐에서
2를 꺼내지만 이웃이 없으므로 탐색을 종료합니다.
차이점
깊이 우선 탐색(dfs)은 깊게 탐색 후 되돌아 오는 특성이 있으며, 너비 우선 탐색(bfs)은 가중치가 없는 그래프에서 최단 경로를 보장하는 차이점을 보입니다.
