김유성 교수님 교안 + 면접에 나올법한 지식
OSI 7계층
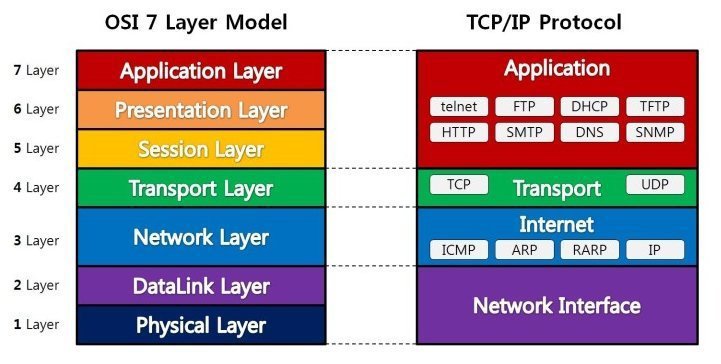
- 존재 이유: 통신이 일어나는 과정이
단계별로 파악할 수 있기 때문 - 흐름을 한눈에 알아보기 쉽고, 사람들이 이해하기 쉽고, 7단계 중 특정한 곳에 이상이 생기면 다른 단계의 장비 및 소프트웨어를 건들이지 않고도 이상이 생긴 단계만 고칠 수 있기 때문
- 전송하면 application layer->..-> physical, 수신할 때 physical->..->applicaition layer
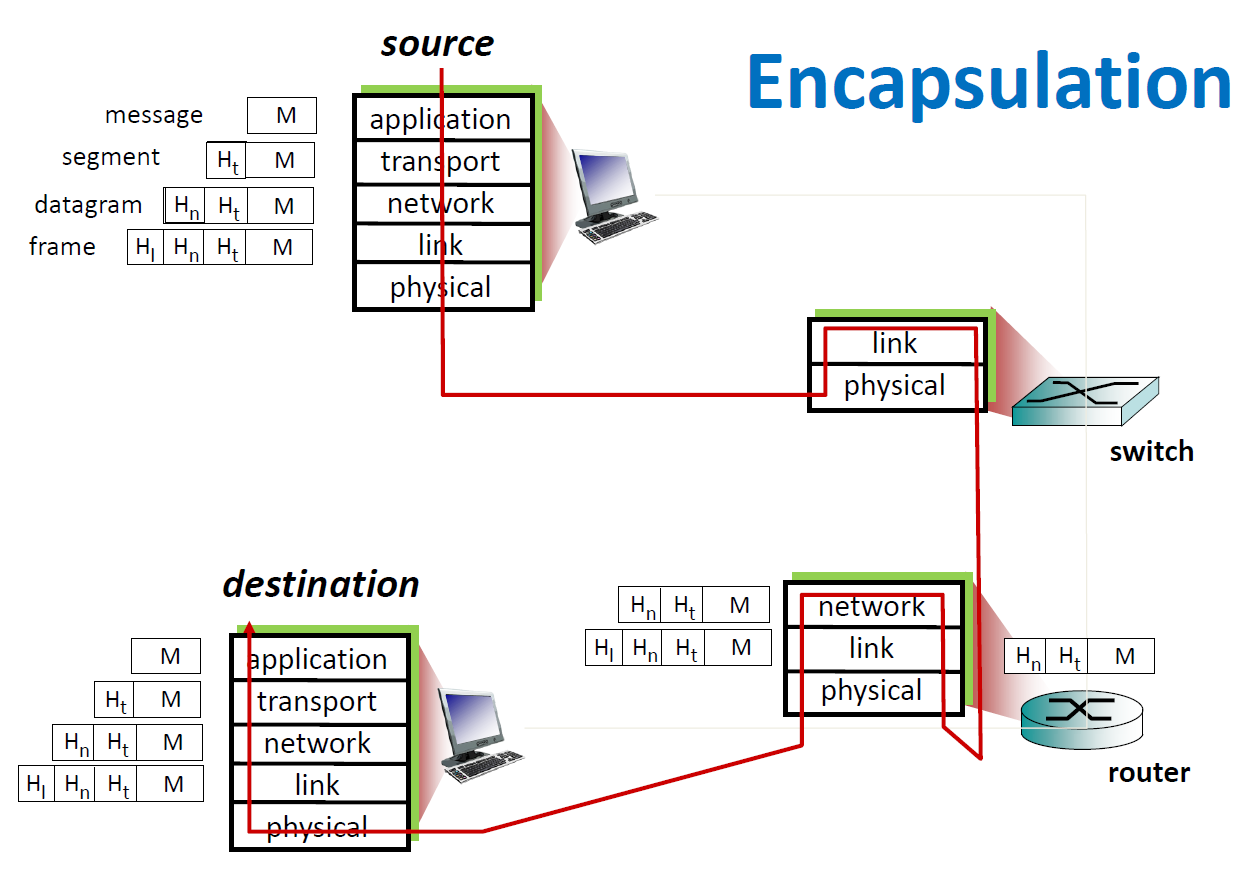
1계층 - 물리계층(Physical Layer)
- 이 계층에서는 주로 전기적, 기계적, 기능적인 특성을 이용해서 통신 케이블로 데이터를 전송하게 된다.
- 이 계층에서 사용되는 통신 단위는 비트이며 이것은
1과 0으로 나타내어지는, 즉 전기적으로 On, Off 상태라고 생각하면 된다. - 데이터를 전달만 할뿐 전송하려는(또는 받으려는)데이터가 무엇인지, 어떤 에러가 있는지 등에는 전혀 신경 쓰지 않는다.
2계층 - 데이터 링크계층(DataLink Layer)
-
네트워크 카드가 만들어질 때부터 물리적 주소값인
맥 주소(MAC address)가 정해져 있음
브릿지나 스위치를 통해 맥주소를 가지고 물리계층에서 받은 정보를 전달함. -
에러검출/재전송/흐름제어 : 물리계층을 통해 송수신되는 정보의 오류와 흐름을 관리하여 안전한 정보의 전달을 수행할 수 있도록 도와주는 역할
-
주소 체계는 계층이 없는 단일 구조이다. 데이터 링크 계층의 가장 잘 알려진 예는
이더넷이다.
3계층 - 네트워크 계층(Network Layer) - (IP 계층)
-
주소부여(IP),경로설정(Route)*- 이 계층에서 가장 중요한 기능은 데이터를 목적지까지 가장 안전하고 빠르게 전달하는
라우팅기능. 여러개의 노드를 거칠때마다 경로를 선택하고 주소를 정하고 경로에 따라 패킷을 전달해주는호스트간의 논리적인 통신
- 이 계층에서 가장 중요한 기능은 데이터를 목적지까지 가장 안전하고 빠르게 전달하는
-
하위계층인 데이터링크 계층의 하드웨어적인 특성에(즉, ATM 이 든 Frame Relay 이든 상관없이) 관계없이 독립적인 역할을 수행
-
비연결성 데이터그램 방식으로 전달되는 프로토콜 ☞ Connectionless
신뢰성(에러제어)및흐름제어기능이 전혀 없어 신뢰성을 확보하려면 IP 계층 위의 TCP와 같은 상위 트랜스포트 계층에 의존
- IP 패킷 헤더 내 수신 및 발신 주소를 포함 ☞ IPv4 헤더, IPv6 헤더, IP 주소
- TCP, UDP, ICMP, IGMP 등이 IP 데이타그램에 실려서 전송
- IP 계층 상에 있는 주요 프로토콜
- 패킷의 전달을 책임지는 IP
- 패킷 전달 에러의 보고 및 진단을 위한 ICMP
- 복잡한 네트워크에서 인터네트워킹을 위한 경로를 찾게해주는 라우팅 프로토콜
- 이 계층의 대표적인 장비는 라우터 이며, 요즘은 2계층의 장비 중 스위치라는 장비에 라우팅 기능을 장착한 Layer 3 스위치도 있다.
4계층 - 전송 계층(Transport Layer)
- 양 끝단(End to end)의 사용자들이 데이터를 주고 받을 수 있도록
프로세스 간의 논리적인 통신 - 상위 계층들이 데이터 전달의 유효성이나 효율성을 생각하지 않도록 해준다.
UDP,TCP- 오류검출 및 복구와 흐름제어, 중복검사
TCP 프로토콜(Transmission Control Protocol)
- 신뢰할 수 있음 (Reliable)
- 양종단 호스트 내 프로세스 상호 간에 신뢰적인 연결지향성 서비스를 제공
- 패킷 손실, 중복, 순서바뀜 등이 없도록 보장, 하위계층인 IP 계층의 신뢰성 없는 서비스에 대해 다방면으로 신뢰성을 제공
- 연결지향적 (Connection-oriented)
- 연결 관리를 위한 연결설정 및 연결해제 필요
UDP 프로토콜(User Datagram Protocol)
- 비연결성, 신뢰성 없음
- Datagram 지향의 전송계층용 프로토콜
- 메세지 확인 응답, 수신 메시지 순서, 흐름, Checksum을 제외한 오류검출 모두 없음
- UDP를 사용하는 프로그램 쪽에서 오류제어 기능을 스스로 갖추어야
- 실시간 응용 및 멀티캐스팅 가능
- 빠른 요청과 응답이 필요한 실시간 응용에 적합(예:스트리밍)
- 여러 다수 지점에 전송 가능 (1:多)
- 단순한 헤더
- UDP는 TCP 처럼 16 비트의 포트 번호를 사용하지만 헤더는 고정크기의 8 바이트(TCP는 20 바이트) 만 사용
- 즉, 헤더 처리에 많은 시간과 노력을 요하지 않음
5계층 -세션 계층(Session Layer)
- 논리적 연결: 양 끝단의 응용 프로세스가 통신을 관리하기 위한 방법을 제공
- TCP/IP 세션을 만들고 없애는 책임
- 하지만 4계층에서도 연결을 맺고 종료할 수 있기 때문에 우리가 어느 계층에서 통신이 끊어 졌나 판단하기는 한계가 있으므로 세션 계층은 4 계층과 무관하게 응용 프로그램 관점에서 봐야 한다.
- 통신하는 사용자들을 동기화하고 오류복구 명령들을 일괄적으로 다룬다.
- 통신을 하기 위한
세션을 확립/유지/중단(운영체제가 해줌)
6계층 - 표현 계층(Presentation Layer)
- 데이터 표현이 상이한 응용 프로세스의 독립성을 제공하고, 암호화 한다.
- 코드 간의 번역. MIME 인코딩이나 암호화 등의 동작
- EBCDIC로 인코딩된 문서 파일을 ASCII로 인코딩된 파일로 바꿔 주는 것,
- 해당 데이터가 TEXT인지, 그림인지, GIF인지 JPG인지의 구분 등이 표현 계층의 몫
- 사용자 시스템에서 데이터의 형식상 차이를 다루는 부담을 응용 계층으로부터 덜어 준다.
7계층 - 응용 계층(Application Layer)
- 응용 프로세스와 직접 관계하여 일반적인 응용 서비스를 수행
- 최종 목적지로서 HTTP, FTP, SMTP, POP3, IMAP, Telnet 등과 같은 프로토콜
- 해당 통신 패킷들은 방금 나열한 프로토콜에 의해 모두 처리되며 우리가 사용하는 브라우저나, 메일 프로그램은 프로토콜을 보다 쉽게 사용하게 해주는 응용프로그램이다. 한마디로 모든 통신의 양 끝단은 HTTP와 같은 프로토콜이지 응용프로그램이 아니다.
- 네트워크 소프트웨어 UI 부분, 사용자의 입출력(I/O)부분
Application Layer
- client-server 구조: 서버는 고정IP, 클라이언트는 거의 동적 IP이며 클라이언트끼리 소통X
- P2P: peer는 다른 peer끼리 자원 공유. self scalability (각 피어가 서비스에 필요한 capacity). 간헐적인 연결과 동적 IP로 복잡한 관리가 필요함
- Processes comminucation: 한 호스트 안에서 다른 프로세스들이 message 교환(OS)
Socket: 프로세스와 컴퓨터 네트워크 사이의 인터페이스. 소켓을 통해 프로세스끼리 통신
Application Layer Protocol
-
what it defines: 메시지의 타입(request, response), 메시지 형식, 메시지 의미(각 필드의), 언제 어떻게 메시지를 주고받을지. (오픈: HTTP, proprietary: Skype 등)
-
Web vs HTTP: Web은 client-server application이며 HTTP는 Web의 어플리케이션 레이어 프로토콜이다. Web은 HTML standard, browser, server, HTTP로 구성되어 있음. 브라우저 개발자는 HTTP RFC 규칙을 따라야 함 -
HTTP: Hyper Text Transfer Protocol- request line(GET, POST 등) + header lines + data
- HTTP는 TCP를 사용하며 stateless 즉
비연결성 - non-persistent HTTP의 response time은
RTT(Round Trip Time)*2 + 파일 보내는 시간 - 서버에 접속한 클라이언트 수가 많아도 서버의 부담이 적으나 정보를 연결할 수 없어 쿠키나 세션같은 방법으로 유지
- HTTP는 connection less 방식으로 연결을 매번 끊고 새로 생성하는데, 이는 최초 연결하기 위한 준비과정을 반복함으로써 network 비용측면에서 많은 비용을 소비하는 구조 (한 페이지에도 이미지, 텍스트 등 많은 요청이 필요하니까)
- HTTP/1.1부터는 이미 연결되어 있는 TCP 연결을 재사용하는 Keep-Alive라는 기능을 Default로 지원해서 Handshake 과정이 생략되므로 성능 향상을 기대 할 수 있다.
-
GET, POST-
GET은 Http Request Message의 Header 부분의 URL에 담겨서 전송되며, BODY는 비어있는 상태 URL 뒤에 ?param1=one¶m2=two 처럼 데이터를 가져오기 위한 조건이 포함되어 있다. -
URL에 조건이 포함되었기 때문에 데이터의 제한이 존재하며, URL에 노출되기 때문에 보안의 위험존재
-
POST는 Http Request Message의 BODY 부분에 클라이언트의 요청을 처리하기 위한 데이터가 존재- URL에 노출되지 않기 때문에 보안의 위험 X, 보내는 데이터의 제한이 없음
-
GET과POST를 상황에 따라 써야하는 이유는, GET 요청은 캐싱이 된다. 그뜻은 웹 서버에 요청이 전달되지 않고, 캐시에서 데이터를 전달해준다는 것이다. -
만약 글작성을 GET으로 처리한다면, 똑같은 요청을 처리했을 때, 캐싱으로 인해 두번째부터의 동일한 글작성은 서버에 전달되지 않고 첫번째 캐싱된 결과를 계속 전달받을 수 있기 때문에 METHOD를 명확하게 구분해서 써야한다.
-
웹 캐시(프록시 서버)
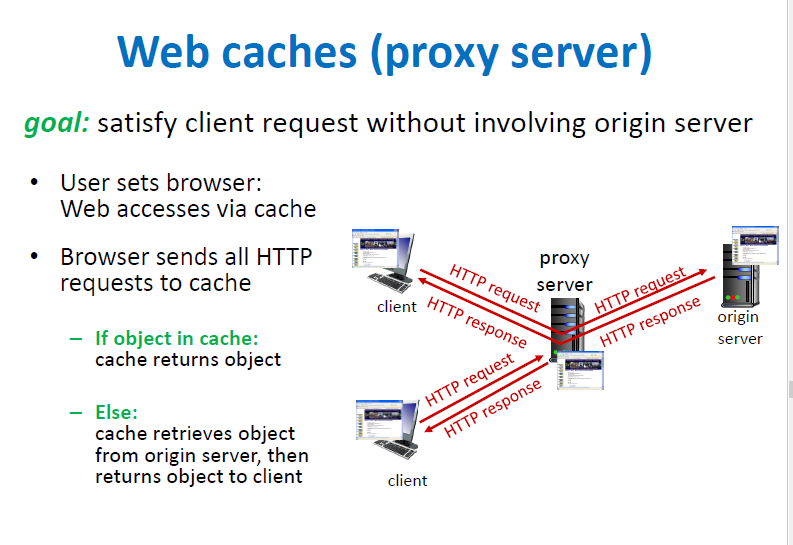
- origin 서버 없이도 미리 저장해둔 데이터로 중간에서 response
- client의 요청에 대한 응답 시간과 트래픽을 줄여주고 효과적으로 데이터 전달
- cache 서버의 데이터가 up-to-date인지(origin 서버와 같은 상태인지) 체크해서 받는
Conditional GET방법도 있음 (if-modified-since헤더)
DNS(Domain Name System)
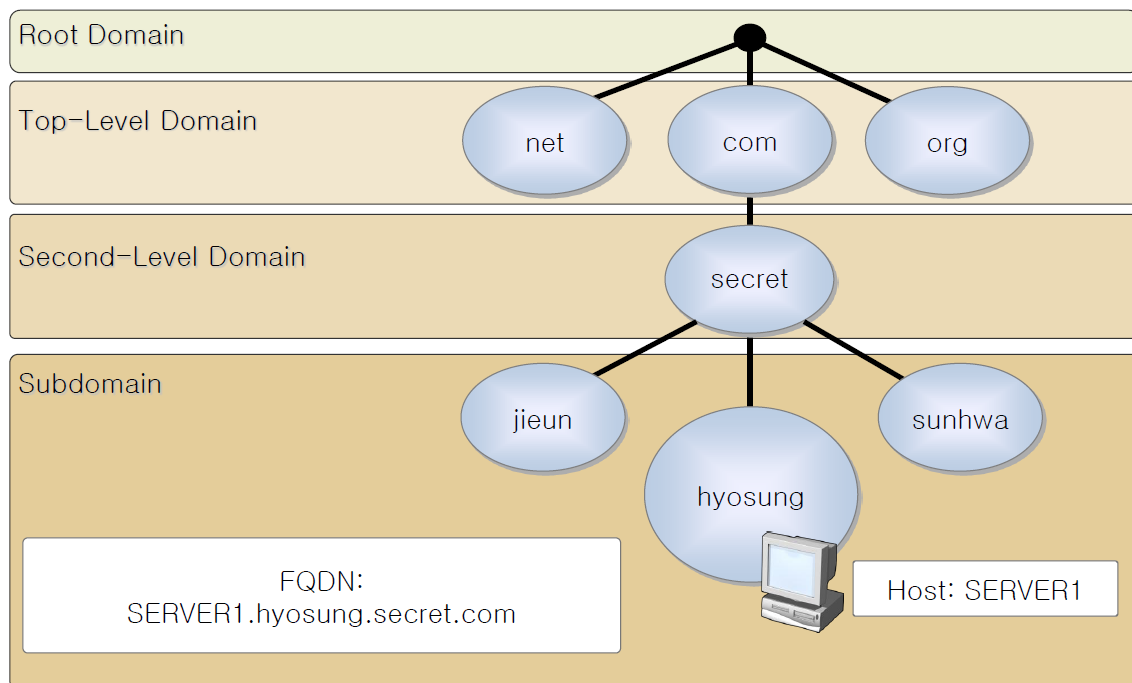
- IP address와 이름을 매핑해주는 시스템. 115.145.129.40 -> www.skku.edu
- 분산되어 있어 한 이름에 여러 IP address가 걸려있을 수 있음
- Root DNS server(전세계 13개 + 600 copy)
-> TLD(Top-Level Domain) .com DNS server
-> skku.com DNS server 등 - 왜 centralize DNS가 아닌가?
- single point of failure
- traffic volume
- 프록시처럼 local DNS name server도 존재함. local->root->tld 순서의 계층
- DNS에 대한 DDoS 공격 존재. 많은 트래픽으로 root server를 공격하는 등
CDN(Content Delivery Networks)
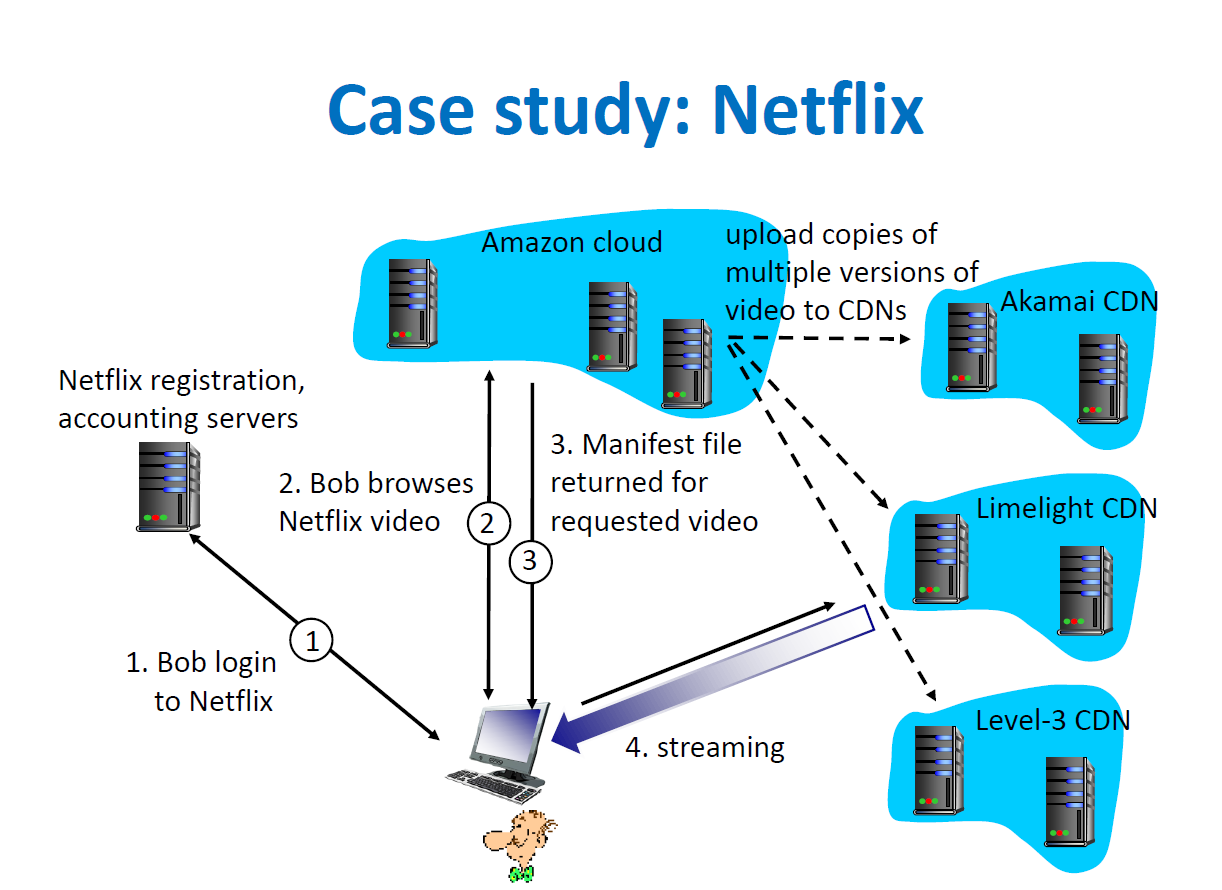
- 지리적, 물리적으로 떨어져 있는 사용자에게 컨텐츠 제공자의 컨텐츠를 더 빠르게 제공하기 위해
Cache Server를 이용하는 기술 - 엔드유저와 가장 가까운 위치에 최적으로 배치된 CDN 서버에 엔드유저가 매핑
P2P
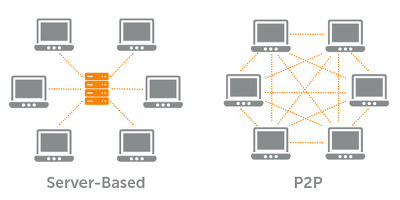
중앙 서버 없이 대등한 관계의 컴퓨터 그룹이 직접 서로 통신하는 분산 구조- 망 구성에 참여하는 Peer들이 processing power, 저장공간, bandwith 등의
자원 공유 - application layer에 네트워크를 build 하는
overlay network - 빠른 인터넷 연결 속도, end-user들의 높은 성능. peer가 많을수록 power 상승
- 확장성, 신뢰성(복사본, 지리적 분산, No single point of failure), 저렴함
Structured P2PDHT(Distributed Hash Table): key: hash(file name); value : a node ( IP address )- assign: 가장 가까운 peer에게 key를 주기, find: key에 해당되는 노드들 찾기
- key lookup 방식
- 직속 successor peer의 주소만 아는 경우: 물어보고->물어보고->물어보고.. 쿼리 O(N) 유지 O(1)
- 모든 peer의 주소를 아는 경우: 쿼리 O(1) 유지 O(N)
- Chord Lookup: 2^i로 뛰며 탐색해서 O(logN)
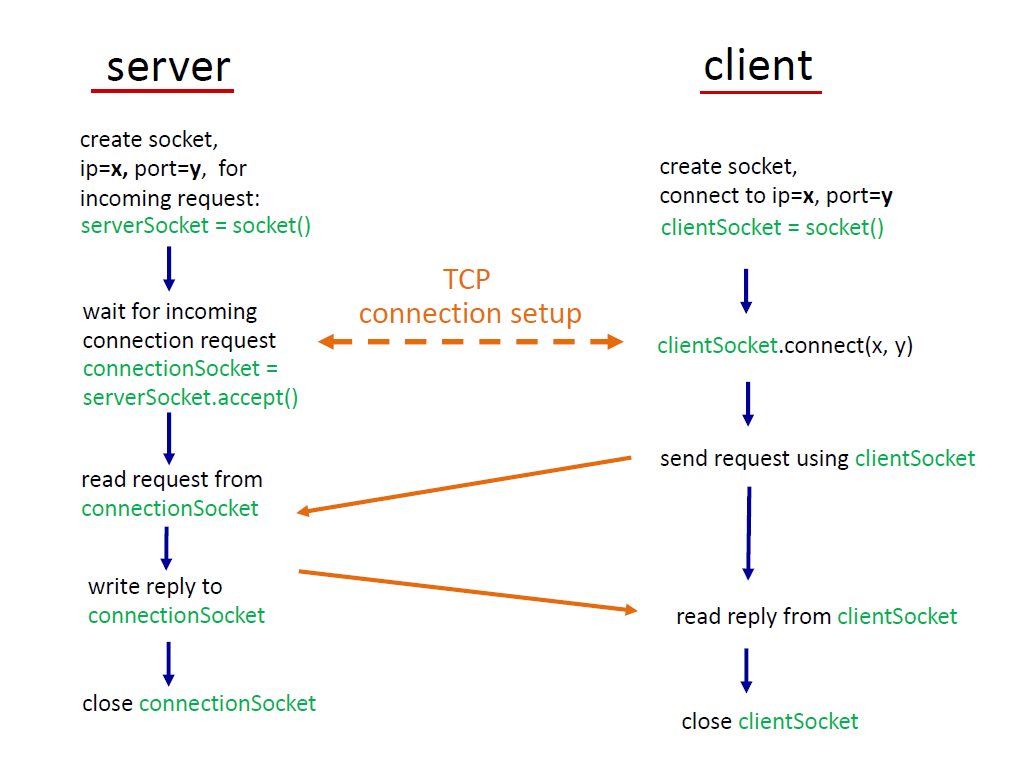
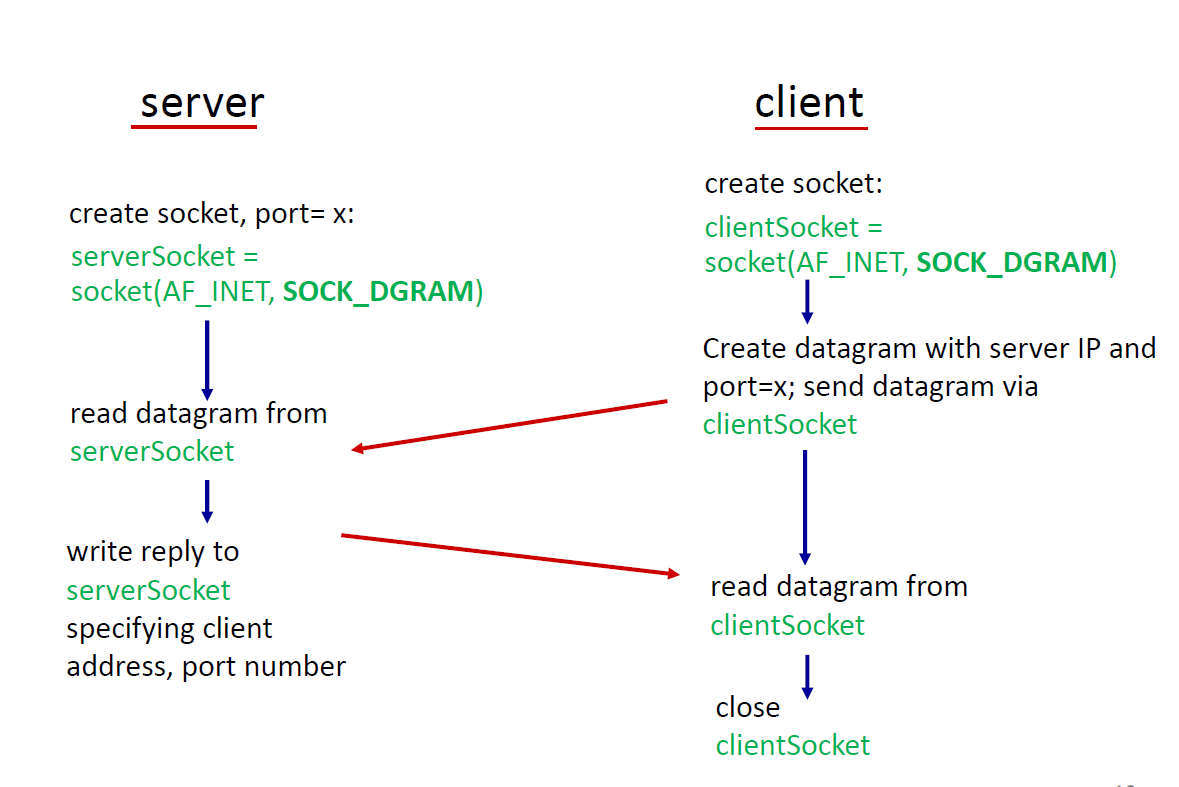
Socket Programming
Socket
- application process와 transport 프로토콜 간의 문
- 소켓의 두 가지 타입: TCP, UDP
TCP
UDP
Transport Layer
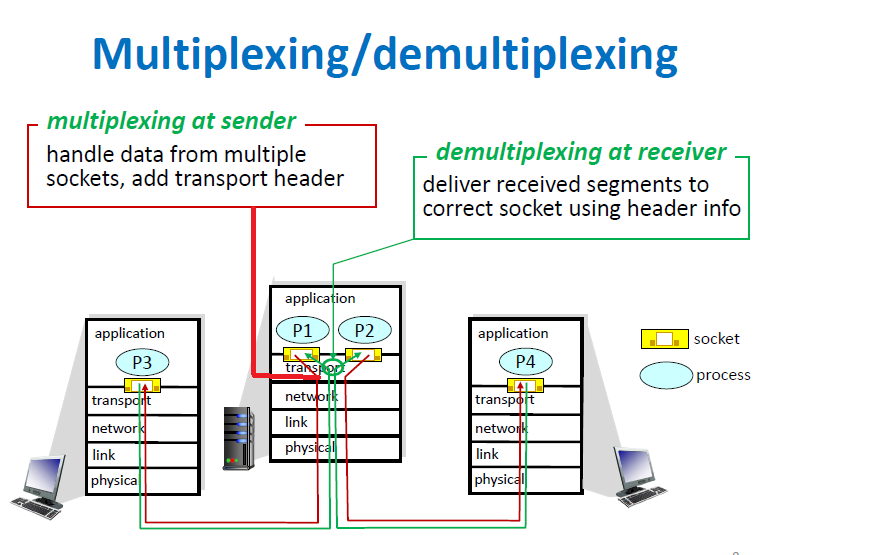
- 다중화(multiplexing) : 여러 소켓의 데이터들을 다루고 전송 헤더 붙임
- 역다중화(demultiplexing) : 받은 데이터들 전송 헤더 정보를 보고 해당하는 소켓에 전달
검사합(checksum)- 네트워크를 통해 전달 된 값이 변경되었는지를 감지하기 위함. 헤더에 포함되어 있음
- <예시> 다음과 같이 4 바이트의 데이터가 있다고 치자: 0x25, 0x62, 0x3F, 0x52
- 1단계: 모든 바이트를 덧셈하면 0x118이 된다. -> 0001 0001 1000
- 2단계: 캐리 니블(최상위 니블)을 버림으로써 0x18을 만든다 -> 0001 1000
- 3 단계: 0x18의 2의 보수를 얻음으로써 0xE8을 얻는다. 이것이 체크섬 바이트이다. -> 1의보수: 1110 0111, 2의보수: 1110 1000 -> 0xE8
- 체크섬 바이트를 테스트하려면 원래 그룹의 바이트에 체크섬 바이트까지 모두 더하면 0x200이 된다. -> 0x118+0xE8 = 0x200 -> 0010 0000 0000
- 다시 캐리 니블을 버림으로써 0x00이 된다. 0x00이라는 뜻은 오류가 없다는 뜻이다. (하지만 오류가 있어도 우연히 0x00이 될 수도 있다.)
-
RDT(Reliable Data Transfer) v3.0의 원리
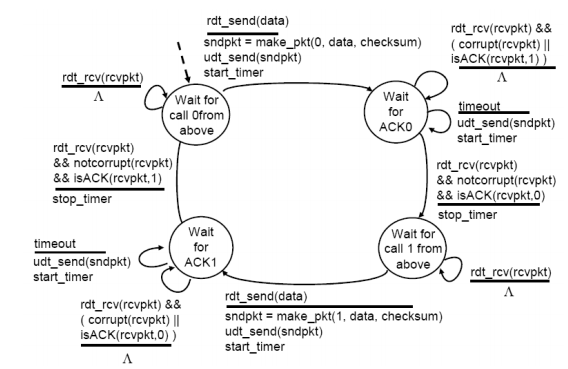
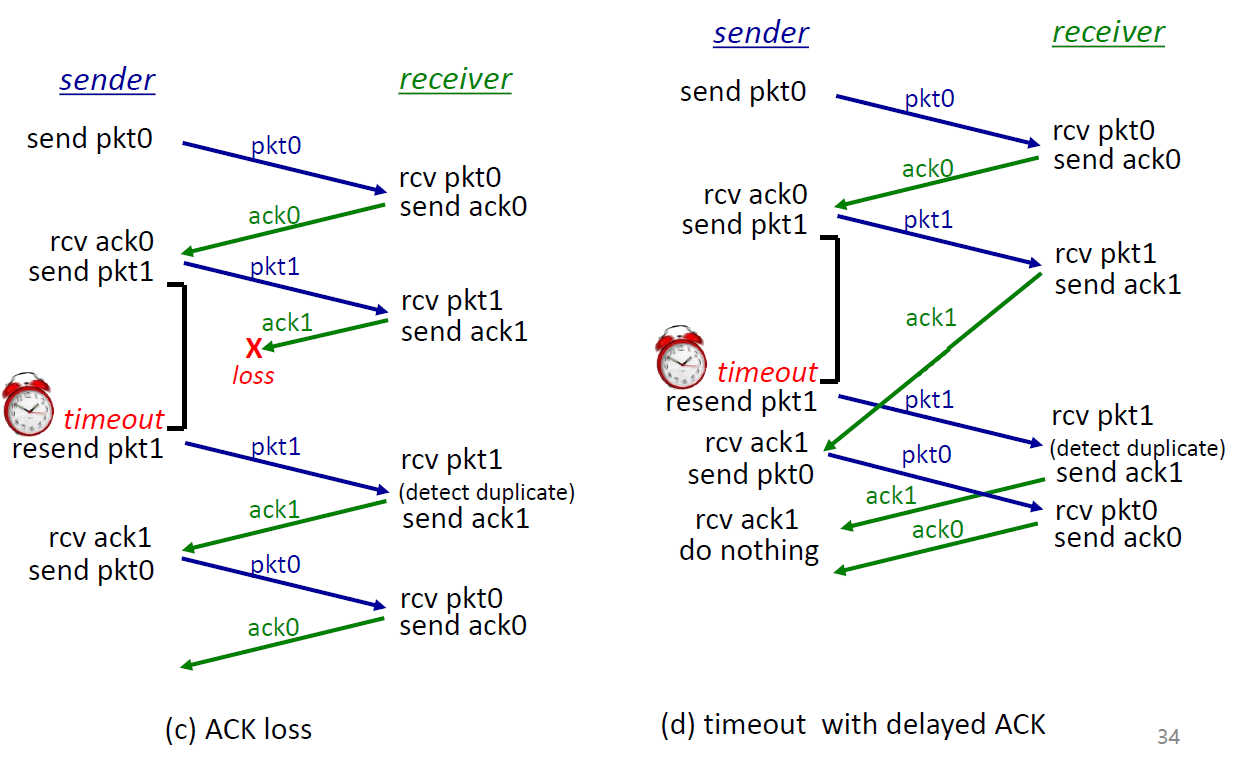
- 기존의 checksum, seq #, ACKs, retransmission + timer로 정해진
timeout을 재고,중복 처리추가 - 이런
stop-and-waitoperation의 문제점: RTT를 기다리는 시간 낭비
- 기존의 checksum, seq #, ACKs, retransmission + timer로 정해진
Pipelined Approach
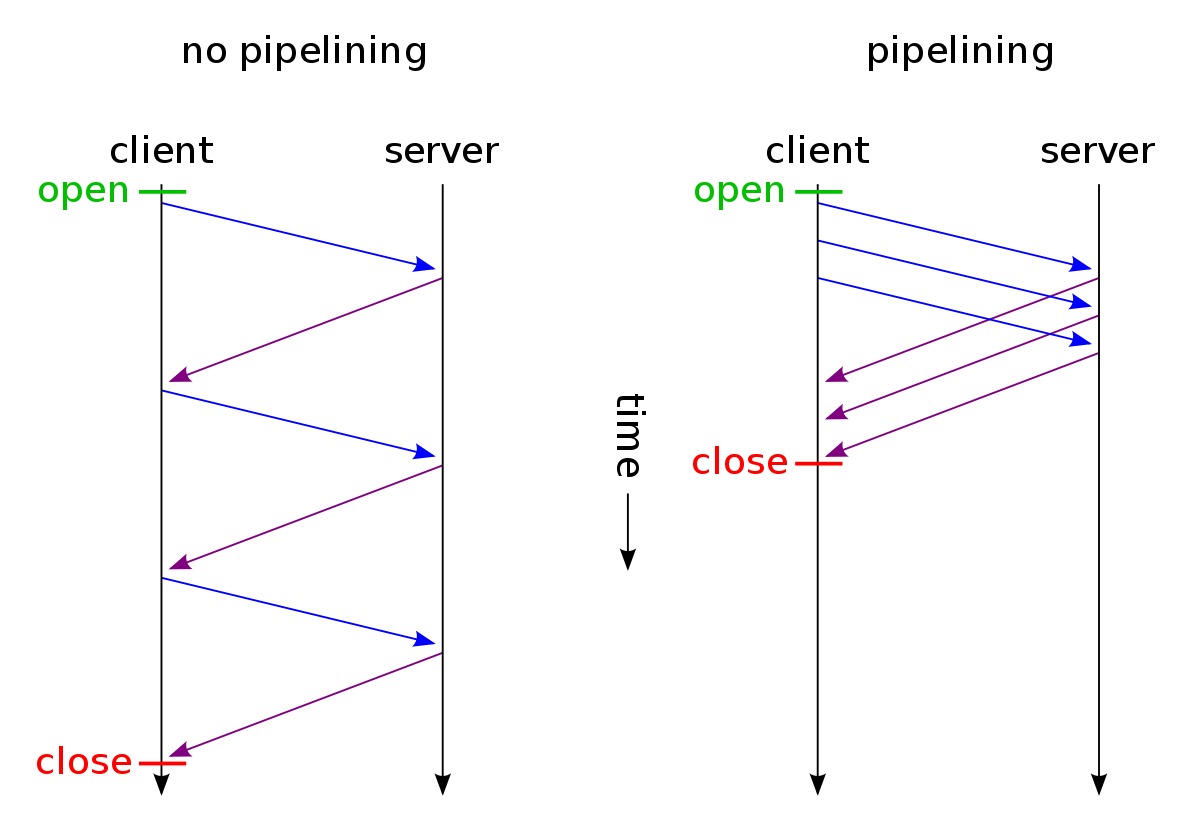
- Pipelining : sender는 아직 ack 받지 못하더라도 여러
in-flight패킷을 보냄 - Pipelined protocols(Go-Back-N, Selective Repeat)
- 공통점: 송신자는 N개만큼의 unacked 패킷을 파이프라인에 가질 수 있으며 타이머 잼
- 공통점: 송신자는 N개만큼의 unacked 패킷을 파이프라인에 가질 수 있으며 타이머 잼
Go-Back-N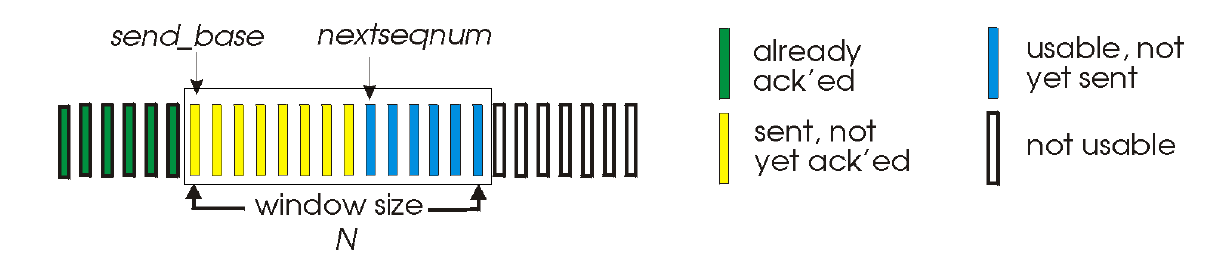
- 가장 오래된 unacked 패킷에 대해서만 timer 잼
- 수신자는 성공적으로 받은데까지만 표시되는
cumulative ACK만을 전송 - 타이머 끝나면 이후에 잘 받은 패킷이 있더라도 모든 unacked 패킷을 재전송
-
Selective Repeat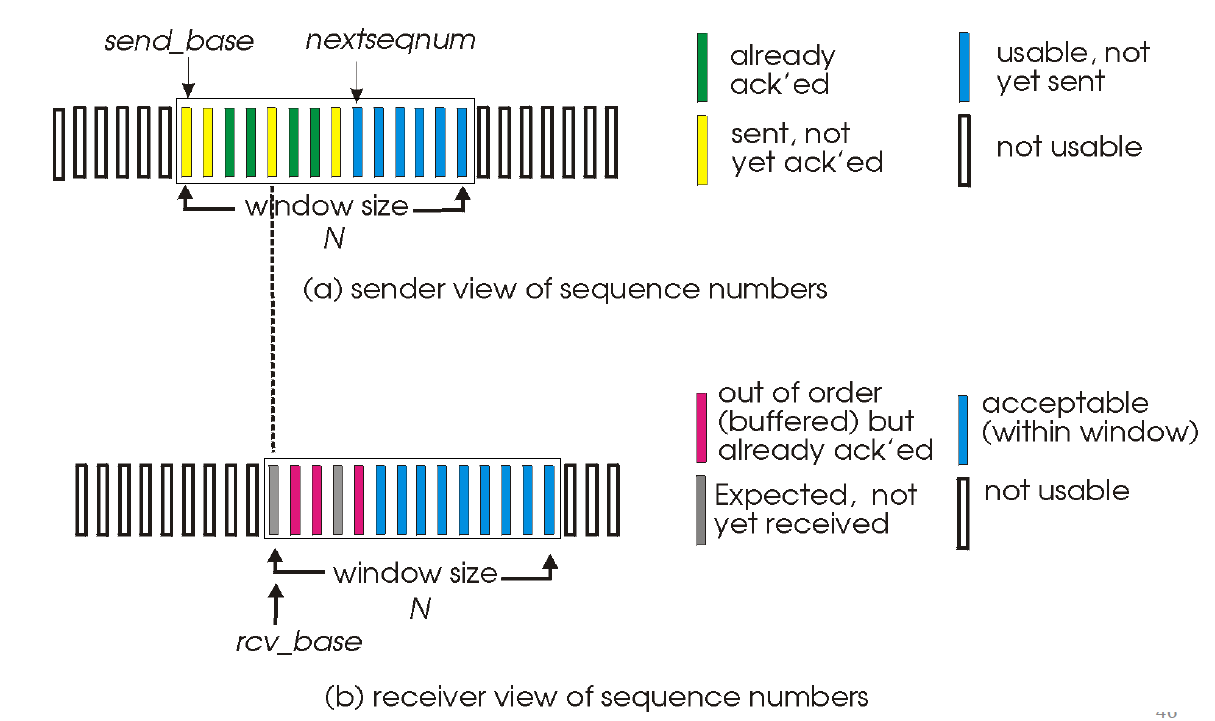
- 모든 패킷 각각에 대해 timer 잼
- 수신자는 개별
individual ACK를 전송 - 타이머 끝나면 unacked 패킷에 대해서만 재전송
-
TCP(Transmission Control Protocol)cumulative acks: 받은 마지막 패킷까지 표시ACK가 누락되어 갑자기 점프해도send Base는 마지막 ACK 기준- single retransmission timer : 타이머는 제일 오래된 unacked 패킷 하나만
- timeout,
3 duplicate acks에 의해 재전송 : ACK seq로 전송 안 된 패킷 판단 - timeout 기준은 최근 전송들에 걸린
avgRTT(최근 전송일수록 가중치 up)+safety margin를 계산해서 업데이트
-
TCP의 flow control
- receiver가 sender를 컨트롤하여 sender가 너무 빠르거나 많이 전송해서 receiver의 버퍼를 초과하지 않도록 하는 것
- receiver는
rwnd(receiver window)즉 남은 버퍼 공간을 TCP 헤더에 보냄 - sender는
cwnd(congestion window)를 받은 rwnd에 기반해 제한함
-
TCP의 connection control
- 연결 시: 3 way handshake
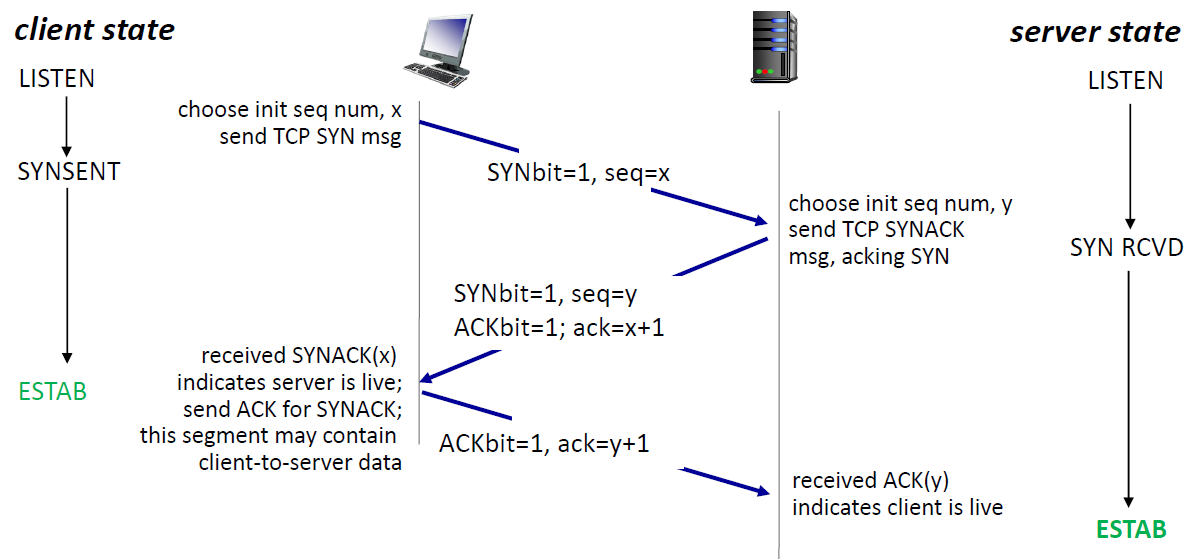
- SYN(SYNCHRONIZE) - SYN+ACK(ACKNOWLEDGE) - ACK
- 종료 시: 4 way handshake
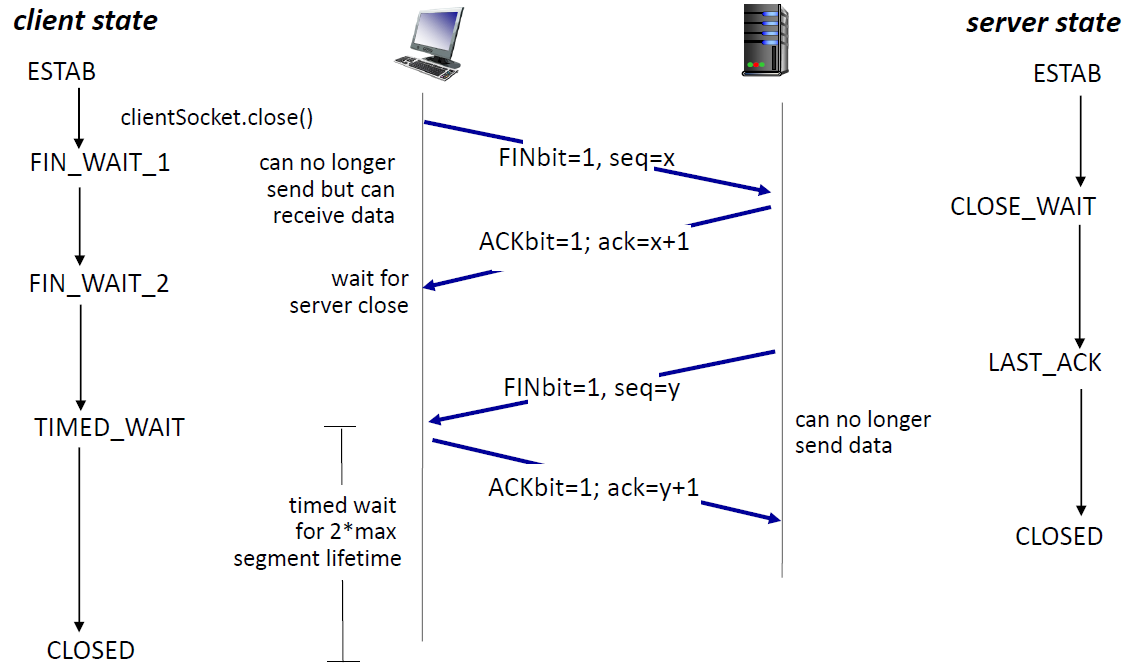
-
FIN(클라이언트가 종료 알림) - ACK - FIN(서버가) - ACK
-
클라이언트는 연결을 완전히 종료하기 전에 도착하지 않은 패킷이 있을까봐 넉넉하게 기다림 (디폴트 3분)
- 연결 시: 3 way handshake
-
Congestion Control(혼잡 제어)- 네트워크가 다루기에 너무 많고 빠른 데이터들
- buffer overflow, long delays 등의 문제가 발생
flow control과는 다름available bandwidth란? 다른 트래픽들 있어도 병목현상 없이 감당할 수 있는 양- 네트워크 컨디션의 변화에 따라 계속 바뀜
congestion window의 크기를 변화시키며 동적으로 찾아야 함- TCP는 network의 정확한 피드백 없이도 end-system에서 발견된 loss, delay를 가지고 판단하는
end-end approach를 채택
- TCP Congestion Control
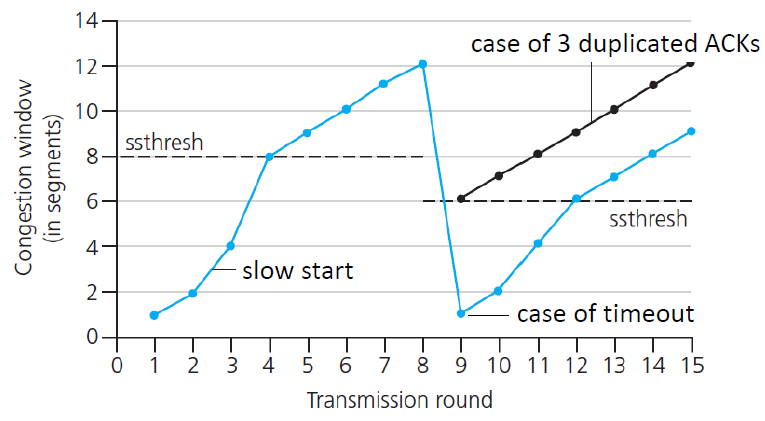
Slow Startmode- 초기
cwnd(congestion window)= 1 - 매 RTT 마다 x2 해서 exponential하게 키움
3 duplicated ACKS로 loss가 발견되면 cwnd를 window 반으로 줄임timeout으로 loss가 발견되면 cwnd를 1로 초기화
- 초기
CA(Congestion Avoidance)modessthresh: loss 직전의 cwnd/2- cwnd가 ssthresh와 같아지면 CA 모드로 바꾸는데, 1씩 linear하게 증가
TCP fairness- bandwidth R에 K개의 TCP 세션이 있다면, 각각 평균적으로 R/K만큼 쓴다
- TCP가 fair한 이유? 증가는 선형적이고 감소는 2로 나누어서
Network Layer
-
Forwarding: router의 input 패킷을 적절한 output으로 옮기는 것, hardware
- 데이터 영역 (Data plane) : 트래픽을 전송하는 목적을 제공하는 영역
-
Routing: 출발지부터 도착지까지 라우팅 알고리즘에 의해 경로를 결정하는 것, software
- 컨트롤 영역 (Control plane) : 데이터 영역으로 어떻게 무슨 트래픽이 흐르도록 제어하는 영역
-
IP: 호스트, router 인터페이스를 위한 32-bit 식별자. subnet + host
-
Interface: 호스트/router 와 물리적 링크 사이의 연결
-
Subnet: 같은 subnet part를 가진 주소들은 router의 개입 없이도 서로 물리적으로 닿을 수 있음 (123.456.789.xxx 의 앞 24비트) -
Subnet mask- 로컬 네트워크: 하나의 라우터를 거치는 여러 호스트들이 연결된 브로드캐스트 영역
- 호스트: 각각의 노드(PC, 스마트폰, 태블릿 등)
- 하나의 로컬 네트워크에서 IP 주소의 subnet부분은 같고 호스트 부분은 달라야 함
- 예시: a. 192.168.0.1/24 , b. 192.168.0.1 서브넷 마스크:255.255.255.0
- a의 /24 와 b의 /255.255.255.0 은 같은 것을 나타내는데, 255.255.255.0 을 2진수로 쓰면 1111 1111.1111 1111.1111 1111.0000 0000이다. 여기서 앞에서부터 연속된 1의 개수만 나타낸 것이 /24
- 서브넷 마스크를 씌우는 것은 논리곱으로, 결국 뒤의 8비트는 0이 되고 앞부분만 남게 된다.
-
DHCP(Dynamic Host Configuration Protocol)- 목적: IP를 필요로 하는 컴퓨터가 네트워크에 참여할 때 IP를 자동으로 할당해서 사용할 수 있도록 해주고, 사용하지 않으면 반환받아 다른 컴퓨터가 사용할 수 있도록 해줌
- 순서
- 호스트가 "DHCP discover" 메시지를 브로캐스트
- DHCP 서버가 "DHCP offer" 메시지로 응답
- 호스트가 IP 주소를 요청: "DHCP request"
- DHCP 서버가 주소를 보냄: "DHCP ack"
-
NAT(Network Address Translation)
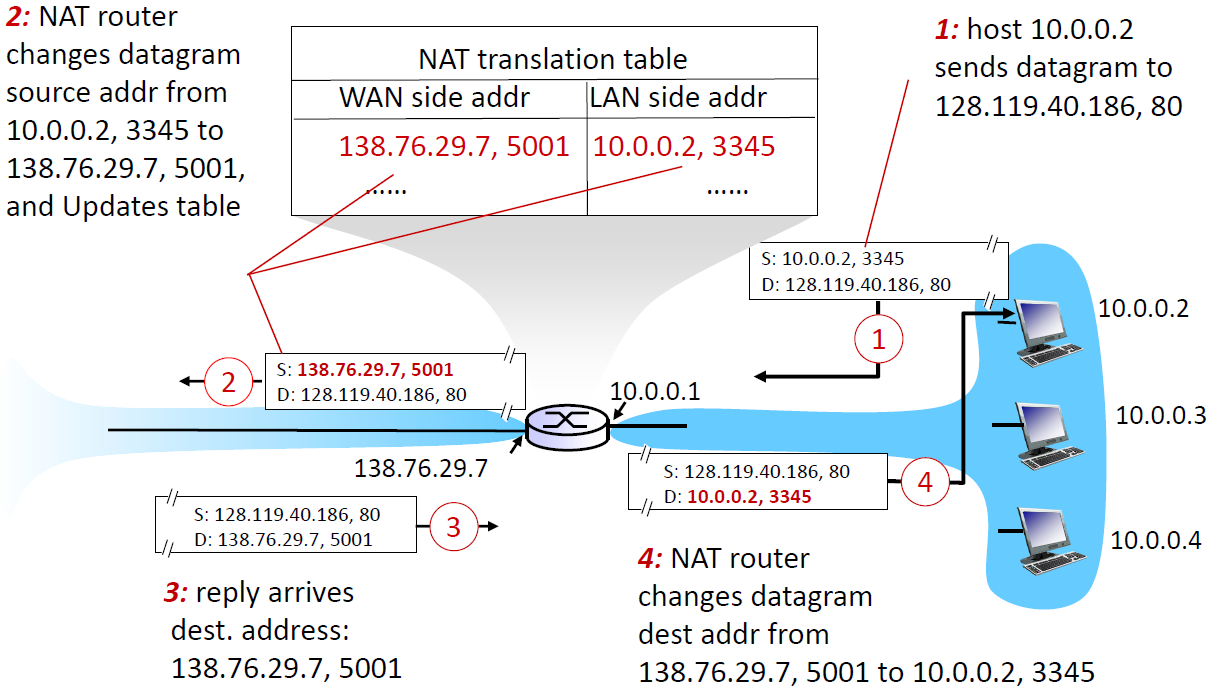
- 한 public IP 주소를 local address로 매핑. 하나의 public IP만 있으면 되며 바깥에 알리지 않고 내부적으로 로컬 네트워크 속 장치들의 주소를 바꿀 수 있음 +security
- Outgoing datagrams: origin IP address를 public IP address로 바꿈
- Incoming datagrams: public IP address를 origin IP address로 바꿈
- 여기서 port 번호는 바꾸지 않기 때문에 NAT table에 기록해두고 port번호로 구분해 매핑할 수 있음
- 예시:
- 요청: 192.168.0.2/65000(사설) ==> 192.168.0.2/65000(사설) > 120.160.10.123/65000(공인) 변환 ==> Internet
- 응답: Internet==> 120.160.10.123/65000(공인) > 192.168.0.2/65000(사설) 변환 ==> 192.168.0.2/65000(사설)
Router Scheduling: 링크에 보낼 다음 패킷 정하기- FIFO: 큐에 도착한 순서대로 보내기
- Priority Queuing: 큐에 우선순위를 지정해 패킷을 분류해 넣은 뒤 높은 것부터 보내기
- Round Robin Queuing: 여러 큐에 패킷을 분류해 넣고 돌아가면서 보내기
- Weighted Fair Queuing: 종류에 따라 weight을 다르게 두기
- AQM(Active Queue Management): 큐가 꽉 차기 전 버릴 패킷 정하기
- Random Early Detection
- Explicit Congestion Notification
- Controlled delay
- Routing algorithm
- global, link state 알고리즘 : 모든 라우터가 모든 링크의 cost 정보를 가지고 있다고 가정
- Dijkstra 알고리즘
- decentralized, distance vector 알고리즘: 라우터는 물리적으로 연결되어있는 이웃의 정보만 알고 있음
- Belman-ford 알고리즘
- global, link state 알고리즘 : 모든 라우터가 모든 링크의 cost 정보를 가지고 있다고 가정
Autonomous Systems(AS)- router들을 집약 (domains)
- Interconnected ASes의 Forwarding table이 intra-AS와 inter-AS 다 가지고 있음
intra-AS: 같은 AS 안의 라우터들끼리 같은 라우팅 프로토콜- Gateway router(border router): AS의 edge에 다른 AS들의 라우터를 가지고 있음
OSPF(Open Shortest Path First): 다익스트라 알고리즘 사용, link에 변화가 있거나 주기적으로 AS안의 라우터들에게 알림- admin이 하나이므로 따로 결정할 정책은 없음
inter-AS: AS간의 라우팅, gateway가 inter-AS 라우팅 수행BGP(Border Gateway Protocol)
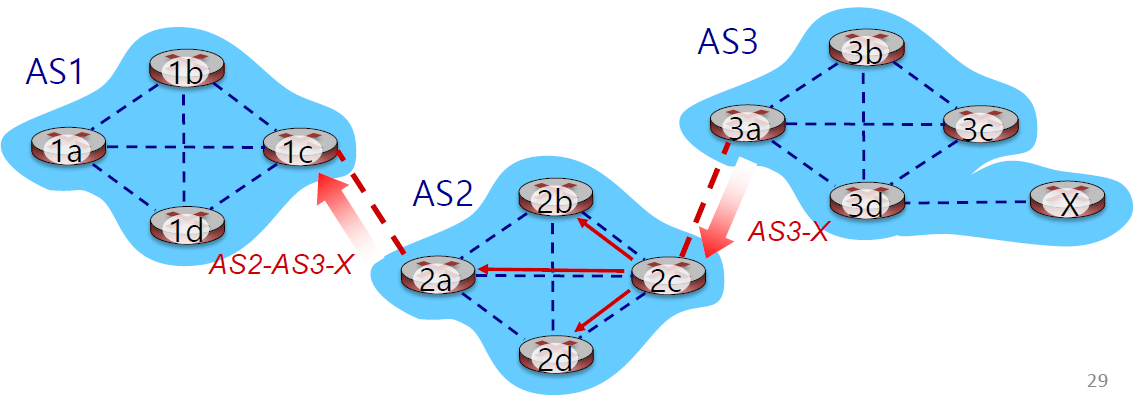
- AS간의 연결을 할 gateway router가 이웃 AS 정보를 얻고, 다른 router에게 홍보
- 나를 통해 라우팅하기를 원치 않으면 굳이 홍보하지 않음
- admin이 트래픽 경로를 설정하고, 자신을 통해 라우팅하는 노드를 관리하고 싶어함
Link Layer
- 한 노드의 datagram을 물리적으로 인접한 노드에게 링크(통신 채널)을 통해 전달하는 책임
- datagram을 frame으로 캡슐화하고 헤더와 테일 붙이기
- 프레임 헤더에서 출발지와 도착지를 식별하기 위해 MAC address 사용
- 신호 불량에 의한 에러 감지 및 correcting
NIC(Network Interface Controller)s communicating- 컴퓨터를 네트워크에 연결하여 통신하기 위해 사용하는 하드웨어 장치(랜 카드)
- Sending side: datagram을 frame으로 캡슐화, 에러 체크 비트 추가 등
- Receiving side: datagram 추출, 에러 찾기, 상위 레이어에 패스
-EDC(Error Detection and Correction bits)
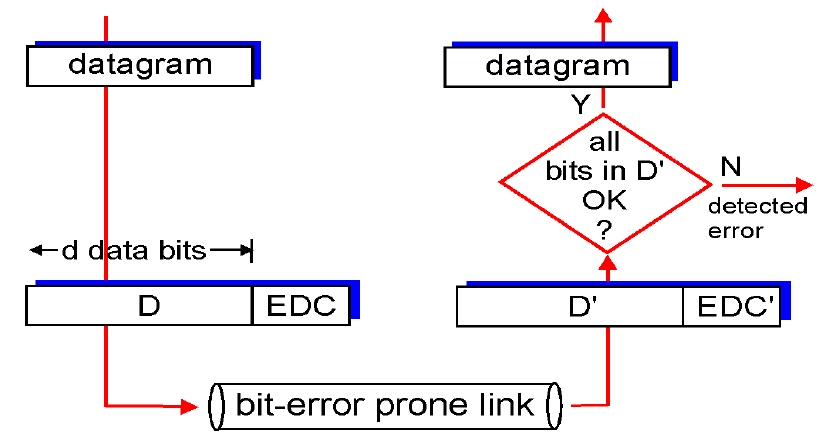
-
CRC(Cyclic Redundancy Check)- 전송된 데이터에 오류가 있는지 검사하는 체크썸
- CRC 값을 데이터에 붙여 전송하고, 데이터 전송이 끝난 후 받은 데이터의 값으로 다시 CRC 값을 계산. 이 두 값이 다르면 데이터 전송 과정에서 잡음 등에 의해 오류가 덧붙여 전송된 것
-
ARP(Address Resolution Protocol)- 물리적인 주소인 MAC 주소와 논리적인 주소인 IP 주소를 대응 시키는 역할
- 제 3계층으로부터 받은 패킷을 프레임으로 만들어 케이블로 흘려보내야 하는데 이때 출발지 MAC 주소는 자기 자신의 NIC에 쓰여 있는 MAC 주소라서 알 수 있지만 목적지 MAC 주소는 알 수가 없다. 이때 ARP를 이용하여 IP 주소로부터 MAC 주소를 구할 수 있다.
- 동일 네트워크 상에서는 수집된 ARP 테이블을 참고하여 프레임을 만든다. 다른 네트워크 간 통신은 기본 게이트웨이의 MAC 주소를 ARP에서 조회하여 목적지 MAC 주소로 등록한다.
- IP 주소는 목적지까지 바뀌지 않지만 MAC 주소는 NIC을 경유할 때 마다 바뀐다.
-
이더넷(Ethernet)

-
OSI 제 1계층과 제 2 계층의 기술 규격이다. 유선 네트워크의 경우 거의 대부분이 이더넷을 사용한다.
이더넷은 네트워크 계층으로부터 받은 데이터(패킷)에 프레임의 처음을 나타내는 프리앰블(preamble)과 목적지(수신자)와 출발지(송신자)를 나타내는 헤더, 비트 오류체크에 사용하는 FCS(Frame Check Sequence)를 추가하여 프레임을 생성한다. 이더넷은 MAC 주소라는 48비트로 된 식별자를 사용하여 컴퓨터를 식별한다.
-
MAC address- 데이터링크 계층(제 2계층)에서 통신을 위해 사용되는 48비트로 된 전세계에서 유일한 식별자
- 상위 24비트는 IEEE가 기기의 제조업체 별로 할당한 제조업체 코드, 하위 24비트는 제조업체가 기기 별로 고유한 값을 할당한 코드
-
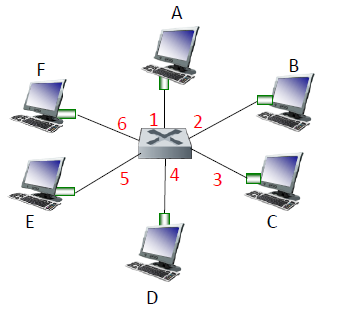
Switch
- 네트워크 스위치가 데이터 패킷 내 포함된 주소 정보에 따라 해당 입력 패킷을 해당 출력 포트에 빠르게 접속 시키는 기능. LAN 케이블을 통해 컴퓨터를 연결하며 프레임이 들어온 LAN 포트 번호와 그 프레임의 출발지 MAC 주소를 테이블(=MAC address table=switch table)로 만들어 일정 기간 동안 기억한다.
