use hr;
단일행 함수
– 변환함수, 제어 흐름 함수, 시스템 정보 함수
변환 함수
| 함수 | |
|---|---|
| DATE_FORMAT(날짜, 형식) | 날짜를 형식에 맞게 출력하는 함수 |
| format | 설명 |
|---|---|
| %Y | 년도를 4자리 숫자로 표현 |
| %y | 년도를 2자리 숫자로 표현 |
| %M | 월을 영문 풀네임으로 표현 |
| %b | 월을 영문 약자로 표현 |
| %m | 월을 2자리 숫자로 표현 |
| %c | 월을 2자리 숫자로 표현하되 10보다 작을 경우 한자리로 표현 |
| %d | 일을 2자리 숫자로 표현 |
| %e | 일을 2자리 숫자로 표현하되 10보다 작을 경우 한자리로 표현 |
| %W | 요일을 영문 풀네임으로 표현 |
| %a | 요일을 영문 약자로 표현 |
| %H | 시간을 24시간으로 표현 |
| %h | 시간을 12시간으로 표현 |
| %k | 시간을 24시간으로 표현하되 10보다 작을 경우 한자리로 표현 |
| %l | (소문자 엘) 시간을 12시간으로 표현하되 10보다 작을 경우 한자리로 표현 |
| %i | 분을 2자리 숫자로 표현 |
| %s | 초를 2자리 숫자로 표현 |
select date_format(now(),'%Y-%M-%d') as "Now";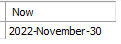
select date_format(now(), '%Y/%M/%d %H:%i:%s') as "Now";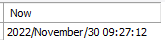
select employee_id, date_format(hire_date, '%Y-%M-%d %W') as "입사일" from employees;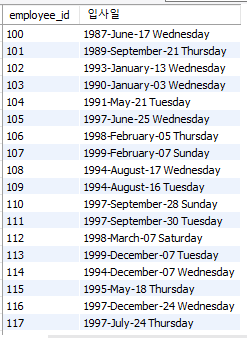
| 함수 | |
|---|---|
| CAST(값 AS 데이터타입) | 값을 지정된 데이터타입으로 변환하는 함수 |
| 데이터타입 | 데이터타입 |
|---|---|
| BINARY | CHAR (문자형) |
| SIGNED (부호 있는 정수형) | UNSIGNED (부호 없는 정수형) |
| DECINAL (숫자형) | DOUBLE (숫자형) |
| FLOAT (숫자형) | DATETIME (날짜형) |
| DATE (날짜형) | TIME (시간) |
select cast("123" as signed), cast("-123.45" as signed);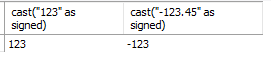
select cast("123" as unsigned), cast("123.45" as unsigned);
select cast('2022/03/18' as date) as '날짜';
select cast('2022@03@18' as date) as '날짜';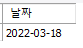
select cast('2022-01-02 21:24:33.123' as date) as "DATE",
cast('2022-01-02 21:24:33.123' as time) as "TIME",
cast('2022-01-02 21:24:33.123' as datetime) as "DATETIME";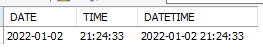
제어 흐름 함수
| 함수 | |
|---|---|
| IF(논리식, 참일 때 값, 거짓일 때 값) | 논리식이 참이면 참일 때 값을 출력하고 거짓이면 거짓일 때 값을 출력하는 함수 |
select if(100>200, '참이다', '거짓이다') as "결과";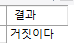
select employee_id, salary, if(salary>10000, '1등급', '2등급') as "급여 등급"
from employees;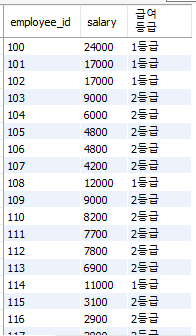
| 함수 | |
|---|---|
| IFNULL(수식1, 수식2) | 수식1이 NULL이 아니면 수식1이 반환되고, 수식1이 NULL이면 수식2가 반환되는 함수 |
null값을 실제값으로 변환해주는 함수
select ifnull(null, '널이군요') as "결과1", ifnull(100, '널이군요') as "결과2";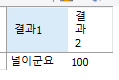
select employee_id, last_name, salary, commission_pct, ifnull(commission_pct, 0)
from employees;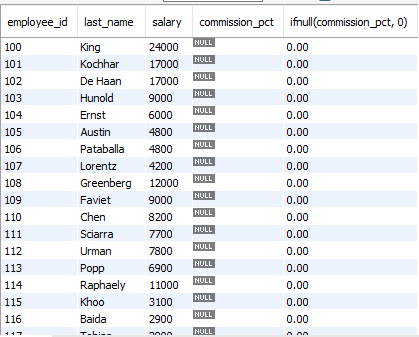
| 함수 | |
|---|---|
| NULLIF(수식1, 수식2) | 수식1과 수식2가 같으면 NULL을 반환하고, 다르면 수식1을 반환하는 함수 |
select nullif(100,100) as "결과1", nullif(100,200) as"결과2";
select employee_id, first_name, last_name, nullif(length(first_name), length(last_name)) as "결과"
from employees;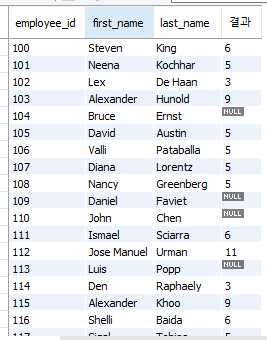
| 함수 | |
|---|---|
| CASE 비교값 WHEN 값1 THEN 결과1 WHEN 값2 THEN 결과2 ... ... ELSE 기본값 END | SQL구문에서 if-then-else의 논리를 적용할 수 있는 연산자 함수는 아니나 제어 흐름 함수와 함께 정리해두기 |
select case 10 when 1 then '일'
when 5 then '오'
when 10 then '십'
else '모름'
end as "case예제";
select employee_id, last_name, department_id,
case department_id when 10 then '부서 10'
when 50 then '부서 50'
when 100 then '부서 100'
when 150 then '부서 150'
when 200 then '부서 200'
else '기타 부서'
end as "부서정보"
from employees;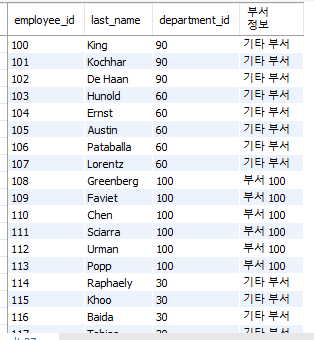
시스템 정보 함수
| 함수 | |
|---|---|
| USER( ) CURRENT_USER( ) SESSION_USER( ) | 현재 사용자 정보를 반환하는 함수 |
| DATABASE( ) SCHEMA( ) | 현재 데이터베이스 또는 스키마 정보를 반환하는 함수 |
| VERSION( ) | 현재 MySQL 버전을 반환하는 함수 |
select user(), current_user(), session_user();
select database(), schema();
select version();
연습문제

select last_name, ifnull(commission_pct, 'No Commision') COMM
from employees;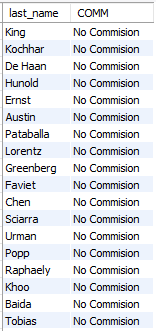
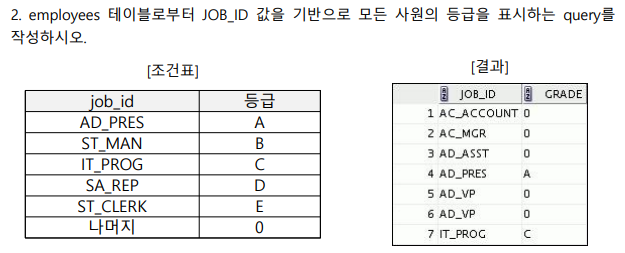
employee_id, last_name, job_id, grade 출력하기
select employee_id, last_name, job_id,
case job_id when 'ad_pres' then 'A'
when 'st_man' then 'B'
when 'it_prog' then 'C'
when 'sa_rep' then 'D'
when 'st_clerk' then 'E'
else '0'
end as "grade"
from employees;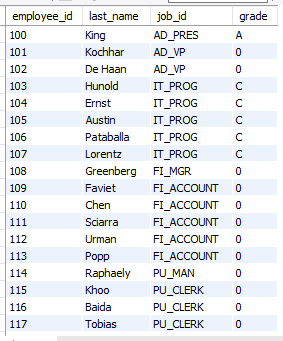
그룹함수와 그룹화
그룹함수
- 행 그룹을 조작해서 하나의 결과값을 반환하는 함수
- 그룹함수 종류 : min, max, sum, avg, count
- 그룹함수 특징 : null값은 제외하고 작업함.
| 함수 | |
|---|---|
| MIN(행그룹) | 행그룹에서 최소값을 구해주는 함수 모든 데이터타입에 사용 가능함. |
| MAX(행그룹) | 행그룹에서 최대값을 구해주는 함수 모든 데이터타입에 사용 가능함. |
select min(salary) as "최소 급여", max(salary) as "최대 급여"
from employees;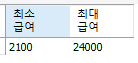
select min(hire_date) as "가장 오래된 입사일",
max(hire_date) as "가장 최근 입사일"
from employees;
select min(last_name) as "name1", max(last_name) as "name2"
from employees;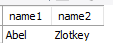
| 함수 | |
|---|---|
| SUM(행그룹) | 행그룹의 합계를 구해주는 함수 |
| AVG(행그룹) | 행그룹의 평균을 구해주는 함수 |
select sum(salary) as "급여 합계", avg(salary) as "평균 급여"
from employees;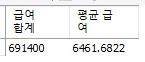
select sum(salary) as "급여 합계", avg(salary) as "평균 급여"
from employees
where job_id like '%REP%';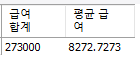
예제 employees 테이블에서 전체 직원의 커미션 평균을 출력하시오.
-- [오답] 커미션을 받는 사원들의 커미션 평균
select avg(commission_pct) as "comm-avg"
from employees;
-- [정답] 전체 사원들의 커미션 평균
select avg(ifnull(commission_pct,0)) as "comm-avg"
from employees;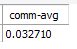
| 함수 | |
|---|---|
| COUNT(*) | 행그룹에서 행의 개수를 반환해주는 함수 (null값 포함, 중복값 포함) |
| COUNT(행그룹) | 행그룹에서 행의 개수를 반환해주는 함수 (null값 제외, 중복값 포함) |
| COUNT(DISTINCT 행그룹) | 행그룹에서 행의 개수를 반환해주는 함수 (null값 제외, 중복값 제외) |
- count(*)
모든 컬럼의 조합값을 기준으로 count함.
null 값 O. 중복값 포함 O. - count(행그룹)
특정 컬럼 기준으로 count함.
null값 포함 X - count(distinct 행그룹)
중복값을 제외하고 특정 컬럼을 기준으로 count함.
null값 포함 X, 중복값 포함 X
select count(*)
from employees; -- 전직원 수 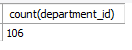
select count(commission_pct)
from employees; -- 커미션을 받는 직원의 수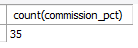
select count(*)
from employees
where department_id <=80;
-- 80번 이하 부서에 소속된 직원의 수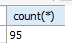
select count(commission_pct)
from employees
where department_id <=80;
-- 80번 이하 부서에 소속된 직원 중 커미션을 받는 직원의 수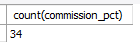
select count(department_id)
from employees;
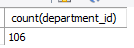
select count(distinct department_id)
from employees;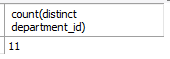
그룹화 : group by절, having절
group by절
테이블 안에서 또다시 작은 그룹화를 나눠서 그룹함수를 적용함.
[문법] select 컬럼1, 컬럼2, 컬럼 3
from 테이블명
[where 조건문][group by 컬럼명]
[order by 컬럼명 [asc | desc]];
select sum(salary)
from employees; -- 전 직원의 급여 합계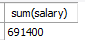
select department_id, sum(salary)
from employees
group by department_id; -- 부서별 급여합계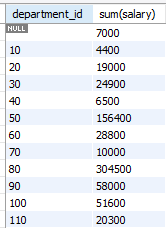
- group by절 사용 시 주의사항
select 절의 컬럼 리스트 중 그룹함수에 포함된 컬럼과 그룹함수에 포함되지 않은 컬럼이 함께 출력되려면 적어도 그룹함수에 포함되지 않은 컬럼은 빠짐없이 group by절에 포함되어야 문법 오류가 발생되지 않음!!!
group by절에 있는 컬럼이 꼭 select 절에 포함되어야 하는 건 아니다!!!
select department_id, job_id, sum(salary)
from employees
group by department_id, job_id
order by department_id; -- 부서 내 업무별 급여 합계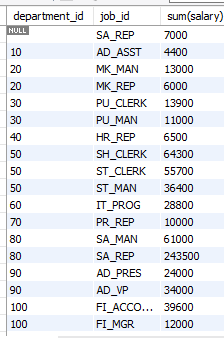
select department_id, job_id, sum(salary)
from employees
where department_id > 40
group by department_id, job_id
order by department_id;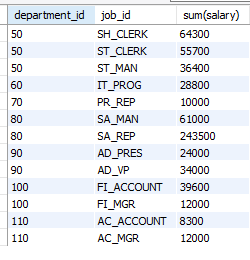
오류의 원인 파악 및 수정하기
-- [오류]
select department_id, count(last_name)
from employees;
-- [수정]
select department_id, count(last_name)
from employees
group by department_id;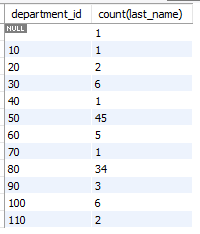
-- [오류]
select department_id, job_id, count(last_name)
from employees
group by department_id;
-- [수정]
select department_id, job_id, count(last_name)
from employees
group by department_id, job_id
order by department_id;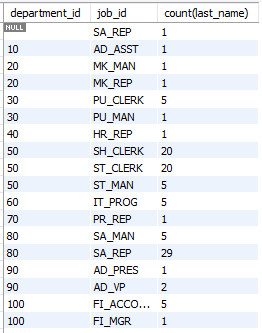
* null 값 제외 조회 : where department_id is not null 추가.
예제
매니저별 부하직원의 수를 출력하시오.
select manager_id, count(last_name)
from employees
where manager_id is not null
group by manager_id;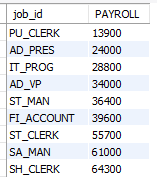
having절 (조건절)
- where절
행을 제한하는 조건문을 작성하는 곳 - having절
행그룹을 제한하는 조건문을 작성하는 곳
그룹 함수가 포함된 조건을 작성하는 곳[문법] select 컬럼1, 그룹함수(컬럼2)
from 테이블명
[where 조건문][group by 컬럼1]
[having 그룹함수가 포함된 조건문]order by 컬럼명 [asc | desc]];
select job_id, sum(salary) PAYROLL
from employees
where job_id not like '%rep%'
group by job_id
having sum(salary) > 13000
order by sum(salary);연습문제

select round(avg(ifnull(commission_pct,0)),2) 'avg_comm'
from employees;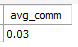
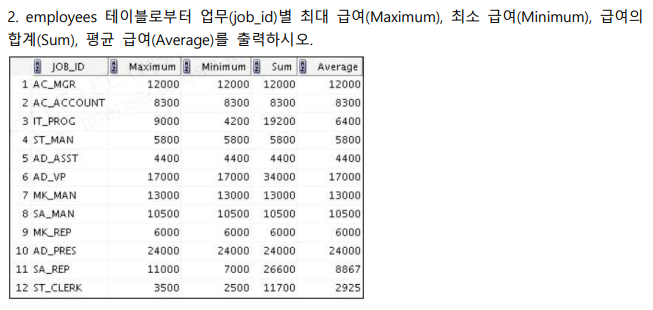
select JOB_ID, max(salary) Maximum, min(salary) Minimum, sum(salary) Sum, floor(avg(salary)) Average
from employees
group by job_id;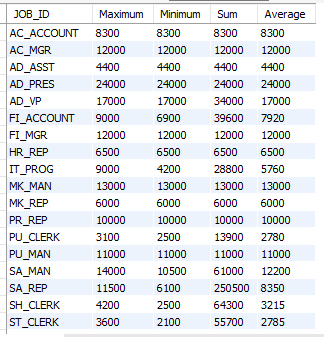

select JOB_ID, count(*)
from employees
group by job_id;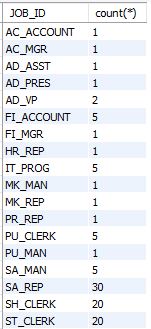

select MANAGER_ID, min(salary)
from employees
where manager_id is not null
group by manager_id
having min(salary)>=6000
order by min(salary) desc;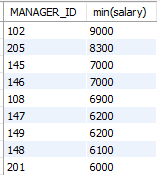

select max(salary)-min(salary) as DIFFERENCE
from employees;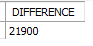

select count(*) TOTAL,
count(if(year(hire_date)=1995, 1, null)) "1995",
count(if(year(hire_date)=1996, 1, null)) "1996",
count(if(year(hire_date)=1997, 1, null)) "1997",
count(if(year(hire_date)=1998, 1, null)) "1998"
from employees
-- (==)
select count(*) TOTAL,
sum(if(year(hire_date)=1995, 1, null)) "1995",
sum(if(year(hire_date)=1996, 1, null)) "1996",
sum(if(year(hire_date)=1997, 1, null)) "1997",
sum(if(year(hire_date)=1998, 1, null)) "1998"
from employees;서브쿼리
- 서브쿼리란?
쿼리구문 안에 또다시 쿼리구문이 들어가 있는 형태
group by절을 제외한 쿼리구문 전체에 사용 가능함.
[where절에 서브쿼리 사용 문법]
select 컬럼1, 컬럼2, 컬럼3
from 테이블명
where 컬럼명 = (select 컬럼명
from 테이블명
where 조건문)
- 서브쿼리 유형 : 단일행 서브쿼리, 다중행 서브쿼리
(예제) employees 테이블에서 Abel보다 급여를 더 많이 받는 사원들의 employee_id, last_name, salary를 출력하시오.
select employee_id, last_name, salary
from employees
where salary > (Abel의 급여);
-- abel의 급여
select salary
from employees
where last_name = 'abel';
select employee_id, last_name, salary
from employees
where salary >
(select salary
from employees
where last_name = 'abel');
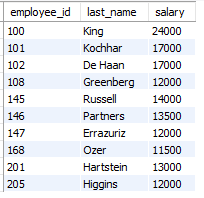
** Davies란 직원보다 나중에 입사한 사원을 출력하는 구문을 작성하시오
select last_name, hire_date
from employees
where hire_date > (select hire_date
from employees
where last_name = 'davies');단일행 서브쿼리
서브쿼리로부터 오직 하나의 행이 반환되는 유형
메인쿼리에 단일행 비교연산자 사용하면 됨
- 단일행 비교연산자 : =, >, >=, <, <=, <>
-- 141번 사원과 동일한 업무 담당자를 출력하시오.
select employee_id, last_name, job_id
from employees
where job_id =
(select job_id
from employees
where employee_id = 141);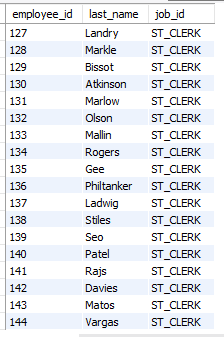
-- 141번 사원과 동일한 업무 담당자를 출력하되 결과에 141번 사원을 제외하시오.
select employee_id, last_name, job_id
from employees
where job_id =
(select job_id
from employees
where employee_id = 141) and employee_id <> 141;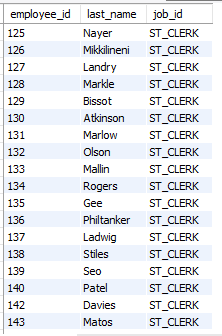
employees 테이블의 전체 직원 중 급여를 가장 작게 받는 사원의 employee_id, last_name, salary, job_id, department_id를 출력하시오.
select employee_id, last_name, salary, job_id, department_id
from employees
where salary =
(select min(salary)
from employees);
-- [오류]
select employee_id, last_name, min(salary)
from employees
group by employee_id, last_name;

- 서브쿼리 2개 사용
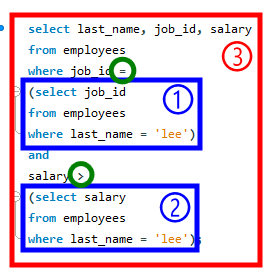
- having절에 서브쿼리
select department_id, min(salary)
from employees
where department_id is not null
group by department_id
having min(salary) >
(select min(salary)
from employees
where department_id = 30);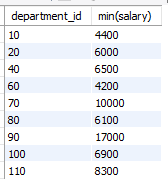
- 오류 원인 찾기
select employee_id, last_name
from employees
where salary =
(select min(salary) -- 부서별 최소 급여
from employees
group by department_id);서브쿼리가 부서별 최소 급여값이므로 결과가 여러개임..
메인쿼리에 단일행 비교연산자(=)를 사용하였으므로 서브쿼리로부터 한 행이 반환되어야 하나 여러 행이 반환되어 오류가 발생됨.
-- [수정]
select employee_id, last_name
from employees
where salary in
(select min(salary) -- 부서별 최소 급여
from employees
group by department_id);- 결과가 나오지 않는 원인 찾기
select last_name, job_id
from employees
where job_id =
(select job_id
from employees
where last_name = 'haas');haas라는 직원이 없음
단일행 서브쿼리인 경우 결과가 null이면 메인쿼리 결과도 null값이 반환됨.
다중행 서브쿼리
서브쿼리로부터 메인쿼리로 여러행이 반환되는 유형
다중행 서브쿼리인 경우 메인쿼리에 다중행 비교연산자 사용해야함.
- 다중행 비교연산자 : in, not in, any, all
in(=, or) <--> not in(<>, and)
| 연산자 | ||
|---|---|---|
| =any | (=, or) | in(=, or) |
| >any | (>, or) | 최소값보다 큰지를 비교하는 연산자 |
| >=any | (>=, or) | 최소값보다 크거나 같은지 비교하는 연산자 |
| <any | (<, or) | 최대값보다 작은지를 비교하는 연산자 |
| <=any | (<=, or) | 최대값보다 작거나 같은지 비교하는 연산자 |
| <>any | (<>, or) | 보통 사용 되지 않음! 모두 true |
| =all | (= , and) | 보통 사용 되지 않음! 무조건 false. 단일행이 들어오는 경우는 만족 |
| >all | (> , and) | 최대값보다 큰지를 비교하는 연산자 |
| >=all | (>= , and) | 최대값보다 큰거나 같은지를 비교하는 연산자 |
| <all | (< , and) | 최소값보다 작은지를 비교하는 연산자 |
| <=all | (<= , and) | 최소값보다 작거나 같은지를 비교하는 연산자 |
| <>all | (<> , and) | not in(<>, and) |
- in 예제
select employee_id, last_name, manager_id, department_id
from employees
where manager_id in
(select manager_id
from employees
where employee_id in (174,141))
and department_id in
(select department_id
from employees
where employee_id in (174,141))
and employee_id not in (174,141);- any 예제
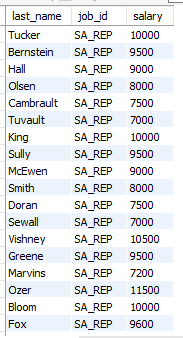
select employee_id, last_name, job_id, salary
from employees
where salary < any
(select salary
from employees
where job_id = 'it_prog')
and job_id <> 'it_prog';서브쿼리의 최대값보다 작은지 비교함.
