Object(객체) 종류
- Table
- 사용방법 : select, insert, update, delete
- 정의방법 : create table, alter table, drop table, truncate table
- View
- Sequence
- Index
- Synonym
View
하나 이상의 Base table을 기반으로 생성은 되었으나 물리적으로 존재하지 않고 Data Dictionary에 Select 구문 형태로 정의만 되어 있는 가상의 논리적인 테이블
- 사용방법 : select, insert, update, delete
- 정의방법 : create view, alter view(mysql o, oracle x), create or replace view(있으면 교체해달라), drop view

- noforce : base table이 존재할 때만 뷰가 생성됨
- force : base table 없어도 뷰가 생성
뷰 생성 및 수정
create view empvu80
as
select employee_id, last_name, salary
from employees
where department_id = 80;
desc empvu80;
select * from empvu80;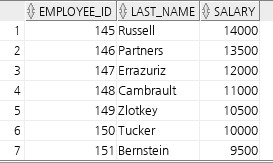
create view salvu50
as
select employee_id ID_NUMBER, last_name NAME, salary*12 ANN_SALARY
from employees
where department_id = 50;
desc salvu50;
select * from salvu50;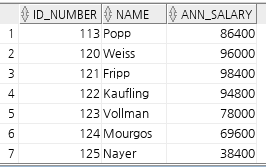
- 뷰 수정
create or replace view empvu80
(id_number, name, sal, department_id)
as
select employee_id, first_name || ' ' || last_name, salary, department_id
from employees
where department_id = 80;
desc empvu80;
select * from empvu80;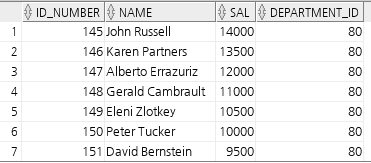
create or replace view dept_sum_vu
(name, minsal, maxsal, avgsal)
as
select d.department_name, min(e.salary), max(e.salary), avg(e.salary)
from employees e join departments d
on e.department_id = d.department_id
group by d.department_name;
desc dept_sum_vu;
select * from dept_sum_vu;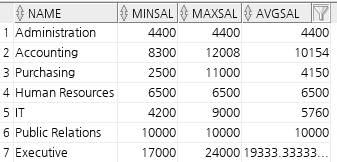
뷰 사용 – 테이블과 동일함
- SQL> desc dept_sum_vu
- SQL> select * from dept_sum_vu;
- 뷰를 통한 insert, update, delete 가능 => 결국 Base table의 data가 조작되어짐.
뷰 삭제
drop view 테이블명;
- 데이터 사전 조회하기
select view_name, text from user_views;
Sequence
자동으로 고유한 번호를 반환해 주는 번호생성기와 같은 Object (mysql에는 없음)
- 사용방법 : 시퀀스명.nextval, 시퀀스명.currval
- 정의방법 : create sequence
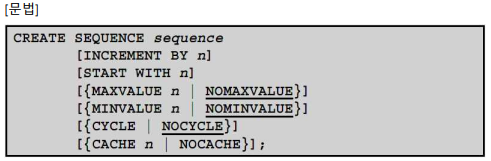
- increment by n : 시퀀스 번호의 간격(default = 1)
- start with n : 시퀀스 번호의 시작값 (default = 1)
- maxvalue n : 시퀀스 번호의 최대값 (default = 10^27)
- minvalue n : 시퀀스 번호의 최소값 (default = -10^26)
- cycle : 순환여부
- cache n : 시퀀스값 저장여부
select max(department_id)
from departments;- 시퀀스 생성
create sequence dept_id_seq
start with 350
increment by 10
maxvalue 1000;- 시퀀스 사용
- 시퀀스명.NEXTVAL : 사용가능한 다음 시퀀스값 반환
- 시퀀스명.CURRVAL : 현재 시퀀스값, 즉 마지막 시퀀스값 반환
insert into departments
values (dept_id_seq.nextval, 'AAA', 105, 1700);select * from departments
order by department_id desc;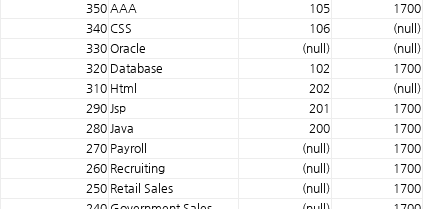
insert into departments
values (dept_id_seq.nextval, 'BBB', null, null);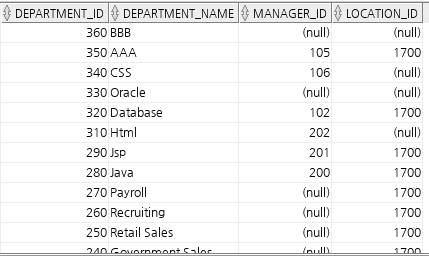
시퀀스 수정(alter sequence)
- 시퀀스 간격, 최대값, 최소값, Cycle 옵션, Cache 옵션 변경 가능
- 시퀀스 시작값 변경 불가(start with N)
시퀀스 삭제(drop sequence)
drop sequence 시퀀스명;
휴지통에는 테이블만 들어감, 뷰X 시퀀스X
연습문제 1
1번
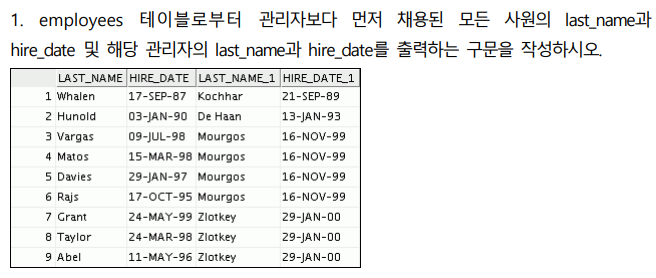
select e.last_name, e.hire_date, m.last_name, m.hire_date
from employees e join employees m
on e.manager_id = m.employee_id
where e.hire_date< m.hire_date;2번

select employee_id, last_name
from employees
where department_id in
(select department_id
from employees
where lower(last_name) like '%u%');3번

select employee_id, last_name, salary, department_id
from employees
where department_id in
(select department_id
from employees
where last_name like '%u%') and
salary>
(select avg(salary) from employees);연습문제2
1번

select department_id, min(salary)
from employees
having avg(salary) =
(select max(avg(salary))
from employees
group by department_id)
group by department_id;2번

a)
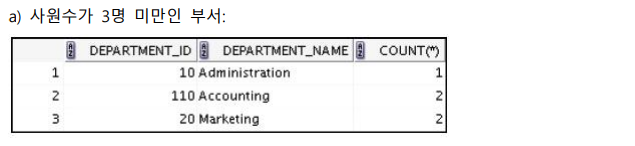
select d.department_id, d.department_name, count(employee_id)
from departments d left join employees e
on d.department_id = e.department_id
group by d.department_id, d.department_name
having count(employee_id)<3;b)

select d.department_id, d.department_name, count(employee_id)
from departments d left join employees e
on d.department_id = e.department_id
group by d.department_id, d.department_name
having count(employee_id) =
(select max(count(employee_id))
from departments d left join employees e
on d.department_id = e.department_id
group by d.department_id);c)

select d.department_id, d.department_name, count(employee_id)
from departments d left join employees e
on d.department_id = e.department_id
group by d.department_id, d.department_name
having count(employee_id) =
(select min(count(employee_id))
from departments d left join employees e
on d.department_id = e.department_id
group by d.department_id);