JPA를 사용할때 영속성 컨텍스트의 이점으로 1차 캐시가 있는데, 1차 캐시가 어떤 방식으로 작동하는지 알아보겠습니다.
먼저 설명하기 위한 엔티티 예시를 보겠습니다.
@Entity
class Member {
@Id @GeneratedValue
Long id;
String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
Team team;
void setTeam(Team team){
this.team = team;
this.team.getMembers().add(this);
}
}
@Entity
class Team{
@Id @GeneratedValue
Long id;
String name;
@OneToMany(mappedBy = "team")
List<Member> members = new ArrayList<>();
}단순하게 팀과 멤버가 일대다 관계를 갖고 있습니다.
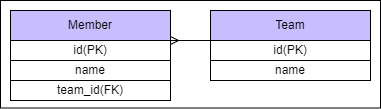
현재 DB에 저장된 데이터 정보
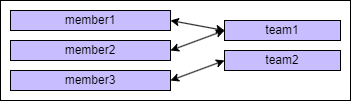
현재 DB에 Member 엔티티로 member1, member2, member3
Team 엔티티로 team1, team2가 저장되어 있다.
member1, member2는 team1 소속이고,
member3은 team2 소속이다.
기본적인 테스트
우선 영속성 컨텍스트는 한번 조회했던 객체를 나중에 다시 조회할때,
미리 저장해놔서 다시 DB에 쿼리를 보내지 않고 조회 가능하다고 알고있습니다.
한번 테스트해보겠습니다.
Optional<Member> result1 = memberRepository.findById(mIds.get(0));
System.out.println(result1.get());mIds는 멤버들의 id를 갖고있는 리스트입니다
memberRepositroy와 teamRepository는 스프링 데이터 JPA를 이용했습니다.
위 코드를 실행하면 나타나는 결과는
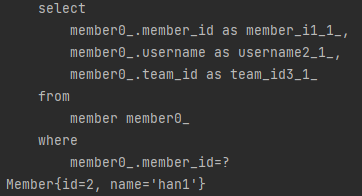
spring.jpa.properties.hibernate.format_sql: true
logging.level.org.hibernate.SQL: debug
을 통해 SQL 로그를 확인했습니다.
쿼리를 한번만 보냈다.
이는 당연한 결과다. 데이터를 한번만 조회했기 때문입니다.
이때 같은 쿼리를 두번 보낸다면,
Optional<Member> result1 = memberRepository.findById(mIds.get(0));
System.out.println(result1.get());
Optional<Member> result2 = memberRepository.findById(mIds.get(0));
System.out.println(result2.get());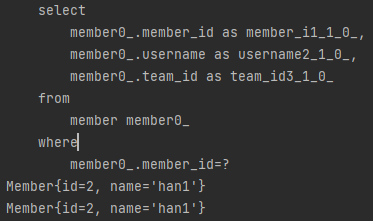
같은 객체를 두번 find 했지만, 조회 쿼리는 1번만 보냈습니다.
영속성 컨텍스트가 1차캐시를 통해 기존의 객체를 저장해놨기 때문입니다.
id가 아닌 name을 통한 조회
그럼 id를 통해 조회하는게 아니라 name을 통해 조회한다면 어떤 결과가 나올까요?
저는 처음에는 한 객체를 두번 조회하면, 해당 객체가 1차 캐시를 통해,
영속성 컨텍스트에 저장되있기 때문에 추가적인 조회 쿼리가 나가지 않을 것이라고 예상했습니다.
다음은 예시입니다.
Optional<Member> result1 = memberRepository.findByName("han1");
System.out.println(result1.get());
Optional<Member> result2 = memberRepository.findByName("han1");
System.out.println(result2.get());위 코드의 결과는,
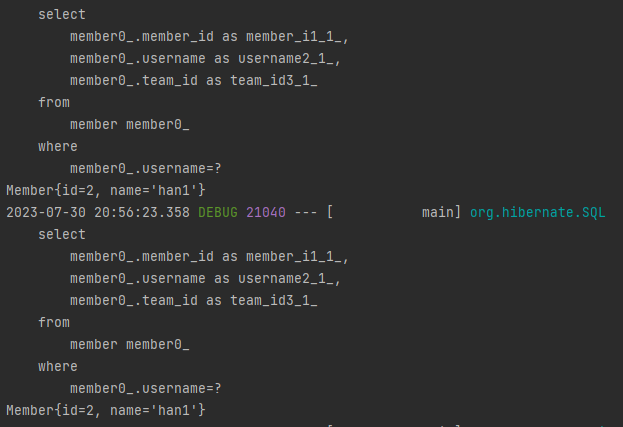
같은 객체를 두번 조회했을때, DB로 두번의 쿼리가 나갔습니다.
이유가 무엇일까요?
1차캐시의 PK
한번 객체를 조회했을때 해당 객체는 영속성 컨텍스트의 1차캐시에 저장됩니다.
해당 객체는 1차캐시에서 PK를 통해 구별됩니다.
여기선 PK가 id입니다
따라서 id가 아닌 name을 통해 객체를 두번 조회하면,
name은 PK가 아니기 때문에 쿼리가 두번 나가게 되었습니다.
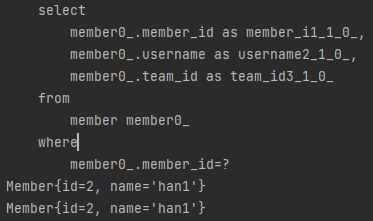
그럼 처음에는 name을 통해 조회하고, 두번째로 id를 통해 조회하면 쿼리가 몇번 나갈까요?
Optional<Member> result1 = memberRepository.findByName("han1"); System.out.println(result1.get()); Optional<Member> result2 = memberRepository.findById(mIds.get(0)); System.out.println(result2.get()); // "han1"과 mIds.get(0)은 같은 객체의 정보입니다정답은 한번만 나갑니다.
처음 이름을 통해 조회했을때, 1차캐시에 저장되고, 해당 객체는 PK를 통해 식별하기 때문에 추가 쿼리가 나가지 않습니다.그런데 이런 케이스는 쓸 일이 거의 없을 것 같습니다...
1차캐시와 프록시객체(지연로딩)
사실 이번 글은 이 부분을 위해 작성했습니다.
JPA를 사용할때 엔티티 사이에 다양한 연관관계가 생기는데,
거의 모든 연관관계에 지연로딩을 적용시키고 있습니다.
지연로딩을 적용시키면 처음 객체를 조회할때,
해당 객체와 연관되어 있는 객체는 프록시 객체로 조회된 후에,
나중에 실제로 연관되어 있는 객체를 조회할때 실제 객체를 조회하게 됩니다.
이때 추가 쿼리가 발생할 수 있습니다.
프록시 객체를 조회하면 추가 쿼리가 발생할 수 있는데, 만약 해당 객체가 이미 1차캐시에 저장되어 있다면 추가쿼리가 발생할까요? 발생하지 않을까요?
이번 테스트는 위에서 기술한 일대다 관계(OneToMany)의 Team과 Member를 통해서 진행했습니다.
FK가 Many쪽에 있는 걸로 생각하고 테스트 하겠습니다.
거의 모든 코드에서 OneToMany에서 Many쪽에 FK를 두기 때문입니다.
프록시객체 테스트 - OneToMany에서 Many
같은 트랜잭션 내에서 모든 Team과 Member를 조회한 뒤에
Member의 필드인 Team을 콘솔에 출력한다면?
List<Member> members = memberRepository.findAll();
List<Team> teams = teamRepository.findAll();
members.forEach(m -> {
System.out.println(m.getTeam());
});모든 멤버와 팀을 조회한 뒤에, 각 멤버 별로 팀을 콘솔에 출력합니다.
결과
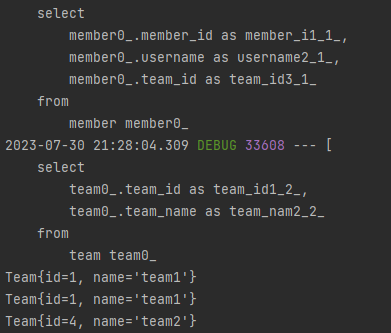
모든 멤버와 팀을 조회하는 쿼리가 나간 뒤에, 각 멤버마다 팀을 출력했는데 추가 쿼리가 나가지 않았습니다.
그 이유는, Member의 Team 필드는 FK를 통해 조회되는데, Member의 FK는 Team의 id이기 때문입니다. (Team에서 id는 PK)
따라서 추가 쿼리가 발생하지 않습니다.
전체 Team을 조회하지 않고, 프록시객체를 조회했을때,
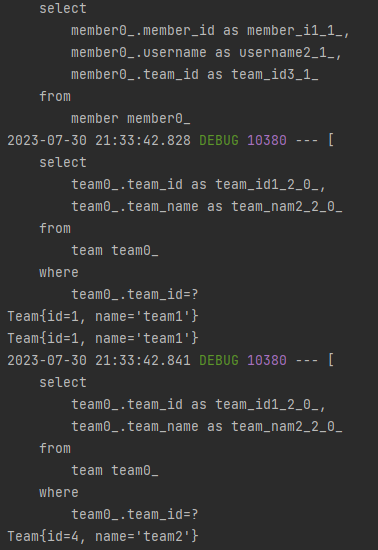
List<Member> members = memberRepository.findAll(); //List<Team> teams = teamRepository.findAll(); // Team조회부분 주석처리 members.forEach(m -> { System.out.println(m.getTeam()); });결과
전체 Member를 조회한 뒤에, 각 팀을 호출할때마다 추가 쿼리가 발생했습니다.
(Team은 2개이기 때문에, 추가 쿼리 2개만 발생함)이때 프록시 객체를 조회하는 쿼리가 team_id를 이용해서 조회하는 것이 확인됩니다.
-> Team의 PK
프록시객체 테스트 - OneToMany에서 One
같은 트랜잭션 내에서 모든 Team과 Member를 조회한 뒤에
Team의 필드인 Member를 콘솔에 출력한다면?
List<Member> members = memberRepository.findAll();
List<Team> teams = teamRepository.findAll();
teams.forEach(t -> {
System.out.println(t.getMembers());
});모든 멤버와 팀을 조회한 뒤에, 각 팀 별로 멤버를 콘솔에 출력합니다.
결과
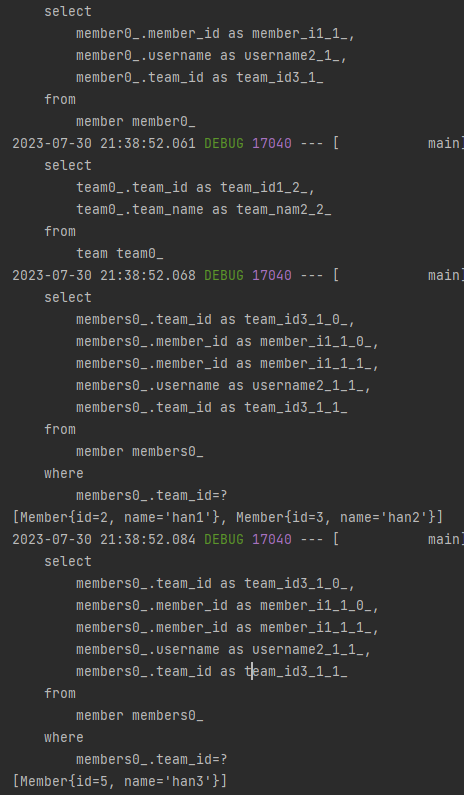
전체 멤버와 팀을 조회한 후에, 각 팀마다 멤버들을 조회하는데,
조회할때마다 추가 쿼리가 발생했습니다.
그 이유는 Member의 FK인 team_id를 통해 멤버들을 조회하는데,
team_id는 Member의 PK가 아니기 때문에 추가 쿼리가 발생한 것입니다.
주의할 점
지금까지 모든 테스트는 스프링 데이터 JPA 리포지토리를 이용해서 진행했습니다.
native SQL이나 JPQL을 사용한다면 이러한 결과가 나오지 않습니다. (QueryDSL도 마찬가지)
두가지 모두 영속성 컨텍스트를 거치지 않고 바로 DB에 쿼리를 보냅니다.
따라서 1차캐시와는 관련이 없습니다.
정리
핵심
영속성 컨텍스트의 1차캐시는 해당 객체의 PK를 통해 구별한다.
PK가 아닌 다른 필드로 객체를 조회하면 추가 쿼리가 발생할 수 있다.
사실 이번 글은, 실제 서비스를 운영할때 유용하게 사용되는 정보는 아니라고 생각합니다.
하지만 이런 실험?을 통해서 영속성 컨텍스트에 조금더 이해하게 된 것 같습니다.
