기본 하드웨어
배경
-
프로그램의 실행은 프로그램을 디스크에서 메모리로 적재한 다음 프로세스의 형태로 실행된다.
-
메인 메모리와 레지스터는 CPU만이 접근할 수 있는 저장소이다.
-
레지스터 접근은 일반적으로 CPU clock의 1사이클 내에 이루어지는 반면, 메인 메모리 접근에는 많은 사이클을 필요로 하기 때문에 지연(stall) 현상이 발생한다.
-
레지스터와 메인 메모리의 접근 시간 차이로 캐시(Cache)를 메인 메모리와 CPU 레지스터 사이에 배치하여 사용할 수 있다.
-
올바른 작동을 보장하기 위해 메모리를 보호할 필요가 있다.
보호
프로그램은 보조 저장 장치에 저장되어 있다가 실행되면 메모리에 적재되어 프로세스 형태로 실행이 된다.
이 때, 각각의 프로세스가 독립된 메모리 공간을 가지고 그 메모리 영역에만 접근할 수 있도록 보장해야 한다.
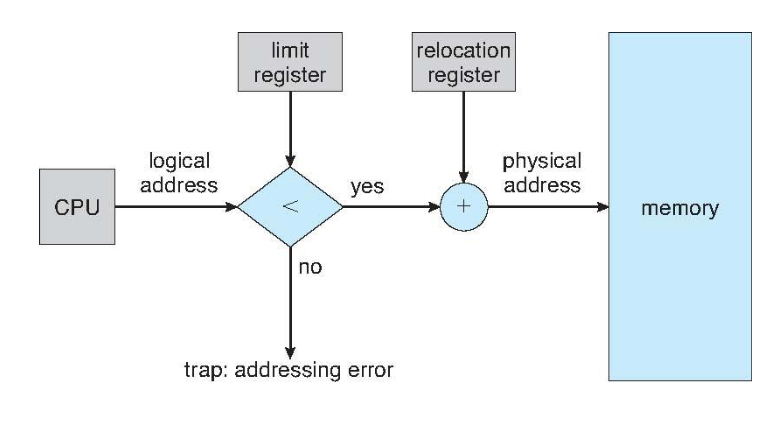
이러한 보호 기능을 위해 기준 레지스터(base register), 상한 레지스터(limit register)를 사용하여 프로세스의 논리적 주소 공간을 정의할 수 있다.
- base register : 가장 작은 legal physical memory address를 저장
- limit register : 주어진 영역의 크기를 저장
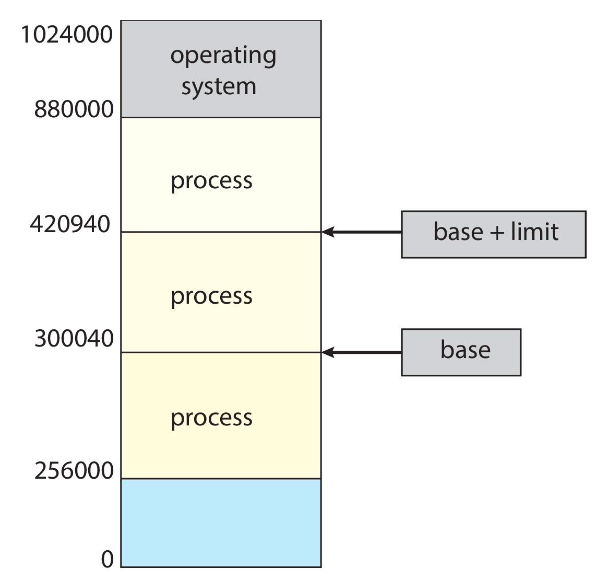
CPU는 사용자가 요구하는 모든 메모리 접근을 반드시 확인하여 해당 사용자에게 할당된 논리 주소 공간(base register ~ base + limit)의 영역 사이에 접근하는지 확인한다.
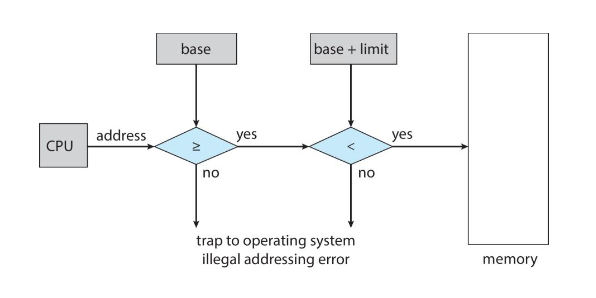
(기준 및 상한 레지스터는 여러가지 특권 명령(special privileged instruction)을 사용하는 운영체제에 의해서만 적재된다.)
주소의 할당
프로그램이 메모리에 적재되기 이전에 메모리로 가져올 준비가 된 프로그램들은 입력 대기열을 형성한다.
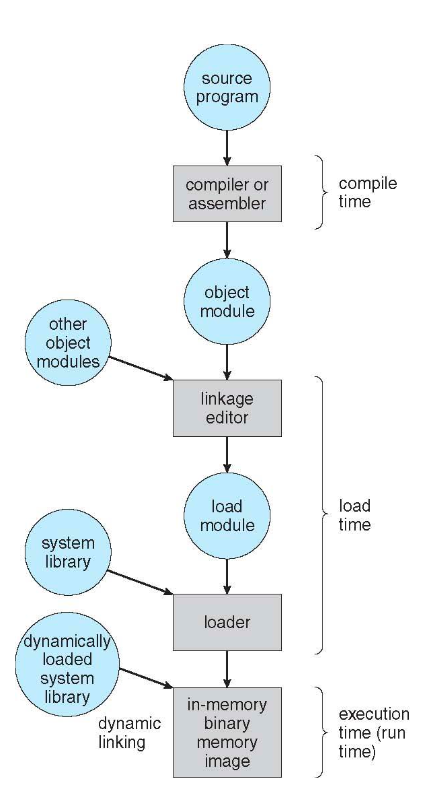
프로그램은 자신의 라이프 사이클동안 여러가지 다양한 방법으로 주소가 표현된다.
- 소스코드 : 주소는 항상 심볼 형태(symbolic)로 표현됨
- 컴파일된 소스코드 : 재배치 가능한 주소로 바인딩됨. 이후 linker 혹은 loader가 재배치 가능한 주소에서 절대 주소로 바인딩한다.
메모리에서 명령어와 데이터의 바인딩
메모리에서 instruction-data 바인딩은 3가지 단계에서 발생할 수 있음
- 컴파일 시간 (compile time) : 만약 메모리 주소를 미리 알 수 있다면, 절대코드를 미리 생성할 수 있음 (시작 위치가 바뀌게 되면 반드시 다시 컴파일해야함)
- 적재 시간 (load time) : 메모리 주소를 컴파일 시간에 알 수 없다면, 반드시 재배치 가능 코드를 생성해야함
- 실행 시간 (execution time) : 프로세스가 실행 중에 한 메모리 내의 세그먼트에서 다른 세그먼트로 옮겨질 수 있다면 프로그램이 실행될 때 까지 바인딩이 지연됨 (메모리 주소를 찾아갈 수 있게 하드웨어의 지원이 필요)
Logical versus Physical Address Space
- 논리 주소 (logical address) : CPU에 의해 생성. 가상 주소 (virtual address)
- 물리 주소 (physical address) : 메모리 유닛에 표시되는 실제 주소
compile 또는 load time에 주소를 바인딩하면 논리 주소와 물리 주소는 같지만, execution time에 바인딩된다면 논리 주소와 물리 주소가 다름
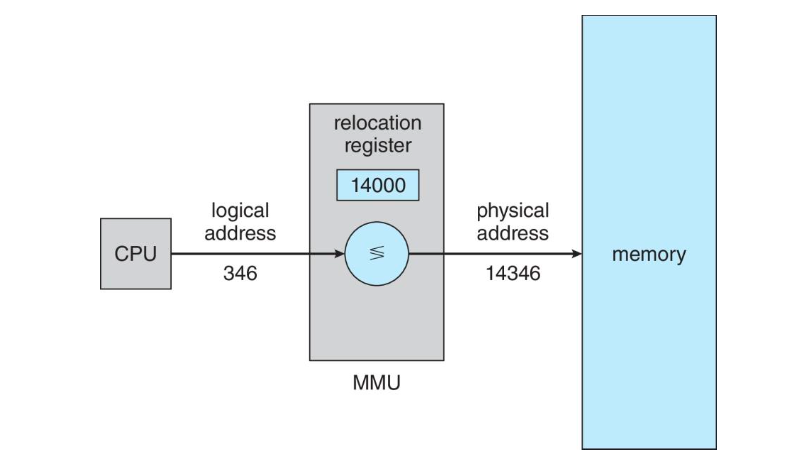
메모리 관리 장치 (MMU)
Memory Management Unit은 런타임에 가상 주소에서 물리 주소로 변환을 수행하는 하드웨어 장치이다.
실제 물리 주소는 MMU가 처리를 해주기 때문에 프로세스는 자기가 가진 논리 주소만을 사용하면 된다.
여러 방법을 사용하여 구현이 가능하지만 간단하게 기준 레지스터 기법을 일반화시킨 기법을 생각해보자.
기준 레지스터를 재배치 레지스터(relocation register)라 부르고,
재배치 레지스터의 값은 주소가 메모리로 보내질 때마다 사용자 프로세스에 의해 모든 주소에 더해진다.
동적 적재
지금까지 프로그램이 돌아가기 위해서는 전체 프로그램과 프로세스의 데이터들이 물리 메모리에 적재되어야 실행될 수 있다고 얘기했다. 따라서 프로세스의 크기가 실제 메모리의 크기에 제한될 수 밖에 없다. 따라서 동적 적재를 사용하게 되었다.
이 때, 프로그램에서 실제 돌아가는 부분만 메모리에 넣고 루틴이라고 부르는 돌아가지 않는 친구들을 잘라서 메모리에 적재하지 않는다.
루틴은 실제 호출될 때까지는 메모리에 적재되지 않고, 따라서 사용되지 않는 루틴은 절대 적재되지 않으므로 보다 효율적이게 메모리 공간을 활용할 수 있다.
예를 들어, 예외처리를 하는 부분들은 실제 돌아갈 때에는 메모리에 적재되지 않다가 에러가 났을 때 메모리에 적재하게 된다.
동적 적재는 운영체제로부터 특별한 지원이 필요 없고 프로그램 설계를 통해 구현된다. (하지만 운영체제는 동적 적재를 구현하는 라이브러리 루틴을 제공해줄 수 있다.)
동적 연결
- 정적 연결 (static linking) : 시스템 라이브러리와 프로그램 코드가 이진 프로그램 이미지로 로더에 의해 결합됨
- 동적 연결 (dynamic linking) : 런타임에 link됨
코드의 작은 부분인 스텁(stub)이 적절한 메모리 상주 라이브러리 루틴을 찾는 데에 사용됨
운영체제는 루틴이 프로세스 내의 메모리 주소에 있는지 확인함
동적 연결은 라이브러리에 특히 유용함
시스템은 공유 라이브러리라고 불리기도 함
시스템 라이브러리는 갱신이나 패치될 수 있음 (버전 관리가 필요할 수 있다)
연속 메모리 할당
연속 할당
메인 메모리에는 운영체제 뿐만 아니라 여러 사용자 프로세스들도 있어야 한다.
초기에는 연속 할당이란 방법을 사용하였는데, 이는 메인 메모리를 두 파티션으로 나눈다.
- 운영체제를 위한 파티션 : 일반적으로 낮은 메모리 주소. 인터럽트 벡터와 같이 상주함
- 사용자 프로세스를 위한 파티션 : 일반적으로 높은 메모리 주소. 각 프로세스는 메모리의 연속된 단일 섹션에 포함됨 (프로세스마다 한 덩어리)
연속 할당을 할 때 이전에 알아본 재배치 레지스터를 사용하여 사용자 프로세스들이 서로 보호되고 운영체제의 코드와 데이터를 변경하지 못하도록 함.
기준 레지스터(재배치 레지스터)에는 가장 작은 물리 주소의 값을 저장, 상한 레지스터에는 논리 주소의 범위 값을 저장하고 MMU가 논리 주소를 동적으로 매핑한다.
(각 논리 주소는 반드시 상한 레지스터보다 작은 크기를 가져야 함)
재배치 레지스터를 사용하여 커널 코드를 일시적으로 활용할 수 있고 운영체제 실행 중에도 커널의 크기를 변경할 수 있게됨
가변 파티션
-
메인 메모리를 파티션으로 구분하여 각 파티션에 프로세스를 할당 -> 동시에 돌아가는 프로세스의 수, 즉 다중 프로그래밍의 정도는 파티션의 수에 제한을 받음
-
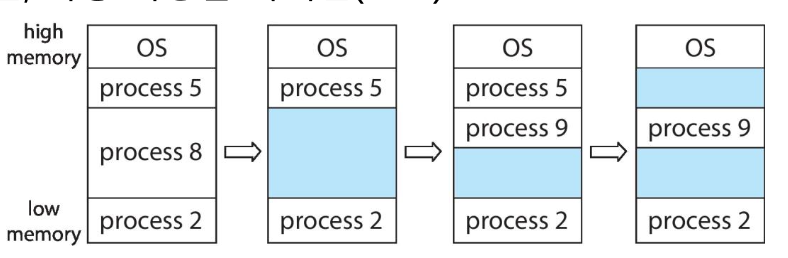
파티션에 프로세스가 할당되기 때문에 파티션의 크기를 동적으로 하여 프로세스의 크기에 맞추면 효율적으로 관리할 수 있음 -> 가변 파티션
-
시스템이 실행되면서 다양한 크기의 사용 가능한 메모리 블록(Hole)들이 메모리에 흩어지게 됨
-
프로세스가 도착하면 해당 프로세스가 들어갈 수 있는 충분히 큰 hole에 할당됨
-
프로세스는 종료될 때 할당된 파티션을 해제하고 인접한 할당 가능한 파티션(hole)과 합쳐짐
-
운영체제는 할당된 파티션, 사용 가능한 파티션에 대한 정보를 관리
동적 메모리 할당 문제 (Dynamic Storage-Allocation Problem)
프로세스의 크기가 n일 때 hole들 중에서 어떤 곳에 들어가야할까?
- 최초 적합 (first-fit) : 첫번째 사용 가능한 공간을 할당
- 최적 적합 (best-fit) : 사용 가능한 공간 중 가장 작은 것을 할당. hole들의 리스트가 정렬되어있지 않다면 전체 리스트를 검색해야 함. 가장 작은 잔여 hole을 생성
- 최악 적합 (worst-fit) : 사용 가능한 공간 중 가장 큰 것을 할당. 마찬가지로 정렬되어있지 않다면 전체 리스트를 검색해야 함. 가장 큰 잔여 hole을 생성
first-fit, best-fit이 worst-fit보다 시간과 메모리 이용 효율 측면에서 더 좋다.
단편화 (Fragmentation)
-
외부 단편화 (External fragmentation) : 전체 메모리 공간이 요청을 충족하기에 충분하지만, 연속적이지 않음. 최악의 경우 프로세스 사이사이 마다 낭비되는 공간이 있을 수 있다. 따라서 이 작은 낭비되는 hole들을 하나로 합쳐서 또 다른 프로세스를 돌릴 수 있는 공간으로 만드는 것이 좋다.
-
내부 단편화 (Internal fragmentation) : 할당된 메모리가 요청된 메모리 크기보다 약간 더 클 수 있음. 이 약간 큰 부분은 파티션 내에 있지만 사용되지 않음.
first-fit, best-fit 모두 외부 단편화의 문제가 있을 수 있다.
- 50% 규칙 : First-fit을 사용할 때, N개의 블록을 할당할 때 0.5N개의 블록이 단편화 때문에 손실될 수 있음. 즉 메모리의 1/3을 사용할 수 없게 됨
외부 단편화는 압축(compaction) 을 통해 감소시킬 수 있다. 띄엄띄엄 위치한 hole들을 하나의 큰 hole으로 합치는 방법이다.
그러나 재배치가 정적이거나 load time에 이루어진다면 압축은 할 수 없고, 재배치가 실행 시간에 동적으로 이루어지는 경우에만 사용 가능하다.
Paging
페이징
앞에서 프로세스는 메모리를 연속적으로 가지고 있어야 한다고 했다.
페이징 기법을 사용하면 프로세스의 물리적 주소 공간은 연속될 필요가 없다.
물리 메모리를 512B ~ 16MB 크기의 프레임(frame)이라는 고정된 크기의 블록으로 나눈다. (모든 가용 프레임은 추적 가능해야 한다.)
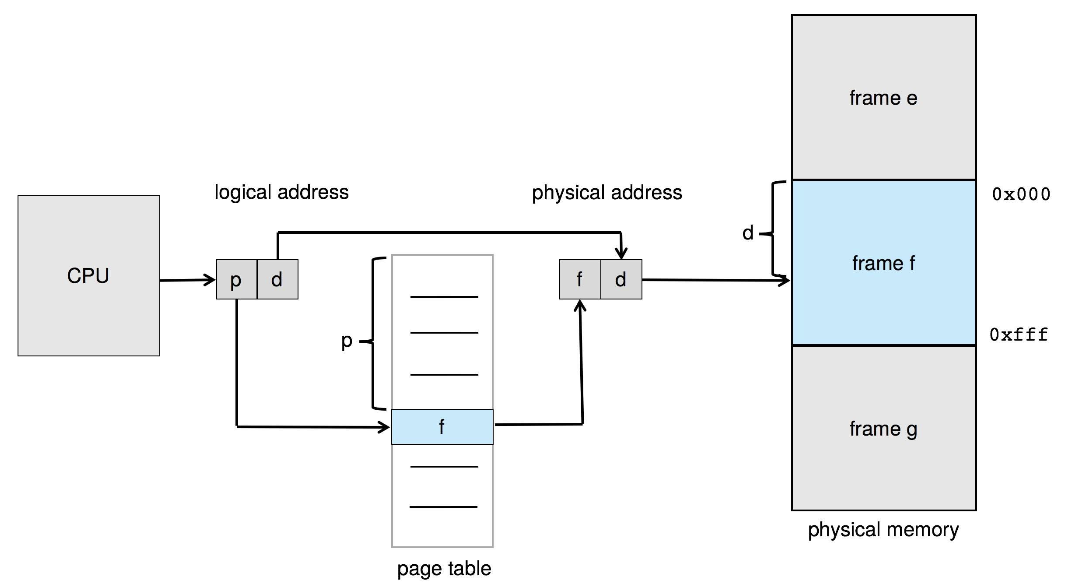
논리 메모리를 페이지(page)라는 동일한 크기의 블록으로 나눈다.
n개의 page를 가지는 프로그램을 실행하기 위해서는 n개의 가용 프레임을 찾은 후 프로그램을 적재해야한다.
페이지 테이블을 이용하여 논리 주소를 물리 주소로 변환한다.
페이징 기법을 사용하면 외부 단편화는 없지만,
프레임의 크기는 고정되어 있기 때문에 내부 단편화를 해결할 수는 없다.
주소 변환 기법
CPU에 의해 생성된 주소는 다음과 같이 나눌 수 있다.
- 페이지 번호 (p: page number)
- 페이지 오프셋 (d : page offset)
내부 단편화 계산
페이지 크기 : 2,048B
프로세스 크기 : 72,766B = 35page + 1,086B (72,766 / 2,048 = 35.5302...)
내부 단편화 크기 : 2,048B - 1,086B = 962B
최악의 경우 딱 1바이트만을 위해 1프레임이 필요할 수도 있다. 이 경우에는 1바이트를 제외한 나머지가 모두 내부 단편화.
평균 단편화 = 1/2 프레임 크기
내부 단편화를 줄이기 위해서 어떻게 해야할까? -> 작은 프레임 크기를 가지게 할 수 있다.
그러나 페이지와 프레임은 1:1 대응을 해야하기 때문에 단편화를 줄이기 위해 페이지의 개수를 증가시키면 페이지 테이블의 크기가 커지는 trade off가 있다.
페이지 테이블 구현
page table 역시 메인 메모리에 저장된다.
페이지 테이블을 사용하기 위해서 앞서 살펴본 base, limit register와 같은 역할을 하는 레지스터들이 존재한다.
- 페이지 테이블 기준 레지스터 (Page-table base register) : 페이지 테이블을 가리킴
- 페이지 테이블 길이 레지스터 (Page-table length register) : 페이지 테이블의 크기를 나타냄
페이지 테이블을 사용하여 효율성은 좋아졌지만, 결국 페이지 테이블도 메모리에 위치하기 때문에 메모리를 2번 참조하게 되어 속도가 느려지는 문제가 있다. (페이지 테이블을 참조하는데 1번, 데이터 / 명령 접근을 위해 1번)
메모리를 2번 참조하는 문제를 해결하기 위해 TLB (Translation look-aside buffers) (연관 메모리, associative memory) 라 불리는 특수한 소형 하드웨어 캐시를 사용한다.
Translation Look-Aside Buffer (TLB)
TLB는 쉽게 말해 Page table의 캐시
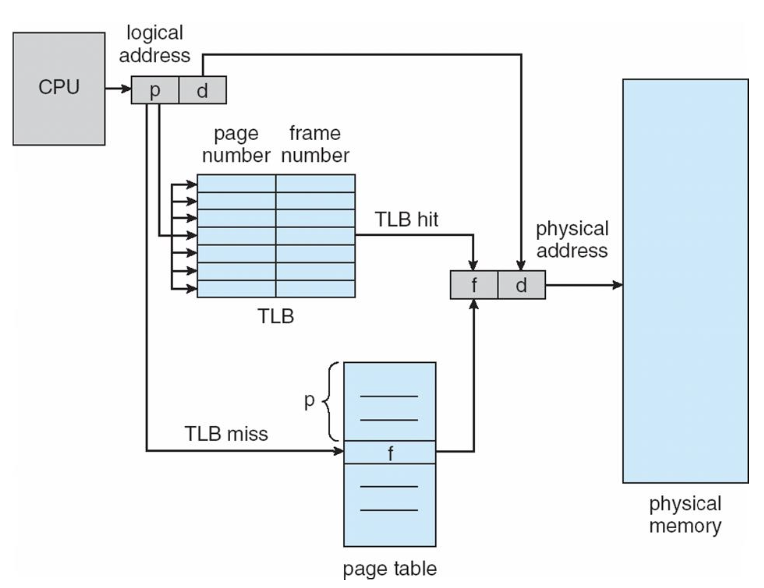
CPU에서 논리 주소의 page number를 가지고 TLB에 해당하는 frame number를 찾으면 TLB hit으로 바로 frame의 number를 얻어내고 논리 주소의 offset을 통해 실제 메모리에 접근을 한다.
만약 TLB에서 miss가 일어나면 page table을 참조하여 frame을 찾아낸 후 TLB를 update하고 메모리에 접근을 한다.
이렇게 캐시를 통해 항상 page table을 참조하지 않도록 하여 메모리를 2번 참조하는 문제를 해결할 수 있다.
어떤 TLB는 각 항목에 ASIDs (Address-Space ID) 를 저장하기도 한다.
- 그 TLB 항목이 어느 프로세스에 속하는지 알려줌
- 그 프로세스에 대한 주소 공간 보호를 제공
- ASID 지원이 없으면 새로운 페이지 테이블이 선택될 때 마다 (= 모든 문맥 교환 시) TLB가 전부 flush 되어야 함
일반적으로 TLB의 크기는 64~1024개로 작기 때문에 page table을 모두 담지 못할 수 있다.
따라서 TLB에서 miss가 일어나면 다음에 더 빠르게 접근할 수 있도록 TLB에 값을 load 해야한다.
- 교체 정책을 고려 (LRU, RR, Random 등)
- 일부 항목은 영구적인 빠른 액세스를 위해 TLB에 고정 (중요 커널 코드 등)
실질 접근 시간 (Effective Access Time)
실질 접근 시간 (EAT)는 TLB에서 hit 또는 miss를 했을 때 메모리 접근 시간
즉, 메모리 참조 시간이 t라고 하면
실질 접근 시간 = (TLB hit ratio t) + (TLB miss ratio 2t)
예를 들어, 적중률이 80%이고 메모리 접근 시간이 10ns라고 한다면
EAT = 0.810 + 0.220 = = 12ns
즉 메모리 접근 시간이 20%나 늘어난다.
그러나 현실적으로 적중률이 99%라고 가정한다면
EAT = 0.9910 + 0.0120 = 10.1ns
메모리 접근 시간이 단지 1% 증가한다.
메모리 보호
page table의 각 항목에 valid/invalid bit를 추가하여 메모리를 보호할 수 있다.
페이지를 실행 전용 등으로 표기하기 위해 더 많은 비트를 추가할 수도 있다.
- valid : 관련된 페이지가 프로세스의 논리 주소 공간에 있으므로 legal page임을 나타냄
- invalid : 관련된 페이지가 프로세스의 논리 주소 공간에 없음을 나타냄
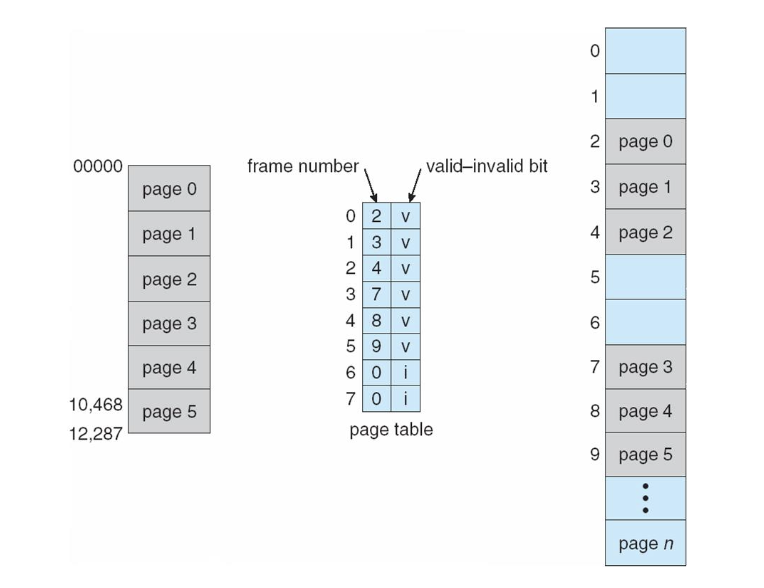
이러한 검사에서 오류가 발생하면 트랩을 발생시킴
또는 페이지 테이블 길이 레지스터 (Page-table length register)를 사용
공유 페이지
paging의 장점중 하나는 공통되는 코드들을 공유할 수 있다는 것이다. 특히 이는 multi-processes 환경에서 장점을 가진다.
여러 프로세스들이 같은 자원을 사용하는데, 만약 자원을 각각 가지고 있게 되면 이는 비효율적이기 때문이다.
만약 코드가 reentrant code라면 이는 공유될 수 있다.
reentrant code는 스스로를 수정할 수 없는 코드여서 여러 프로세스들이 동시에 실행해도 수정될 가능성이 없기 때문에 안전하다.
공유된 자원은 메모리에 한번 올라가있고, 이를 사용하는 여러 프로세스들이 여기에 매핑되어 있다.
- 공유 코드 (Shared code) : 프로세스 간에 공유되는 1개의 읽기 전용 코드 (재진입 코드, reentrant code) 복사본
동일 프로세스 공간을 공유하는 여러 스레드와 유사한 느낌
읽기/쓰기 페이지 공유가 허용되는 경우 프로세스 간 통신에도 유용
- 개인 코드 및 데이터 (Private code and data)
각 프로세스는 코드와 데이터에 대한 분리된 복사본을 유지
개인 코드 및 데이터에 대한 페이지는 논리 주소 공간의 어느 곳에나 나타날 수 있음
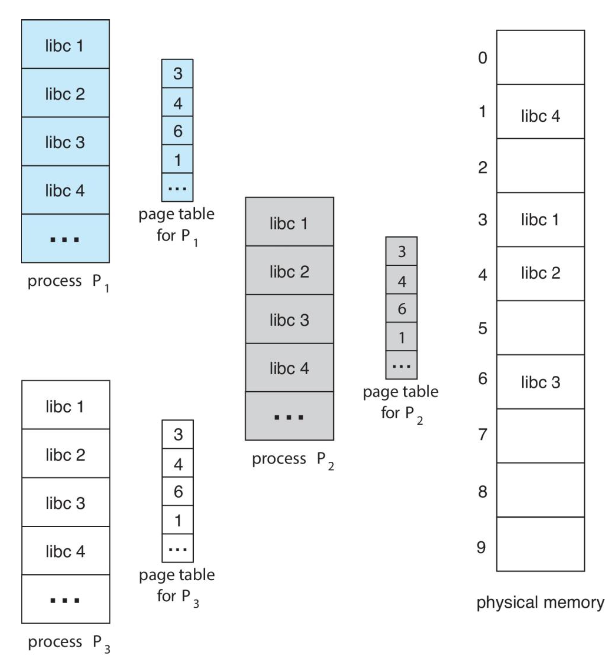
페이지 테이블의 구조
현시대의 대부분의 시스템은 큰 논리 주소 공간을 지원하기 때문에 (32, 64bit) page table 역시 엄청 커질 수 있다.
따라서 page table 전체를 한번에 메인 메모리에 올리는 것은 한계가 있고,
1) 계층적 페이징
2) 해시 페이지 테이블
3) 반전된 페이지 테이블
등의 기법을 통해 페이지 테이블을 구현하여 이를 해결할 수 있다.
계층적 페이지 테이블
논리 주소 공간을 여러 개의 페이지 테이블로 분할하는 기법.
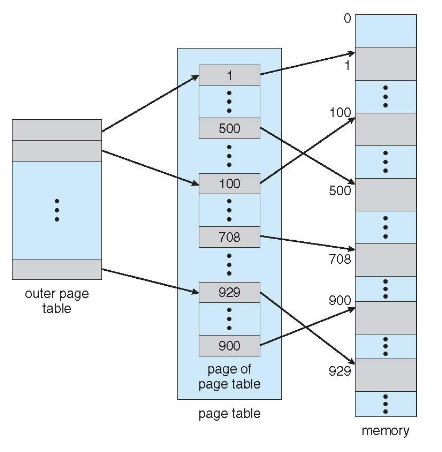
32bit 환경
기존에는 20비트에 page number, 12비트에 page offset을 저장했다면
간단한 two-level paging을 살펴보면,
20비트의 page number를 다시 10비트씩 나누어 이를 또 10비트의 page number, 10비트의 page offset으로 설정한다.
이러한 방식을 forward-mapped page table이라고 부른다.
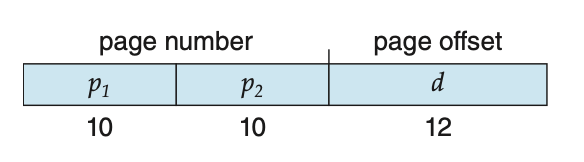
p1 : 외부 페이지 테이블의 인덱스
p2 : 내부 페이지 테이블의 페이지 내의 오프셋
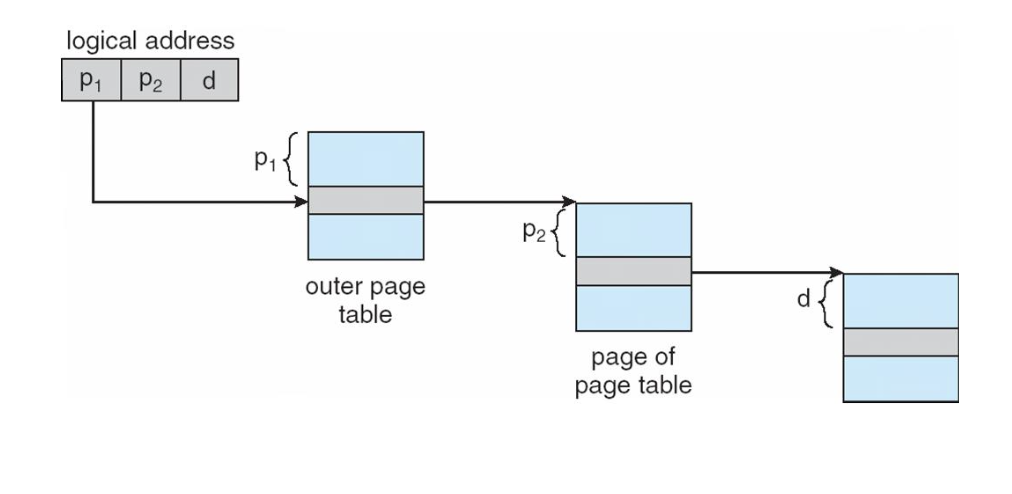
64bit 환경
이 경우에는 앞서 살펴본 2단계 페이징 기법도 충분하지 않다.
단계를 하나 더 추가해 3단계 페이징 기법을 보면 아래와 같다.

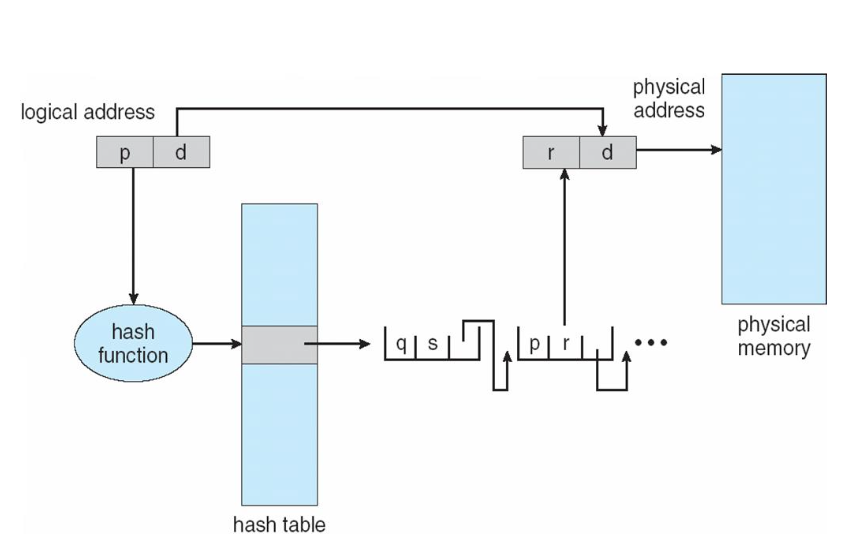
Hashed Page Table
해시 페이지 테이블은 주소 공간이 32비트보다 큰 경우에 많이 사용한다.
해시 페이지 테이블의 각 항목은 연결리스트로 구성이 되어있고, 연결리스트의 원소들은
1) 가상 페이지 번호 : 일치하는 항목을 검색하는 데 사용됨 (key)
2) mapping되는 페이지 프레임 번호 : 가상 페이지 번호에 대응하는 물리적 프레임 (value)
3) 연결 리스트 상 다음 포인터
를 가진다.
64비트 주소 공간에서 사용할 수 있는 방법이 클러스터 된 페이지 테이블(Clustered page tables)을 활용하는 방식이다.
이는 해시 페이지 테이블과 비슷하지만, 각 항목의 시작이 한 페이지를 가리킼는 것이 아닌 여러 페이지를 가리키게 된다. 따라서 한 페이지 테이블의 entry는 여러 physical-page frames들을 매핑할 수 있다.
클러스터 페이지 테이블은 메모리 참조가 연속되지 않고 분산되어 있는 sparse한 주소 공간에서 특히 유용하다.
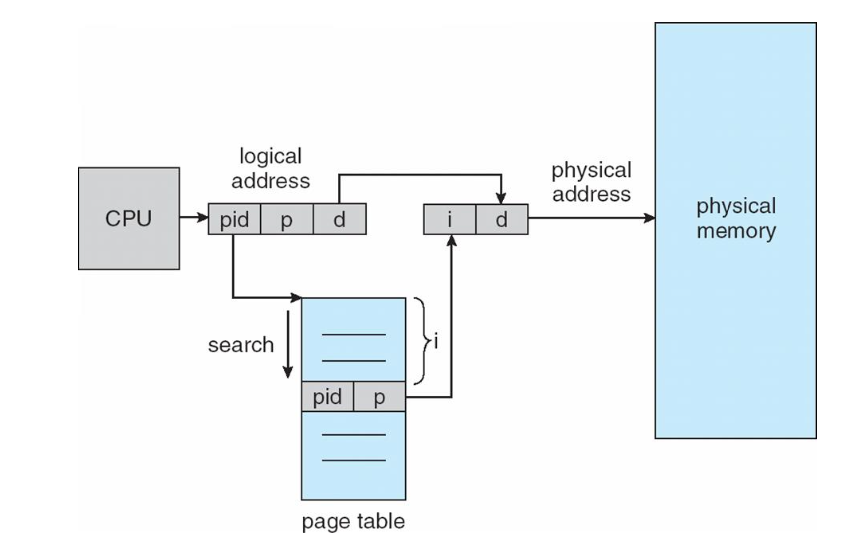
Inverted Page Table
일반적으로 각 프로세스는 연관된 페이지 테이블을 하나씩 가지고 있다.
그 페이지 테이블은 프로세스가 사용하고있는 각각의 페이지에 대한 하나의 entry를 가진다.
운영체제는 반드시 이것을 physical memory address로 변환해주어야한다.
역 페이지 테이블은 각 프로세스가 모든 물리적 페이지를 추적하는 방식이다.
메모리 프레임마다 한 항목씩 할당한다.
각 항목은 실제 메모리 위치에 저장된 페이지의 가상 주소와 그 페이지를 소유하고 있는 프로세스에 대한 정보를 가지고 있다.
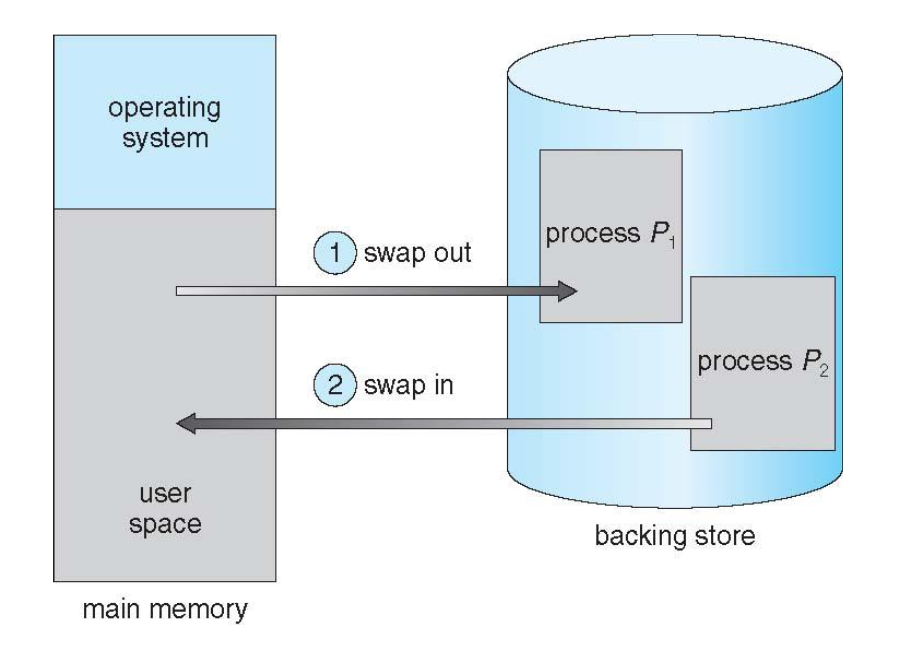
스와핑
스와핑
프로세스는 메모리에 적재되어 실행이 되다가, 잠시 백업 저장장치로 내보내어지기도 하고, 다시 실행을 위해 메모리로 돌아올 수도 있다.
스와핑을 통해 실행되는 프로세스들이 사용해야하는 전체 메모리 크기가 실제 메모리 크기보다 클 수 있게 되고, 따라서 multiprogramming이 가능 및 증가될 수 있다.
이렇게 프로세스가 메모리와 저장장치 사이를 왔다갔다 하는 것을 스와핑이라고 한다.
(스왑 아웃된 프로세스는 다시 들어올 때 똑같은 메모리 주소에 들어오나?? -> 바인딩 기법에 따라 다름)
-
백업 저장장치 (Backing store)
- 사용자의 모든 메모리 이미지 복사본을 수용할 수 있을 만큼 충분히 큰 빠른 디스크- 이러한 메모리 이미지에 직접 접근할 수 있어야 한다.
-
롤 아웃(Roll out), 롤 인(Roll in)
- 우선순위 기반 스케줄링 알고리즘에 사용되는 스와핑의 변형
- 낮은 우선순위의 프로세스는 높은 우선순위의 프로세스가 적재되고 실행될 수 있도록 스왑아웃 된다.
스왑을 하는데 걸리는 시간의 대부분은 전송시간이고, 전체 전송 시간은 스왑되는 메모리의 크기에 정비례한다.
시스템은 프로세스 준비 큐에 디스크에 메모리 이미지가 있는 즉시 실행 가능한 프로세스들을 넣어둔다.
스와핑을 포함한 문맥 교환 시간
문맥 교환이란 실행되고 있는 프로세스를 다른 프로세스로 교환하는 것을 말한다.
만약 CPU에서 실행될 다음 프로세스가 메모리에 없다면 스와핑을 통해 실행할 프로세스를 스왑-인 해야한다.
이 경우 문맥 교환 시간이 매우 길어질 수 있다.
100MB의 프로세스를 50MB/sec의 전송 속도를 지니는 하드 디스크로 스와핑 할 경우
- 스왑 아웃 시간 : 2sec
- 스왑 인 시간 : 2sec (스왑 아웃 시간과 동일)
스왑되는 메모리의 양을 줄일 수 있으면 시간을 줄일 수 있다. 따라서 실제로 사용되는 메모리의 양을 파악해야 한다.
(다음의 시스템 콜을 통해 OS에게 메모리 사용을 알릴 수 있다. request_memory(), release_memory())
스와핑에 대한 다른 제약 조건도 존재
- 보류중인 I/O
- 항상 I/O를 커널 공간으로 전송한 다음 I/O 장치로 전송하는 경우 (이중 버퍼링, double buffering)
최신 운영체제에서는 표준 스와핑을 사용하지 않고, 대신 변형된 버전의 스와핑이 흔히 사용된다. (사용 가능한 메모리가 매우 부족한 상황에서만 스왑)
Swapping with Paging
페이징은 페이징에서의 스와핑을 의미한다. (page-out, page-in)
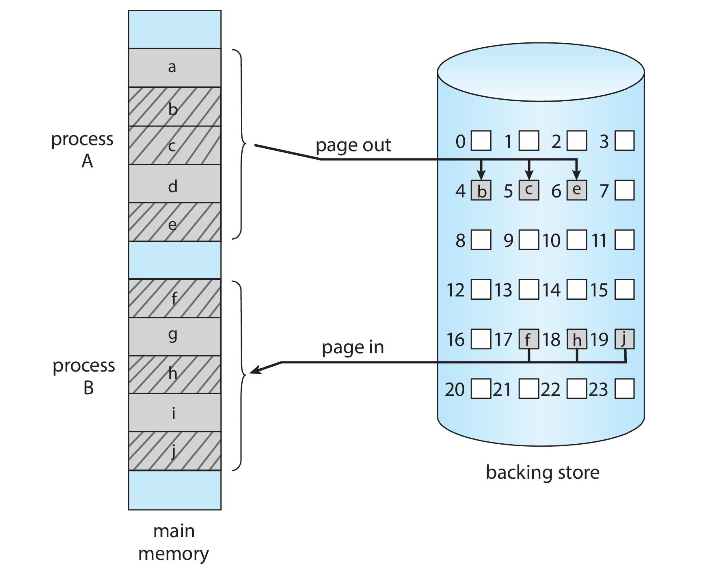
모바일 시스템에서의 스와핑
일반적으로 모바일에서는 스와핑을 지원하지 않는다. 대신 메모리가 부족한 경우 다른 방식을 사용한다.
iOS는 앱에 할당된 메모리를 자발적으로 반환하도록 요청
- 필요한 경우 읽기 전용 데이터를 버리고, 나중에 플래시 메모리에서 적재될 수 있음
- 메모리 반환에 실패하게 되면 종료될 수 있다.
AOS는 메모리가 부족하면 앱을 종료하지만, 빠른 재시작을 위해 응용프로그램의 상태를 플래시 메모리에 쓴다.
Summary
• Memory is central to the operation of a modern computer system and consists of a large array of bytes, each with its own address.
• Onewaytoallocateanaddressspacetoeachprocessisthroughtheuseof base and limit registers. The base register holds the smallest legal physical memory address, and the limit specifies the size of the range.
• Binding symbolic address references to actual physical addresses may
occur during (1) compile, (2) load, or (3) execution time.
• An address generated by the CPU is known as a logical address, which the memory management unit (MMU) translates to a physical address in memory.
• One approach to allocating memory is to allocate partitions of contiguous memory of varying sizes. These partitions may be allocated based on three possible strategies: (1) first fit, (2) best fit, and (3) worst fit.
• Modern operating systems use paging to manage memory.In this process, physical memory is divided into fixed-sized blocks called frames and logical memory into blocks of the same size called pages.
• When paging is used, a logical address is divided into two parts: a page number and a page offset. The page number serves as an index into a per- process page table that contains the frame in physical memory that holds the page. The offset is the specific location in the frame being referenced.
• A translation look-aside buffer(TLB) is a hardware cache of the page table. Each TLB entry contains a page number and its corresponding frame.
• Using a TLB in address translation for paging systems involves obtaining the page number from the logical address and checking if the frame for the page is in the TLB. If it is, the frame is obtained from the TLB. If the frame is not present in the TLB, it must be retrieved from the page table.
• Hierarchical paging involves dividing a logical address into multiple parts, each referring to different levels of page tables. As addresses expand beyond 32 bits, the number of hierarchical levels may become large. Two strategies that address this problem are hashed page tables and inverted page tables.
• Swapping allows the system to move pages belonging to a process to disk to increase the degree of multiprogramming.
• The Intel 32-bit architecture has two levels of page tables and supports either 4-KB or 4-MB page sizes. This architecture also supports page- address extension, which allows 32-bit processors to access a physical address space larger than 4 GB. The x86-64 and ARMv9 architectures are 64-bit architectures that use hierarchical paging.
