선생님 둘보다 한 명의 선생님이 낫다는 역설
학교에서 수학 선생님과 국어 선생님이 따로따로 가르칠 때를 생각해보자. 수학 선생님은 논리적 사고를, 국어 선생님은 글 읽기를 가르친다. 그런데 어느 날 갑자기 수학 문제가 긴 글로 쓰여 있다면? 두 선생님이 따로 가르쳐왔기 때문에, 학생은 '수학 모드'와 '국어 모드'를 번갈아 써야 하는 혼란에 빠진다.
지금까지의 AI도 비슷했다. 글을 읽는 능력과 이미지를 보는 능력을 따로 키운 뒤, 나중에 합쳐 붙이는 방식이 일반적이었다. 그런데 문제가 있었다. 합쳐 붙인 두 능력은 서로 충돌하기도 했고, 한쪽이 강해질수록 다른 쪽이 약해지는 기이한 현상이 나타났다. 마치 오른손 근육을 키우면 왼손이 오히려 얇아지는 것처럼.
중국의 AI 회사 Moonshot AI가 발표한 'Kimi K2.5'는 이 오래된 딜레마에 정면으로 도전했다. 그들의 답은 의외로 단순했다. "처음부터 함께 가르치면 되지 않을까?" 그리고 그 결과는 놀라웠다. 눈(시각)으로 공부한 것이 귀(언어)를 더 예리하게 만들고, 귀로 익힌 것이 눈을 더 밝게 했다. 두 능력이 충돌하는 대신 서로를 강화한 것이다.
1조 개의 부품을 가진 뇌, 그런데 한 번에 쓰는 건 320억 개뿐
Kimi K2.5의 토대가 되는 모델은 '1조 4백억 개의 매개변수'를 가지고 있다. 매개변수란 AI가 학습하면서 조정하는 수많은 숫자 덩어리인데, 이걸 '뇌의 신경 연결'이라고 생각하면 이해하기 쉽다. 인간의 뇌에 약 100조 개의 시냅스가 있다고 하니, AI의 1조 개는 여전히 우리보다 작지만, 2024년 기준으로 세계에서 가장 큰 AI 모델 중 하나다.
그런데 이 중 실제로 한 번에 '켜지는' 부품은 320억 개뿐이다. 이게 바로 'MoE(Mixture of Experts, 전문가 혼합)'라는 구조의 핵심이다. 비유하자면 이렇다. 어느 대형 병원에 수천 명의 의사가 있다고 해보자. 독감 환자가 오면 내과 의사만 나서고, 골절 환자가 오면 정형외과 의사만 출동한다. 모든 의사가 모든 환자를 동시에 보는 것이 아니라, 필요한 전문가만 그때그때 투입된다. 덕분에 병원은 거대한 전문성을 갖추면서도 효율적으로 운영된다. Kimi K2.5는 바로 이런 구조로 설계되어 있다. 384명의 '전문가'가 대기하고 있고, 각 질문마다 그중 8명이 선발되어 협력한다.
글만 읽었는데 그림도 보게 되다 — '제로 비전 SFT'의 역설
이 논문에서 가장 충격적인 발견 중 하나는 이것이다. 연구자들은 AI에게 시각 능력을 가르칠 때, 처음에는 '사람이 직접 설계한 시각 학습 자료'를 쓰지 않았다. 대신 텍스트만으로 이루어진 학습을 했다. 그런데 놀랍게도, 텍스트만 공부한 AI가 나중에 이미지도 더 잘 이해했다.
왜 이런 일이 가능했을까? 연구자들의 설명은 이렇다. 이미 사전 학습 단계에서 텍스트와 이미지를 처음부터 함께 보여줬기 때문에, AI의 뇌 속에는 이미 '언어 개념'과 '시각 개념'이 깊숙이 연결되어 있었다. "고양이"라는 단어와 고양이 사진이 같은 신경망 안에서 이미 손을 잡고 있는 상태였다는 것이다.
여기에 적합한 비유가 있다. 어린 시절 영어를 배울 때, 'apple'이라는 단어를 사과 그림과 함께 수백 번 봤다고 생각해보자. 나중에 글로만 된 소설을 읽다가 'apple'이 나와도, 우리 뇌는 자동으로 빨간 사과를 떠올린다. 어른이 돼서 사과 그림을 따로 외우지 않아도 된다. 이미 어릴 때 몸에 배어 있기 때문이다. Kimi K2.5의 사전 학습이 바로 이 역할을 했다. 이미지와 언어를 처음부터 함께 보여줌으로써, 나중에 시각 예제를 억지로 주입하지 않아도 두 능력이 자연스럽게 통합되었다.
이 발견은 단순한 기술적 효율의 문제가 아니다. '사람이 일일이 설계한 학습 데이터가 오히려 방해가 될 수 있다'는 매우 반직관적인 교훈을 담고 있다. 억지로 짜맞춘 커리큘럼보다, 풍부한 환경에서의 자연스러운 학습이 더 강력할 수 있다는 것이다.
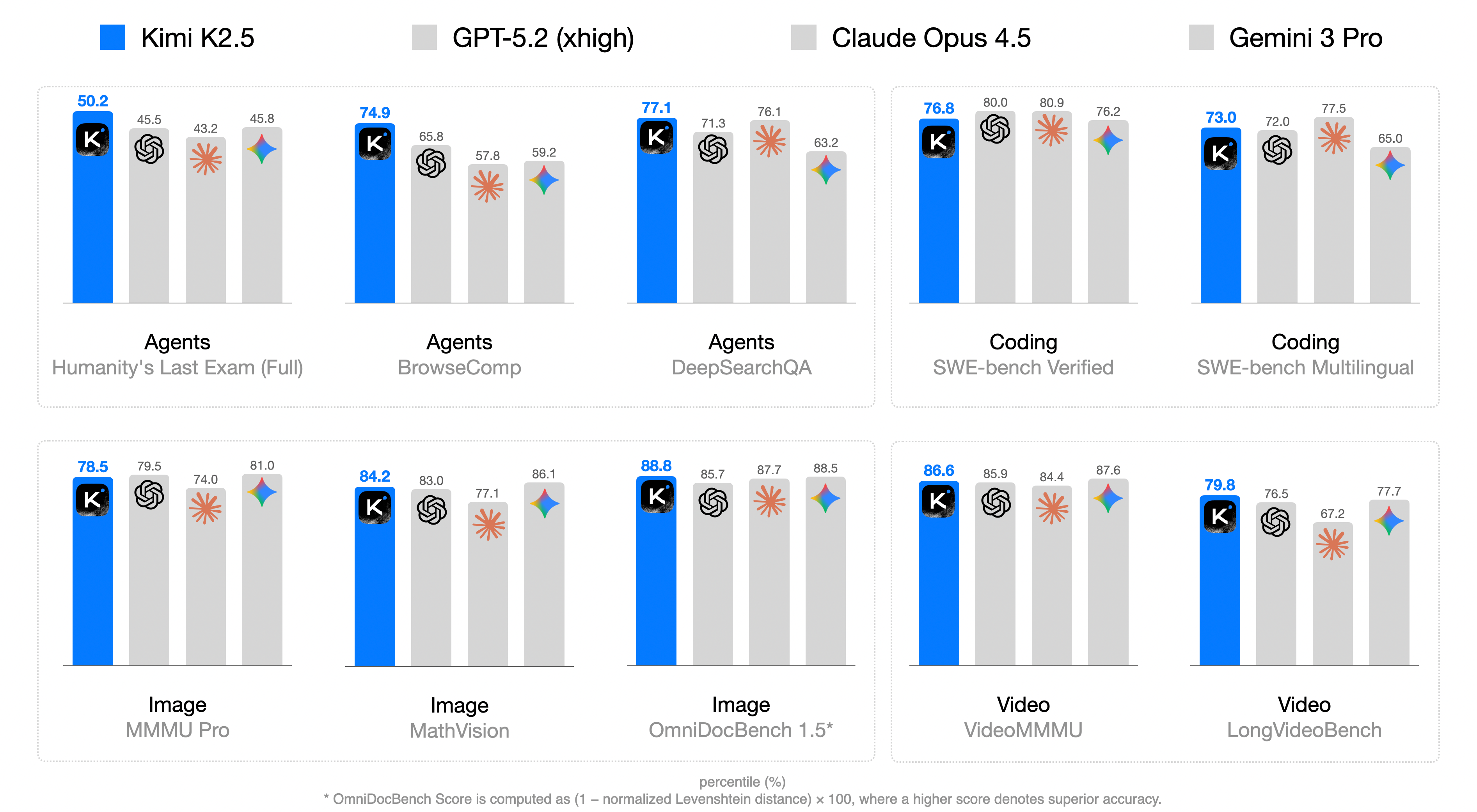
Figure 1: Kimi K2.5 main results.
운동하면 공부도 잘 된다 — 시각 강화학습이 언어를 강화한 이유
더 신기한 일이 강화학습 단계에서 벌어졌다. AI에게 이미지를 분석하는 과제를 반복 훈련시켰더니, 언어 시험 점수까지 올랐다. MMLU-Pro(다양한 분야의 지식을 묻는 시험)와 GPQA-Diamond(대학원 수준의 과학 문제)에서 점수가 오른 것이다. 시각 공부가 어떻게 언어 능력을 키웠을까?
이건 마치 피아노를 배우면 수학 성적이 오른다는 연구 결과와 비슷한 원리다. 피아노는 손가락 협응, 악보 읽기, 음악적 패턴 인식을 동시에 요구한다. 이 훈련이 뇌의 공간 추론과 패턴 인식 능력 전반을 강화하고, 그 효과가 수학으로 번진다. 이미지를 분석한다는 것도 마찬가지다. 차트를 읽고, 도형의 관계를 파악하고, 숫자와 기호를 시각적으로 해석하는 훈련은 논리적 추론 능력 전체를 날카롭게 만든다. 눈을 훈련시키면 뇌 전체가 강해지는 것이다.
연구자들은 이를 '양방향 향상(bidirectional enhancement)'이라 부른다. 텍스트가 시각을 부트스트랩하고, 시각이 텍스트를 정제한다. 두 능력이 같은 신경망 안에 살고 있기에 가능한 일이다.
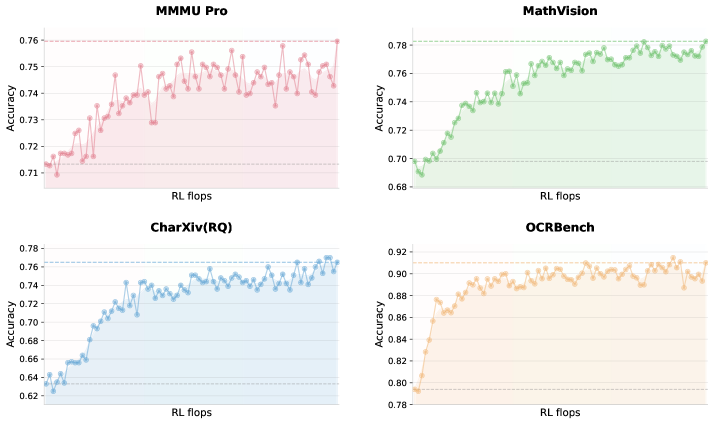
Figure 2: Vision RL training curves on vision benchmarks starting from minimal zero-vision SFT.
혼자 달리는 마라토너에서 릴레이 팀으로 — Agent Swarm
그러나 Kimi K2.5의 가장 야심찬 아이디어는 '에이전트 스웜(Agent Swarm)'이다. 이것을 이해하려면 먼저 기존 AI 에이전트의 한계를 알아야 한다.
지금까지 대부분의 AI 에이전트는 '혼자 달리는 마라토너'였다. 복잡한 문제가 주어지면, 하나의 AI가 1번 생각, 2번 도구 사용, 3번 생각, 4번 도구 사용… 이런 식으로 순서대로 처리했다. 단계가 수백 개라면? 첫 번째 단계를 마칠 때까지 나머지 모든 것이 기다려야 한다. 마치 슈퍼마켓 계산대가 하나밖에 없어서, 100명이 한 줄로 서서 차례를 기다리는 상황이다.
에이전트 스웜은 이 계산대를 수십 개로 늘린다. 그것도 단순히 늘리는 게 아니라, '지휘자(오케스트레이터)'가 복잡한 문제를 분해해서 각 전문 에이전트에게 나눠준다. 논문 내용을 요약하는 에이전트, 웹을 검색하는 에이전트, 코드를 작성하는 에이전트, 사실을 확인하는 에이전트가 동시에 작동한다. 그리고 각자의 결과물이 나오면 지휘자가 이를 모아 최종 답을 만든다.
오케스트라 비유가 정확하다. 바이올린, 첼로, 플루트, 타악기가 동시에 연주한다. 각 파트는 독립적으로 자기 악보를 연주하면서도, 지휘자의 박자와 신호에 따라 하나의 음악으로 수렴한다. 바이올린이 끝날 때까지 첼로가 기다리는 오케스트라는 없다.
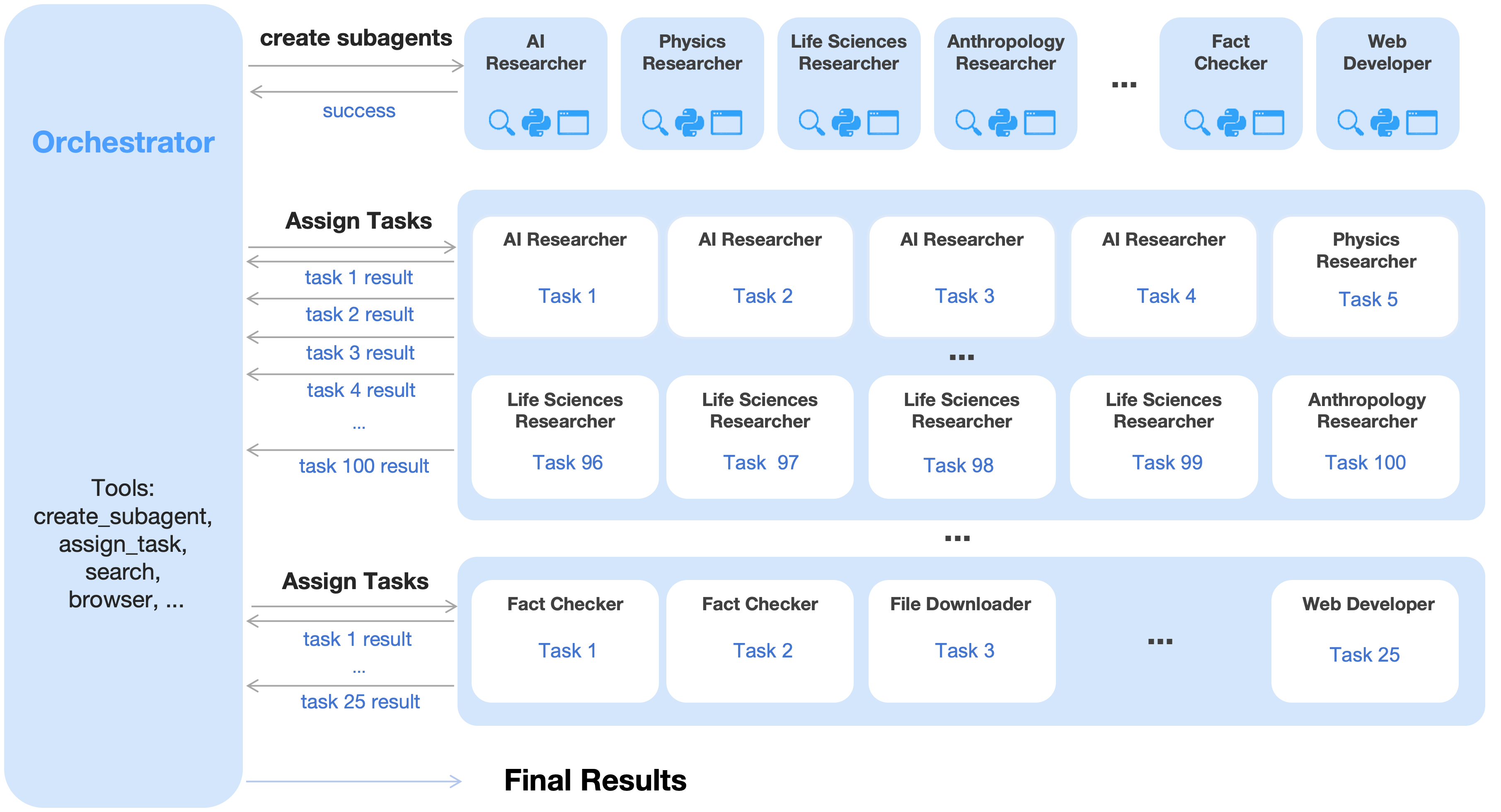
Figure 3: An agent swarm has a trainable orchestrator that dynamically creates specialized frozen subagents and decomposes complex tasks into parallelizable subtasks for efficient distributed execution.
이 설계에는 흥미로운 세부사항이 있다. 지휘자(오케스트레이터)만 학습이 가능하고, 각 서브에이전트들은 고정되어 있다. 이게 왜 중요할까? 모든 단원이 즉흥적으로 연주하면 오케스트라가 아니라 소음이 된다. 전체를 조율하는 지휘자만이 배움과 변화의 주체이고, 각 전문가는 자신의 역할에 충실하다. 이 구조 덕분에 시스템 전체가 예측 가능하고 안정적으로 동작한다.
결과는 수치로 나왔다. 단일 에이전트 대비 지연 시간이 최대 4.5배 줄었다. BrowseComp(인터넷을 탐색해 복잡한 질문에 답하는 능력)에서 에이전트 스웜을 쓰면 74.9%의 정확도를 기록했는데, 이는 단일 에이전트의 60.6%보다 훨씬 높다. 더 빠르면서 더 정확하다 — 보통은 하나를 얻으면 하나를 잃는데, 여기서는 둘 다 얻었다.
더 적게 읽고 더 잘 이해한다 — MoonViT-3D의 동영상 전략
동영상을 이해하는 것은 이미지를 이해하는 것보다 훨씬 어렵다. 이미지는 한 장의 사진이지만, 동영상은 초당 24~30장의 사진이 흘러가는 것이기 때문이다. 긴 영상이라면 수만 장의 이미지를 처리해야 하는데, 이걸 전부 AI에게 보여주면 처리 용량을 금세 초과한다.
Kimi K2.5의 해법은 이렇다. 연속하는 4개의 프레임을 하나의 '묶음'으로 처리하고, 공간적으로 겹치는 정보를 압축해서 핵심만 남긴다. 비유하자면, 달리는 사람을 찍은 영상을 볼 때 모든 프레임을 다 보는 대신, "1번 프레임엔 왼발 앞, 2번엔 오른발 앞, 3번엔 왼발 앞…"처럼 변화하는 부분만 추적하는 방식이다. 배경이 바뀌지 않는다면, 굳이 매 프레임마다 배경 전체를 기억할 필요가 없다. 달라진 것만 기록하면 된다.
이 전략 덕분에 K2.5는 같은 처리 용량으로 4배 더 긴 영상을 소화할 수 있다. 그리고 더 중요한 것은, 이미지를 처리하는 모듈과 동영상을 처리하는 모듈이 완전히 같은 구조를 공유한다는 점이다. 그림 공부가 영상 이해에도 그대로 적용된다. 하나의 능력이 자연스럽게 다른 능력으로 번진다.
덜 말하고 더 정확하게 — 토큰 효율화의 의미
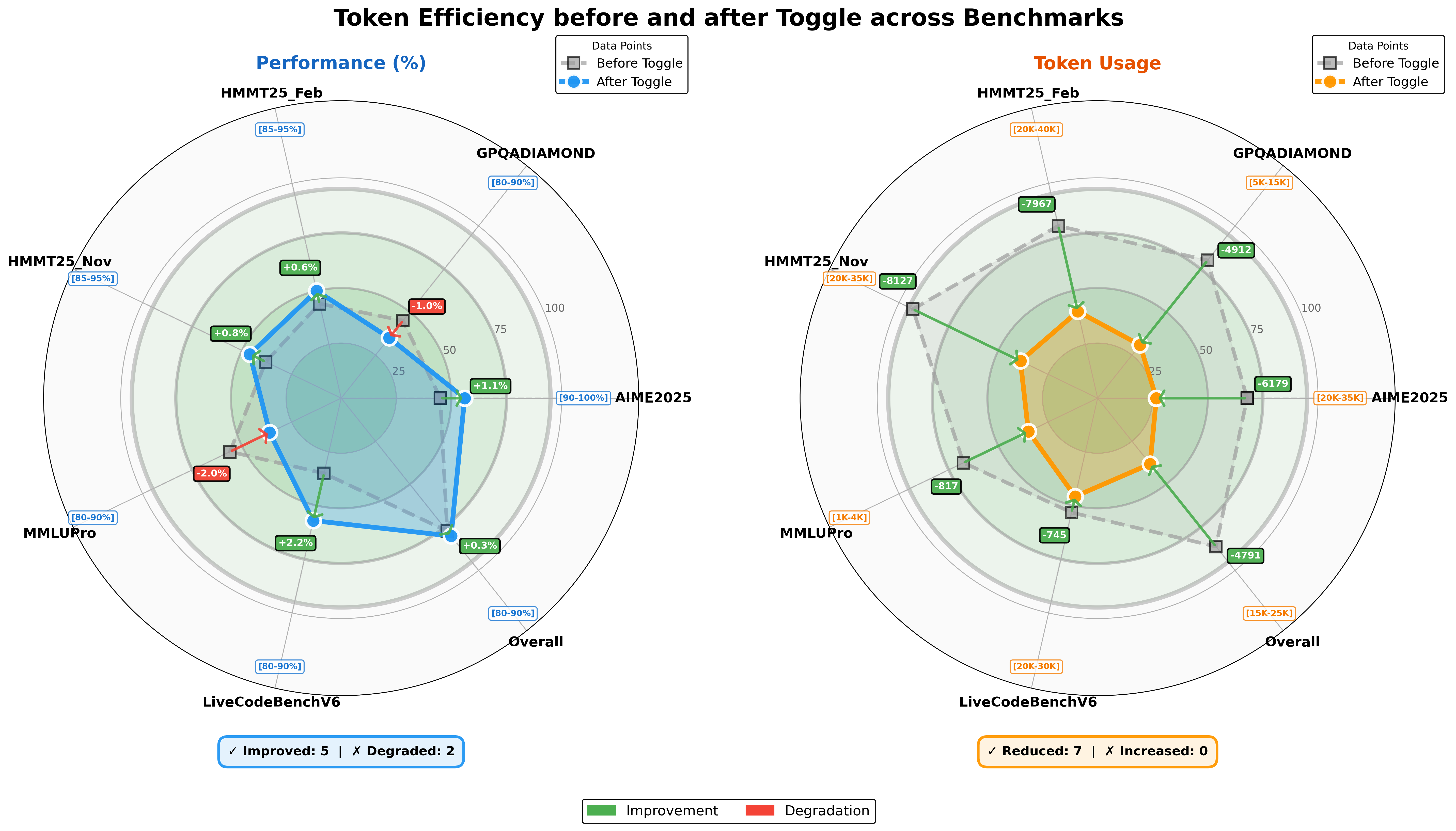
Figure 5: Comparison of model performance and token usage for Kimi K2 Thinking following token-efficient RL.
논문의 또 다른 흥미로운 발견은 '토큰 효율화 강화학습'이다. AI가 답을 생성할 때 사용하는 '토큰'은 단어나 글자의 단위인데, 더 많이 쓸수록 더 많은 시간과 비용이 든다. 말이 많은 것이 항상 좋은 것은 아니다. 핵심을 간결하게 짚는 능력도 중요하다.
훈련 후의 결과를 보면, 대부분의 과제에서 성능이 유지되거나 오히려 향상되면서 동시에 토큰 사용량은 줄었다. 이는 마치 처음에 긴 에세이로 답하던 학생이, 훈련 후에는 같은 내용을 훨씬 짧고 명확한 문장으로 전달하게 된 것과 같다. 유식한 말을 줄줄이 늘어놓는 것이 아니라, 딱 필요한 말만 골라서 하는 것. 그게 진짜 실력이다.
그래서 무엇이 달라지나
이런 기술들이 일상에 스며들면 어떤 변화가 생길까.
지금은 "이 계약서를 읽고 주요 조항을 정리해줘"라고 부탁하면, AI가 텍스트를 한 줄씩 순서대로 읽는다. 그런데 에이전트 스웜 구조라면, 계약서 전체를 동시에 여러 에이전트가 분담해 읽고, 각자 담당한 조항을 분석하고, 한꺼번에 결과를 종합할 수 있다. 지금 몇 분 걸리는 일이 몇 초로 줄 수 있다.
복잡한 프로젝트 기획도 달라진다. "여행 계획 짜줘"라고 하면, 하나의 AI가 항공편 검색, 숙소 검색, 날씨 확인, 현지 음식점 조사를 차례차례 하는 대신, 여러 에이전트가 동시에 각 항목을 담당한다. 그리고 진짜 중요한 것은, 이 AI가 이제 '글로 된 정보'뿐만 아니라 '지도 이미지', '메뉴판 사진', '구글 스트리트뷰'까지 함께 볼 수 있다는 것이다.
아직 남은 질문들
솔직히 말하면, 이 연구에는 몇 가지 의문이 남는다.
병렬 에이전트 구조는 '분리 가능한 문제'에서만 효과적이다. 앞의 판단이 뒤의 행동을 완전히 바꿔야 하는 복잡한 추론에서는 오케스트레이터가 어디까지 조율할 수 있을까? 지휘자가 각 악기의 실시간 연주를 완벽히 통제할 수 없듯, 여러 에이전트 사이의 예상치 못한 충돌이나 정보 불일치는 어떻게 해결될까.
또한 이 모델은 개방형으로 공개되었지만, '1조 개 매개변수'를 실제로 구동하려면 일반 기업도 감당하기 어려운 수준의 GPU가 필요하다. 공개는 했지만 누구나 쓸 수 있다고 말하기엔 아직 거리가 있다.
그럼에도 불구하고, Kimi K2.5가 보여준 핵심 통찰은 오래 기억될 것 같다. 텍스트와 시각을 처음부터 함께 훈련하면, 두 능력이 충돌하는 대신 서로를 강화한다는 것. 그리고 혼자 오래 달리는 것보다, 팀이 함께 나눠 달리는 것이 더 빠르고 더 멀리 갈 수 있다는 것. 이 두 가지 교훈은 AI만이 아니라 어쩌면 우리 인간의 협업에도 해당하는 이야기일지 모른다.
태그: 멀티모달AI, 에이전트AI, 딥러닝, 비전언어모델
📄 원문: https://arxiv.org/abs/2602.02276
🌐 English version on Dev.to: https://dev.to/xoqhdgh1002/when-the-ai-learns-to-see-and-think-at-the-same-time-235e
