장애 조치 아키텍처 구성
장애 조치란 장애 극복 기능으로 시스템의 일부 서버에 장애가 발생했을 때 전체 시스템이 죽는 것이 아니라 예비 시스템이 즉시 요청을 대신 처리해서 다운타임을 최소화하고 문제 없이 서비스가 돌아가게 하는 것이다. 따라서 운영 서버라면 꼭 서버를 2대 이상 띄워서 장애 조치가 가능하도록 처리해야한다.
Auto Scaling 그룹을 이용한 장애 조치
Auto Scaling 그룹과 로드 밸런서를 이용하면 장애 조치를 구현할 수 있다. 로드 밸런서에서는 서버 인스턴스들의 사태를 계속 파악하고 있으며 장애가 발생한다면 해당 인스턴스가 정상 상태로 돌아올 때까지 클라이언트의 요청을 전달하지 않는 기능이 포함되어 있다.
이러한 로드 밸런서의 기능 덕분에 클라이언트에서는 잠시 에러 응답을 받겠지만 바로 정상적인 응답만 받을 수 있게 된다.
Auto Scaling 그룹과 로드 밸런서를 통한 장애 조치
장애를 직접 재현 한 뒤 해당 기능이 정상적으로 동작하는지 확인해보자
실습을 하기 전에 기존에 설정을 많이 변경하였다.
서버에 nginx를 띄워서 ec2 인스턴스 주소에 접속하면

이와 같은 화면이 뜨도록 설정하고 해당 ec2 인스턴스로 이미지를 생성하여 이 이미지로 시작 템플릿, 오토 스케일링, 로드 밸런서를 구성하였다.
EC2 서비스의 로드밸런싱 -> 대상 그룹을 클릭한 뒤 앞서 생성한 대상 그룹을 선택하고 상태 검사 탭을 클릭한다.
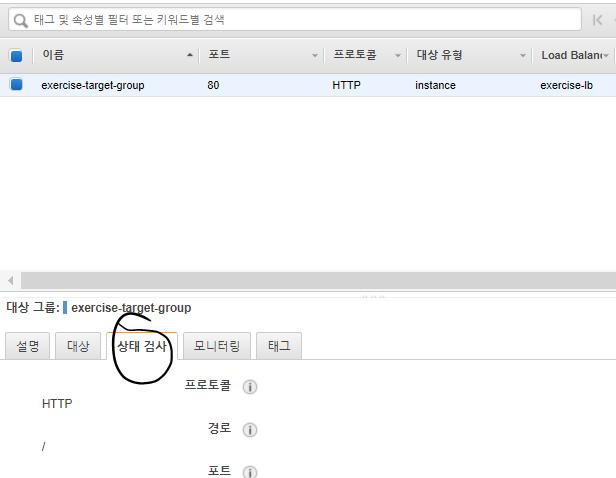
상태 검사 항목에 대한 설명
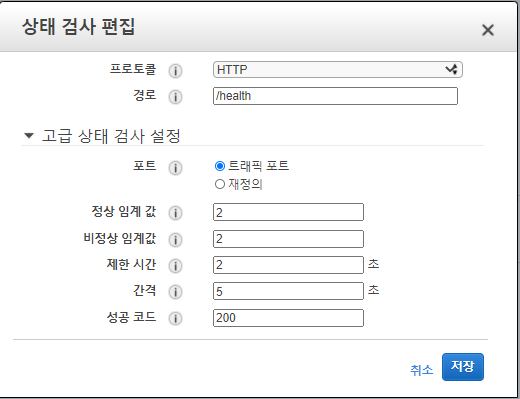
경로 : 인스턴스가 정상인지 확인하기 위해 호출한 URL 주소이다.
정상 임계값 : 연속으로 몇 번 정상 응답을 해야만 정상 상태로 볼 것인지 지정하는 항목이다.
비정상 임계값 : 연속으로 몇 번 비정상 응답을 해야만 정상 상태로 볼 것인지 지정하는 항목이다.
제한 시간 : 타임아웃 시간으로 응답이 몇 초 이내로 오지 않을 경우 비정상 응답으로 판단할지 지정하는 항목이다.
간격 : 몇 초 간격으로 인스턴스의 상태를 물어볼지 지정하는 항목이다.
성공 코드 : 어떤 HTTP 응답 코드를 줬을 경우 정상 상태로 판단할 것인지 지정하는 항목이다.상태 검사를 다음과 같이 편집한다.
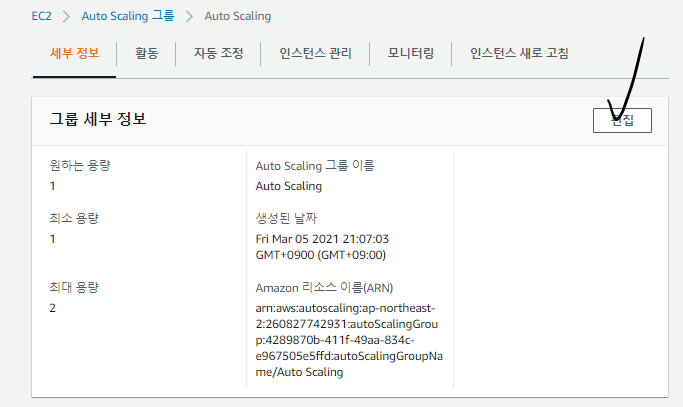
AUTO SCALING -> Auto Scaling 그룹 메뉴에서 만든 그룹을 선택한 뒤 세브 정보에서 그룹 세부 정보 편집을 누른다.
원하는 용량, 최소 용량 모두 2로 바꾼다.
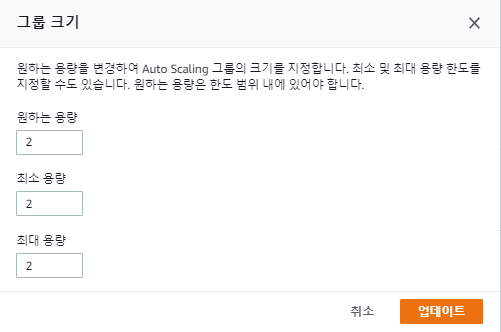
이러면 인스턴스 1개가 추가로 생성되서 2개가 될 것이다. 인스턴스 상태가 Running될 때까지 잠시 기다린다.

이제 로드밸런서의 DNS 주소로 이동하면 새로고침할 때마다 2개의 서버를 오가면서 내용을 표시할 것이다.
이를 증명하기 위해서
접속한 2개의 서버 중 하나의 서버에서
$ sudo service nginx stop을 입력하고 로드밸런서 DNS 페이지로 이동해서 새로고침을 누르면
502 error 와 기존 구성한 화면이 번갈아서 나타나는 것을 볼 수 있다.
구성도
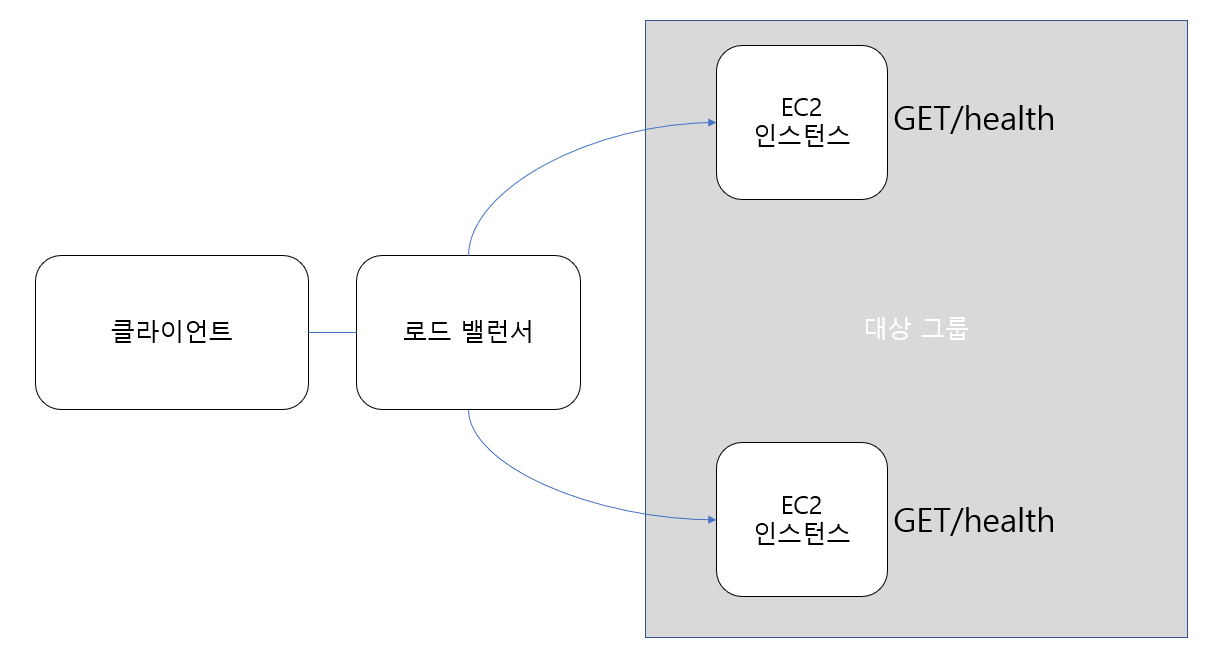
만든 구성도는 간단하게 이와 같다고 볼 수 있다.
