
4. 프로세스 스케줄러
스케줄러란 어떤 프로세스에게 자원을 할당할지를 결정하는 운영체제 커널의 코드를 의미한다.
스케줄러는 역할과 목적에 따라서 단기 스케줄러, 중기 스케줄러, 장기 스케줄러로 구분할 수 있다.

4-1. 단기 스케줄러(Short-term scheduler or CPU scheduler)
단기 스케줄러는 미리 정한 스케줄링 알고리즘에 따라 실행할 프로세스를 선택한다.
- CPU와 메모리 사이의 스케줄링을 담당
- ready queue에 존재하는 프로세스 중 어떤 프로세스를 실행할지 결정한다.
- 프로세스에 CPU를 할당한다.
- ready -> running(dispatch)
- 프로세스의 상태는 ready -> running -> waiting(block) -> ready
4-2. 장기 스케줄러(Long-term scheduler or job scheduler)
메모리는 한정되어 있는데 많은 프로세스들이 한꺼번에 메모리에 올라올 경우, 대용량 메모리(디스크)에 임시로 저장된다. 여기에 저장되어 있는 프로세스 중 어떤 프로세스에 메모리를 할당하여 ready queue로 보낼지 결정하는 역할을 한다.
- 메모리와 디스크 사이의 스케줄링을 담당한다.
- 하드 디스크에 있는 프로그램일 메모리에 load하는 역할을 담당한다.
- 메모리에 몇개의 프로그램이 올라갈 것인지 제어한다.
- 프로세스의 상태는 new -> ready
4-3. 중기 스케줄러(Medium-term scheduler or Swapper)
중기 스케줄러는 현 시스템에서 메모리에 너무 많은 프로그램이 동시에 올라가는 것을 조절하는 역할을 한다.
- 메모리의 여유 공간을 마련하기 위해서 프로세스를 통째로 디스크로 쫒아낸다.(swapping)
- 프로세스의 상태는 ready -> suspended
5. 스케줄링 알고리즘
CPU가 하나의 프로세스 작업이 끝나면 다음 프로세스 작업을 수행해야 한다. 이때 어떤 프로세스를 다음에 처리할 지 선택하는 알고리즘을 스케줄링 알고리즘이라 한다.
스케줄링 알고리즘에는 비선점 스케줄링 방식과 선점 스케줄링 방식이 있다.
5-1. 비선점 스케줄링
비선점 스케줄링은 프로세스가 CPU를 할당받으면 작업 종류 후 CPU 반환 시간까지 다른 프로세스는 CPU 점유가 불가능한 스케줄링 방식이다.
모든 프로세스에 대한 요구를 공정하게 처리할 수 있지만, 짧은 작업을 수행하는 프로세스가 긴 작업을하는 프로세스 종료 시까지 대기해야 할 수도 있다.
FCFS, SJF, 우선순위 등
FCFS(First-Come-First-Served) 알고리즘
FCFS는 먼저 들어온 것이 먼저 처리되는 FIFO 구조의 알고리즘이다.(Queue)

대기 시간
P1 = 0
P2 = 18 - 2 = 16
P3 = 25 - 2 = 23
평균 대기 시간 : (0 + 16 + 23)/3 = 13
반환 시간
P1 = 18 - 0 = 18
P2 = 25 - 2 = 23
P3 = 35 - 2 = 33
평균 반환 시간 : (18 + 23 + 33)/3 = 24.66
FCFS의 장점
- 가장 간단한 스케줄링 알고리즘으로 구현이 쉽다.
FCFS의 단점
- 비선점식이라 대화식 프로세스에는 부적합하다.
- 장기 실행 프로세스가 단기 실행 프로세스를 지연시켜 평균 대기시간이 길어지게 된다.
SJF(Shortest Job First)
실행 시간이 가장 작은 프로세스에게 자원을 할당하는 방법이다.

대기 시간
P1 = 10 - 3 = 7
P2 = 0
P3 = 4 - 4 = 0
P4 = 6 - 5 = 1
평균 대기 시간 : (7 + 0 + 0 + 1)/4 = 2
반환 시간
P1 = 15 - 3 = 12
P2 = 4 - 0 = 4
P3 = 6 - 4 = 2
P4 = 10 - 5 = 5
평균 반환 시간 : (12 + 4 + 2 + 5)/4 = 5.75
SJF의 장점
- 항상 실행 시간이 짧은 작업을 가장 먼저 실행하므로 평균 대기시간이 가장 짧다.
SJF의 단점
- 초기의 긴 작업이 짧은 작업들이 끝날 때까지 기다리는 현상이 발생한다.
- 실행 시간을 예측하기 어렵다
- 기본적으로 짧은 작업이 항상 먼저 시작되기에 불공평하다.
우선순위(비선점)
프로세스마다 우선순위를 부여하여 높은 우선순위를 가진 프로세스에게 먼저 자원을 할당하는 방법이다.
우선순위 알고리즘은 선점과 비선점이 있다.
선점 우선순위 스케줄링은 새로 도착한 프로세스의 우선순위가 현재 실행중인 프로세스의 우선순위보다 높으면 높은 우선순위 프로세스가 CPU를 선점한다.(먼저 실행, 가로챔)
비선점 우선순위 스케줄링은 실행중인 것과 무관하게 우선순위가 높으면 큐의 제일 앞에 넣어준다.(가로챔 없음)

대기 시간
P1 = 0
P2 = 11 - 1 = 10
P3 = 14 - 2 = 12
P4 = 5 - 3 = 2
평균 대기 시간 : (0 + 10 + 12 +2)/4 = 6
반환 시간
P1 = 5 - 0 = 5
P2 = 14 - 1 = 13
P3 = 22 - 2 = 0
P4 = 11 - 3 = 8
평균 반환 시간 : (5 + 13 + 0 + 8)/4 = 11.5
우선순위의 장점
각 프로세스의 상대적 중요도를 명시할 수 있다.
실시간 시스템에 유리하다.
우선순위의 단점
높은 우선순위 프로세스가 계속 오면 우선순위가 낮은 프로세스는 기다려야 한다.
5-2. 선점 스케줄링
선점 스케줄링은 하나의 프로세스가 CPU를 차지하고 있을 때 우선순위가 높은 다른 프로세스가 현재 프로세스를 중단시키고 CPU를 점유하는 스케줄링 방식이다.
응답이 빠르다는 장점이 있지만 처리 시간을 예측하기 힘들고 높은 우선순위 프로세스들이 계속 들어오는 경우 오버헤드가 생길 수 있다.
우선순위(선점)


대기 시간
P1 = 8 - 0 - 2 = 6
P2 = 16 - 1 = 15
P3 = 2 - 2 = 0
P4 = 58 - 3 = 55
P5 = 44- 4 = 40
평균 대기 시간 : (6 + 15 + 0 + 55 + 40)/5 = 23.2
반환 시간
P1 = 16 - 0 = 16
P2 = 44 - 1 = 43
P3 = 8 - 2 = 6
P4 = 62 - 3 = 59
P5 = 58 - 4 = 54
평균 반환 시간 : (16 + 43 + 6 + 59 + 54)/5 = 35.6
RR(Round-Robin)
현대적인 cpu 스케줄링 방식으로 각 프로세스는 동일한 할당 시간을 갖게 되고 할당 시간이 지나고 나면 ready queue 맨 끝으로 가서 다시 cpu 할당을 기다린다.

CPU 점유 시간을 2로 제한했을 때
대기 시간
P1 = 21 - 2 4 = 13
P2 = 14 - 2 2 = 10
P3 = 19 - 2 * 3 = 13
평균 대기 시간 : (13 + 10 + 13)/3 = 12
반환 시간
P1 = 23 - 0 = 23
P2 = 15 - 0 = 15
P3 = 21 - 0 = 21
평균 반환 시간 : (23 + 15 + 21)/3 = 19.66
Round-Robin의 장점
- 모든 프로세스가 공정하게 시간을 할당 받는다.
- 프로세스의 최악의 응답시간을 아는데 용이하다.
Round-Robin의 단점
- 하드웨어 타이머가 필요하다.
- 작업 시간을 너무 짧게 하면 Context Switching이 자주 일어나서 오버헤드가 발생한다.
MLQ(MultiLevel Queue)
MLQ(다단계 큐 스케줄링)는 준비 상태 큐를 여러 종류별, 단계별로 분할해두고 자신만의 독자적인 스케줄링 구현이 가능하다.
각 큐는 절대적인 우선순위를 가지며 우선순위가 높은 큐가 모두 비어있기 전에는 낮은 우선순위 큐에 있는 프로세스를 실행할 수 없다.

위의 그림에서 Queue1은 FCFS 방식을 사용하고 Queue2는 RR 방식(CPU 점유 시간 = 2)을 사용하는 모습이다.
MLQ의 장점
- 응답이 빠르다.
MLQ의 단점
- 여러 준비 큐와 스케줄링 알고리즘을 사용하기 때문에 추가 오버헤드가 발생한다.
- 우선순위가 낮은 큐의 프로세스가 기다리는 현상이 발생한다.
6. 동기와 비동기

6-1. 동기(Synchronous)
동기식 처리는 직렬적으로 태스크(task)를 수행한다. 즉, 태스크는 순차적으로 실행되며 어떤 작업이 수행 중이면 다른 작업은 대기하게 된다.
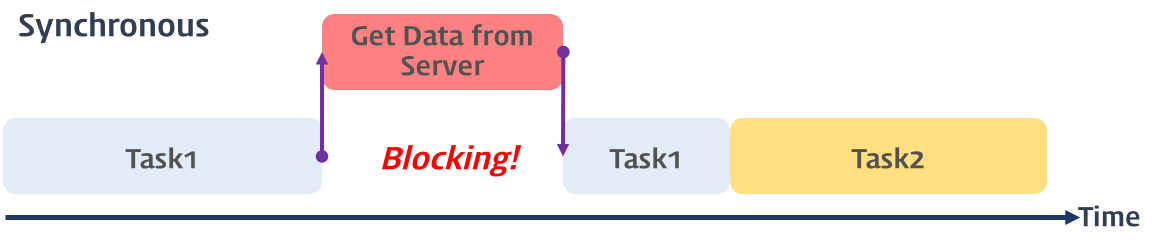
서버에서 데이터를 가져와서 화면에 표시하는 작업을 수행할 때, 서버에 데이터를 요청하고 데이터가 응답될 때까지 이후의 작업들은 Blocking(작업 중단) 된다.
6-2. 비동기(Asynchronous or Non-Blocking)
비동기식 처리는 병렬적으로 태스크를 수행한다. 즉, 태스크가 종료되지 않은 상태라 하더라도 대기하지 않고 다음 태스크를 실행한다.
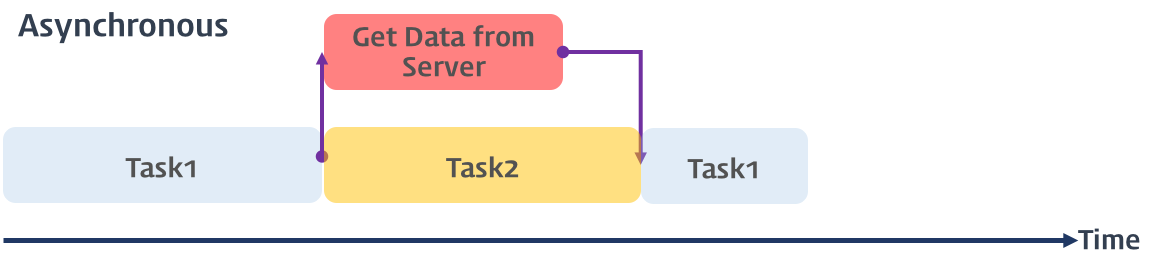
서버에서 데이터를 가져와서 화면에 표시하는 작업을 수행할 때, 서버에 데이터를 요청하고 데이터가 응답할 때까지 기다리지 않고(Non-Blicking) 이후의 작업들을 수행한다. 서버로부터 데이터가 응답되면 이벤트가 발생하고 이벤트 핸들러가 데이터를 가지고 수행할 태스크를 계속해서 수행한다.
참고
