
굉장히... 굉장히 오랜만에 프로젝트 글을 써보는 것 같습니다. 개인적인 일로 나름 바빴던지라 이제서야 프로젝트도 재개하고 글도 작성하네요. 아무튼, 저번 글에 이어 이번에도 챗봇 프로젝트, 시작하겠습니다.
모델 탐색
지금 제가 진행하는 프로젝트는 이전 글을 바탕으로 새로운 글을 만들어내는 Text Generation 태스크입니다. BERT나 Electra같은 양방향 모델은 강력한 성능을 자랑하지만, 생성 태스크에는 맞지 않는 모델입니다. 해당 모델은 Transformer 모델의 인코더를 기반으로 한 모델인데, 이런 인코더를 기반으로 한 모델들은 생성 태스크에는 적합하지 않습니다. 반대로 순수 Transformer와 같은 인코더 - 디코더 모델이나, 혹은 GPT 종류와 같이 디코더를 기반으로 한 모델이 생성 태스크에 적합한 모델입니다.
앞서 말한 모델 중 Transformer를 제외한 모델들은 모두 사전학습 모델(Pre-trained Model)에 속합니다. 사전학습 모델은 기존에 대용량의 데이터로 미리 학습을 해놓고, 특정 도메인에 속하는 상대적으로 적은 데이터로 미세조정(Fine-Tunining)해 사용하는 모델입니다. 최신 딥러닝 모델들의 대다수가 이 사전학습 모델에 속합니다.
왼쪽 빨간 네모는 트랜스포머 모델의 인코더, 오른쪽 파란색 네모는 디코더를 표현했습니다.
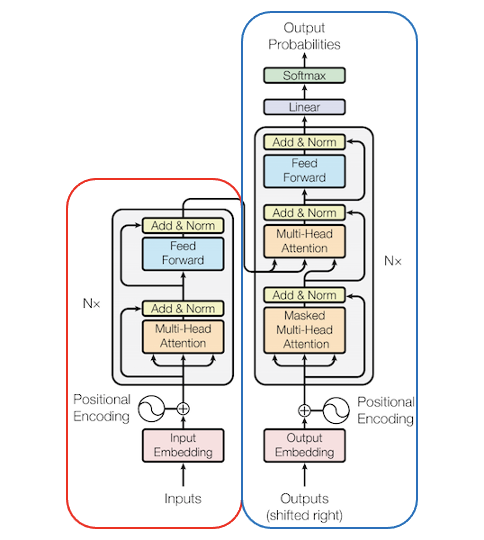
최종적으로, 저는 GPT2 모델을 선택했습니다. 오픈도메인 챗봇의 성능 자체는 구글에서 발표한 Meena등 더욱 뛰어난 모델이 있겠지만, GPT2의 경우는 이미 huggingface라는 라이브러리에서 지원하고있기 때문입니다. 즉, 굳이 모델을 처음부터 만들고, pre-train을 진행하고 거기에 fine-tuning까지 해야 하는 삽질을 하지 않아도 된다는 뜻입니다.
게다가 GPT2는 이미 DialoGPT라는 GPT 기반 챗봇 모델이 있고, 이를 통해 어느정도의 성능은 보장받는다고 봐도 무방하기 때문입니다.
그래서 최종적으론 SKT에서 학습시킨 Ko-GPT2를 사용하기로 했습니다. 대화체에도 익숙하게 학습되어있고, 무엇보다 SKT에서 학습시켰으니 좋은 성능을 낼 수 있겠죠?
학습을 위한 준비
모델 하나 선택했다고 바로 학습을 할 수 있는게 아닙니다! 학습을 하기 위해 정해줄 것이 조금 남아있어요. 하나씩 얘기해보겠습니다.
토크나이저 커스텀하기
웬만한 단어를 모두 인식할 수 있다 하더라도, 그 '웬만한'의 범위에 들어가지 않는 단어는 언제나 있는 법입니다. 특히나 시간에 따라 항상 바뀌는 구어체라면 더더욱 말이죠. 이를 위해 이미 학습된 토크나이저에 우리가 원하는 단어를 몇개 추가해보겠습니다.
Ko-GPT2는 정말 많은 언어를 커버할 수 있지만, ㅋㅋㅋ 나 ㅗㅜㅑ 등 자모가 따로 노는 단어는 읽지를 못하는 것을 확인했습니다. 이를 위해 토크나이저를 한번 만져보겠습니다.
import tokenizers
from transformers import GPT2TokenizerFast
print(tokenizer.__version__) # 0.10.2
tokenizer = GPT2TokenizerFast.from_pretrained("taeminlee/kogpt2")
tokenizer.save_pretrained('tokenizer', legacy_format=False)`Ko-GPT2의 토크나이저는 BPE 방법을 사용하는 GPT2Tokenizer입니다. 이대로 토크나이저를 불러와서 저장을 하는데, 이때 legacy_format=False로 지정하고 저장합니다. True로 지정하게 된다면 tokenizers 버전이 0.10.1 이전의 형식으로 저장되는데, GPT2Tokenizer의 경우 이때 에러가 발생해서 불러올 수가 없더군요.
기억할건 두가지입니다.
- tokenizers 버전은 0.10.2 이상
- 저장할 때,
legacy_format=False꼭 넣어주기
이렇게 토크나이저를 파일로 저장하고, 저장된 파일들을 적절하게 수정해줍니다. 수정할 땐 사용하지 않는 토큰인 [unused]토큰들을 바꿔주시면 됩니다. 저는 자음과 모음을 일반 토큰에 추가하고 이름을 동일하게 인식할 수 있도록 [name]이라는 특수 토큰을 추가했습니다.
데이터 양식에 맞게 저장하기
이전 글에서 저는 멀티 턴을 인식하는 챗봇을 이야기했었습니다. 단순하게 한 문장 한문장을 주고 받는것이 아니라, 실제 메신저처럼 여러번 말해도 이를 인식할 수 있는 모델이 더욱 사람같이 보이겠죠?
이를 위해서 모델은 하나의 문장(발화)을 받고 출력을 뽑아내는게 아니라, 그 사용자가 한 말이 끝날때까지 주어진 모든 문장들을 새로운 토큰 [sept]로 분리시켜 입력받습니다.
input: ㄴㄴ [sept] 재택 잘하시고 [sept] 난 내일 애플 스토어를 가고
output: 오우야... [sept] 맥북 살아나는더야?
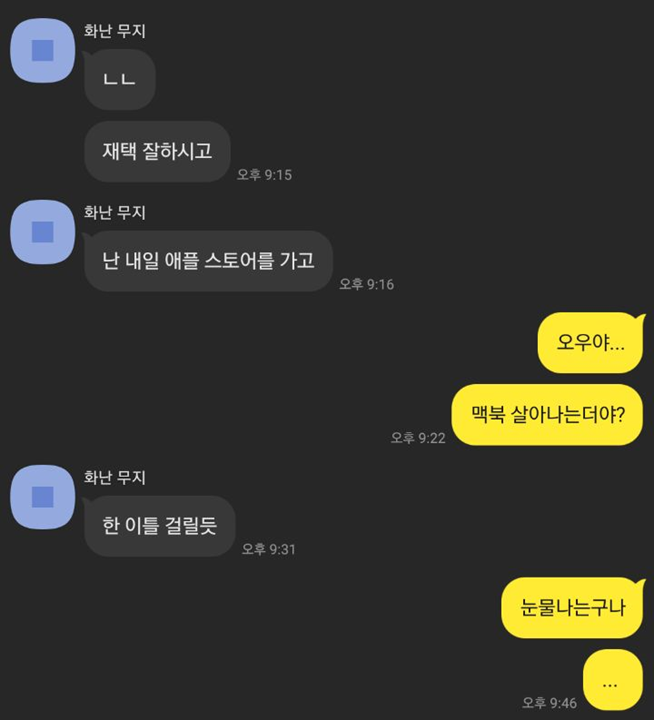
이렇게 하면 여러 발화를 한번에 처리할 수 있는 모델이 완성되겠죠?
데이터를 위와 같은 방식으로 저장하고, huggingface에서 용이하게 불러올 수 있도록 .jsonl 형식으로 저장합니다.
이렇게 데이터와 토크나이저, 학습 루틴등이 모두 짜여졌다면, 바로 학습을 하면 되겠죠? 사전학습된 GPT2 모델을 5epochs정도 파인튜닝한 결과입니다.
기만...?

어... 왜인지 기만을 잘하는 이상한 챗봇이 만들어졌습니다. 뭔가 짜증나는 말투네요.
저런 경우는 상당히 잘 뽑힌 경우고, 잘 뽑아내지 못하는 경우도 상당히 많았습니다. 데이터가 부족한것일수도 있고, 과적합일수도 있고, 많은 이유들이 있겠죠?
마침 얼마전 skt에서 kogpt2-v2 모델을 개발했다고 하길래 데이터를 증강해서 다시 학습시켜볼까도 했지만... 실수로 전처리 파일들을 모두 날려버렸어요...
광기
아무튼 그러한 이유로... 학습에는 시간이 좀 걸릴 예정입니다. 눈물나네요...
마치며
이번 시간엔 저번에 전처리한 데이터를 가지고 모델을 학습시켜보았습니다. 비록 만족할만한 성능은 아니지만, 그래도 가능성이 보인다는 것을 알 수 있었습니다. 최대한 빨리 파일들을 복구하고, 다른 성능 좋은 모델들도 찾아보며 더욱 사람같이 보일 수 있는, 그런 봇을 만들어보겠습니다.
다음 글은 아마도 재학습 이후, 디스코드로 서빙까지 해보는 글이 될 것 같습니다. 읽어주셔서 감사합니다!
