🚩 통계학
🔹정의
: 관심의 대상이 되는 모집단의 특성을 파악하기 위해 모집단으로부터 표본을 수집, 정리, 요약 분석하여 표본의 특성을 파악하고 이를 이용하여 모집단의 특성에 대해 추론하는 원리와 방법을 배우는 학문
🔹목적
: 자료에 근거한 합리적인 의사결정
🔹분류
🌲기술 통계학
: 요약 통계량, 그래프, 표 등을 이용해 데이터를 정리, 요약하여 데이터의 전반적인 특성을 파악하는 방법
: 표, 그래프 등을 활용해 데이터를 시각적으로 표현하고 통계량 등으로 수치를 요약
🌲추론 통계학
: 데이터가 모집단으로부터 나왔다는 가정하에 모집단으로부터 추출된 표본을 사용하여 모집단의 특성을 파악하는 방법
: 점 추정, 구간 추정을 하거나 가설을 검정
🚩 기초 통계
🌈 모집단과 표본
🔹모집단
: 대상이 되는 집단 전체
🌲모수
: 모집단의 특성(모평균, 모분산, 모표준편차 등)
🔹표본
: 모집단의 전체 데이터를 분석하기 위한 모집단에서 추출된 일부 집단
🌲통계량
: 표본의 특성(표본평균, 표본분산, 표본표준편차 등)
🔸모평균, 표본 평균
: 우리가 알고 싶은 평균은 모집단의 평균인 모평균이지만, 모평균을 정확히 알 수 없을 경우 표본 평균을 이용
➡️ 표본 평균이라고 해서 모집단에 비해 지나치게 편향되어 있지 않으며, 표본 데이터의 개수가 늘어날수록 모평균에 가까워짐
🔸모분산, 표본 분산
: 표본 분산은 모분산에 비해 분산을 과소평가해서 계산
➡️ 모평균과 표본 평균이 다르기 때문
🌈 추출(Sampling)
🔹추출(Sampling)
: 모집단에서 표본을 추출하는 방법
🔹추론(Inference)
: 표본 통계량으로 모집단의 특성을 추론
🔹확률 표본 추출
🌲단순 샘플링(Simple Random)
: 단순 랜덤으로 샘플을 추출
🌲층화 샘플링(Stratified)
: 모집단을 몇 개의 그룹으로 나누어 각 그룹에서 랜덤으로 n개씩 추출
🌲계통 샘플링(Systematic)
: 모집단 데이터에 1~n개의 번호를 임의로 매긴 다음, 일정 간격마다 데이터 추출
🌲군집 샘플링(Cluster)
: cluster로 모집단 데이터로 분할하고, 군집 중 하나 또는 여러 개의 군집을 선정, 선정된 군집의 전체 데이터 사용
🔹복원 샘플링
: 한번 뽑은 표본을 다시 모집단에 포함시켜 다음 표본을 샘플링
🔹비복원 샘플링
: 한법 뽑은 표본을 모집단에서 제외시키고 다음 표본을 샘플링
🌈 변수
🔹변수
: 값이 변하는 수로 수치형 변수와 범주형 변수로 나뉨
🌲수치형 변수
: 측정값이 숫자로 표현되고 숫자의 크기가 의미를 갖는 자료
: 이산형 자료, 연속형 자료
🌲범주형 번수
: 숫자로 표현할 수 없는 자료를 집단화하여 나타낸 자료
: 명목형 자료, 순서형 자료
🌈 정규분포
🔸중심극한정리
: 표본의 크기가 커질수록 표본 평균의 분포는 모집단의 분포 모양과는 관계없이 정규분포에 가까워진다.
: 표본 평균의 평균은 모집단의 모평균과 같고, 표본 평균의 표준 편차는 모집단의 모 표준 편차를 표본 크기의 제곱근으로 나눈 것과 같다.
🔸정규 분포
: 통계학에서의 대표적인 연속 확률 분포로 중앙 부분이 평균이며 평균을 기준으로 대칭 모양
➡️ 표준정규분포 : 평균이 0, 표준편차가 1인 분포
🚩 기초 통계량
🔹평균
🌲산술평균
: 일반적으로 사용되는 값으로 데이터 전체를 더한 후 데이터의 총 개수로 나누어 준 값
🌲기하평균
: 인구증가율, 물가상승율, 경제성장률 등과 같이 연속적인 변화율 데이터를 기반으로 평균 변화율을 구할 때 사용하는 평균
🌲조화평균
: 각각의 데이터 값에 역수를 취하여 산술 평균을 구한 후 다시 역수를 취한 값
🔸중앙값
: 데이터를 크기 순으로 정렬했을 때 가장 중앙에 위치하는 값
➡️ 데이터 개수가 짝수인 경우 : 중앙에 있는 두 값의 평균
❗ 평균은 모든 데이터를 포함한 개념이기 때문에 이상치에 취약하고.
중앙값은 모든 데이터를 포함하진 않기 때문에 이상치에 강건하다.
🔹최빈값
: 가장 많이 등장한 값
🔹분산
: 데이터가 평균과 얼마나 떨어져 있는가를 나타내는 지표
🔸표준편차
: 분산의 제곱근
➡️ 작을수록 데이터들이 평균에 가까이 있고 클수록 평균에 멀리있다.
🚩 이상치 탐색
🔸이상치
: 정상군의 상한과 하한의 범위를 벗어나 있거나 패턴에서 벗어난 수치
➡️ 일반적으로 -3σ 미만, +3σ 초과인 값을 이상치로 판정
❗ 이상치는 분석의 질을 향상시키기 위해 제거하거나 다른 값으로 대체하는 경우가 많지만, 상황에 따라서는 제거하지 않고 분석해야 하는 경우도 있음
🔸Z-Score
: 자료가 평균으로부터 표준편차의 몇 배만큼을 떨어져 있는지를 나타내는 지표
➡️ 양의 Z-Score는 자료 값이 평균보다 높다.
➡️ 음의 Z-Score는 자료 값이 평균보다 낮다.
➡️ 0에 가까운 Z-Score는 자료 값이 평균과 비슷하다.
➡️ Z-Score가 3이상이거나 -3이하면 일반적으로 이상치로 판단
🔸사분위수(Quartile)
: 값을 같은 갯수로 4개로 나눈 각각의 값
🌲1사분위수(Q1) : 25%
🌲2사분위수(Q2) : 50%, 중앙값
🌲3사분위수(Q3) : 75%
🌲4사분위수(Q4)
🔸IQR(Inter Quartile Range, 사분위간 범위)
: 1사분위수(Q1)와 3사분위수(Q3) 간의 거리(Q3-Q1)
🌲IQR을 활용한 이상치 범위
이상치 < Q1 – 1.5 X IQR, Q3 + 1.5 X IQR < 이상치
🔹변동계수
: 상대적으로 얼마나 변동이 많은지를 보기 위한 지표
: 단위가 다르거나, 표준편차가 비슷한 그룹끼리 비교하고 싶을 때 일정한 기준에 따른 비교가 가능
🔑 변동계수(CV) = 표준편차 / 평균
🔸왜도(Skeweness)
: 분포의 비대칭도를 나타내는 통계량
➡️ 비대칭이 커질수록 왜도의 절대값은 증가
➡️ 왜도가 -1, +1 범위는 치우침이 없는 데이터라고 한다.
🌲Negative : 평균<중앙값<최빈값이면 오른쪽으로 치우친 형태
🌲Positive : 최빈값<중앙값<평균이면 왼쪽으로 치우친 형태
🔹첨도(Kurtosis)
: 꼬리 부분의 길이와 중앙 부분의 뾰족함으로 데이터의 분포 파악
🌲Mesokurtic : 정규 분포 모양
🌲Leptokurtic : 중앙 부분은 Mesokurtic보다 높고 뾰족하기 때문에 이상치가 많을 수 있음
🌲Platykurtic : leptokurtic와 반대, 이상치가 없어서 데이터를 다시 확인할 필요가 있음
🚩 기술 통계
🔸카이제곱분포
: 검정 통계량이 카이제곱 분포를 따르는 통계 검정에 사용
: 분산의 특징을 확률 분포로 만든 것
: 분포는 자유도에 의해 정의
: 모분산을 구하는 것
: 카이제곱 분포의 자유도가 높을수록 정규 분포에 근접
: y축에 편향된 분포
➡️ 제곱된 값의 분산을 다루기 때문에, +값만 존재
🔸(스튜던트) t분포
: 모분산이 알려져 있지 않고 소규모 표본인 경우에 쓸 수 있는 분포
➡️ 표본의 크기가 30 이하인 경우 사용
: 모분산을 모를 때 모평균을 구하는 것
: 표본평균, 두 표본평균 사이의 차이, 회귀 파라미터 등의 분포를 위한 기준으로 사용
🔸F분포
: t분포는 집단 3개 이상은 검정이 불가, 이 경우에 F분포로 검정
: 카이제곱 분포처럼 분산을 다루지만 집단 간의 분산을 다룸
➡️ 분산분석에 주로 사용
🔑 F = 집단 간 분산 / 집단 내 분산
🚩 통계적 분석 기법
🌈 검정(test)
🔸유의확률(P-Value)
: 귀무가설(H0)이 맞다는 전제 하에, 표본에서 실제로 관측된 통계치와 같거나 더 극단적인 통계치가 관측될 확률
: 귀무가설을 기각하는 정도(기준)
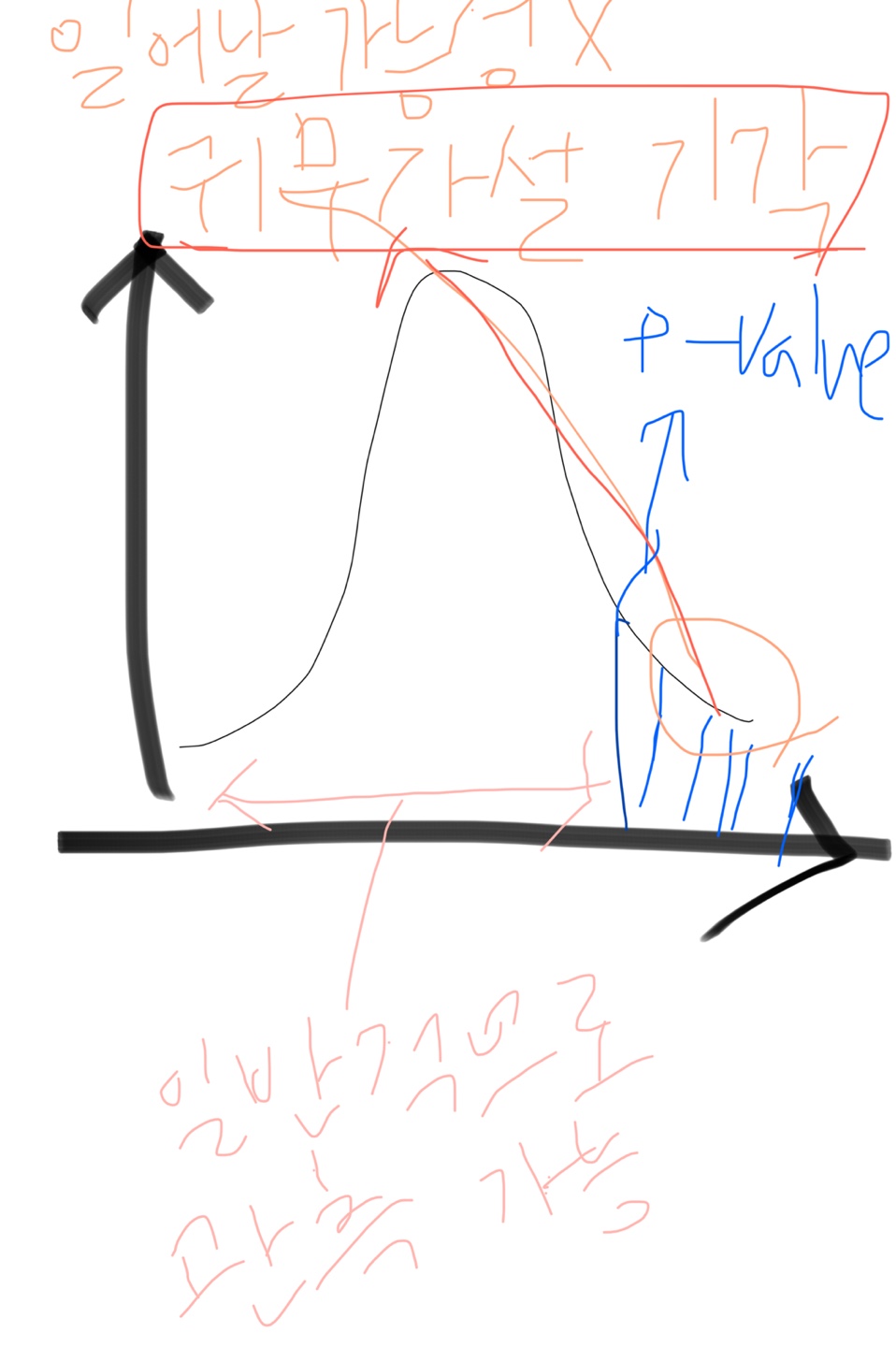 ➡️ 신뢰 구간이 95%일 때 대립 가설이 틀릴 확률이 5% 미만이어야(귀무 가설이 일어날 확률이 거의 없을 확률) 대립 가설이 채택됨
➡️ 신뢰 구간이 95%일 때 대립 가설이 틀릴 확률이 5% 미만이어야(귀무 가설이 일어날 확률이 거의 없을 확률) 대립 가설이 채택됨
🔸귀무가설(H0)
: 검정 대상이 되는 가설으로 일반적으로 널리 인정되는 사실
➡️ 기각이 목표
🔸대립가설(H1)
: 귀무가설과 대립되는 주장으로 연구자가 새롭게 주장하고자 하는 가설
➡️ 채택이 목표
🔹단측 검정(one-tailed test)
: 한 방향성으로 가능성이 크다고 생각되는 경우
🔹양측 검정(two-tailed test)
: 방향성은 모르겠지만 차이가 있다고 생각되는 경우
🔹제 1종 오류
: 귀무가설이 참인데도 불구하고 이를 기각
🔹제 2종 오류
: 귀무가설이 거짓인데도 이를 채택
🔸t-검정(t-test)
: 두 개 집단의 평균에 통계적으로 유의미한 차이가 있는지를 검정
: 적합한 t-test 방법을 선택하기 위한 F 검정 필요
➡️ P-value가 0.05보다 크면 두 집단의 평균에는 유의미한 차이가 없고, 0.05보다 작으면 두 집단의 평균에는 유의미한 차이가 있다.
🔑 귀무가설(H0) : 두 집단의 평균에는 유의미한 차이가 없다.
🔑 대립가설(H1) : 두 집단의 평균에는 유의미한 차이가 있다.
🌲t-검정:등분산 가정 두 집단
🌲t-검정:이분산 가정 두 집단
🪄 변수 선택 → F 검정 → t-test → 결과 해석
🔸F-검정
: 두 집단의 등분산성(분산이 같은지 여부)을 검정
➡️ P-value가 0.05보다 크면 두 집단의 분산은 같고, 0.05보다 작으면 두 집단의 분산은 다르다.
🔑 귀무가설(H0) : 두 집단의 분산은 같다.
🔑 대립가설(H1) : 두 집단의 분산은 다르다.
🔸카이제곱검정
: 카이제곱 통계량은 데이터 분포와 가정된 분포 사이의 차이를 나타내는 측정값
: 카이제곱 검정통계량이 카이제곱분포를 따른다면 카이제곱분포를 사용해서 검정 수행
: 카이제곱분포에서 일어나기 힘든 일이면 귀무가설 기각, 대립가설 채택
➡️ 독립성 검정 : 두 변수는 서로 연관성이 있는가?
➡️ 적합성 검정 : 실제 표본이 내가 가정한 분포와 같은가?
➡️ 동일성 검정 : 두 집단의 분포가 같은가?
🌈 회귀 분석
(정의는 앞선 목록에서 정리 완료)
🔸회귀 분석의 종류
✔️ 선형 회귀 분석
: 함수식이 선형 함수 식인 경우
🌲단순 선형 회귀 분석 : 독립 변수가 한 개
🌲다중 선형 회귀 분석 : 독립 변수가 여러 개
❗ 다중 선형 회귀 분석에서는 조정된 결정 계수 결과를 확인 해야 한다.
➡️ 어느 독립변수가 종속변수에 영향을 주는 변수가 아니더라도 독립변수의 개수가 많아지면 결정 계수는 어느 정도 높아지게 되기 때문(오류)
➡️ 따라서 영향이 없는 변수들이 추가되어 결정계수가 높아진 오류분을 조정 반영한 조정된 결정 계수를 확인 해야한다.
✔️ 비선형 회귀 분석
: 함수식이 선형 함수 식이 아닌 경우
🌈 시계열 데이터
🔹시계열 데이터
: 시간의 흐름에 따라 발생한 데이터
🔹시계열 데이터 분석 목표
: 과거 시계열 데이터 특성 파악 및 미래 데이터 예측
🔹시계열 데이터 분석 방법
🌲지수 평활법
: 현재의 실제 값과 현재의 예측 값을 합산하여 미래의 예측 값을 구하는 방법
💭 단순 지수 평활법을 활용한 예측치 계산 방법
: 과거 시계열 데이터 특성 파악 및 미래 데이터 예측
🔑 미래의 예측값 = 과거의 실제 값 X α(실제값을 반영할 가중치 0 ~ 1사이의 값) + 과거의 예측값 X (1-α)
💭 엑셀의 함수로 예측(=FORECAST.ETS)
: 지수 평활법을 활용한 예측치 산출
🔑 = FORECAST.ETS(예측할 날짜, 알고 있는 실제값들(ex. 과거 매출 등), 과거 날짜들, [계절성], [누락데이터 처리], [중복 시계열 처리])
[계절성] : >2 - 해당 주기로 데이터 예측, =0 -주기가 없다고 가정하고 선형 예측, 1또는 비어 잇는 경우 - 엑셀에서 자동으로 계절성 예측
[누락된 데이터 처리] : 0인 경우 - 0으로 계산, 1 또는 비어있는 경우 - 주변 데이터의 평균으로 계산
[중복 시계열 처리]
: 1 또는 빈칸 - AVERAGE (평균으로 반영), 2 - COUNT (빈칸이 아닌 숫자만 개수를 세서 반영)
: 3 - COUNTA (빈칸이 아닌 모든 값의 개수를 세서 반영), 4 - MAX (최대값만 반영)
: 5 - MEDIAN (중간값으로 반영), 6 - MIN (최소값만 반영), 7 - SUM (합계를 반영)

그림이 개성있네요