데이터 수집
크롤링을 연습하기 위해 직접 데이터를 수집하였다.
무신사스토어 홈페이지 실시간 랭킹 - 바지 항목에서 1위부터 900위까지 제품들의 브랜드명, 제품명, 가격을 TEXT파일에 저장하였다.
코드
import requests
from bs4 import BeautifulSoup
with open("C:/Users/musinsa.text","w",encoding="utf8") as f:
for i in range(1,11):
url="https://www.musinsa.com/ranking/best?period=now&age=ALL&mainCategory=003&subCategory=&leafCategory=&price=&golf=false&kids=false&newProduct=true&exclusive=false&discount=false&soldOut=false&page={}&viewType=small&priceMin=&priceMax=".format(i)
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"}
res=requests.get(url,headers=headers)
res.raise_for_status()
soup=BeautifulSoup(res.text,"lxml")
items=soup.find_all("div",attrs={"class":"article_info"})
for item in items:
brand=item.find("p",attrs={"class":"item_title"}).get_text().strip()
product=item.find("p",attrs={"class":"list_info"})
if product.find('strong'):
product.find('strong').decompose()
product=product.get_text().strip()
price=item.find("p",attrs={"class":"price"})
if price.find('del'):
price.find('del').decompose()
price=price.get_text().strip()
f.write(brand+"|"+product+"|"+price+"\n") 복습
1) 종종 크롤링을 하기 위해 홈페이지에 접속하려고 하면 홈페이지가 사람이 아님을 인지하고 홈페이지가 차단을 하는 경우가 있다.
이런 에러를 방지하기 위해 headers={"User-Agent"~~}를 사용하였다.
USER-Agent는 컴퓨터마다 다를 수 있기 때문에 http://m.avalon.co.kr/check.html 에서 확인해야 한다.
2) 찾고자하는 데이터인 브랜드명, 제품명, 가격은 모두 div태그의 class가 article_info인 곳에 있다. 이곳에서 이제 필요한 정보만 뽑아내면 된다. 브랜드명은 바로 가져왔지만 제품명과 가격 데이터에는 추가적인 정보가 들어있다.

사진처럼 제품이 배송예정이거나 새벽배송이면 제품명 앞에 저런 어구가 붙었다. 마찬가지로 가격도 필요한 데이터인 구입가가 아닌 정가가 붙어있어 필요없는 태그는 없앨 필요가 있다. 따라서 decompose() 함수를 통해 각각 브랜드와 가격에서 필요없는 태그는 없앴고 strip() 함수를 이용해 공백도 없앴다. 데이터를 구분하기 위해 구분자로 "|"를 사용하였고 f.write()를 이용해 TEXT파일로 저장하였다.
결과
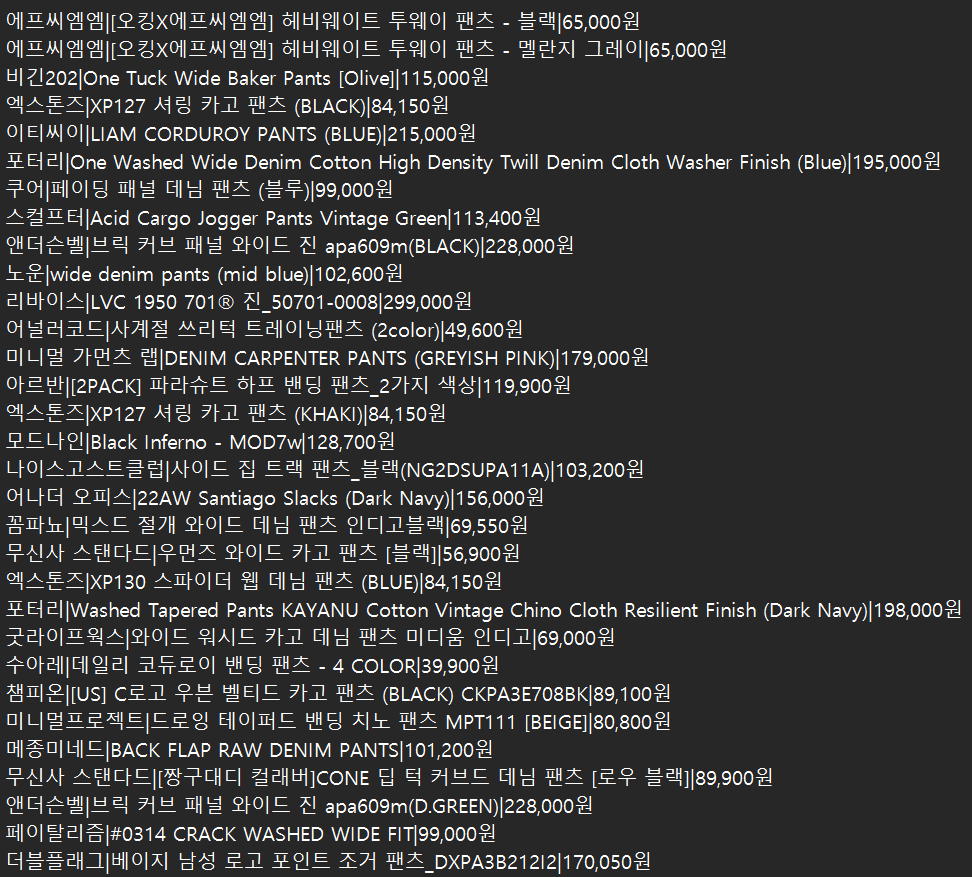


~