
- 시작하게 된 계기 및 다짐 😮
-
이번 코드스테이츠의
백엔드 엔지니어링 개발자 부트캠프에 참여하게 되면서 현직개발자 분들의 빠른 성장을 위한 조언 중 자신만의 블로그를 이용하여 배운 것 들을 정리하는게 많은 도움이 된다 하여 시작하게 되었다.- 그 날 배웠던 것을 길지 않아도 좋으니 정리하며 복습하는 습관 기르기
- 주말에 다음주에 배울 내용들을 예습
- 코딩 문제와 java코드들은 꾸준히 학습
- 학습 목표 😮
| 목표 | 결과 |
|---|---|
| 제네릭 활용 및 이해 | O |
| 제네릭 메서드/ 와일드카드 이해 및 사용 | O |
| 컬렉션 프레임워크의 핵심 인터페이스 이해 및 사용 | O |
| List/Set/Map의 필요에 따른 사용 및 핵심 메서드 이해 | O |
- 정리
★★ 제네릭과 Object 클래스의 차이점
-
Object : 다양한 자료형에 대응할 수 있는 하나의 최상위 클래스로, 형변환과 타입체크가 필요함
코드의 중복은 막을 수 있지만, 타입체크와 형변환을 필요로 함 -
generic : 여러 데이터타입을 외부에서 일반화시켜 다양한 자료형을 받을 수 있게 만듬
런타임이 아닌 컴파일 시점에 타입체크를 하고 객체를 정의할 때 타입을 지정하여 불필요한 형변환과 체크를 할 필요가 없음반복적인 코드, 불필요한 코드를 제거하고 재활용이 가능 컴파일시에 안정성이 높아짐
Generic
# Generic
- 클래스 내부에서 사용할 데이터 타입을 외부에서 파라미터 형태로 지정하여 데이터 타입을 일반화
- pulbic class/interface 이름<타입 매개변수,타입 매개변수>{};
- 제네릭 타입의 경우(메서드제외) static을 사용할 수 없음(_ 타입을 지정하기 전에 메모리에 올릴수 없어서)
★★ 객체 생성부의 <>안에 아무것도 넣지않거나 <>를 빼도 문맥상 추론하여 자동으로 생성
★★ 메서드의 부분에서 <>를 사용하지 않아도 문맥상 추론하여 자동생성 (<>만 사용시 오류)
==> 보통 대문자 알파벳 한 글자로 표현한다.
==> 제네릭 타입 매개변수의 개수대로 선언
- 선언순서
1. 제네릭 클래스 정의
2. 템플릿 형태의 제네릭 클래스에 속성과 메서드 정의
3. 제네릭 객체 생성
4. 사용
ex)
class Basket<T>{ (1)
private T t;
public void set(T t){ this.t = t;} (2)
public get() { return this.t};
}
public static void main(String[] args){
Basket<String> basket = new Basket<String>; (3)
basket.set("String"); (4)
}
# 타입 매개변수
- 제네릭 클래스의 <> 안의 매개변수(보통 하나의 대문자로 작성)
- <?> : 타입 매개변수에 모든 타입을 사용한다는 의미
==> <? extends T> : 매개변수의 자료형을 특정 클래스를 상속받은 클래수로만 제한, T타입과 T타입을 상속받는 하위 클래스 타입만 사용 ( 매개변수로 , 일회성 인자받는 변수)
==> <T extends 클래스> : 클래스 선언시 사용하며, 인스턴스 생성시 특정 클래스를 상속받은 클래스형만 인스턴스 내부에서 사용할 수 있도록함 ( 클래스 레벨에서 선언처리)
==> <? super T > : T타입과 T타입을 상속받는 상위 클래스 타입만 사용
ex) class Show{ static void show(Basket<?> basket){}}
# 제네릭 메서드
- 클래스의 특정 메서드만 제네릭으로 선언
- 메서드를 호출할 때 실제 타입을 지정
- 제네릭에 특정 타입을 정의하지 않으면 어떤 타입이 입력되는지 몰라 Object 클래스를 제외한 메서드는 사용이 불가능
ex)
class TestClass{
public <T> T accept(T t){ // public <제네릭>리턴타입 함수이름(인자);
return t;
}
}

Collection_framework
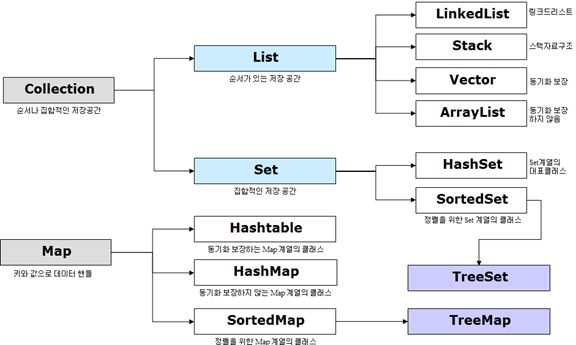
# 프레임워크
- 데이터를 저장하기 위해 자료구조를 바탕으로 객체들을 효율적으로 추가/검색/삭제할 수 있도록 관련된 것들을 모아놓은 인터페이스와 클래스
0. Collections - 해당 3의 부모 클래스 개념
1. List_인터페이스
- 순서를 유지하고, 중복저장 가능
- ArrayList, Vector, Stack, LinkedList ( 구현 클래스)
2. Set_인터페이스
- 순서를 유지하지 않고, 중복저장 불가능
- HashSet, TreeSet 등 (구현 클래스)
3. Map_인터페이스
- 키와 값(Value)쌍으로 저장, 순서 유지하지않음, 키는 중복저장 불가능(Value는 중복가능)
- HashMap,Hashtable,TreeMap,properties 등
Collection_List-Class
1. ArrayList
- Vector를 개선하여 보다 빈번하게 사용
- 객체를 추가하면 인덱스에서 이를 관리, 배열의 크기가 추가/삭제에 따라 유동적으로 저장공간이 바뀜
- 데이터가 연속적으로 존재
ex) List<타입 파라미터> 객체명 = new ArrayList(초기용량); or ArrayList<타입파라미터>(초기 용량);
2. LinkedList
- 데이터의 효율적인 추가/삭제/변경을 위해 사용
- List와 달리 데이터가 불연속적으로 존재하며 원하는 연결 형태를 만들 수 있음(head/tail)
- 데이터의 추가/삭제시 데이터의 이동이 없어 빠르지만 데이터를 찾을 시 순차적으로 데이터를 순회하여 느림
3. Iterator
- 컬렉션에 저장된 요소를 읽어오는 방법으로 iterator 객체를 사용
- hasNext() : 가져올 객체가 있으면 true, 없으면 false;
- next() : 다음 객체 하나를 가져옴
- remove() : 컬렉션에서 객체를 제거
ex)
List<String> list = ...;
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) { //가져올 객체가 있는 동안은, 괄호 안의 내용이 true이면
String str = iterator.next();
Collection_Set-Class
1. HashSet
- 가장 기본적인 Set 클래스, 순서가 없고 중복을 허용하지 않음
ex) HashSet<T> hashset = new HashSet<>();
2. TreeSet
- 이진 탐색 트리 형태로 데이터를 저장, 순서가 없고 중복을 허용하지 않음
- hashset.first() : 리스트에서 첫번째 값
- hashset.list() : 마지막 값
- higher(ele) : 인자로 받은 값보다 큰 값중 가장 작은 값
- hashset.subset(ele,ele) : 인자로 받은 값들로 작은 서브셋
# 트리_ : 부모노드 하나에 두개의 자식노드가 달려 왼쪽 자식은 부모보다 작고 오른쪽은 부모보다
Collection_Map-Class
Map
1. Hashmap
- Key로 사용할 객체는 hasCode()의 리턴값이 같고 equals()의 메서드가 true가 되어야 동등키이다.
- Hashing을 사용하여 기존의 set보다 보다 빠른 뛰어난 성능을 지닌다.
- Hashtable과 달리 null값을 허용함
- key와 value값은 기본타입은 사용할 수 없고 클래스 및 인터페이스 타입만 가능
ex)
Map<key,Value> map = new HashMap<Key,Value)();
Collection_Method
# List와 Set 주요 메서드
- add(Object o), addAll(Collection c) : 주어진 객체 / 컬렉션의 객체들을 컬렉션에 추가
, add(index, Object o) : index에 객체 추가
- contains(Object o), containsAll(Collection c) : 주어진 객체 / 컬렉션이 저장되어 있는지 여부
- iterator() : 컬렉션의 iterator를 반환
- equals(Object o) : 컬렉션이 동일한지 여부
- isEmpty() : 컬렉션이 비어있는지 여부
- size() : 저장되어 있는 전체 객체 수를 반환
- clear() : 컬렉션에 저장된 모든 객체를 삭제
- remove(Object o), removeAll(Collection c) : 주어진 객체 / 컬렉션을 삭제하고 성공 여부를 반환
- retainAll(Collection c) : 주어진 컬렉션을 제외한 모든 객체를 컬렉션에서 삭제하고 컬렉션에 변화가 있는지 여부를 반환
- toArray() : 컬렉션에 저장된 객체를 객체배열(Object [])로 반환
- toArray(Object[] a) : 주어진 배열에 컬렉션의 객체를 저장해서 반환
# List 추가 메서드
- set(int index, Object element) : 주어진 위치에 객체를 저장
- get(int index) : 주어진 인덱스에 저장된 객체 반환
- indexOf(Object o) / lastIndexOf(Object o): : 순/역 방향으로 주어진 객체 위치 반환
- listIterator() / listIterator(int index) : List객체를 탐색할 수 있는 ListIterator 반환
- subList(int fromIndex, int toIndex) : from 부터 to 까지 있는 객체 반환
- remove(int index) : 주어진 인덱스에 저장된 객체 삭제 및 삭제된 객체 반환
remove(Object o) : 주어진 객체 삭제
- sort(Comparator c) : 주어진 비교자로 List를 정렬
# Map 인터페이스 주요 메서드
- put(Object key, Object value) : 주어진 키로 값을 저장, 새로운 키일 경우 null을 리턴하고 동일한 키가 있을 경우 값을 대체하고 이전값을 리턴
- containsKey(Object key) : 주어진 키가 있으면 true, 없으면 false를 리턴
- containsValue(Object value) : 주어진 값이 있으면 true, 없으면 false를 리턴
- entrySet() : 키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아서 리턴
- get(Object key) : 주어진 키에 해당하는 값(Values)을 리턴
- keySet() : 모든 키를 Set 객체에 담아서 리턴
- values() 저장된 모든 값을 Collection에 담아서 리턴
- remove(Object key) : 주어진 키와 일치하는 Map.Entry를 삭제하고 값을 리턴
- size() : 저장된 키-값 쌍의 총 갯수를 리턴
- clear() : 모든 Map.Entry(키와 값)을 삭제
- isEmpty() : 컬렉션이 비어 있는지 확인
Supplement
Comparator vs Comparable
1. Comparator(compare)
- 매개변수로 받은 두 객체를 비교,
- 주로 기본정렬이 아닌 특정 기준 정렬을 사용하고 싶을때 사용
- 보통 오버라이딩을 통해 원하는 정렬 기준을 만들어 사용
ex)
public int compare(Employee employee1, Employee employee2) {
return employee2.id - employee1.id;
}
2. Comparable(compareTo)
- 매개변수로 받은 객체와 자기 자신을 비교
- 객체.compareTo(비교 객체) : 비교 객체가 자신보다 작으면 양수, 같으면 0, 크면 -1을 리턴
#Collections.sort(workers,new SortbyId());
==> 컬렉션의 sort 메서드를 이용하여 workers 객체와 새 정렬기준 new SortbyId를 넘겨주어 정렬
- 피드백 😮
-
Java를 사용할 때 배열보다 보다 쉽게 데이터를 추가/삭제/수정을 할 수 있는 Collection 클래스의 List/Set/Map을 배웠는데 배열과 달리 크기를 지정해주거나 인덱스를 따로 신경쓰지 않아도 되서 굉장히 편하게 사용할 수 있다
-
Map의 경우 List/Set과 달리 사전같이 Key와 Value로 구성하여 데이터를 보관할 수 있는데 hashMap을 사용하면 굉장히 빠른 속도로 원하는 데이터를 찾을 수 있다.
-
Generic 클래스를 통해 메서드나 클래스에 특정 타입을 지정하지 않고 그때 그때 원하는 타입을 사용할 수 있으므로 여러 타입을 사용하기 위해 하나의 클래스로 처리할 수 있어 굉장히 효율적인 코드가 작성된다.
- 앞으로 해야 될 것 😮
- 매일 꾸준히 할 것
- 꾸준히 velog 작성
- Java 언어 및 Algorithm 공부(Coding-Test)
- 틈틈히 운동 하기
- 내일 해야 할 것
- 내부 클래스 이해
- 각 내부 클래스의 이해와 사용 방법 및 사용이유

Will be great Backend-developer