
💡 본 글은 프로젝트 진행 중 수행한 성능 개선 과정을 다룹니다.
따라서 기능의 의미보다는 문제의 본질에 중점을 두어 설명할 예정입니다.
자세한 정보와 원본 코드, PR 내용은 아래 링크에서 확인하실 수 있습니다.
- Project : Dev Race
- PR 1 : @EntityGraph 리팩토링
- PR 2 : Fetch Join 리팩토링
- P.S.) 다음 프로젝트에서도 해당 리팩토링이 반영되었습니다.
→ 온라인 메모장 Ver.2 / N+1 Query
N+1 문제란?
N+1 문제는 JPA를 사용하다보면 자주 마주하는 쿼리 문제 중 하나로, 기본 엔티티를 조회할 때 연관된 엔티티를 추가로 조회하는 과정에서 발생한다.
구체적으로, 기본 엔티티를 조회하는 SQL 쿼리 외에, 연관된 엔티티를 조회하기 위해 기본 엔티티의 개수(N)만큼 추가 쿼리가 실행된다. 이로 인해 쿼리가 과도하게 발생하여 성능이 저하될 수 있다.
N+1 가 아닌 1+N 문제로 불러야 한다는 의견도 있다.
지연 로딩 (Lazy)
지연 로딩은 연관된 하위 엔티티를 실제로 필요(사용)할 때만 로드하는 방식이다.
하지만 하위 연관 엔티티의 필드에 접근할 때마다 추가 쿼리가 발생하여, N+1 문제가 발생할 수 있다.
즉시 로딩 (Eager)
즉시 로딩은 기본적으로, 연관된 하위 엔티티도 함께 즉시 로드하는 방식이다.
다만 모든 연관 엔티티를 미리 가져오기에 성능 저하를 초래할 수 있어, 사용을 지양하는 것이 좋다.
- 즉시 불러오니, N+1 문제를 해결할 수 있는 것 아닌가?
해결할 수 없다. Eager 로딩은 연관된 데이터를 즉시 로드하지만, 추가 쿼리 또한 즉시 발생하기에 그저 시간의 차이일뿐 Lazy 로딩과 마찬가지로 N+1 문제가 발생할 수 있다.
- 해결 방안은?
미리 말하자면, 이 문제는 연관관계를 한 번의 쿼리로 조회하는 Fetch Join 또는 @EntityGraph를 사용하여 해결할 수 있다. 자세한 설명과 분석은 이후 진행하겠다.
!!! 참고로 이후 언급할 Eager 용어는, 편의상 Fetch Join 처럼 "연관된 데이터를 한 번에 조회한다는 의미"로 사용될 예정이다. 혼동하지 않도록 주의하길 바란다. !!!
N+1 쿼리 발생
ERD
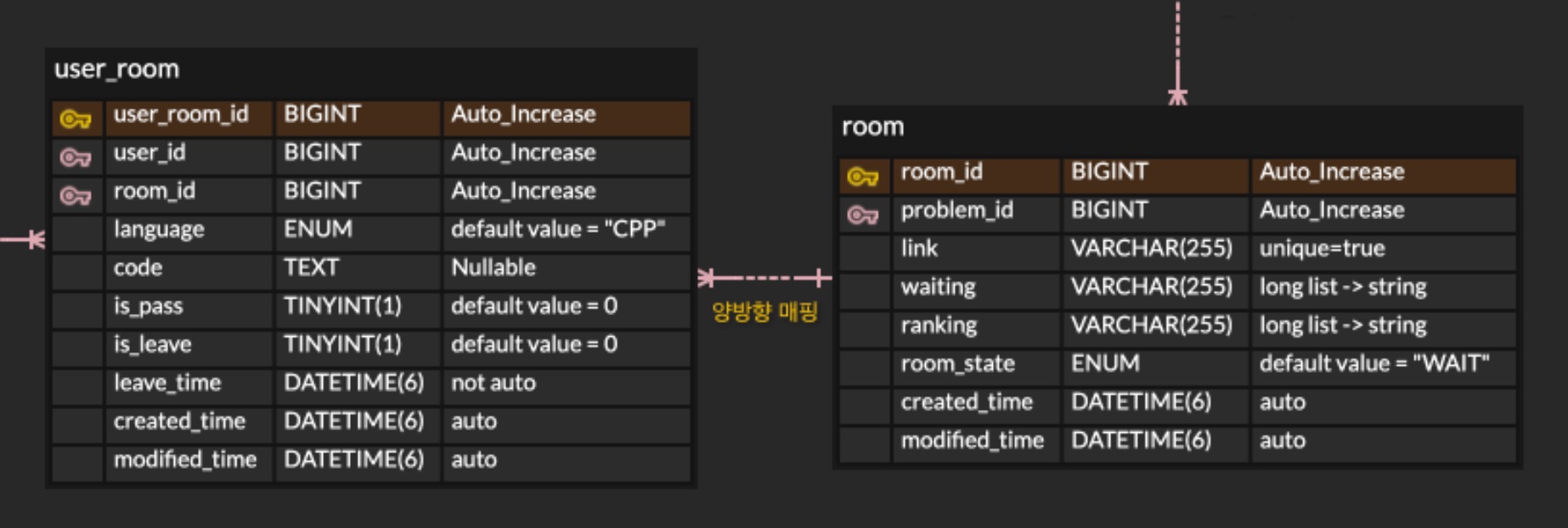
위의 ERD를 보면, UserRoom과 Room은 N:1의 연관 관계로 이루어져있다.
그리고 UserRoom은 room 필드를 가지며, Room은 userRoomList 읽기전용 필드를 가진다.
이제 실제 코드를 바탕으로, N+1 문제가 발생한 케이스들을 상세히 살펴보자.
Entity
UserRoom
@Table(name = "user_room")
@Entity
public class UserRoom {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "user_room_id")
private Long id;
@Column(name = "is_leave", columnDefinition = "TINYINT(1) default 0", length = 1)
private Integer isLeave;
// [ Case 1 ]
// UserRoom 조회 후, room 필드의 하위 roomState를 사용하며 N+1 발생 (room 조회 쿼리 +1)
// [ Case 2 ]
// UserRoom 조회 후, room 필드의 하위 userRoomList를 사용하며 N+1 발생 (room 조회 쿼리 +1)
@ManyToOne(fetch = FetchType.LAZY) // Room-UserRoom 양방향매핑
@JoinColumn(name = "room_id")
private Room room;
}UserRoom을 조회할 때, 기타 필드와 연관 매핑 필드인 room의 기본(껍데기) 정보를 함께 가져온다.
→ 이 경우, 기타 필드나 room '객체 자체만' 사용하면 추가 쿼리는 발생하지 않는다.
Room
@Table(name = "room")
@Entity
public class Room {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "room_id")
private Long id;
@Enumerated(value = EnumType.STRING)
@Column(name = "room_state")
private RoomState roomState;
// [ Case 3 ]
// UserRoom.room 조회 후, userRoomList 필드의 하위 isLeave를 사용하며 N+1 발생 (userRoom 조회 쿼리 +1)
@OneToMany(mappedBy = "room") // Room-UserRoom 양방향매핑 (읽기 전용 필드)
private List<UserRoom> userRoomList = new ArrayList<>();
}Room을 조회할 때, 기타 필드와 연관 매핑 필드인 userRoomList의 기본(껍데기) 정보를 함께 가져온다.
→ 이 경우, 기타 필드나 userRoomList '객체 자체만' 사용하면 추가 쿼리는 발생하지 않는다.
[ Tip ]
아직 Lazy 로딩 상태여도, 하위 엔티티의 FK키는 프록시 객체를 통해 바로 접근이 가능하다.
즉, 만약 room.id만 사용한다면 N+1 추가 쿼리는 발생하지 않는다.
🚨 Case 1 - 해결 전
Repository
// [ UserRoomRepository.java ]
// < 해결 전 - JPA 쿼리 메소드 (Lazy 조회) >
Optional<UserRoom> findByUser_IdAndRoom_Id(Long userId, Long roomId); // UserRoomService
// [ UserRoomServiceImpl.java ]
@Transactional(readOnly = true)
@Override
public UserRoomDto.CheckAccessResponse checkAccess(Long roomId) {
pl("========== !!! 메소드 시작 !!! ==========\n"); // System.out.println
// < 해결 전 - JPA 쿼리 메소드 >
// 'UserRoom.room' Lazy 조회 => N+1 문제 O
pl("===== UserRoom 조회 =====");
Long loginUserId = SecurityUtil.getCurrentMemberId();
Optional<UserRoom> optionalUserRoom = userRoomRepository.findByUser_IdAndRoom_Id(loginUserId, roomId);
pl("===== UserRoom 조회 완료. [1번의 쿼리 발생] =====\n");
// room 필드 객체 자체(껍데기)만 사용 => 추가쿼리 발생 X
pl("===== UserRoom.getRoom() 실행 =====");
Room room = optionalUserRoom
.map(UserRoom::getRoom)
.orElseGet(() -> roomService.findRoom(roomId));
pl("===== UserRoom의 Room을 가져오지만 Room 내부의 변수는 사용하지않음. [추가쿼리 발생 X] =====\n");
// room 필드가 아닌 기타 필드를 사용 => 추가쿼리 발생 X
pl("===== UserRoom.getIsLeave() 실행 =====");
Integer isLeave = optionalUserRoom.map(UserRoom::getIsLeave).orElse(null);
pl("===== UserRoom의 Room 외의 타변수를 사용. [추가쿼리 발생 X] =====\n");
// 껍데기뿐인 room 필드의 하위 roomState에 접근 => 추가쿼리 발생 O
pl("===== UserRoom.getRoom().getRoomState() 실행 =====");
Boolean isExistUserRoom = optionalUserRoom.isPresent();
UserRoomDto.CheckAccessResponse checkAccessResponseDto = UserRoomDto.CheckAccessResponse.builder()
.isExistUserRoom(isExistUserRoom)
.roomState(room.getRoomState())
.isLeave(isLeave)
.build();
pl("===== UserRoom의 Room 내부의 변수를 사용. [@EntityGraph 미처리시 추가쿼리 발생 O] =====\n");
pl("========== !!! 메소드 종료 !!! ==========\n");
...
}Query
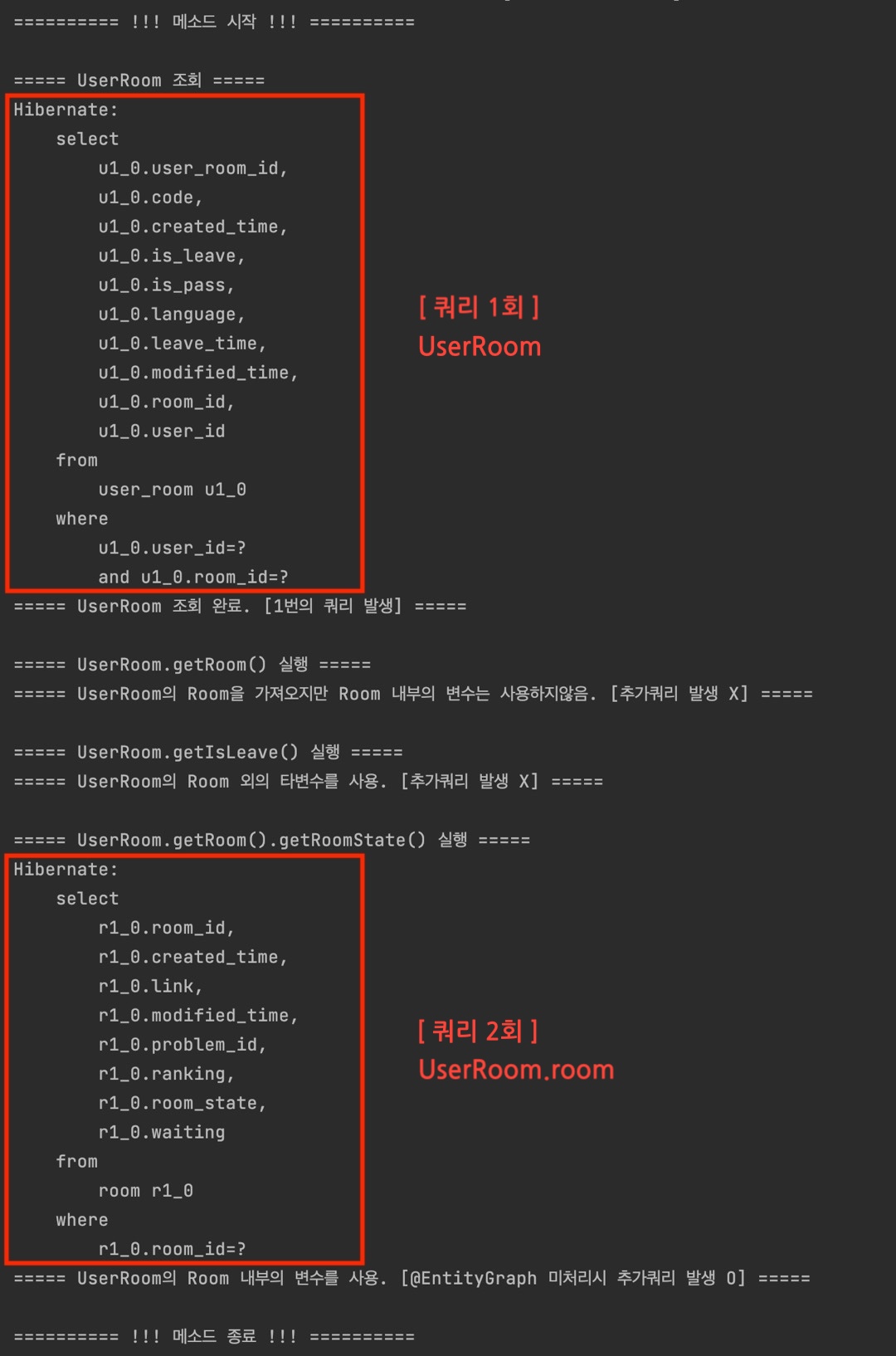
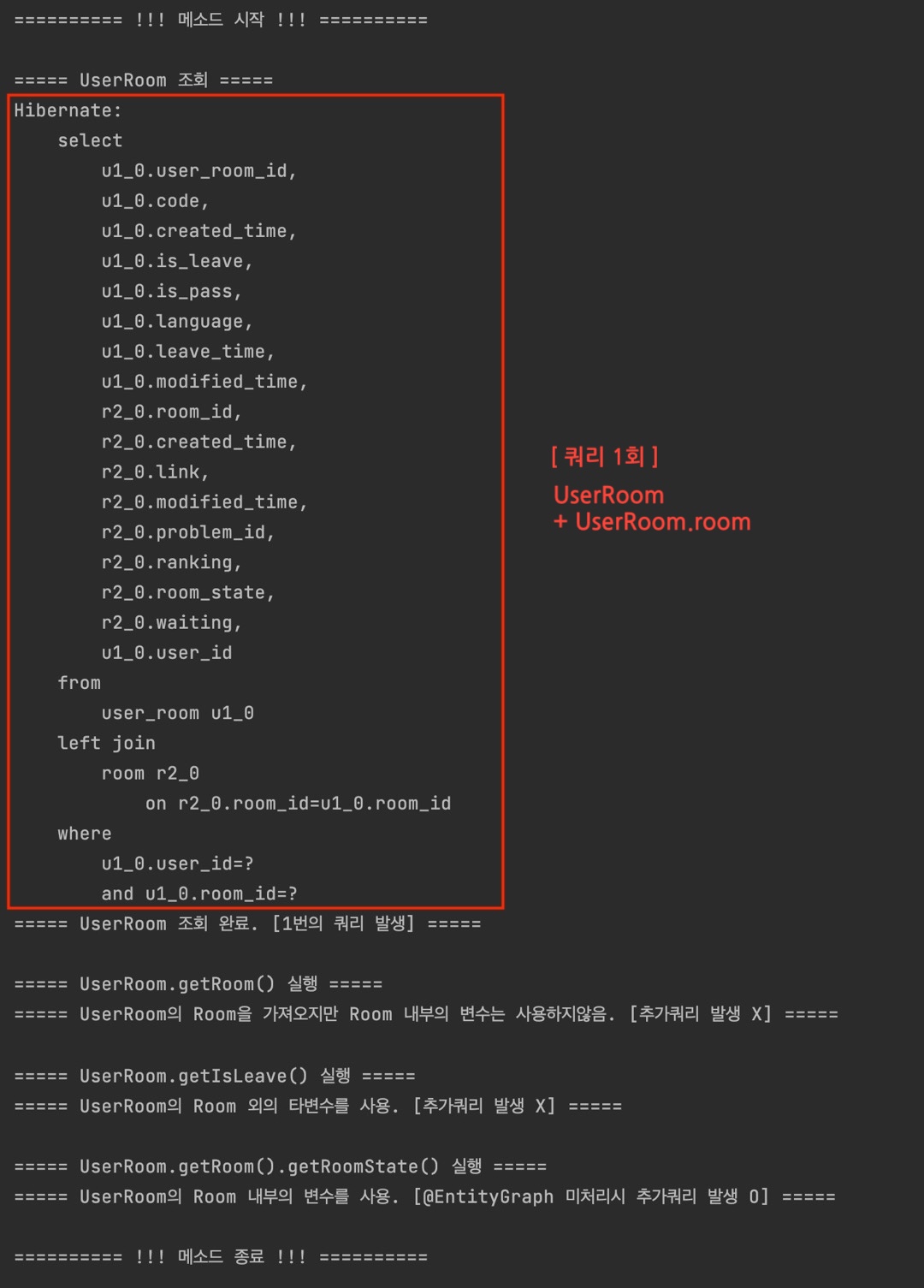
- Case 1 : UserRoom 조회 후, UserRoom.room.roomState 사용
Lazy 로딩으로 껍데기만 가져와진 room 필드의 하위 roomState에 접근할 경우,
room 필드의 내부를 가져오고자 Room 엔티티를 조회하는 추가 쿼리가 발생하게 된다.
즉, 만약 UserRoom을 N개 조회할 경우, 각 UserRoom에 대해 별도로 room을 추가 조회하여 총 N+1개의 쿼리가 발생하는 것이다. 이것이 N+1 문제이다.
🚨 Case 2, 3 - 해결 전
Repository
// [ UserRoomRepository.java ]
// < 해결 전 - JPA 쿼리 메소드 (Lazy 조회) >
Optional<UserRoom> findByUser_IdAndRoom_Id(Long userId, Long roomId); // UserRoomService
// [ UserRoomServiceImpl.java ]
@Transactional
@Override
public void solveProblem(Long roomId, UserRoomDto.SolveRequest solveRequestDto) {
pl("========== !!! 메소드 시작 !!! ==========\n"); // System.out.println
// < 해결 전 - JPA 쿼리 메소드 >
// 'UserRoom.room & UserRoom.room.UserRoomList' Lazy 조회 => N+1 문제 O
pl("===== UserRoom 조회 =====");
Long loginUserId = SecurityUtil.getCurrentMemberId();
UserRoom userRoom = userRoomRepository.findByUser_IdAndRoom_Id(loginUserId, roomId); // 404 예외처리문 생략.
pl("===== UserRoom 조회 완료. [1번의 쿼리 발생] =====\n");
// room 필드 객체 자체(껍데기)만 사용 => 추가쿼리 발생 X
pl("===== UserRoom.getRoom() 실행 =====");
Room room = userRoom.getRoom();
pl("===== UserRoom의 Room을 가져오지만 Room 내부의 변수는 사용하지않음. [추가쿼리 발생 X] =====\n");
...
// 껍데기뿐인 room 필드의 하위 userRoomList에 접근 => 추가쿼리 발생 O
pl("===== UserRoom.getRoom().getUserRoomList() 실행 =====");
List<UserRoom> userRoomList = room.getUserRoomList();
pl("===== UserRoom의 Room 내부의 변수를 사용. [Fetch Join 미처리시 추가쿼리 발생 O] =====\n");
// 껍데기뿐인 room.userRoomList 필드의 하위 isLeave에 접근 => 추가쿼리 발생 O
pl("===== UserRoom.getRoom().getUserRoomList().getIsLeave() 실행 =====");
Boolean isLeaveAllUsers = userRoomList.stream()
.allMatch(enterUserRoom -> enterUserRoom.getIsLeave() == 1);
pl("===== UserRoom의 Room의 UserRoomList 내부의 변수를 사용. [Fetch Join 미처리시 추가쿼리 발생 O] =====\n");
...
pl("========== !!! 메소드 종료 !!! ==========\n");
}Query
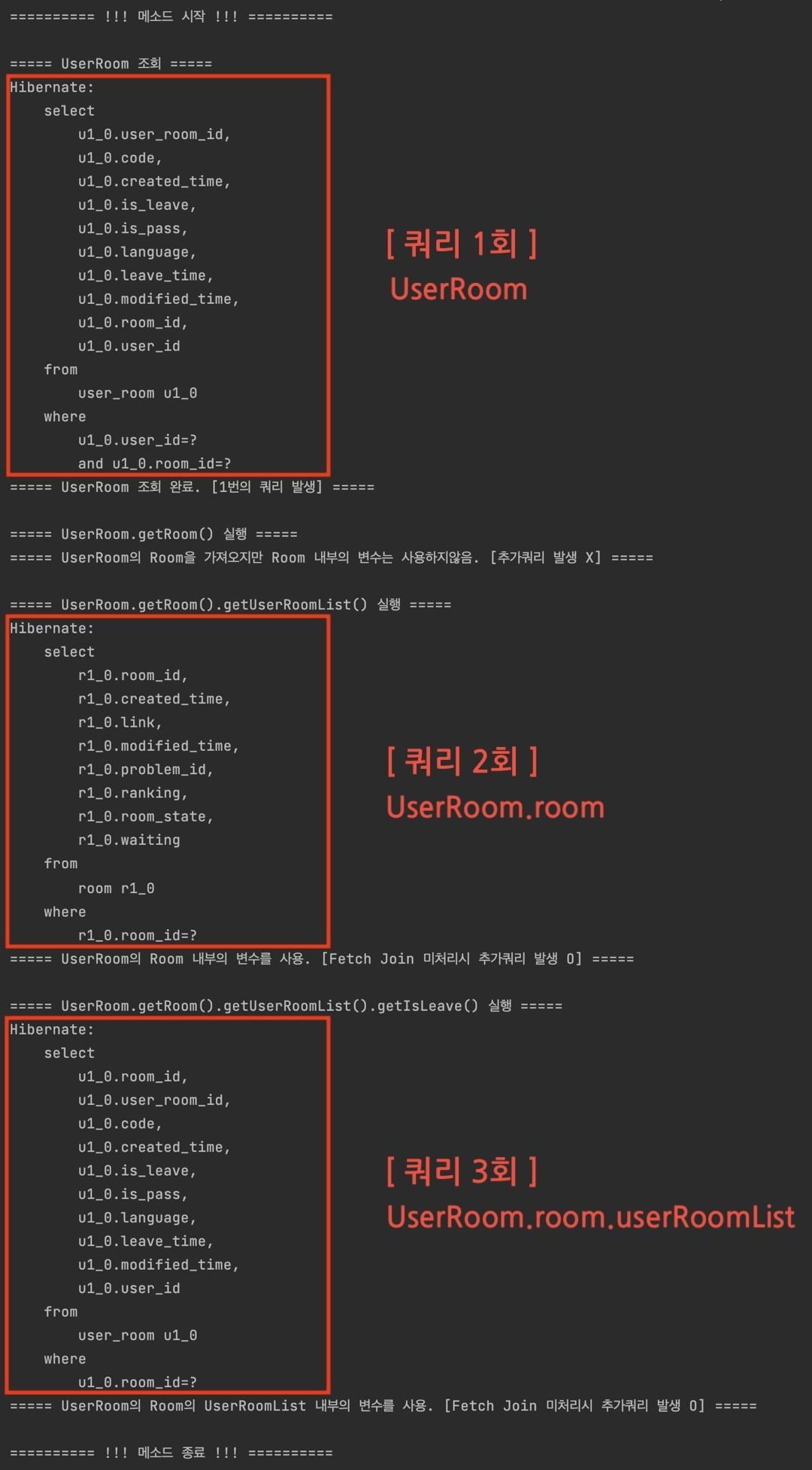
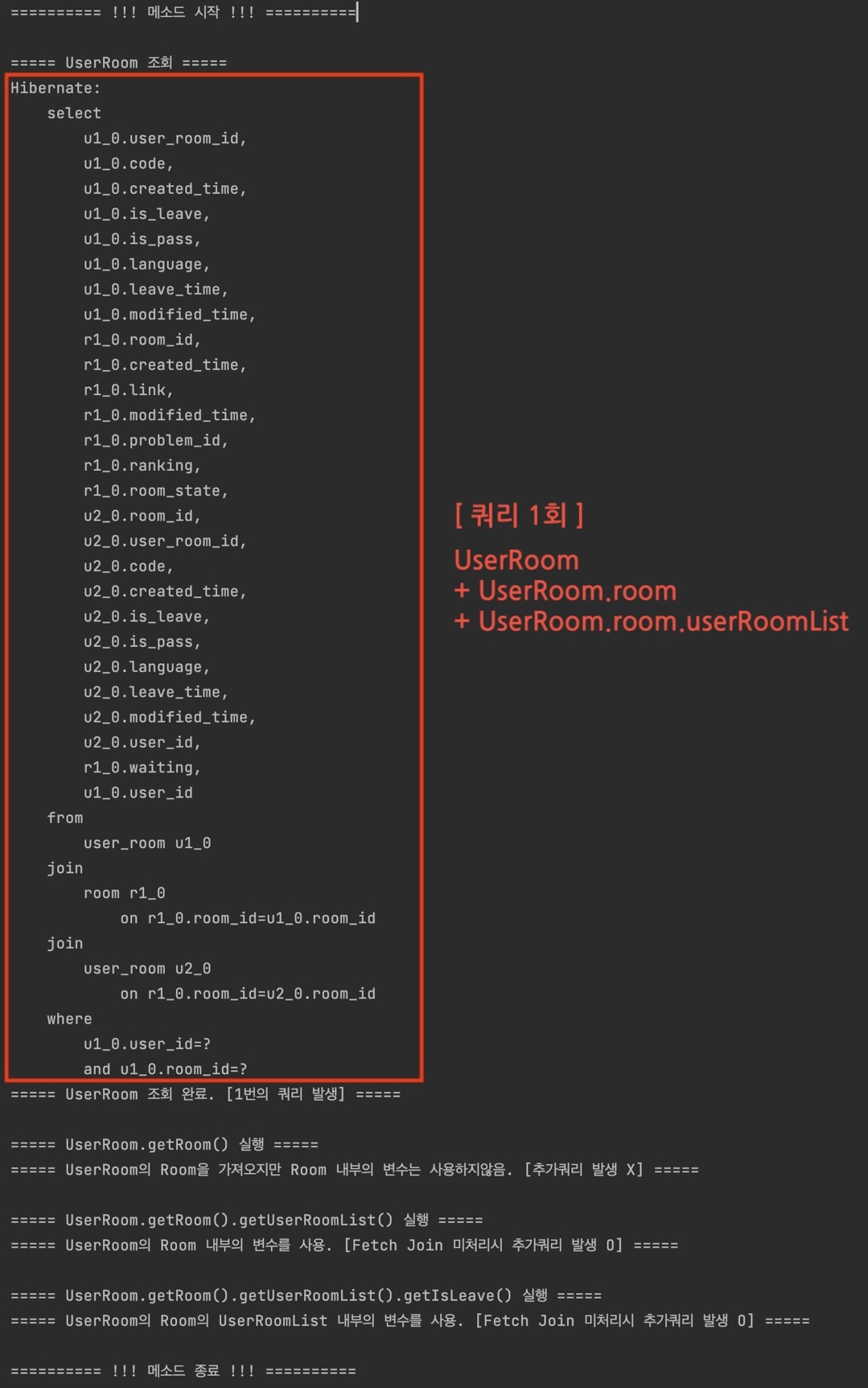
- Case 2 : UserRoom 조회 후, UserRoom.room.userRoomList 사용
Case 1과 동일한 이유로, UserRoom 조회 후 껍데기뿐인 room 필드의 하위 userRoomList에 접근하면, 마찬가지로 Room 엔티티를 조회하는 추가 쿼리가 발생하게 된다.
- Case 3 : UserRoom.room 조회 후, UserRoom.room.userRoomList.isLeave 사용
Case 1과 동일한 이유로, UserRoom.room을 조회 후 껍데기뿐인 userRoomList 필드의 하위 isLeave에 접근하면, 마찬가지로 userRoomList 내 UserRoom 엔티티들을 조회하는 추가 쿼리가 발생하게 된다.
주의할 점은, 1차적인 연관 매핑 필드만 고려한다고 N+1 문제가 완전히 해결되는 것은 아니라는 것이다.
Case 3 처럼 room 필드의 하위 연관 매핑 필드 또한 N+1 문제를 초래할 수 있으므로, 이를 간과해서는 안된다. 따라서 더욱 깊은 연관 매핑 필드에 접근할 경우, 해당 필드들도 함께 고려해야 한다.
해결 방안
Fetch Join (Inner, Left)
Fetch Join 은 SQL 조인과는 달리 Hibernate에서 지원되는 기능으로, JPQL을 통해 성능 최적화를 도와준다. 이는 연관된 하위 엔티티 및 컬렉션을 한 번의 쿼리로 함께 조회할 수 있어, N+1 문제를 해결하는 데 유용하다.
JOIN FETCH 또는 LEFT JOIN FETCH 명령어로 사용이 가능하며, 전자는 inner join 쿼리가, 후자는 left outer join 쿼리가 실행된다.
필드의 fetchType이 Lazy 로딩으로 설정되어 있어도, 이보다 Fetch Join이 더 높은 우선순위를 가지기 때문에, 마치 Eager 처럼 한번의 조회로 연관된 엔티티를 모두 불러올 수 있는 것이다.
물론, Eager 로딩과는 발생 쿼리 수가 확연히 다르다. 비유다 비유..
Inner vs Left
용도 비교
- Fetch Join (Inner join)
- 단일 연관 매핑 필드에 사용. (
@ManyToOne) - '확실히 존재하는' 컬렉션 연관 매핑 필드에 사용. (
@OneToMany) - 예시 : 하위 userRoomList가 반드시 하나 이상의 요소를 가진 경우
- 단일 연관 매핑 필드에 사용. (
- Fetch Join (Left join)
단일 연관 매핑 필드에 사용. (@ManyToOne)- '비어있을 수 있는' 컬렉션 연관 매핑 필드에 사용. (
@OneToMany) - 예시 : 하위 userRoomList가 비어있더라도 정상 반환해주어야 하는 경우
성능 차이
- INNER JOIN
- 두 개의 테이블에서 일치하는 행만 가져옴.
- 검색 범위가 줄어들어 성능이 더 최적화됨.
- LEFT JOIN
- 왼쪽 테이블의 모든 행과 오른쪽 테이블의 일치하는 행을 가져옴.
- 검색 범위가 넓어져 더 많은 자원을 소모함.
→ INNER JOIN이 LEFT JOIN보다 성능이 우수하다. 때문에 위에 언급된 용도가 아니라면, INNER JOIN을 활용하여 Fetch Join을 선언하는 것이 더욱 효과적이다.
주의 사항
1. 별칭 사용 금지
Fetch Join (Inner join)이 아닌 Fetch Join (Left join)을 사용할 때는 별칭을 사용하지 않는 것이 좋다. 이는 DB와의 일관성을 해칠 수 있기 때문이다. 그러나 단순 조회가 목적인 경우에는 별칭을 부여해도 괜찮다.
예시로, 아래의 코드는 Fetch Join (Left join)을 사용한 경우이다.
@Query("SELECT ur FROM UserRoom ur " + // UserRoom
"LEFT JOIN FETCH ur.userRoomList url " + // + UserRoom.userRoomList
"WHERE ur.user.id = :userId AND ur.room.id = :roomId")
Optional<UserRoom> findUserRoom(@Param("userId") Long userId, @Param("roomId") Long roomId);여기서 UserRoom 의미하는 ur은 Fetch Join 대상 필드가 아니므로, WHERE 또는 ON 절에서 해당 별칭을 활용해도 문제가 없다.
반면 ur.userRoomList 의미하는 url은 Fetch Join 대상 필드이므로, WHERE 또는 ON 절에서 사용해서는 안된다. 만약 이처럼 별칭을 잘못 사용하여 컬렉션 결과를 필터링하면, 객체와 DB의 상태 사이에 일관성이 깨지는 문제가 발생할 수 있다.
2. 카테시안곱 중복 발생
카테시안 곱은 두 개 이상의 테이블을 조인할 때 발생할 수 있는 현상으로, 각각의 테이블에서 가능한 모든 조합이 생성된다. 예를 들어, N개의 행을 가진 테이블과 M개의 행을 가진 테이블을 조인하면 총 N * M 개의 결과가 생성되어 중복된 결과가 나타날 수 있다.
이는 특히 @OneToMany 같은 컬렉션 연관 매핑 필드를 Fetch Join 할 때 자주 발생한다.
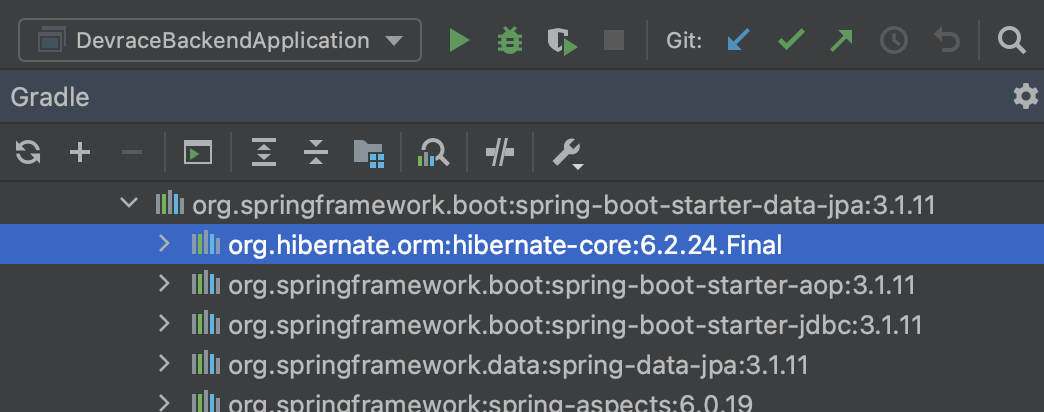 일반적으로 DISTINCT를 사용하면 중복된 결과를 제거할 수 있지만, Hibernate 6부터는 이러한 중복을 자동으로 처리하므로 별도로 신경 쓸 필요가 없다. 위 사진에서 보다시피, 내 "Dev Race" 프로젝트는 Spring Boot 3 이상에서 사용되는 Hibernate 6을 기반으로 하고 있어, DISTINCT를 명시하지 않았다.
일반적으로 DISTINCT를 사용하면 중복된 결과를 제거할 수 있지만, Hibernate 6부터는 이러한 중복을 자동으로 처리하므로 별도로 신경 쓸 필요가 없다. 위 사진에서 보다시피, 내 "Dev Race" 프로젝트는 Spring Boot 3 이상에서 사용되는 Hibernate 6을 기반으로 하고 있어, DISTINCT를 명시하지 않았다.
따라서 Hibernate 6 이전 버전을 사용할 경우, 카테시안 곱이 발생하지 않도록 별도로 DISTINCT를 명시하여 중복된 결과를 제거해야 한다.
Hibernate 공식 문서 :
" Hibernate ORM 6부터는 자식 컬렉션을 join fetching 할 때 동일한 부모 엔터티 참조를 필터링하기 위해 JPQL 및 HQL에서 distinct를 사용할 필요가 더 이상 없습니다. 반환되는 엔터티 중복은 이제 항상 Hibernate에서 필터링됩니다. "
3. 컬렉션 2개 이상 금지
Fetch Join을 사용할 때, @XToOne으로 연관된 단일 필드는 여러 개를 조회할 수 있지만, @XToMany로 연관된 컬렉션 필드는 한 개만 조회할 수 있다. 이로 인해, 두 개 이상의 @OneToMany 연관 매핑 필드를 동시에 Fetch Join 할 경우 MultipleBagFetchException 에러가 발생한다.
// 변경 전 (에러 발생 O)
@OneToMany(mappedBy = "room")
private List<UserRoom> userRoomList = new ArrayList<>();
// 변경 후 (에러 발생 X)
@OneToMany(mappedBy = "room")
private Set<UserRoom> userRoomSet = new HashSet<>();이는 위의 예시처럼 List 대신 Set을 사용하여, 중복된 결과를 허용하지 않는다면 문제를 회피할 수 있다.
→ 요약 : @OneToMany 관계의 연관 매핑 필드를 Fetch Join으로 설정할 때는 하나의 컬렉션만 가능하며, 두 개 이상 사용할 경우에는 Set으로 변경해야 한다.
4. 페이징 금지
Fetch Join을 사용할 때, @XToMany로 연관된 컬렉션 필드는 페이징 API와 함께 사용할 수 없다.
만약 사용하게 되면, Hibernate가 모든 데이터를 불러온 후 메모리에서 페이징을 수행하므로 메모리 과부하를 일으킬 위험이 있다.
그러나 몇 가지 대안이 존재한다.
- BatchSize를 지정하여 페이징 실시
- Fetch Join 시,
@XToOne으로 연관된 단일 필드만 사용
이러한 방법들을 통해 메모리 사용을 최적화하면, 페이징과 Fetch Join을 함께 사용할 수 있다.
@EntityGraph
@EntityGraph는 JPA에서 제공하는 어노테이션으로, Fetch Join을 보다 선언적이고 간결하게 사용할 수 있는 방법이다. 이는 마찬가지로 N+1 문제를 해결하는 데 유용하다.
@EntityGraph(attributePaths = {"userRoomList"}) // + UserRoom.userRoomList
Optional<UserRoom> findUserRoom(Long userId, Long roomId); // UserRoom위의 예시처럼 JPQL 쿼리 메소드를 작성하지 않고도 하위 연관 매핑 필드를 한 번의 쿼리로 가져올 수 있어, 훨씬 간결하고 가독성이 뛰어나다.
단, @EntityGraph 메소드는 LEFT JOIN을 기반으로 작동하기에, Fetch Join (Left)와 마찬가지로 '비어있을 수 있는' 컬렉션 연관 매핑 필드에 사용해야 한다. 때문에 Fetch Join (Inner)보다 성능이 떨어지므로, 사용처에 맞게 신중히 선택해야 한다.
Fetch Join인 JPQL과는 달리, @EntityGraph 메소드는 JPA 네이밍 규칙을 따른다.
따라서 만약 Fetch Join의 기능이 필요하지만, 이미 Repository에서 해당 JPA 쿼리 메소드의 네이밍이 겹친다면, @EntityGraph 대신 Fetch Join을 사용하는 것을 추천한다.
사용처 비교 분석
- 네이밍이 남아서 JPA 쿼리메소드 규칙을 따라도 되는 경우
- 하위 연관 매핑 필드의 존재가 없어도 정상 반환해주어야 하는 경우
→@EntityGraph (Left join)또는Fetch Join (Left join) - 하위 연관 매핑 필드가 존재한다는것이 확실한 경우
→Fetch Join (Inner join)
- 하위 연관 매핑 필드의 존재가 없어도 정상 반환해주어야 하는 경우
- 네이밍이 부족하거나 오버라이딩으로 겹쳐서 JPA 쿼리메소드 규칙을 따르지 못하는 경우
- 하위 연관 매핑 필드의 존재가 없어도 정상 반환해주어야 하는 경우
→Fetch Join (Left join) - 하위 연관 매핑 필드가 존재한다는것이 확실한 경우
→Fetch Join (Inner join)
- 하위 연관 매핑 필드의 존재가 없어도 정상 반환해주어야 하는 경우
✅ Case 1 - 해결 후 (@EntityGraph)
Repository
// [ UserRoomRepository.java ]
// < 해결 후 - @EntityGraph 메소드 (Eager 조회) >
@EntityGraph(attributePaths = {"room"}) // + UserRoom.room
Optional<UserRoom> findByUser_IdAndRoom_Id(Long userId, Long roomId); // UserRoomService
// [ UserRoomServiceImpl.java ]
@Transactional(readOnly = true)
@Override
public UserRoomDto.CheckAccessResponse checkAccess(Long roomId) {
...
// < 해결 후 - @EntityGraph 메소드 >
// 'UserRoom.room' Eager 조회 => N+1 문제 X
pl("===== UserRoom 조회 =====");
Long loginUserId = SecurityUtil.getCurrentMemberId();
Optional<UserRoom> optionalUserRoom = userRoomRepository.findByUser_IdAndRoom_Id(loginUserId, roomId);
pl("===== UserRoom 조회 완료. [1번의 쿼리 발생] =====\n");
...
}@EntityGraph 메소드는 JPA 네이밍 규칙을 따르기에, 사실 호출 메소드명은 이전과 동일하다.
Query
| Before - JPA method | After - @EntityGraph |
|---|---|
|  |
| - Lazy 로딩 : UserRoom.room - 쿼리 2회 발생 → N+1 문제 O | - Eager 로딩 : UserRoom.room - 쿼리 1회 발생 → N+1 문제 X |
기존 JPA 방식은 연관 매핑 필드의 내부에 접근할 때마다 Lazy 로딩되어 매번 쿼리가 실행되었다.
반면 @EntityGraph 방식은 쿼리가 통합되어 한 번만 실행되고, 더는 추가 쿼리가 발생하지 않았다.
==> Case 1 의 경우, @EntityGraph 방식을 채택함으로써 N+1 문제를 해결할 수 있었다.
✅ Case 2, 3 - 해결 후 (FetchJoin)
Repository
// [ UserRoomRepository.java ]
// < 해결 후 - Fetch Join 메소드 (Eager 조회) >
@Query("SELECT ur FROM UserRoom ur " + // UserRoom
"JOIN FETCH ur.room r " + // + UserRoom.room
"JOIN FETCH r.userRoomList " + // + UserRoom.room.userRoomList
"WHERE ur.user.id = :userId AND ur.room.id = :roomId")
Optional<UserRoom> findByUser_IdAndRoom_IdWithUserRoomList(@Param("userId") Long userId, @Param("roomId") Long roomId);프로젝트 기능상, room 필드 및 하위 room.userRoomList는 반드시 존재하기에,
둘 모두 LEFT JOIN 보다 성능이 더 우수한 INNER JOIN을 사용했다.
Service
// [ UserRoomServiceImpl.java ]
@Transactional
@Override
public void solveProblem(Long roomId, UserRoomDto.SolveRequest solveRequestDto) {
...
// < 해결 후 - Fetch Join 메소드 >
// 'UserRoom.room & UserRoom.room.userRoomList' Eager 조회 => N+1 문제 X
pl("===== UserRoom 조회 =====");
Long loginUserId = SecurityUtil.getCurrentMemberId();
UserRoom userRoom = userRoomRepository.findByUser_IdAndRoom_IdWithUserRoomList(loginUserId, roomId); // 404 예외처리문 생략.
pl("===== UserRoom 조회 완료. [1번의 쿼리 발생] =====\n");
...
}Query
| Before - JPA method | After - JPQL Fetch Join |
|---|---|
|  |
| - Lazy 로딩 1 : UserRoom.room - Lazy 로딩 2 : UserRoom.room.userRoomList - 쿼리 3회 발생 → N+1 문제 O | - Eager 로딩 1 : UserRoom.room - Eager 로딩 2 : UserRoom.room.userRoomList - 쿼리 1회 발생 → N+1 문제 X |
기존 JPA 방식은 연관 매핑 필드의 내부에 접근할 때마다 Lazy 로딩되어 매번 쿼리가 실행되었다.
반면 Fetch Join 방식은 쿼리가 통합되어 한 번만 실행되고, 더는 추가 쿼리가 발생하지 않았다.
==> Case 2,3 의 경우, Fetch Join 방식을 채택함으로써 N+1 문제를 해결할 수 있었다.
핵심 정리
N+1 문제의 발생 원인
- 연관된 엔티티를 Lazy 로딩으로 설정했을 때, 하위 필드에 접근할 때마다 추가 쿼리가 발생
- 직접적인 연관 필드뿐만 아니라, 더 깊은 연관 관계에서도 발생 가능
- 즉시 로딩(Eager)만으로는 해결할 수 없음
해결 방안과 각각의 특징
- Fetch Join
- JPQL을 통해 연관 엔티티를 한 번에 조회
- Inner join과 Left join 중 상황에 맞는 것을 선택
- 성능상 Inner join이 유리
- @EntityGraph
- 더 간단하고 선언적인 방식
- 항상 Left join으로 동작
- JPA 네이밍 규칙을 따를 수 있는 경우에 적합
최적의 해결책 선택 기준
- 하위 엔티티가 반드시 존재하는 경우 →
Fetch Join (Inner) - 하위 엔티티가 없을 수 있는 경우 →
@EntityGraph (Left)또는Fetch Join (Left) - JPA 네이밍 규칙을 따르기 어려운 경우 →
Fetch Join
느낀 점
이번 쿼리 개선을 통해 단순히 문제를 해결하는 것을 넘어, 각 해결책의 특성과 적절한 사용 시점을 이해하게 되었다. 이는 앞으로 N+1 성능 이슈에 직면했을 때 더 효과적으로 대응할 수 있는 기반이 될 것이다.
내 시련이 여러분에게도 도움이 되었길 바라며, 글을 마친다.
참고 링크
