💡 본 글은 프로젝트 진행 중 수행한 성능 개선 과정을 다룹니다.
따라서 기능의 의미보다는 문제의 본질에 중점을 두어 설명할 예정입니다.
자세한 정보와 원본 코드, PR 내용은 아래 링크에서 확인하실 수 있습니다.
- Project : Dev Race
- PR : Batch Insert 리팩토링
- P.S.) 다음 프로젝트에서도 해당 리팩토링이 반영되었습니다.
→ 온라인 메모장 Ver.2 / Bulk Query (Insert)
문제 인식
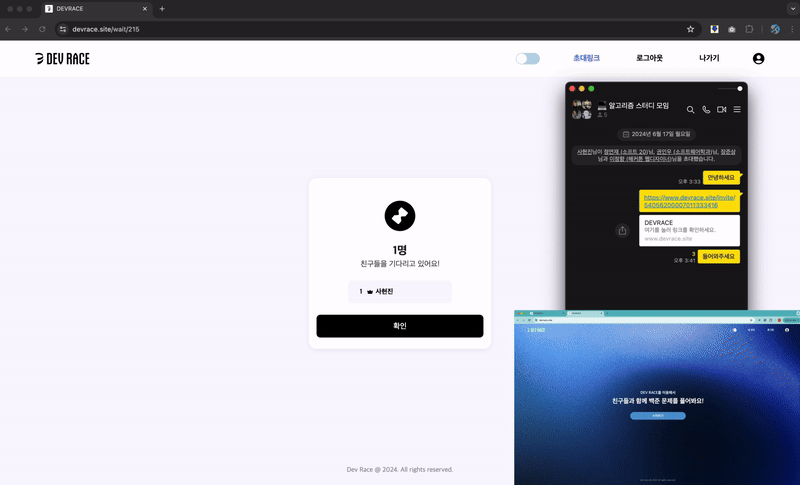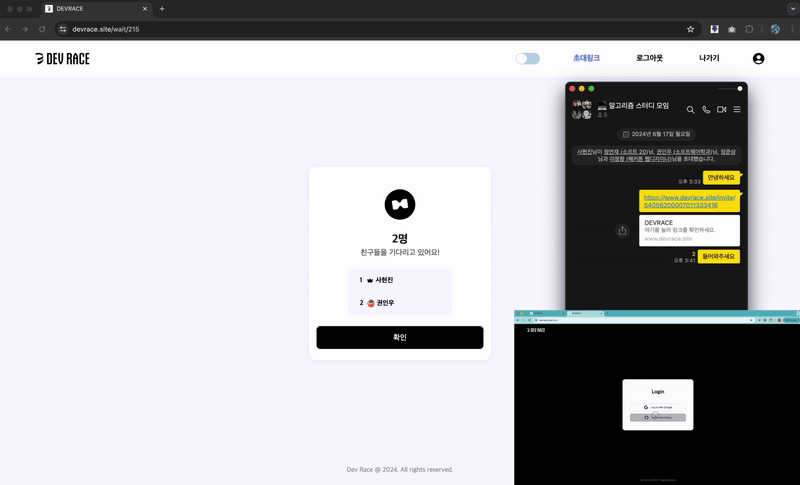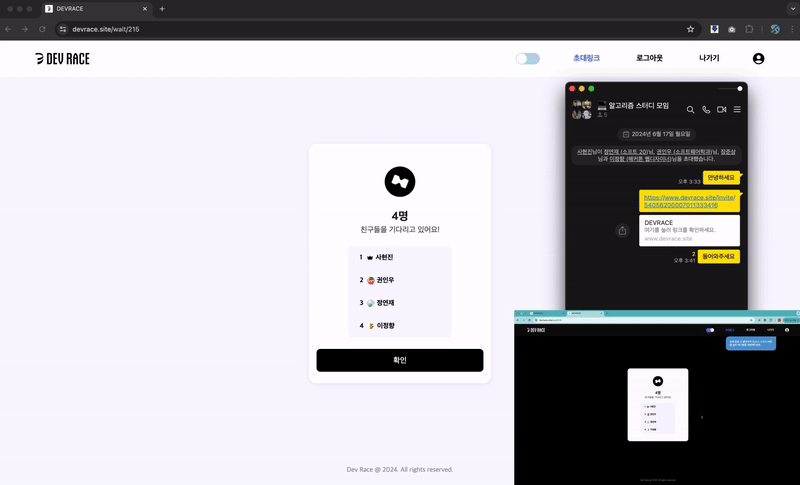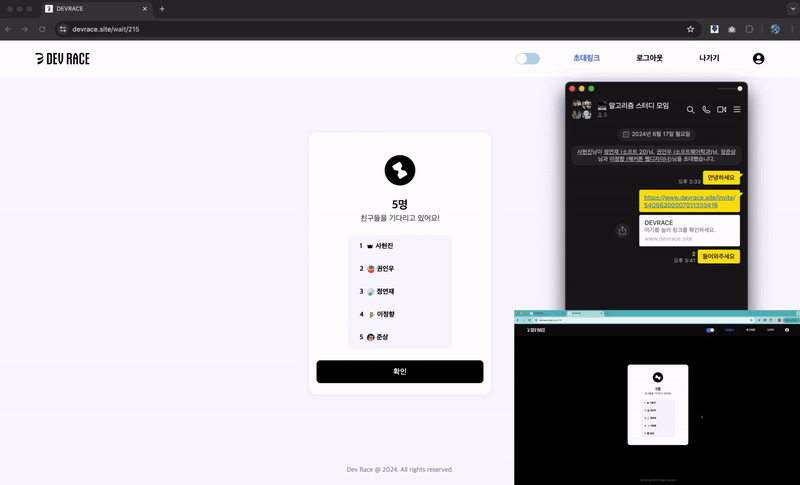 → 방 입장 페이지 : 초대링크 접속 & 실시간 입장 대기열 참가
→ 방 입장 페이지 : 초대링크 접속 & 실시간 입장 대기열 참가
프로젝트 'Dev Race'는 실시간으로 알고리즘 문제를 풀며 순위를 경쟁하는 코딩 플랫폼이다.
이에 공정한 시간 경쟁을 위하여, 대기열의 사용자들이 문제풀이 방에 동시 입장하도록 구현하였다.
그러나 이 기능의 작동 과정에서 몇 가지 문제가 발견되었다.
ERD
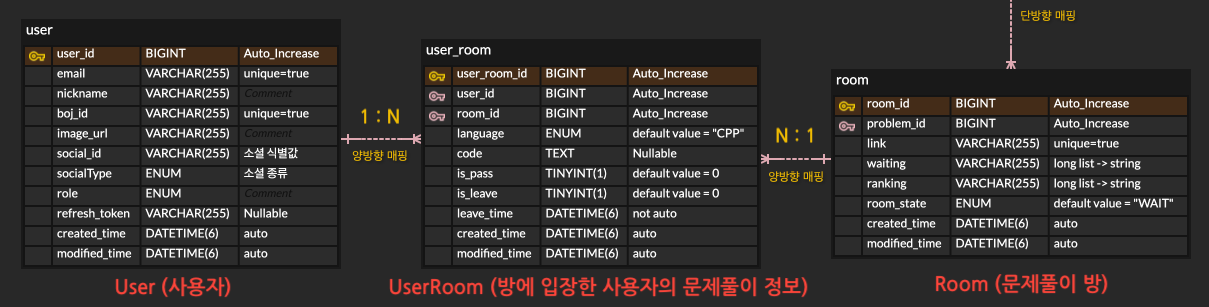
위처럼 엔티티는 User(1) : UserRoom(N) : Room(1) 의 연관 관계로 이루어져있다.
이는 사용자(User)가 방(Room)에 입장할 때, 각각 UserRoom 데이터를 생성함을 의미한다.
즉, 동시 입장의 경우, 방에 입장하는 사용자 수만큼 UserRoom을 추가해야함.
ex) 4명의 사용자가 방에 동시 입장 → 4개의 UserRoom 데이터 생성
Service
// [ UserRoomServiceImpl.java ]
@Transactional
@Override
public void usersEnterRoom(Long roomId) {
// - 대기열 명단 조회 : 방 입장 대기열의 사용자들 조회
Room room = roomService.findRoom(roomId);
List<Long> waitUserIdList = room.getWaiting();
List<User> waitUserList = userService.findUsersOriginal(waitUserIdList);
...
// - 입장 준비 : 인원수만큼 UserRoom 데이터들 생성 (DB 저장 X)
List<UserRoom> userRoomList = waitUserList.stream()
.map(user -> UserRoom.UserRoomSaveBuilder()
.user(user)
.room(room)
.build())
.collect(Collectors.toList());
// - 동시 입장 : UserRoom 데이터들 DB에 일괄 삽입 (DB 저장 O)
// [ 방법 1. 해결 전 - JPA saveAll ]
userRoomRepository.saveAll(userRoomList);
// [ 방법 2. 해결 후 - JDBC Batch Insert ]
// userRoomBatchRepository.batchInsert(userRoomList);
...
// - 입장 완료 : 입장 메세지 생성
chatRepository.save(chat);
}usersEnterRoom()은 여러 사용자를 동시에 입장시키는 역할을 수행한다.
과거 이 메소드에서 JPA saveAll을 채택했던 이유는 다음과 같았다.
1. 반복적인 JPA save 호출의 비효율성
각 사용자에 대해 반복적으로 save를 호출하면, DB에 여러 번 접근하여 쿼리가 다수 발생한다.
for (UserRoom userRoom : userRoomList) { // DB에 여러 번 접근 userRoomRepository.save(userRoom); }위와 같은 for문 방식이 그러한 예시이며, 성능 저하를 초래할 수 있기에 옳지 않다고 판단했다.
2. UserRoom 내 created_time 컬럼값의 불일치 문제
다중 쿼리 발생으로, 동시 입장임에도 사용자들의 입장 시각이 서로 달라질 수 있는 문제가 있다.
비록 이는 몇 밀리초의 차이일지라도, 시간 경쟁 시스템에서는 불공정하게 작용할 수 있다.
물론 Auditing 필드를 일일이 수동 할당하면 되지만, 그만한 리스크를 감수할 만한지..?
→ 따라서 JPA save 다중 호출 대신 JPA saveAll 단일 호출을 활용하여,
Bulk Insert 방식으로 여러 UserRoom 데이터들을 한 번에 저장하는 것으로 결정했다.
그러나 이는 크나큰 착각이었다. 전혀 Bulk 처리되지 않았다..!
Query
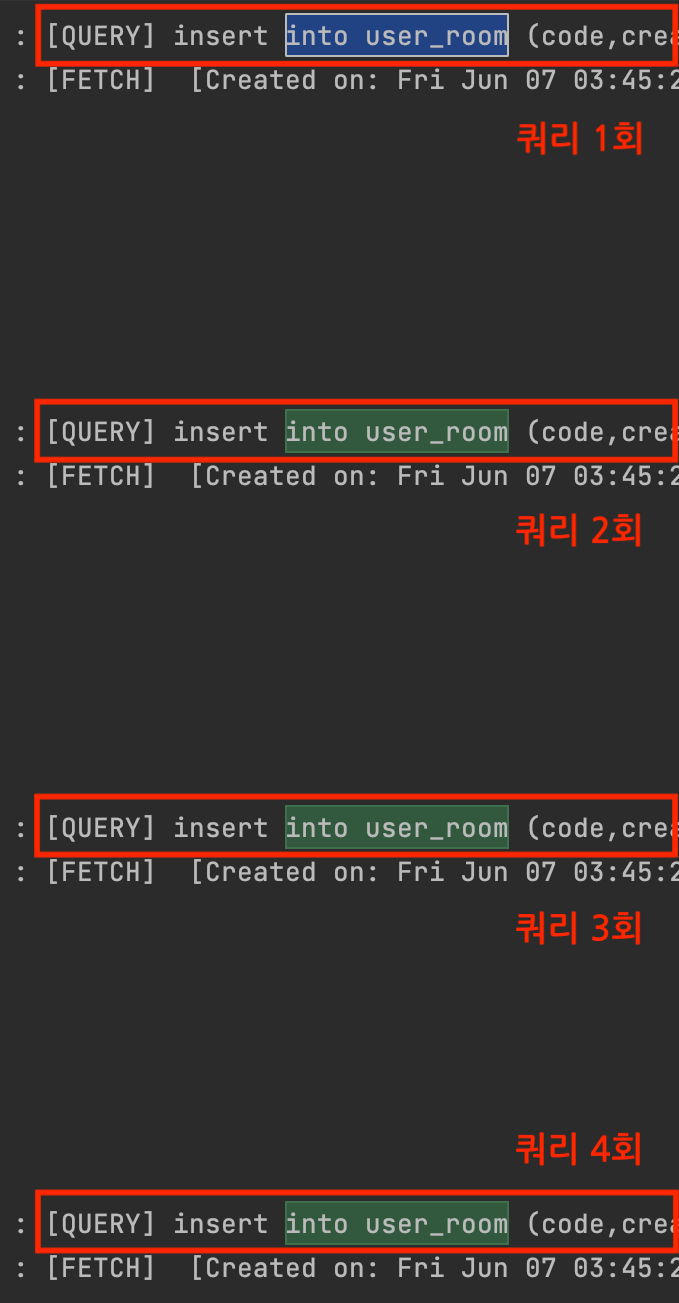 → 사용자 4명 동시 입장 (JPA saveAll)
→ 사용자 4명 동시 입장 (JPA saveAll)
- 기댓값 : 쿼리 1회 발생
- 실제값 : 쿼리 4회 발생
실행 결과, 의도와 다르게 Bulk 처리되지 않고 여러 개의 쿼리가 발생했다.
처음에는 save 대신 saveAll을 사용하였으므로, 한 번에 Bulk Insert가 이루어질 것이라고 생각했다.
그러나 실제로는 for문으로 각각 save를 호출하는 것처럼 쿼리가 개별적으로 실행되었고, 결국 다중 쿼리로 인한 속도 저하를 초래했다. 뿐만 아니라, 동시 입장하는 사용자들의 입장 시각인 created_time 컬럼값 또한 모두 다르게 저장되었다.
따라서 이러한 문제를 해결하고, 동시에 대용량 데이터 처리까지 가능하도록 성능 개선을 진행하였다.
원인 분석
JPA saveAll
IDENTITY 전략
IDENTITY 전략이란, 데이터베이스의 auto_increment 기능을 통해 기본키(PK) 값을 자동으로 증가시키는 방식이다. 이는 일반적으로 JPA와 MySQL을 함께 사용할 때 자주 사용된다.
// [ UserRoom.java ]
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // 기본키가 IDENTITY 전략임.
@Column(name = "user_room_id")
private Long id;그리고 나 또한, 위처럼 UserRoom 엔티티의 기본키를 IDENTITY 전략으로 설정했었다.
saveAll()의 한계
하지만 IDENTITY 전략을 적용한 경우, JPA는 각 엔티티를 저장할 때마다 DB에 INSERT 쿼리를 전송하고, 그 결과로 생성된 키 값을 받아오는 추가적인 과정을 거치게 된다.
이 실행 과정을 정리하면 다음과 같다.
- 과정 1. IDENTITY 전략이 적용된 UserRoom 엔티티들에 대해 JPA saveAll() 실행
- 과정 2. JPA는 각 UserRoom 엔티티에 대해 개별적으로 INSERT 쿼리를 데이터베이스에 전송
- 과정 3. 데이터베이스는 각 INSERT 쿼리를 실행하여 데이터를 저장
- 과정 4. 각 INSERT 쿼리에 대해 고유한 기본키 값을 생성하고, 이를 JPA에 반환
- 과정 5. JPA는 반환된 기본키 값을 각 UserRoom 엔티티에 설정
바로 이 한계로 인하여, UserRoom 엔티티마다 개별 쿼리가 발생하게 되고, 결과적으로 Bulk 방식으로 처리되지 않는 문제가 발생한 것이다.
→ 즉, IDENTITY 전략과 JPA saveAll() 사용이 문제의 원인이었다.
해결 방안
JDBC Batch Insert
JDBC Batch Insert는 대량의 데이터를 효율적으로 데이터베이스에 삽입할 수 있는 방법이다.
이 방식은 여러 개의 INSERT 쿼리를 개별적으로 실행하는 대신, 이를 묶어서 한 번에 실행함으로써 DB 접근 횟수를 줄이고 성능을 개선할 수 있다.
구성 요소
- JdbcTemplate : JDBC를 통해 직접 SQL 쿼리를 직접 실행
- batchUpdate() : 대량 데이터의 여러 쿼리를 묶어 한 번에 처리 → DB 접근 최소화 & 쿼리 개선
- PreparedStatement : SQL 쿼리를 미리 컴파일하여 재사용 → 오버헤드 감소 & 성능 개선
추가 해결점
- 입장 시각 동일화 가능 :
사용자들의 방 동시 입장시, 각 엔티티의 created_time 필드에 동일한 생성시각을 할당함으로써, 모두의 입장 시각을 일관되게 맞출 수 있다.
이로써 기존 JPA saveAll 방식에서 발생하던, 시간 경쟁 불공정성 문제도 해결할 수 있다.
→ 때문에 JDBC Batch Insert는 기존의 JPA saveAll 문제들을 효과적으로 해결할 수 있다.
!!! JPA Auditing 주의사항 !!!
JDBC 사용으로 JPA Auditing 이 작동하지 않는다. 때문에created_time,modified_time등의 Auditing 필드는 수동으로 직접 값을 할당해주어야 한다.
다만 BatchRepository에서 이를 간편하게 처리할 수 있으므로, 크게 걱정할 필요는 없다.
Repository
// [ UserRoomBatchRepository.java ]
private final JdbcTemplate jdbcTemplate;
private static final int BATCH_SIZE = 1000; // 배치 크기 설정 (메모리 오버헤드 방지)
public void batchInsert(List<UserRoom> userRoomList) {
String sql = "INSERT INTO user_room (language, code, is_pass, is_leave, leave_time, created_time, modified_time, user_id, room_id) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)";
Timestamp currentTimestamp = Timestamp.valueOf(LocalDateTime.now()); // 모든 엔티티에 동일한 생성시각 할당.
for (int i=0; i<userRoomList.size(); i+=BATCH_SIZE) {
List<UserRoom> batchList = userRoomList.subList(i, Math.min(i+BATCH_SIZE, userRoomList.size()));
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
UserRoom userRoom = batchList.get(i);
ps.setString(1, userRoom.getLanguage().name());
ps.setString(2, userRoom.getCode());
ps.setInt(3, userRoom.getIsPass());
ps.setInt(4, userRoom.getIsLeave());
ps.setTimestamp(5, userRoom.getLeaveTime() != null ? Timestamp.valueOf(userRoom.getLeaveTime()) : null);
ps.setTimestamp(6, currentTimestamp); // JDBC 사용으로 JPA Auditing가 작동하지 않기 때문에, 직접 할당해야함.
ps.setTimestamp(7, currentTimestamp); // JDBC 사용으로 JPA Auditing가 작동하지 않기 때문에, 직접 할당해야함.
ps.setLong(8, userRoom.getUser().getId());
ps.setLong(9, userRoom.getRoom().getId());
}
@Override
public int getBatchSize() {
return batchList.size();
}
});
}
}동작 과정
- 과정 1. JDBC를 통해 SQL 쿼리를 미리 준비하고 템플릿화
- 과정 2. 설정한 크기(BatchSize)로 UserRoom 엔티티 목록을 나누어 배치
- 과정 3. 각 배치에 대해 PreparedStatement를 사용하여 필드값을 설정
- 과정 4. batchUpdate() 호출하여 대량의 INSERT 쿼리를 한 번에 묶어 데이터베이스에 전송
- 과정 5. 데이터베이스가 일괄적으로 INSERT 쿼리를 실행하여 데이터를 신속하게 저장
이와 같은 과정을 통해 Bulk Insert가 효과적으로 작동하게 된다.
✅ 해결 후 - Service
// [ 방법 1. 해결 전 - JPA saveAll ]
// userRoomRepository.saveAll(userRoomList);
// [ 방법 2. 해결 후 - JDBC Batch Insert ]
userRoomBatchRepository.batchInsert(userRoomList);이처럼 usersEnterRoom() 서비스 메소드에서, 기존의 JPA saveAll 대신 JDBC Batch Insert 을 호출하도록 변경함으로써 문제를 해결하였다.
성능 비교
Test Code
// [ UserRoomServiceTest.java ]
@Test
@DisplayName("다중 사용자 동시입장 - UserRooms Batch Insert")
void usersEnterRoom_Test() {
// ========== < 입장 준비 - Users 생성 > ========== //
// - insert 데이터량 설정
Integer inputUsersCount = 10000; // Users 더미데이터 : 10000명
Long roomId = 1L;
// - Test 이전의 UserRoom & User 개수 측정 (더미데이터 생성 전)
Integer startUserRoomsCount = userRoomRepository.findAll().size(); // 초기 UserRooms 개수
Integer startUsersCount = userRepository.findAll().size(); // 초기 Users 개수
// - Users 더미데이터 생성
List<User> userList = makeFakeUsers(inputUsersCount);
userRepository.saveAll(userList);
// - Users 입장 대기열 참가
...
// ========== < 동시 입장 - UserRooms 생성 > ========== //
// - 대기열의 Users 동시 입장 : Users 개수만큼 UserRooms 더미데이터 생성
LocalDateTime startTime = LocalDateTime.now(); // 동시입장 시작시각 기록
userRoomService.usersEnterRoom(roomId);
LocalDateTime endTime = LocalDateTime.now(); // 동시입장 종료시각 기록
// - 동시입장 실행시간 출력
System.out.printf("\n< JDBC Batch Insert 사용 (JPA saveAll X) >\n");
String printTime = getPrintTime(startTime, endTime);
System.out.printf("- %d명 동시입장 실행시간: %s\n", inputUsersCount, printTime);
// ========== < 종료 - UserRooms,Users 삭제 > ========== //
// - UserRooms 더미데이터 삭제 (자식 엔티티)
List<UserRoom> userRoomList = roomRepository.findById(roomId).orElseThrow().getUserRoomList();
deleteFakeUserRooms(userRoomList);
// - Users 더미데이터 삭제 (부모 엔티티)
deleteFakeUsers(userList);
// - Test 이후의 UserRoom & User 개수 측정 (더미데이터 삭제 후)
Integer endUserRoomsCount = userRoomRepository.findAll().size(); // 롤백후 UserRooms 개수
Integer endUsersCount = userRepository.findAll().size(); // 롤백후 User 개수
// - DB 롤백 검증
assertThat(startUserRoomsCount).isEqualTo(endUserRoomsCount); // UserRooms 롤백여부 검증
assertThat(startUsersCount).isEqualTo(endUsersCount); // Users 롤백여부 검증
}
public String getPrintTime(LocalDateTime startTime, LocalDateTime endTime) {
Duration duration = Duration.between(startTime, endTime); // 실행시간 계산
long milliseconds = duration.toMillis(); // 단위: 밀리초(ms)
double seconds = milliseconds / 1000.0; // 단위: 초(s)
String printTime = String.format("%dms (%.2fs)", milliseconds, seconds);
return printTime;
}이 Test는 대량의 사용자가 동시에 특정 방(roomId=1)에 입장하는 상황을 설정하고, insert 성능 벤치마킹을 수행한다. 주요 목적은 대량의 사용자가 동시 입장할 때, JPA saveAll 방식과 JDBC Batch Insert 방식에서의 성능을 비교하는 것이다.
테스트는 크게 다음 세 가지 단계로 진행된다.
- 대용량의 사용자 생성
- 동시 입장 및 소요시간 측정
- DB 롤백 및 데이터 정합성 검증
결과적으로 대용량 데이터 환경에서 Bulk Insert 시, 발생하는 쿼리 변화와 성능 향상 여부를 분석하고, 이를 실제 지표를 통해 평가하고자 한다.
쿼리 개선
| Before - JPA saveAll | After - JDBC Batch Insert |
|---|---|
| 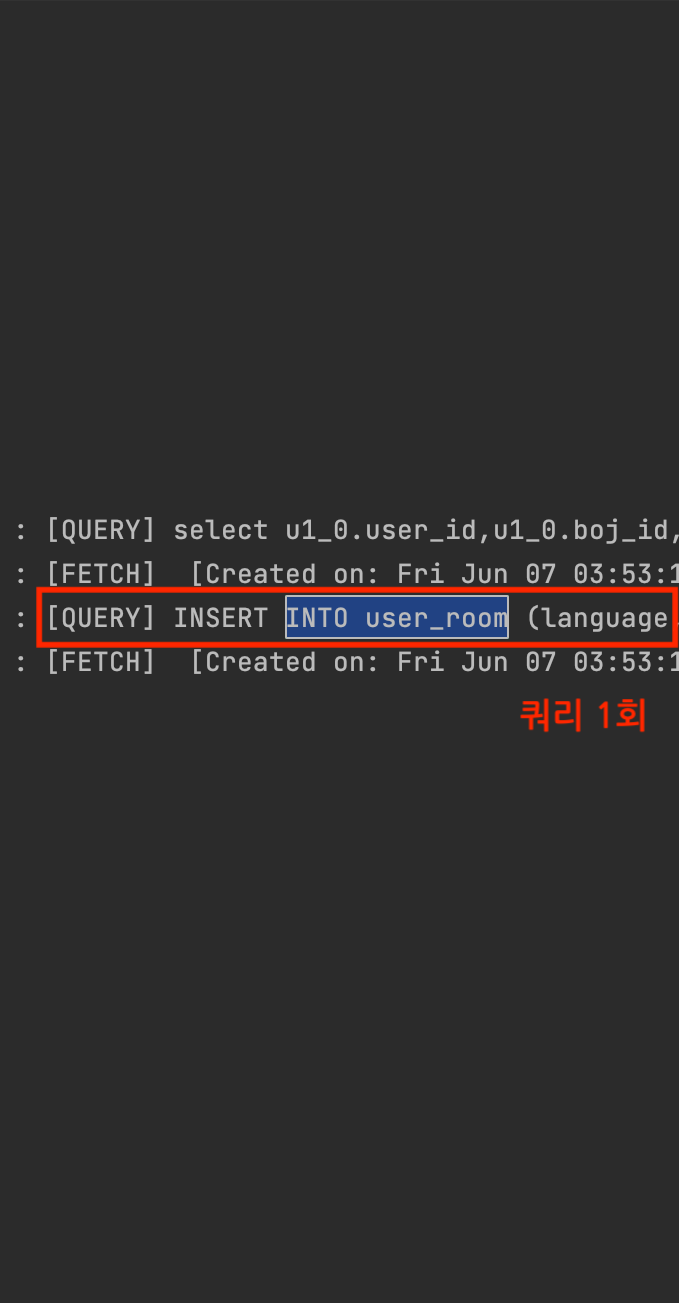 |
| - 입장 인원 수만큼 다중 쿼리 발생 - 쿼리 4회 발생 → Bulk 미적용 문제 O | - BatchSize를 고려한 단일 쿼리 발생 - 쿼리 1회 발생 → Bulk 미적용 문제 X |
4명의 사용자(User)가 방(Room)에 동시 입장(UserRoom)하는 경우,
기존 JPA saveAll 방식은 입장하는 인원 수에 비례하여, 매번 쿼리가 실행되었다. (N회)
반면 JDBC Batch Insert 방식은 인원 수와 무관하게, 쿼리가 통합되어 한 번만 실행되었다. (N회 → 1회)
==> JDBC Batch Insert 방식으로 리팩토링하여, Bulk 처리를 통해 발생 쿼리를 개선할 수 있었다.
속도 향상
| Before - JPA saveAll | After - JDBC Batch Insert |
|---|---|
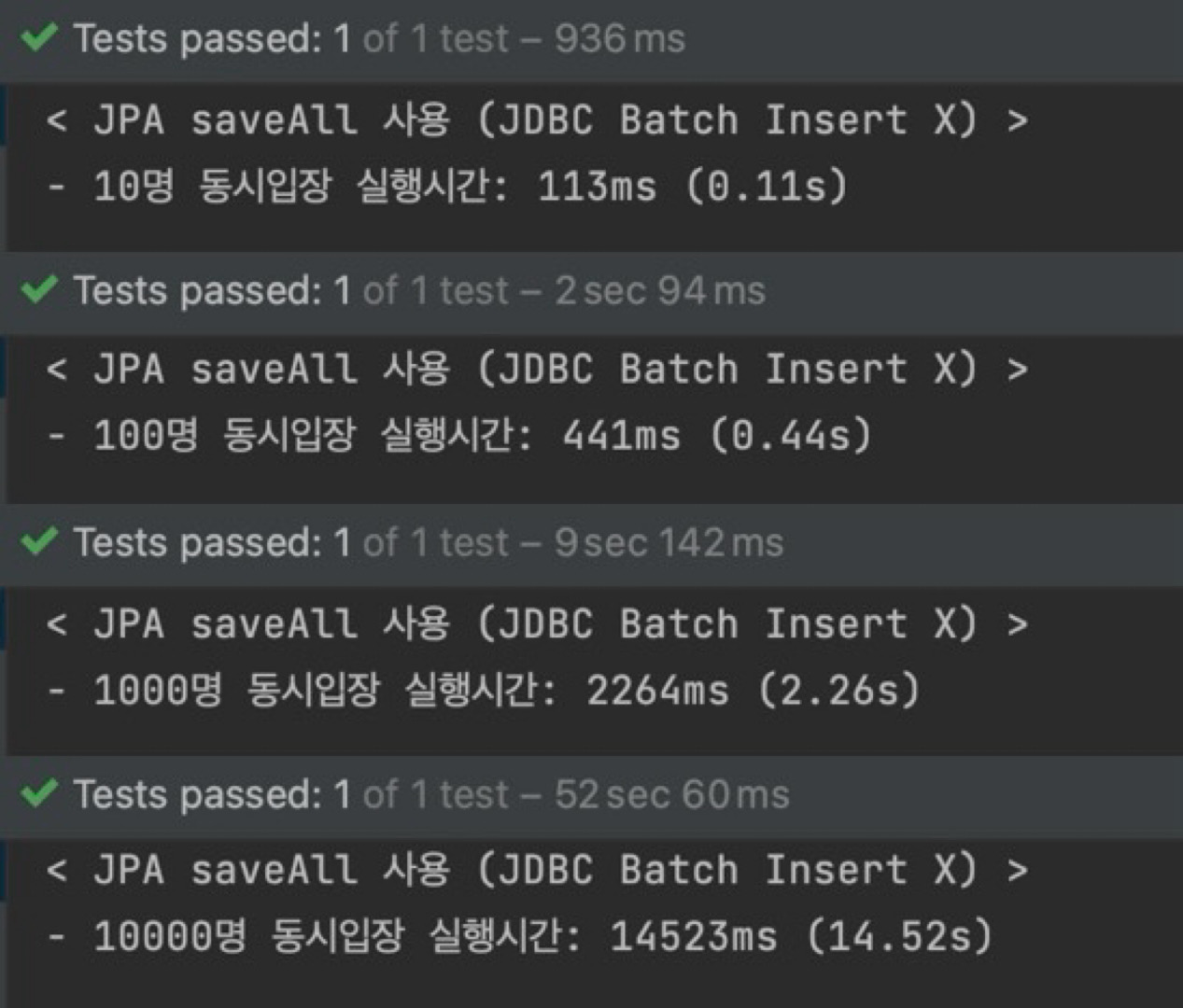 |  |
| - id전략이 IDENTITY라 saveAll이 Bulk로 동작 X - 잦은 DB 접근으로 다중 쿼리 발생 → 성능 저하 | - 배치 처리로 insert가 Bulk로 동작 O - Bulk 처리로 단일 쿼리 발생 → 성능 향상 |
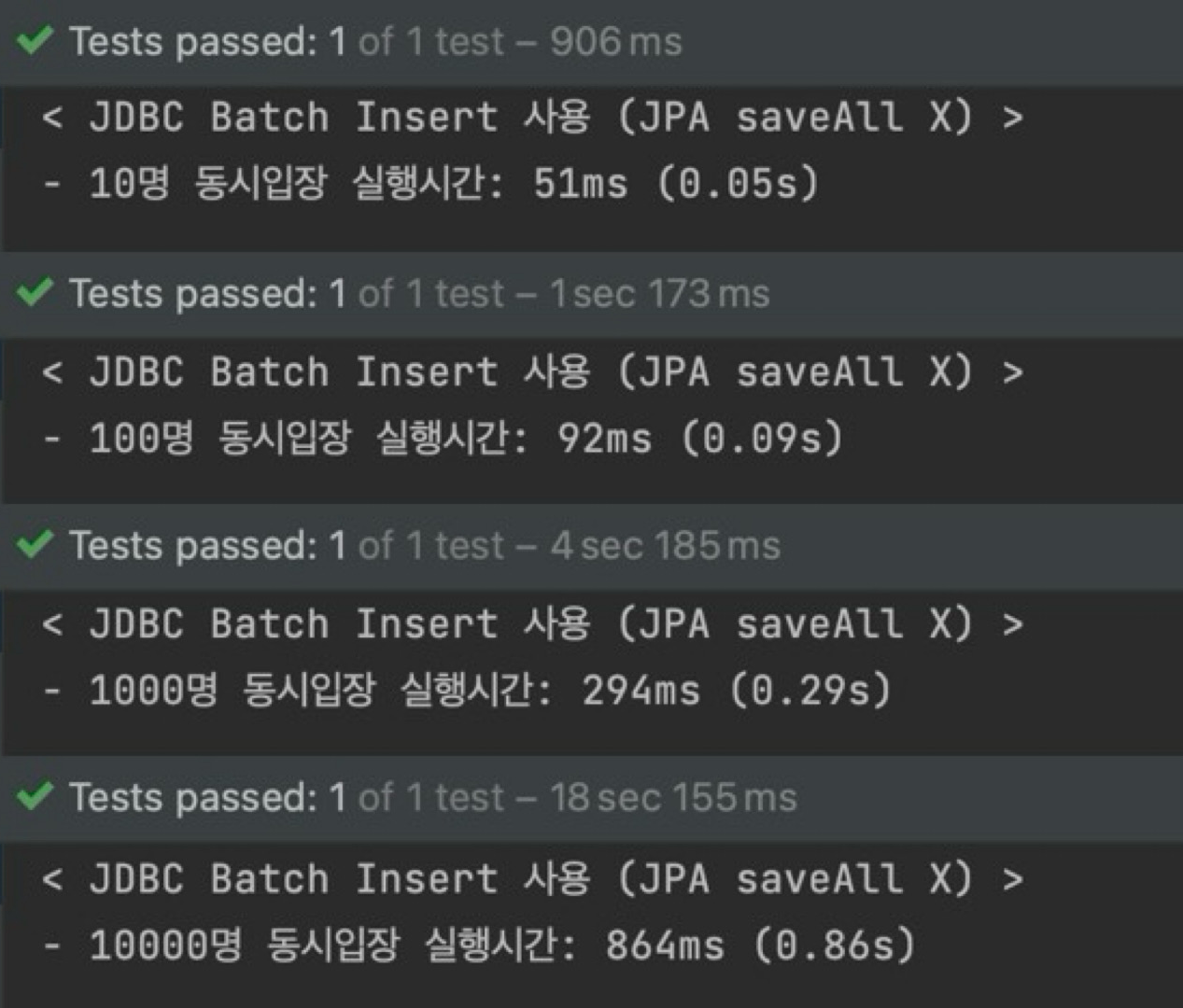
- 10명 : 0.11초 → 0.05초 (2.2배 ↑)
- 100명 : 0.44초 → 0.09초 (4.8배 ↑)
- 1000명 : 2.26초 → 0.29초 (7.7배 ↑)
- 10000명 : 14.52초 → 0.86초 (16.8배 ↑, 95% ↑)
위의 속도 향상 정도를 비교해 보면, 데이터의 양이 많을수록 향상의 폭이 더욱 커지는 것을 알 수 있다.
만약 이 테스트도 10000명에 그치지 않고 더 많은 데이터로 진행했다면, 놀라운 향상폭을 보였을 것이다.
따라서 대용량 데이터를 다룰 때 그 효과가 극대화되며, 이는 용도에 매우 적합하고 우수한 방법임을 나타낸다.
==> JDBC Batch Insert 방식으로 리팩토링하여, 속도를 10000명 기준 95% 향상시킬 수 있었다.
느낀 점
성능 최적화는 단순한 코드 수정에 그치지 않고, 쿼리 등의 내부 프로세스를 분석하고 측정하여, 실제 성능 지표를 통해 개선점을 도출하는 과정이 핵심임을 깨달았다.
특히, 대용량 더미데이터를 활용한 벤치마킹 테스트는 최적화 효과를 입증하는 데 매우 효과적이었다.
이 경험은 최적화의 올바른 접근법을 몸소 이해하고, 보다 실무적인 관점에서 문제를 해결하여 지표적으로 성능을 개선할 수 있는 발판이 될 것이다.
참고 링크
