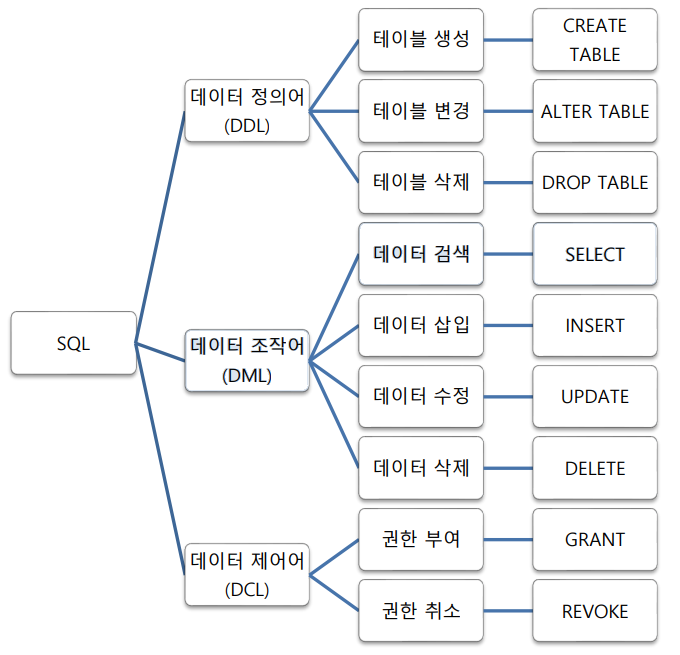
대표적인 SQL문
SELECT 문의 기본 문법
SELECT [ALL┃DISTINCT] 속성이름(들)
[FROM 테이블이름(들)]
[WHERE 검색조건(들)]
[GROUP BY 속성이름]
[HAVING 검색조건(들)]
[ORDER BY 속성이름 [ASC┃DESC]]
SELECT/FROM
SELECT에는 검색하고 싶은 속성을 적는다.
만약 고객들의 핸드폰 번호를 검색하고 싶으면 아래처럼 적으면 된다.
SELECT phone_num 핸드폰 번호와 주소를 출력하고 싶다면
SELECT phone_num, addressFROM에는 검색하고 싶은 속성이 있는 테이블의 이름을 나열한다.
검색 결과는 테이블로 반환된다.
모든 도서의 가격과 이름을 Book이라는 테이블에서 검색하는 코드다.
SELECT price, bookname
FROM Book;
ALL/DISTINCT
SELECT문에 사용하는 키워드인데 ALL은 테이블 투플의 중복을 허용,
DISTINCT는 테이블 투플의 중복을 허용하지 않도록 지정하는 키워드이다.
출판사의 중복을 허락하지 않고, Book이라는 테이블에서 검색하는 코드이다.
SELECT DISTINCT publisher
FROM Book;
WHERE
WHERE은 조건을 만족하는 데이터만 검색하는 키워드이다.
WHERE 키워드와 함께 비교 연산자와 논리 연산자를 이용한다
• 숫자만이 아니라 문자나 날짜 값을 비교하는 것도 가능
– 예) ‘A’ < ‘C’
– 예) ‘2019-12-01’ < ‘2019-12-02’
조건에서 문자나 날짜 값은 작은따옴표로 묶어서 표현(python 문자열같이)
WHERE절에 사용할 수 있는 숙어
비교 : =, <>, <, <=, >, >=
예) price < 20000
범위 : BETWEEN
예) price BETWEEN 10000 AND 20000
집합 : IN, NOT IN
예) price IN (10000, 20000, 30000)
패턴 : LIKE
예) bookname LIKE '축구의 역사'
NULL : IS NULL, IS NOT NULL
예) price IS NULL
복합조건 AND, OR, NOT
예) (price < 20000) AND (bookname LIKE '축구의 역사')
LIKE
LIKE 키워드를 이용해 부분적으로 일치하는 데이터를 검색한다.
문자열을 이용하는 조건에만 LIKE 키워드 사용 가능
+ : 문자열을 연결 ‘골프 ’ + ‘바이블’ , ‘골프 바이블’
% : 0개 이상의 문자열과 일치 ‘%축구%’ , 축구를 포함하는 문자열
[ ] : 1개의 문자와 일치 ‘[0-5]%’ , 0-5 사이 숫자로 시작하는 문자열
[^] : 1개의 문자와 불일치 ‘[^0-5]%’ , 0-5 사이 숫자로 시작하지 않는 문자열
_ : 특정 위치의 1개의 문자와 일치 ‘구%’ : 두 번째 위치에 ‘구’가 들어가는 문자열
도서이름에 ‘축구’가 포함된 출판사를 검색하시오.
ELECT bookname, publisher
FROM Book
WHERE bookname LIKE '%축구%';도서이름의 왼쪽 두 번째 위치에 ‘구’라는 문자열을 갖는 도서를 검색하시오.
SELECT *
FROM Book
WHERE bookname LIKE '_구%';
NULL을 이용한 검색
IS NULL과 IS NOT NULL
– IS NULL 키워드를 이용해 특정 속성의 값이 널 값인지를 비교
– IS NOT NULL 키워드를 이용해 특정 속성의 값이 널 값이 아닌지를 비교
전화번호가 아직 입력되지 않은 고객의 이름을 검색해보자.
SELECT name
FROM Customer
WHERE phone IS NULL;
ORDER
ORDER은 정렬방식의 키워드다.
– ORDER BY 키워드를 이용해 결과 테이블 내용을 사용자가 원하는 순서로 출력
– ORDER BY 키워드와 함께 정렬 기준이 되는 속성과 정렬 방식을 지정
• 오름차순(기본): ASC / 내림차순: DESC
• 널 값은 오름차순에서는 맨 마지막에 출력되고, 내림차순에서는 제일 먼저 출력됨
• 여러 기준에 따라 정렬하려면 정렬 기준이 되는 속성을 차례대로 제시
도서를 가격의 내림차순으로 검색하시오. 만약 가격이 같다면 출판사의 오름차순으로 검색한다.
SELECT *
FROM Book
ORDER BY price DESC, publisher ASC;
집계 함수
특정 속성 값을 통계적으로 계산한 결과를 검색하기 위해 집계 함수를 이용한다.
집계 함수 사용시 주의사항
- 집계 함수는 널인 속성 값은 제외하고 계산함
- 집계 함수는 WHERE 절에서는 사용할 수 없고, SELECT 절이나
HAVING 절에서만 사용 가능
SUM : 속성 값의 합계 계산
AVG : 속성 값의 평균 계산
COUNT : 속성 값의 개수 계산
MAX : 속성 값의 최댓값
MIN : 속성 값의 최솟값
고객이 주문한 도서의 총 판매액을 구하시오.
SELECT SUM(saleprice)
FROM Orders;고객이 주문한 도서의 총 판매액을 총매출이란 키워드로 구하시오.
SELECT SUM(saleprice) AS 총매출
FROM Orders;
GROUP BY/HAVING
– GROUP BY 키워드를 이용해 특정 속성의 값이 같은 투플을 모아 그룹을 만들고, 그룹별로 검색
• GROUP BY 키워드와 함께 그룹을 나누는 기준이 되는 속성을 지정
– HAVING 키워드를 함께 이용해 그룹에 대한 조건을 작성
– WHERE랑 HAVING을 헷갈리는 경우가 많은데 WHERE는 그룹화 하기 전이고, HAVING은 그룹화 후에 조건이다.
– 그룹을 나누는 기준이 되는 속성을 SELECT 절에도 작성하는 것이 좋음
고객별로 주문한 도서의 총 수량과 총 판매액을 구하시오.
SELECT custid, COUNT(*) AS 도서수량, SUM(saleprice) AS 총액
FROM Orders
GROUP BY custid;
가격이 8,000원 이상인 도서를 구매한 고객에 대하여 고객별 주문 도서의 총 수량을 구하시오. 단, 두 권 이상 구매한 고객만 구한다.
SELECT custid, COUNT(*) AS 도서수량
FROM Orders
WHERE saleprice >= 8000
GROUP BY custid
HAVING count(*) >= 2;
CREATE TABLE
테이블 구성, 속성과 속성에 관한 제약 정의, 기본키 및 외래키를 정의한다.
키의 정의
-
PRIMARY KEY: 기본키를 정할 때 사용
– 기본키를 지정하는 키워드
– 예) PRIMARY KEY(고객아이디)
– 예) PRIMARY KEY(주문고객, 주문제품) -
FOREIGN KEY: 외래키를 지정할 때 사용
– 외래키를 지정하는 키워드
– 외래키가 어떤 테이블의 무슨 속성을 참조하는지 REFERENCES 키워드 다음에 제시
– 참조 무결성 제약조건 유지를 위해 참조되는 테이블에서 투플 삭제 시 처리 방법을 지정하는 옵션 -
UNIQUE
– 대체키를 지정하는 키워드
– 대체키로 지정되는 속성의 값은 유일성을 가지며 기본키와 달리 널 값이 허용됨
– 예) UNIQUE(고객이름)
INTEGER : 4바이트 정수형
NUMERIC(m,d), DECIMAL(m,d) : 전체자리수 m, 소수점이하 자리수 d를 가진 숫자
CHAR(n) : 문자형 고정길이, 문자를 저장하고 남은 공간은 공백으로 채움.
VARCHAR(n) : 문자형 가변길이
DATE : 날짜형, 연도, 월, 날, 시간을 저장
다음과 같은 속성을 가진 NewCustomer 테이블을 생성하시오.
• custid(고객번호) - INTEGER, 기본키
• name(이름) – VARCHAR(40)
• address(주소) – VARCHAR(40)
• phone(전화번호) – VARCHAR(30)
CREATE TABLE NewCustomer (
custid INTEGER PRIMARY KEY,
name VARCHAR(40),
address VARCHAR(40),
phone VARCHAR(30) );
다음과 같은 속성을 가진 NewOrders 테이블을 생성하시오.
• orderid(주문번호) - INTEGER, 기본키
• custid(고객번호) - INTEGER, NOT NULL 제약조건, 외래키(NewCustomer.custid, 연쇄삭제)
• bookid(도서번호) - INTEGER, NOT NULL 제약조건
• saleprice(판매가격) - INTEGER
• orderdate(판매일자) – DATE
CREATE TABLE NewOrders (
orderid INTEGER,
custid INTEGER NOT NULL,
bookid INTEGER NOT NULL,
saleprice INTEGER,
orderdate DATE,
PRIMARY KEY (orderid),
FOREIGN KEY (custid) REFERENCES NewCustomer(custid) ON DELETE CASCADE );
ALTER TABLE
생성된 테이블의 속성과 속성에 관한 제약을 변경하며, 기본키 및 외래키를 변경함
– ADD, DROP은 속성을 추가하거나 제거할 때 사용함
– MODIFY는 속성의 기본값을 설정하거나 삭제할 때 사용함
– ADD <제약이름>, DROP <제약이름>은 제약사항을 추가하거나 삭제할 때 사용함
ALTER TABLE 기본 문법
ALTER TABLE 테이블이름
[ADD 속성이름 데이터타입]
[DROP COLUMN 속성이름]
[MODIFY 속성이름 데이터타입]
[MODIFY 속성이름 [NULL┃NOT NULL]]
[ADD PRIMARY KEY(속성이름)]
[[ADD┃DROP] 제약이름]
NewBook 테이블에 VARCHAR(13)의 자료형을 가진 isbn 속성을 추
가하시오.
ALTER TABLE NewBook ADD isbn VARCHAR(13);
NewBook 테이블의 isbn 속성의 데이터 타입을 INTEGER형으로 변경하시오
ALTER TABLE NewBook MODIFY isbn INTEGER;
NewBook 테이블의 bookid 속성을 기본키로 변경하시오.
ALTER TABLE NewBook ADD PRIMARY KEY(bookid);
DROP TABLE
DROP TABLE 문은 테이블을 삭제하는 명령
DROP 문은 테이블의 구조와 데이터를 모두 삭제하므로 사용에 주의해야 함
– 데이터만 삭제하려면 DELETE 문을 사용함
NewBook 테이블을 삭제하시오.
DROP TABLE NewBook;
INSERT
테이블에 새로운 투플을 삽입하는 명령
– INTO 키워드와 함께 투플을 삽입할 테이블의 이름과 속성의 이름을 나열
• 속성 리스트를 생략하면 테이블을 정의할 때 지정한 속성의
순서대로 값이 삽입됨
– VALUES 키워드와 함께 삽입할 속성 값들을 나열
Book 테이블에 새로운 도서 ‘스포츠 의학’을 삽입하시오. 스포츠 의학은 한솔의학서적
에서 출간했으며 가격은 90,000원이다
INSERT INTO Book(bookid, bookname, publisher, price)
VALUES (11, '스포츠 의학', '한솔의학서적', 90000);
UPDATE
테이블에 저장된 투플에서 특정 속성의 값을 수정하는 명령
– SET 키워드 다음에 속성 값을 어떻게 수정할 것인지를 지정
– WHERE 절에 제시된 조건을 만족하는 투플에 대해서만 속성 값을 수정
• WHERE 절을 생략하면 테이블에 존재하는 모든 투플을 대상으로 수정
Book 테이블에서 14번 ‘스포츠 의학’의 출판사를 imported_book 테이블의 21번
책의 출판사와 동일하게 변경하시오.
UPDATE Book
SET publisher = (SELECT publisher
FROM imported_book
WHERE bookid = '21')
WHERE bookid = '14' ;
Book 테이블에 있는 모든 도서의 가격을 5% 인상해보자
UPDATE Book
SET price = price*1.05;
DELETE
테이블에 있는 기존 투플을 삭제하는 명령
– WHERE 절에 제시한 조건을 만족하는 투플만 삭제
• WHERE 절을 생략하면 테이블에 존재하는 모든 투플을 삭제해 빈
테이블이 됨
Book 테이블에서 도서번호가 11인 도서를 삭제하시오.
DELETE FROM Book
WHERE bookid = 11;
모든 고객을 삭제하시오.
DELETE FROM Book
WHERE bookid = 11; 